文章表一
- LeetCode 513.找树左下角的值
- 题目链接🔗
- 思路
- LeetCode 112. 路径总和
- 题目链接🔗
- 思路
- LeetCode 113.路径总和 ii
- 题目链接🔗
- 思路
- LeetCode 106.从中序与后序遍历序列构造二叉树
- 题目链接🔗
- 思路
- LeetCode 105.从前序与中序遍历序列构造二叉树
- 题目链接🔗
- 思路
LeetCode 513.找树左下角的值
题目链接🔗
LeetCode 513.找树左下角的值
思路
本题使用层序遍历时比较容以理解的
代码如下:
class Solution {
public int findBottomLeftValue(TreeNode root) {
Queue<TreeNode> que = new LinkedList();
que.offer(root);
int res = 0;
while(!que.isEmpty()){
int len = que.size();
for(int i = 0; i < len; i++){
TreeNode node = que.poll();
if (i == 0) {
res = node.val;
}
if(node.left != null){
que.offer(node.left);
}
if(node.right != null){
que.offer(node.right);
}
}
}
return res;
}
}
递归
我们来分析一下题目:在树的最后一行找到最左边的值。
首先要是最后一行,然后是最左边的值。
如果使用递归法,如何判断是最后一行呢,其实就是深度最大的叶子节点一定是最后一行。
所以要找深度最大的叶子节点。
那么如何找最左边的呢?可以使用前序遍历(当然中序,后序都可以,因为本题没有 中间节点的处理逻辑,只要左优先就行),保证优先左边搜索,然后记录深度最大的叶子节点,此时就是树的最后一行最左边的值。
递归三部曲:
-
确定递归函数的参数和返回值
参数必须有要遍历的树的根节点,还有就是一个int型的变量用来记录最长深度。 这里就不需要返回值了,所以递归函数的返回类型为void。本题还需要类里的两个全局变量,Depp用来记录最大深度,value记录最大深度最左节点的数值。
代码如下:
private int Deep = -1; private int value = 0; void findLeftValue(TreeNode root,int deep) -
确定终止条件
当遇到叶子节点的时候,就需要统计一下最大的深度了,所以需要遇到叶子节点来更新最大深度。代码如下:
if(root.left == null && root.right==null){ if(deep > Deep){ value = root.val; Deep = deep; } } -
确定单层递归的逻辑
if (root.left != null) findLeftValue(root.left,deep + 1); if (root.right != null) findLeftValue(root.right,deep + 1);
整体代码:
class Solution {
private int Deep = -1;
private int value = 0;
public int findBottomLeftValue(TreeNode root) {
value = root.val;
findLeftValue(root,0);
return value;
}
private void findLeftValue (TreeNode root,int deep) {
if (root == null) return;
if (root.left == null && root.right == null) {
if (deep > Deep) {
value = root.val;
Deep = deep;
}
}
if (root.left != null) findLeftValue(root.left,deep + 1);
if (root.right != null) findLeftValue(root.right,deep + 1);
}
}
LeetCode 112. 路径总和
题目链接🔗
LeetCode 112. 路径总和
思路
可以使用深度优先遍历的方式(本题前中后序都可以,无所谓,因为中节点也没有处理逻辑)来遍历二叉树
-
确定递归函数的参数和返回类型
参数:需要二叉树的根节点,还需要一个计数器,这个计数器用来计算二叉树的一条边之和是否正好是目标和,计数器为int型。本题我们要找一条符合条件的路径,所以递归函数需要返回值,及时返回,那么返回类型是什么呢?
如图所示:
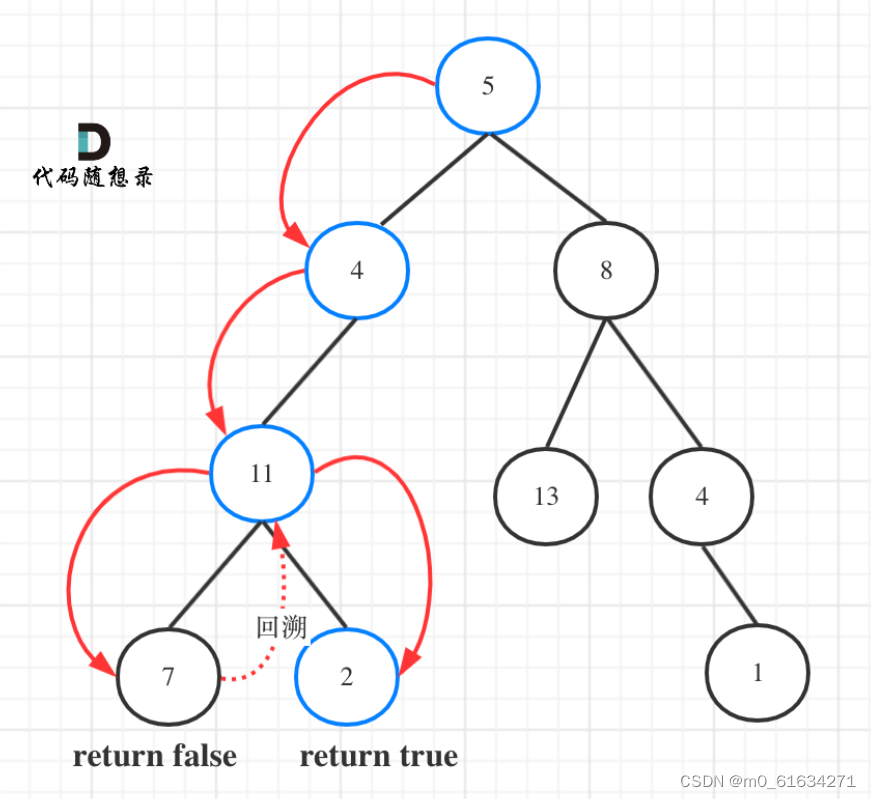
图中可以看出,遍历的路线,并不要遍历整棵树,所以递归函数需要返回值,可以用boolean类型表示。 -
确定终止条件
首先计数器如何统计这一条路径的和呢?不要去累加然后判断是否等于目标和,那么代码比较麻烦,可以用递减,让计数器count初始为目标和,然后每次减去遍历路径节点上的数值。
如果最后count == 0,同时到了叶子节点的话,说明找到了目标和。
如果遍历到了叶子节点,count不为0,就是没找到。
-
确定单层递归的逻辑
因为终止条件是判断叶子节点,所以递归的过程中就不要让空节点进入递归了。递归函数是有返回值的,如果递归函数返回true,说明找到了合适的路径,应该立刻返回。
整体代码:
class solution {
public boolean haspathsum(treenode root, int targetsum) {
if (root == null) {
return false;
}
targetsum -= root.val;
// 叶子结点
if (root.left == null && root.right == null) {
return targetsum == 0;
}
if (root.left != null) {
boolean left = haspathsum(root.left, targetsum);
if (left) { // 已经找到
return true;
}
}
if (root.right != null) {
boolean right = haspathsum(root.right, targetsum);
if (right) { // 已经找到
return true;
}
}
return false;
}
}
// 简洁方法
class solution {
public boolean haspathsum(treenode root, int targetsum) {
if (root == null) return false; // 为空退出
// 叶子节点判断是否符合
if (root.left == null && root.right == null) return root.val == targetsum;
// 求两侧分支的路径和
return haspathsum(root.left, targetsum - root.val) || haspathsum(root.right, targetsum - root.val);
}
}
LeetCode 113.路径总和 ii
题目链接🔗
LeetCode 113.路径总和 ii
思路
class Solution {
List<List<Integer>> result;
LinkedList<Integer> path;
public List<List<Integer>> pathSum (TreeNode root,int targetSum) {
result = new LinkedList<>();
path = new LinkedList<>();
travesal(root, targetSum);
return result;
}
private void travesal(TreeNode root, int count) {
if (root == null) return;
path.offer(root.val);
count -= root.val;
if (root.left == null && root.right == null && count == 0) {
result.add(new LinkedList<>(path));
}
travesal(root.left, count);
travesal(root.right, count);
path.removeLast(); // 回溯
}
}
LeetCode 106.从中序与后序遍历序列构造二叉树
题目链接🔗
LeetCode 106.从中序与后序遍历序列构造二叉树
思路
首先回忆一下如何根据两个顺序构造一个唯一的二叉树,相信理论知识大家应该都清楚,就是以 后序数组的最后一个元素为切割点,先切中序数组,根据中序数组,反过来再切后序数组。一层一层切下去,每次后序数组最后一个元素就是节点元素。
流程如图:
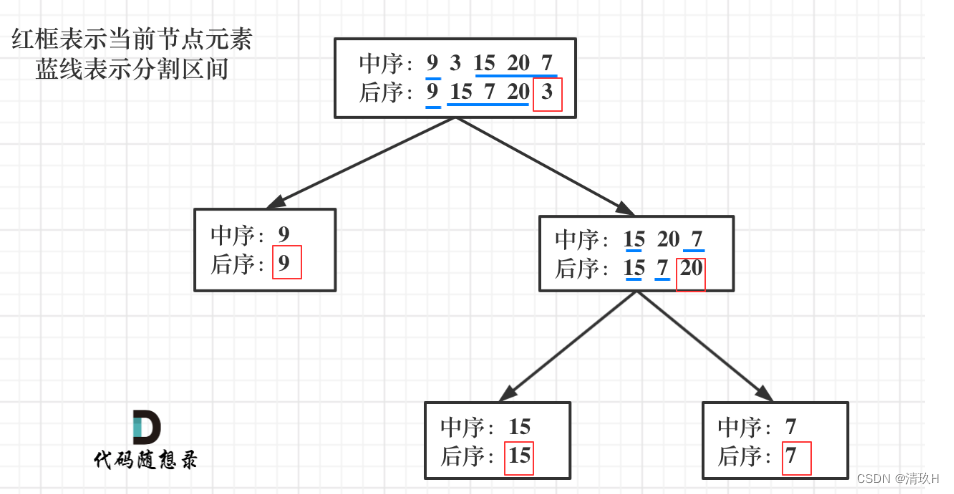
那么代码应该怎么写呢?
说到一层一层切割,就应该想到了递归。
来看一下一共分几步:
-
第一步:如果数组大小为零的话,说明是空节点了。
-
第二步:如果不为空,那么取后序数组最后一个元素作为节点元素。
-
第三步:找到后序数组最后一个元素在中序数组的位置,作为切割点
-
第四步:切割中序数组,切成中序左数组和中序右数组 (顺序别搞反了,一定是先切中序数组)
-
第五步:切割后序数组,切成后序左数组和后序右数组
-
第六步:递归处理左区间和右区间
class Solution {
Map<Integer, Integer> map; // 方便根据数值查找位置
public TreeNode buildTree(int[] inorder, int[] postorder) {
map = new HashMap<>();
for (int i = 0; i < inorder.length; i++) { // 用map保存中序序列的数值对应位置
map.put(inorder[i], i);
}
return findNode(inorder, 0, inorder.length, postorder,0, postorder.length); // 前闭后开
}
public TreeNode findNode(int[] inorder, int inBegin, int inEnd, int[] postorder, int postBegin, int postEnd) {
// 参数里的范围都是前闭后开
if (inBegin >= inEnd || postBegin >= postEnd) { // 不满足左闭右开,说明没有元素,返回空树
return null;
}
int rootIndex = map.get(postorder[postEnd - 1]); // 找到后序遍历的最后一个元素在中序遍历中的位置
TreeNode root = new TreeNode(inorder[rootIndex]); // 构造结点
int lenOfLeft = rootIndex - inBegin; // 保存中序左子树个数,用来确定后序数列的个数
root.left = findNode(inorder, inBegin, rootIndex,
postorder, postBegin, postBegin + lenOfLeft);
root.right = findNode(inorder, rootIndex + 1, inEnd,
postorder, postBegin + lenOfLeft, postEnd - 1);
return root;
}
}
LeetCode 105.从前序与中序遍历序列构造二叉树
题目链接🔗
LeetCode 105.从前序与中序遍历序列构造二叉树
思路
该题和上一题的思路基本一致
class Solution {
Map<Integer, Integer> map;
public TreeNode buildTree(int[] preorder, int[] inorder) {
map = new HashMap<>();
for (int i = 0; i < inorder.length; i++) { // 用map保存中序序列的数值对应位置
map.put(inorder[i], i);
}
return findNode(preorder, 0, preorder.length, inorder, 0, inorder.length); // 前闭后开
}
public TreeNode findNode(int[] preorder, int preBegin, int preEnd, int[] inorder, int inBegin, int inEnd) {
// 参数里的范围都是前闭后开
if (preBegin >= preEnd || inBegin >= inEnd) { // 不满足左闭右开,说明没有元素,返回空树
return null;
}
int rootIndex = map.get(preorder[preBegin]); // 找到前序遍历的第一个元素在中序遍历中的位置
TreeNode root = new TreeNode(inorder[rootIndex]); // 构造结点
int lenOfLeft = rootIndex - inBegin; // 保存中序左子树个数,用来确定前序数列的个数
root.left = findNode(preorder, preBegin + 1, preBegin + lenOfLeft + 1,
inorder, inBegin, rootIndex);
root.right = findNode(preorder, preBegin + lenOfLeft + 1, preEnd,
inorder, rootIndex + 1, inEnd);
return root;
}
}