现象描述
涉及HDFS文件浏览器的某个功能运行一段时间后会出现OOM的情况
错误日志如下:
service.log.2023-02-01-0.log:java.lang.OutOfMemoryError: Java heap space
排查过程
需要查看dump文件排查一下造成OOM的原因
查看jvm参数如下:
java -Duser.timezone=Asia/Shanghai
# -xms:初始堆大小 512M
-Xms512m
# -xmx:最大堆大小 1024M
-Xmx1024m
# -XX:MetaspaceSize 元空间最小尺寸128M,初次分配,表示metaspace首次使用不够而触发FGC的阈值,只对触发起作用
-XX:MetaspaceSize=128m
# -XX:MaxMetaspaceSize 元空间最大尺寸512M
-XX:MaxMetaspaceSize=512m
# -XX:+HeapDumpOnOutOfMemoryError 表示当JVM发生OOM时,自动生成DUMP文件
-XX:+HeapDumpOnOutOfMemoryError
# -XX:+PrintGCDateStamps 输出GC的时间戳(以JVM启动到当期的总时长的时间戳形式)
-XX:+PrintGCDateStamps
# -XX:+PrintGCDetails 输出详细GC日志
-XX:+PrintGCDetails
# 年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代,设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5
-XX:NewRatio=1
# 设置年轻代中Eden区与Survivor区的大小比值。设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6
-XX:SurvivorRatio=30
# 使用线性垃圾回收器
-XX:+UseParallelGC
# 使用 Parallel Scavenge收集器的老年代版本,使用多线程和标记-整理算法。
-XX:+UseParallelOldGC
可以发现并没有指定dump文件存储路径,默认存储在启动该jar的用户根目录下,当前是root用户,从/root路径下将dump文件(java_pid25034.hprof)下载到本地进行分析
- 安装MemoryAnalyzer对dump文件进行分析

发现所有实例对象中,ConcurrentHashMap占比达到47%,实例数10100193,确定它应该是问题所在。软件自动定位到其中占比最多的一个实例是来源于DistributedFileSystem的值,以此为关键字在代码中进行排查。
原因溯源
定位到代码中发现是之前为解决“两个HDFS集群namespace同名时会造成两个集群读取到同一套文件系统”的问题,对命名空间库中已经存在的命名空间,由调用FileSystem.get(hadoopConfig)方法换为调用FileSystem.newInstance方法新建实例。这样确实能解决这个问题,但是为什么会造成OOM呢?
查看HDFS源码中的FileSystem.newInstance源码:
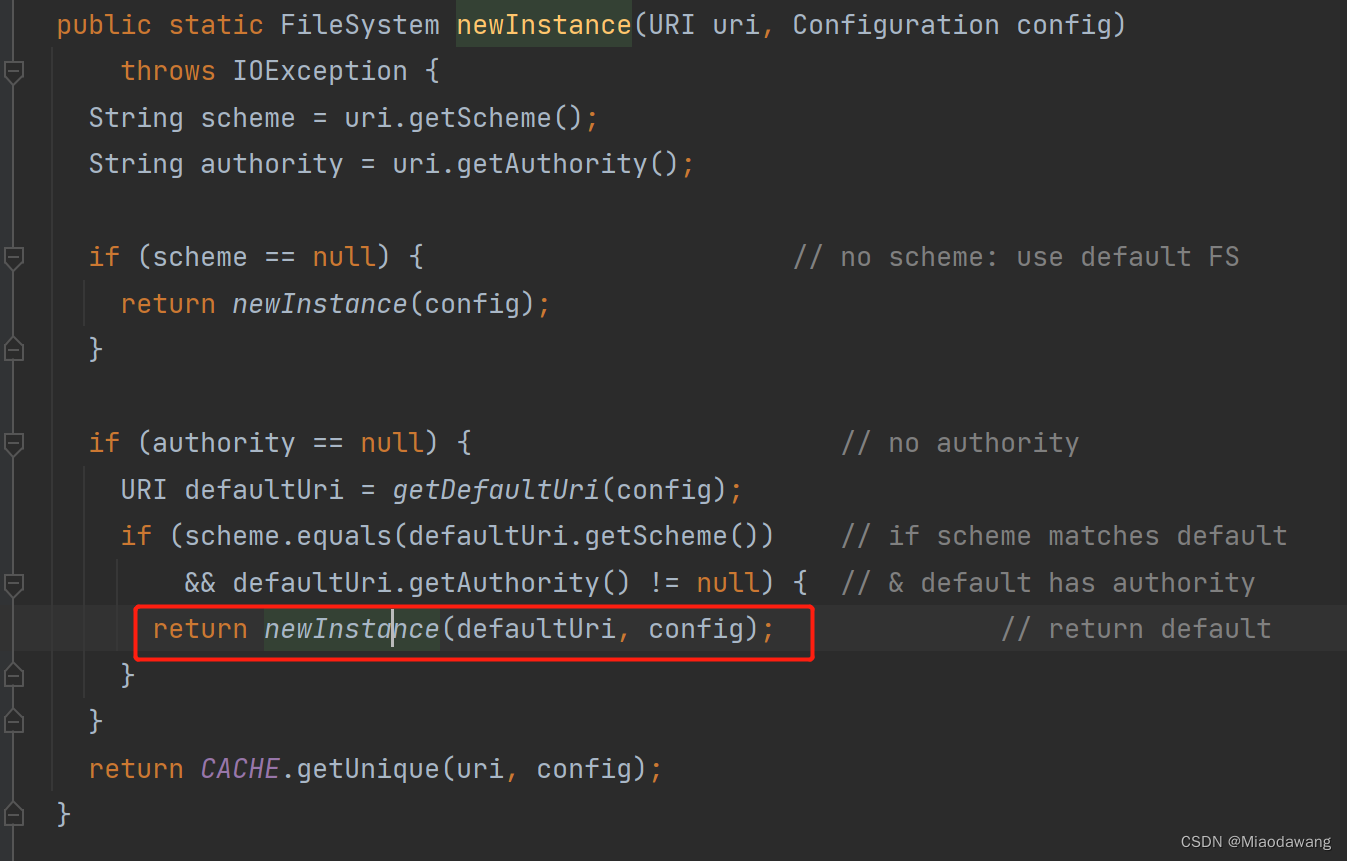
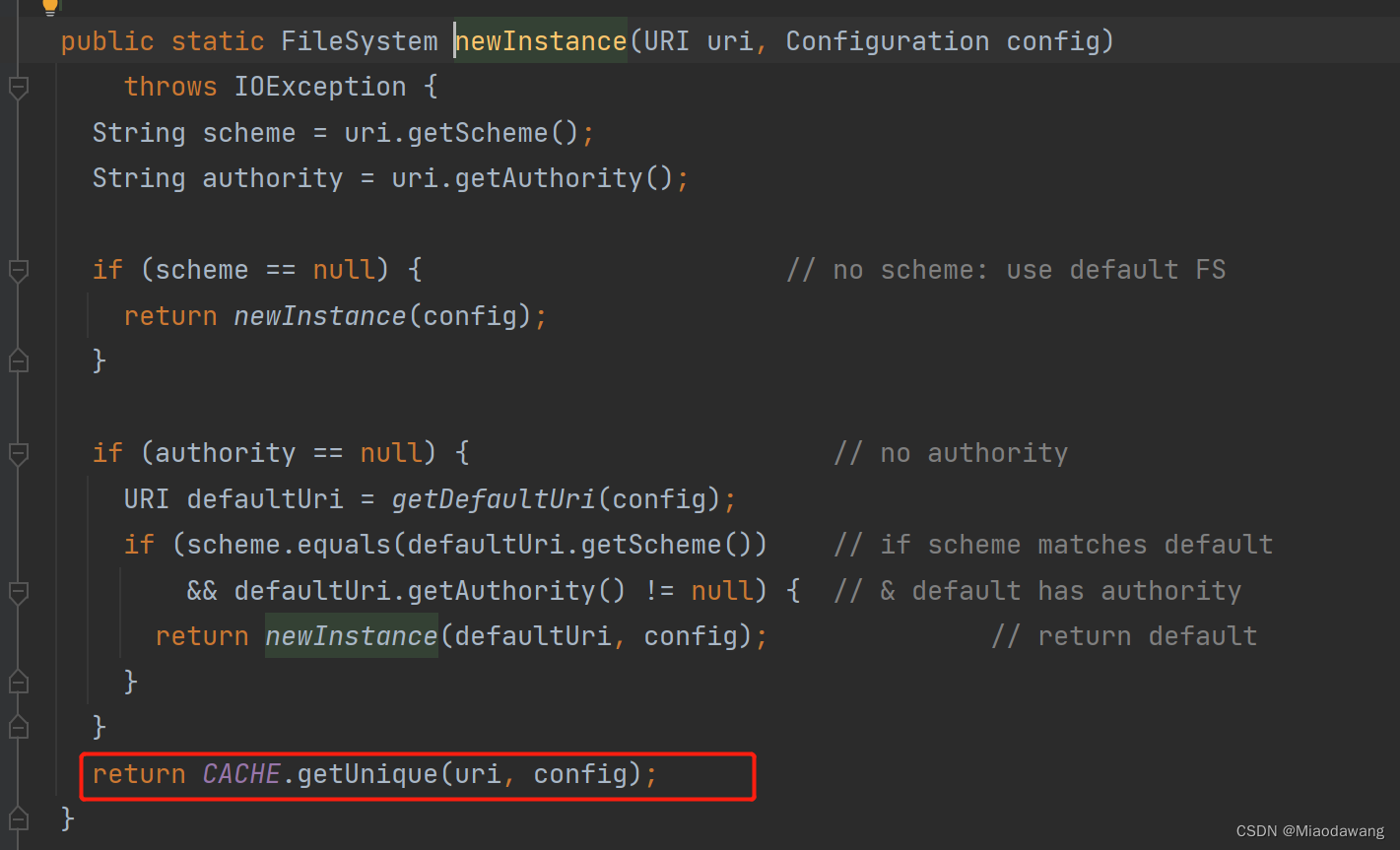

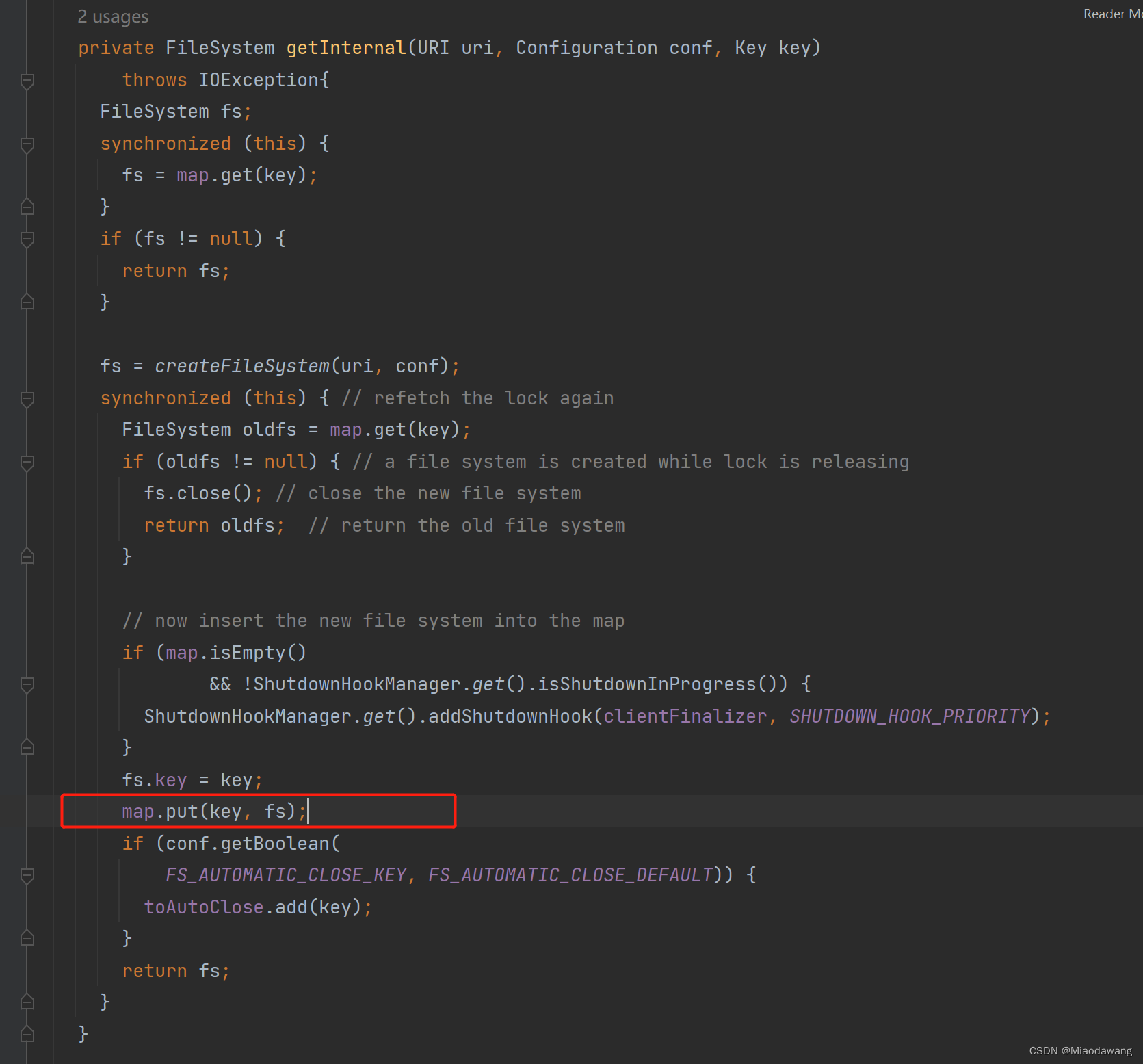
我们发现在底层方法中会有一行向静态变量cache下的map中put值的代码,该类使用公共类加载器,而此类加载器加载过的所有 放在堆中的Class实例都被回收完了, 此类加载器才会被回收,静态变量只有在类加载器被回收时才会被回收,也就意味着该cache以及其下的map一直不会被回收。
因此我们可以看出,解决问题的人希望通过newInstance函数每次都产生新实例的方式解决两个集群namespace同名时混淆的问题,修改后每次调用该函数都会调用newInstance函数,由于对所用到的HDFS源码底层逻辑掌握不够清晰,引入了新的问题,最终导致在需要定时多次调用该服务的在业务场景下OOM情况的发生。
解决方案
使用一个HashMap将每个HDFS对应的FileSystem都缓存起来,在创建之前判断缓存map中是否存在,如果存在则从缓存中取出该实例,不存在则新建并放入map。使用HashMap的computeIfAbsent实现。
private final Map<String, FileSystem> fileSystemMap = new ConcurrentHashMap<>();
//逻辑改为以下,每个集群的hadoopConfig都是不同的可用来标识该集群
return fileSystemMap.computeIfAbsent(ns, value -> newFileSystem(value, hadoopConfig));