最近有个手动任务,需要计算每天的数据量,然后再进行处理。根据这种情况计算,sql是这样的
SELECT FROM_UNIXTIME(publish_time / 1000, '%Y-%m-%d') date,
COUNT(*) as count
FROM
info_article_main
WHERE
publish_time BETWEEN ?
AND ?
GROUP BY date
这个sql的执行计划
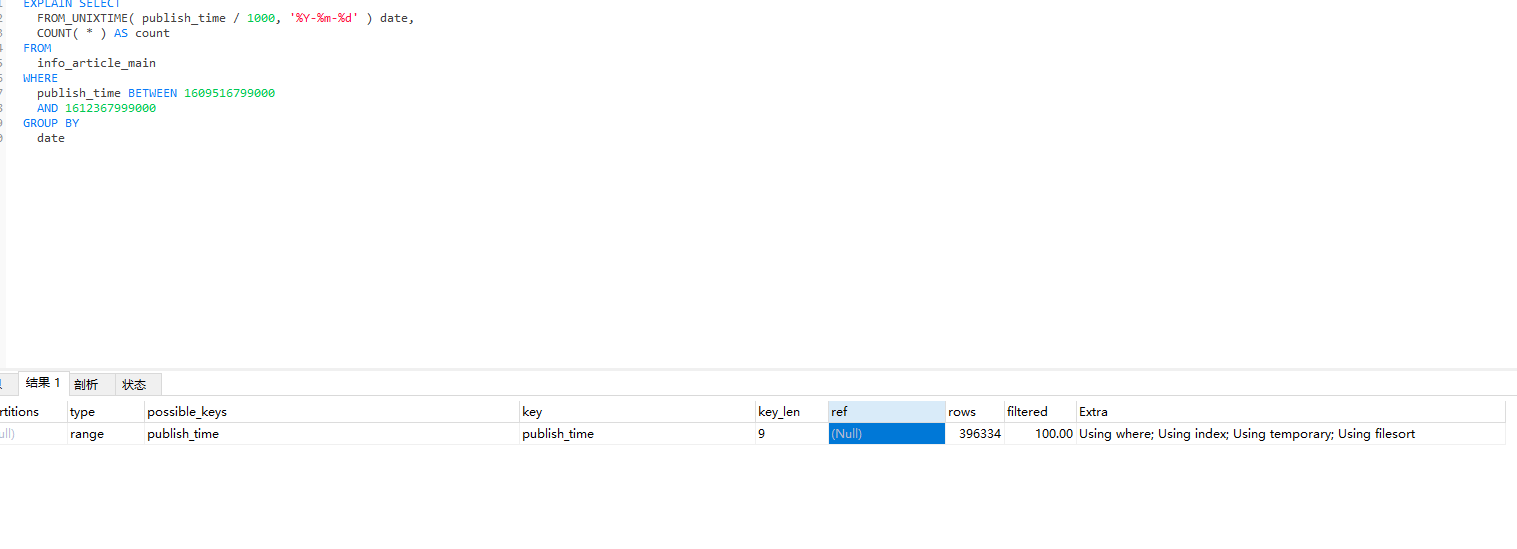
在extra字段里可以看到使用了索引,执行临时表,文件排序操作。
type的类型是range,范围查询也走了索引,看起来还不错。
从rows上来看,扫描了接近40w的数据,数据量很大。所以这个sql有时候会执行十几二十几秒的时间,会导致服务之间调用超时。
group by 语句中需要放到临时表上的数据量特别大,却还是要按照“先放到内存临时表,插入一部分数据后,发现内存临时表不够用了再转成磁盘临时表”,看上去就有点儿傻。
针对这种情况,我们可以使用SQL_BIG_RESULT,通知优化器这次查询数据量很大,直接使用磁盘临时表
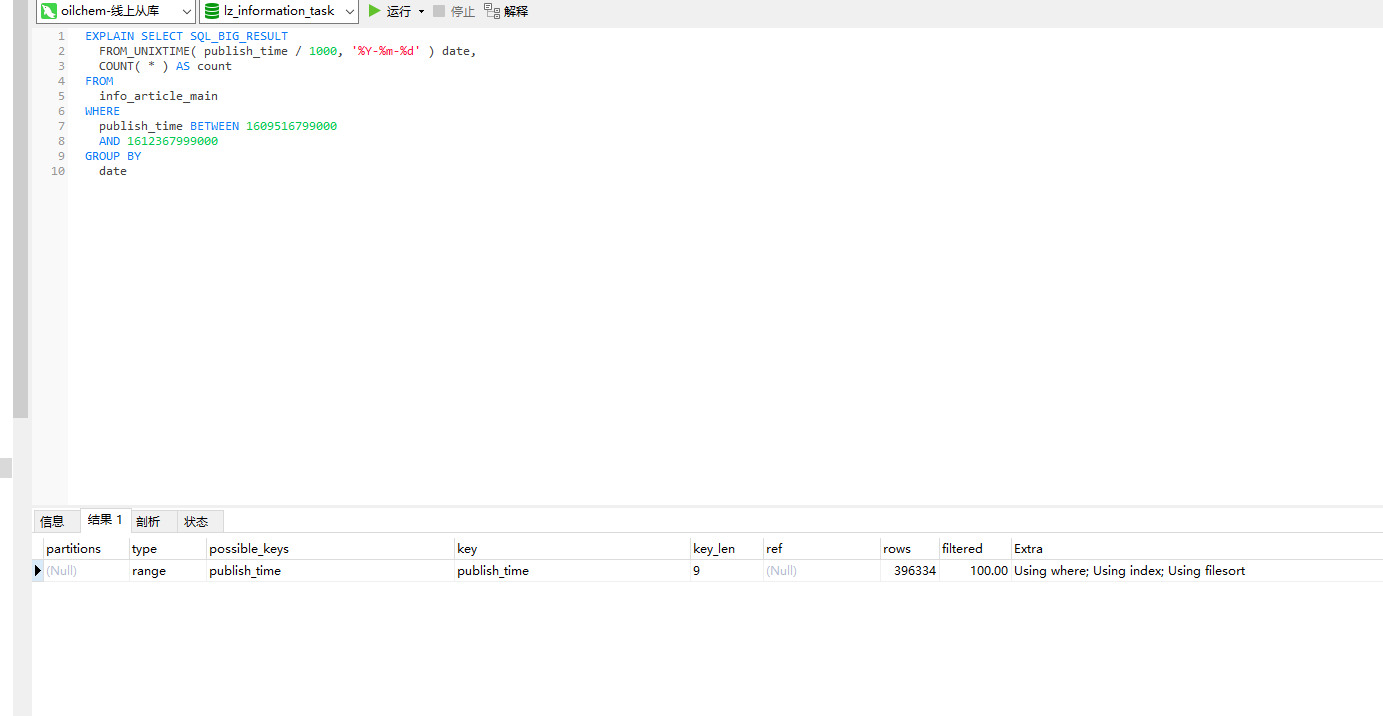
从 Extra 字段可以看到,这个语句的执行没有再使用临时表,而是直接用了排序算法。
如果对 group by 语句的结果没有排序要求,要在语句后面加 order by null;
尽量让 group by 过程用上表的索引,确认方法是 explain 结果里没有 Using temporary 和 Using filesort;
如果 group by 需要统计的数据量不大,尽量只使用内存临时表;也可以通过适当调大 tmp_table_size 参数,来避免用到磁盘临时表;
如果数据量实在太大,使用 SQL_BIG_RESULT 这个提示,来告诉优化器直接使用排序算法得到 group by 的结果。