文章目录
- 一、简单的数据增强技术 EDA (Easy Data Augmentation) 即Normal Augmentation Method
- 1、`同义词替换`(Synonym Replacement, SR):
- 2、`随机插入`(Random Insertion, RI):
- 3、`随机交换`(Random Swap, RS):
- 4、`随机删除`(Random Deletion, RD):
- 5、`字符编辑`:
- 6、`基于模板生成`:
- 二、Normal Augmentation Method
- 1、`回译 (Back Translation)`:
- 2、`生成法`:
- 3、`文本对抗(Text Attack)`:
- 以下详细介绍一种无监督的数据增强技术(可以先不看):
- 损失
- 参考:
浅层的文本数据增强技术,主要是在词汇与字符上做变换。具有代表性的是 Easy Data Augmenter
一、简单的数据增强技术 EDA (Easy Data Augmentation) 即Normal Augmentation Method
EDA 的4个数据增强操作:
1、同义词替换(Synonym Replacement, SR):
从句子中随机选取n个不属于停用词集的单词,并随机选择其同义词替换它们;
2、随机插入(Random Insertion, RI):
随机的找出句中某个不属于停用词集的词,并求出其随机的同义词,将该同义词插入句子的一个随机位置。重复n次;
3、随机交换(Random Swap, RS):
随机的选择句中两个单词并交换它们的位置。重复n次;
4、随机删除(Random Deletion, RD):
以 p的概率,随机的移除句中的每个单词;
使用EDA需要注意:控制样本数量,少量学习,不能扩充太多,因为EDA操作太过频繁可能会改变语义,从而降低模型性能。
5、字符编辑:
在单词中随机删除、插入、替换字符或者交换两个字符次序,用于模拟输入错误。
6、基于模板生成:
这种方法需要从语料中挖掘一些模板。最简单的就是主被动句式变换、命名实体替换等。
二、Normal Augmentation Method
深层的数据增强技术,涉及到语义保持,主要是通过深度模型的语义编码实现的,常见方法有
1、回译 (Back Translation):
用机器翻译的方法将句子翻译成另外一种语言,然后再翻译回来。回译能够在保存语义不变的情况下,生成多样的句式,是无监督学习方法中常使用的语言增强技术。
2、生成法:
可以通过一些基于Transformer的比较好的语言模型去生成句子或者替换句子中的词,例如Fast Cross-domain Data Augmentation through Neural Sentence Editing先用一个编码器生成句子的的向量表示,然后基于这个向量生成新的句子。
3、文本对抗(Text Attack):
这种方法的初衷是通过生成增强的数据干扰分类器,让生成器与分类器对抗学习,从而提升分类器的鲁棒性。省略部分由于看不懂,所以跳过了,链接在此。
以下详细介绍一种无监督的数据增强技术(可以先不看):
无监督的数据增强技术UDA (Unsupervised Data Augmentation) 即一个半监督的学习方法,减少对标注数据的需求,增加对未标注数据的利用。
UDA关键解决的是如何根据少量的标注数据来增加未标注数据的使用。
Google在2019年提出了UDA方法(Unsupervised Data Augmentation 无监督数据增强),这是一种半监督学习方法。问世后,就击败了市面上其他的把深度半监督方法,该方法通过很少量的标记样本,便可以达到跟大数据样本一样的效果。
在UDA论文中,效果体现在IMDb数据集上,通过仅仅20个标记样本与约7万余个无标记样本(经过数据增强)的UDA算法学习,最终达到了与有2.5W标记数据集更好的效果,十分令人兴奋。
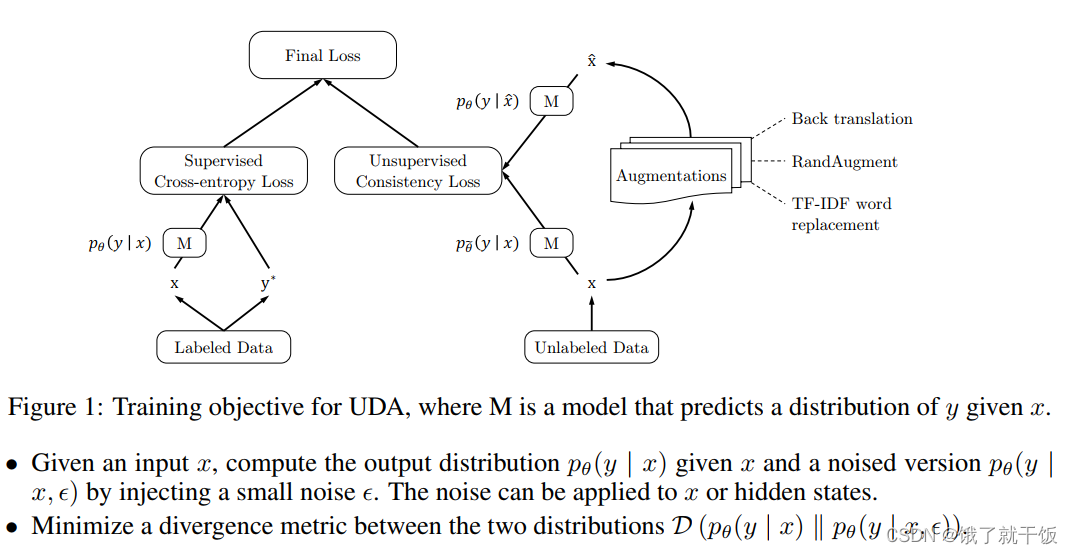
损失
如上面图,损失分为两部分:标记数据的损失 和 未标记的数据的损失
有标注样本:一部分为有标注样本的,计算交叉熵损失。 目标是最小化有标签数据的损失。
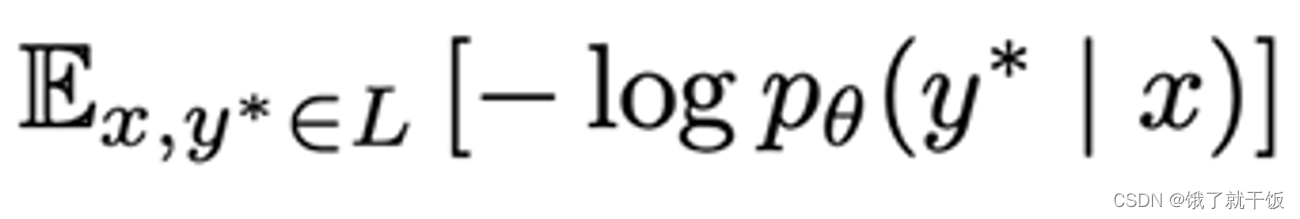
无标签样本:另一部分为无标签的损失
1、目标是什么?
目标是最小化无标签增广数据与无标签数据的KL散度
2、那么这部分无标签样本怎么得到的呢?
2.1 通过数据增强得到,何为数据增强呢?
数据增强就是,在样本x的标签L不变的情况下,对x进行转换,得到新的训练样本x’, 新样本x’的标签也是L。
2.2 转换方法都有哪些?
回译、TF-IDF word替换等等
3、损失定义
新旧数据有相同的数据标签。通常为了得到的增强数据与原始数据相似,使用的是最大似然估计方法。这里采用KL散度,算两个分布的损失:
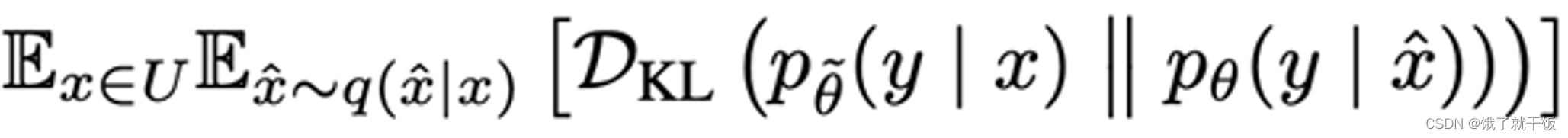
最终的损失为:
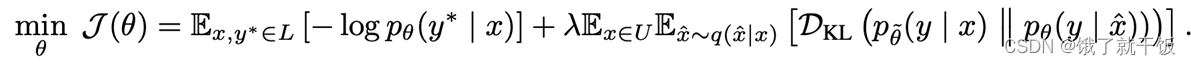
前面部分为有标签的损失部分,后半部分为无标签增强样本损失。
训练技巧
这个简书作者也没写
应用
在实际的场景下,UDA代表的半监督学习有十分广大的应用场景。例如,在某个细分领域,如金融领域,涵盖了大量的财经新闻、公司财报、法律文书、客户沟通记录等等,在该领域下没有标记的原始文本数据非常的庞大。而如果使用传统的监督学习方法,则需要十分昂贵而且专业的人员来进行数据样本的标记,这样的话,它的成本与项目进度将非常巨大与缓慢。但UDA类似的半监督学习恰好能近乎完美的解决这个问题。
参考:
NLP中常用的数据增强技术
NLP数据增强
UDA(Unsupervised Data Augmentation 无监督数据增强)


![[附源码]java毕业设计日常饮食健康推荐系统](https://img-blog.csdnimg.cn/227469ec89164dc38d4e6f259a925653.png)








![[计算机毕业设计]网络流量的在线恶意应用检测系统](https://img-blog.csdnimg.cn/632f16aceeee4be6a8443d20fb0be8d8.png)




![[附源码]java毕业设计实验教学过程管理平台](https://img-blog.csdnimg.cn/20d607f0ae424d9bb1d12ae09f2178f0.png)