第二十一课 卷积神经网络之池化层
卷积神经网络的一个重要概念就是池化层,一般是在卷积层之后。池化层对输入做降采样,常用的池化做法是对每个滤波器的输出求最大值,平均值,中位数等。下面我们和沐神详细学习一下池化层的原理与实现方法吧!
目录
理论部分
实践部分
理论部分
下面举一个老的例子。

对于X矩阵,卷积层可以很容易得把1-0的边缘检测处来,也就是说,卷积对位置信息十分的敏感。但是仔细想想,这貌似也不是啥好东西,因为我的图片不能保证边缘就是一条竖直的直线,可能有倾斜或差别,那么有差别后,可能卷积对它的识别就从原本的“1”变成“0”了。。。这就需要一个手段让卷积能够“模棱两可”的识别同一个东西使其输出结果相同且正确。这个手段就是池化层。
池化层的工作原理如下图所示。
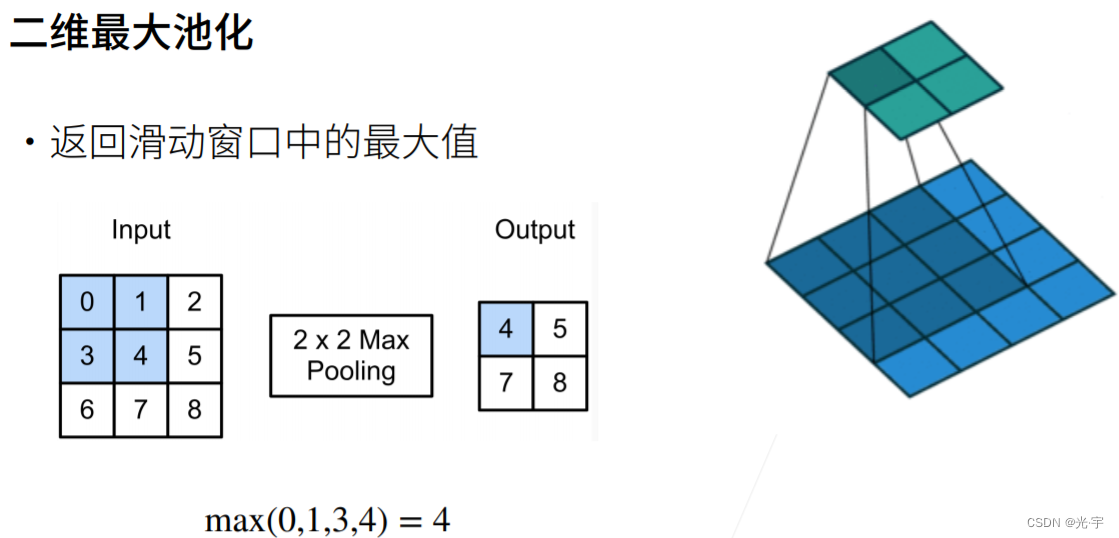
它的原理形似卷积,但他不是卷积,区别就在于,输出的每一个元素都是一个特定区域里的最大元素。

这里我考虑了一个问题,那就是卷积、池化和激活的顺序要如何设置,大家可以参考一下这篇博客会受益匪浅的:https://blog.csdn.net/Lyndon0_0/article/details/116118004
从上面这幅图可以看出,最大池化层可以允许输入发送偏移,而且他作用在卷积输出上可以时输出结果有一定的模糊效果,这也就是我刚才所说的“模棱两可”的含义。
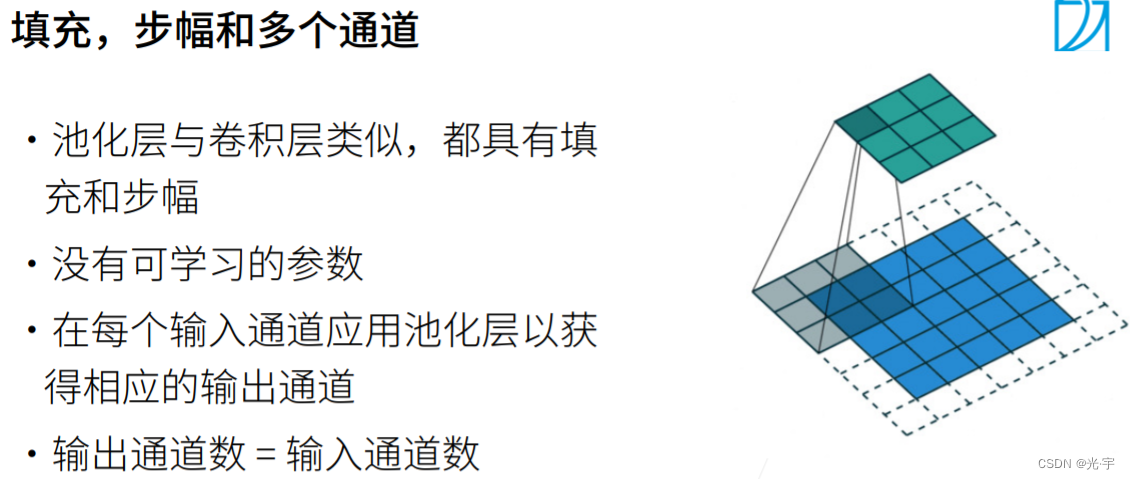
和卷积一样,池化也有填充和步幅这两个超参数。但是它没有可供学习的参数,没有kernal参数,他就是一个最大的计算子。池化层给每个通道做一次池化层,也就是说,它不会和卷积层那样去融合通道,因此池化层的输出通道数=输入通道数。
除了最大池化层,还有平均池化层这种常用的池化层。也就是取一个区域的平均值。


实践部分


代码:
#汇聚层
#实现汇聚层的正向传播
import torch
from torch import nn
from d2l import torch as d2l
def pool2d(X, pool_size, mode='max'):#正向传播函数,X是输入,pool_size池化窗口大小,mode表示最大池化
p_h, p_w = pool_size
Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))#输出的大小和卷积的计算一样
for i in range(Y.shape[0]):#每行迭代
for j in range(Y.shape[1]):#每列迭代
if mode == 'max':#最大池化
Y[i, j] = X[i:i + p_h, j:j + p_w].max()#对池化的区域取最大
elif mode == 'avg':#平均池化
Y[i, j] = X[i:i + p_h, j:j + p_w].mean()#对池化的区域取平均
return Y
#验证二维最大汇聚层的输出
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
print(pool2d(X, (2, 2)))
print('#######################################################################')
#验证平均汇聚层
print(pool2d(X, (2, 2), 'avg'))
print('#######################################################################')
#填充和步幅
X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4))
print(X)
print('#######################################################################')
#深度学习框架中的步幅与池化窗口的大小相同
pool2d = nn.MaxPool2d(3)#直接调用,3*3的窗口,这里步幅和窗口大小是相同的,这样的话
#池化一次后下一次池化窗口不会重叠。
print(pool2d(X))
print('#######################################################################')
#填充和步幅可以手动设定
pool2d = nn.MaxPool2d(3, padding=1, stride=2)#padding是填充,后者是步幅
print(pool2d(X))
print('#######################################################################')
#设定一个任意大小的矩形池化窗口,并分别设定填充和步幅的高度和宽度
pool2d = nn.MaxPool2d((2, 3), padding=(1, 1), stride=(2, 3))
print(pool2d(X))
print('#######################################################################')
#汇聚层在每个输入通道上单独运算
X = torch.cat((X, X + 1), 1)
print(X)
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
print(pool2d(X))tensor([[4., 5.],
[7., 8.]])
#######################################################################
tensor([[2., 3.],
[5., 6.]])
#######################################################################
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]]]])
#######################################################################
tensor([[[[10.]]]])
#######################################################################
tensor([[[[ 5., 7.],
[13., 15.]]]])
#######################################################################
tensor([[[[ 1., 3.],
[ 9., 11.],
[13., 15.]]]])
#######################################################################
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]],[[ 1., 2., 3., 4.],
[ 5., 6., 7., 8.],
[ 9., 10., 11., 12.],
[13., 14., 15., 16.]]]])
tensor([[[[ 5., 7.],
[13., 15.]],[[ 6., 8.],
[14., 16.]]]])进程已结束,退出代码0