文章目录
- Paper1: Understanding User Satisfaction with Task-oriented Dialogue Systems
- Motivation:
- Classification:
- Contributions:
- Dataset
- Knowledge:
- Paper2: Evaluating Mixed-initiative Conversational Search Systems via User Simulation
- Motivation
- Classification:
- Contribution
- Methods
- Semantically-controlled text generation
- GPT2-based simulated user
- Datasets
- Qulac and ClariQ
- Multi-turn conversational data
- Future Work
- Knowledge
Paper1: Understanding User Satisfaction with Task-oriented Dialogue Systems
Understanding User Satisfaction with Task-oriented Dialogue Systems:
Motivation:
The influence of user experience on the user satisfaction ratings of TDS in addition to utility.
Classification:
Use and propose some metrics to evaluate task-oriented dialogue system(TDS)
Contributions:
- add an extra annotation layer for the ReDial dataset
- analyse the annotated dataset to identify dialogue aspects that influence the overall impression.
- Our work rates user satisfaction at both turn and dialogue level on six fine-grained user satisfaction aspects, unlike previous research rating both levels on overall impression
- propose additional dialogue aspects with significant contributions to the overall impression of a TDS
Dataset
ReDial(recommendation dialogue dataset): a large dialogue-based human-human movie recommendation corpus
- operations on datasets: create an additional annotation layer for the ReDial dataset. We set up an annotation experiment on Amazon Mechanical Turk (AMT) using so-called master workers. The AMT master workers annotate a total of 40 conversations on six dialogue aspects(relevance, interestingness, understanding, task completion, efficiency, and interest arousal)
Knowledge:
Dialogue systems(DSs) has two categories:
- task-oriented dialogue systems(TSDs), evaluate on utility
- open-domain chat-bots, evaluate on user experience
Paper2: Evaluating Mixed-initiative Conversational Search Systems via User Simulation
Evaluating Mixed-initiative Conversational Search Systems via User Simulation:
Motivation
Propose a conversational User Simulator, called USi, for automatic evaluation of such conversational search system.
Classification:
Develop the User Simulator to answer clarifying questions prompted by a conversational system.
Contribution
- propose a user simulator, USi, for conversational search systemevaluation, capable of answering clarifying questions prompted by the search system
- perform extensive set of experiments to evaluate the feasibility of substituting real users with the user simulator
- release a dataset of multi-turn interactions acquired through crowdsourcing
Methods
Semantically-controlled text generation
We define the task of generating answers to clarifying questions as a sequence generation task. Current SOTA language models formulate the task as next-word prediction task:

Answer generation needs to be conditioned on the underlying information need:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BrlwpqFT-1668865889265)
- a i a_i ai is the current token of the answer
- a < i a_{<i} a<i are all the previous ones
- i n , q , c q in,q,cq in,q,cq correspond to the information need, initial query, current clarifying question
GPT2-based simulated user
- base USi in the GPT-2 model with language modelling and classification losses(DoubleHead GPT-2)
- learn to generate the appropriate seq through the language modelling loss
- distinguish a correct answer to the distractor one
Singel-turn responses:
-
GPT-2 input:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nQVLyGiP-1668865889266)(C:\Users\nishiyu\AppData\Roaming\Typora\typora-user-images\image-20221118203339781.png)]
- accept two seq as input: one with the original target answer in the end, the other with the distractor answer
Conversation history-aware model:
- history-aware GPT-2 input:
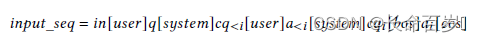
Inference:
- omit the answer a a a from the input seq.
- In order to generate answers, we use a combination of SOTA sampling techniques to generate a textual sequence from the trained model
Datasets
Qulac and ClariQ
both built for single-turn offline evaluation.
Qulac: (topic, facet, clarifying_question, answer). ClariQ is an extension of Qulac
facet from Qulac and ClariQ represents the underlying information need, as it describes in detail what the intent behind the issued query is. Moreover, question represents the current asked question, while answer is our language modelling target.
Multi-turn conversational data
we construct multi-turn data that resembles a more realistic interaction between a user and the system. Our user simulator USi is then further fine-tuned on this data.
Future Work
- a pair-wise comparison of multi-turn conversations.
- aim to observe user simulator behaviour in unexpected, edge case scenarios
- for example, people will repeat the answer is the clarifying question is repeated. We want USi to do so.
Knowledge
Datasets: Qulac, ClariQ
Multi-turn passage retrieval: The system needs to understand the conversational context and retrieve appropriate passages from the collection.
Document-retrieval task: the initial query is expanded with the text of the clarifying question and the user’s answer and the fed into a retrieval model.












![[附源码]java毕业设计日常饮食健康推荐系统](https://img-blog.csdnimg.cn/227469ec89164dc38d4e6f259a925653.png)