文章链接: https://arxiv.org/pdf/2407.08674
github链接: https://still-moving.github.io/
Still-Moving

自定义文本生成图像(T2I)模型最近取得了巨大进展,尤其是在个性化、风格化和条件生成等领域。然而,将这些进展扩展到视频生成仍处于初期阶段,主要原因是缺乏定制视频数据。
本文介绍了Still-Moving,是一种无需定制视频数据即可自定义文本生成视频(T2V)模型的新颖通用框架。该框架适用于T2V模型的主要设计,其中视频模型是在文本生成图像(T2I)模型的基础上构建的(例如,通过扩展)。
假设能够访问仅在静态图像数据上训练的定制版本的T2I模型(例如,使用DreamBooth或StyleDrop)。直接将定制T2I模型的权重插入T2V模型通常会导致显著的伪影或对定制数据的依从性不足。为了解决这个问题,本文训练了轻量级的Spatial Adapters来调整由注入的T2I层产生的特征。重要的是,Adapters是在“冻结视频”(即重复图像)上训练的,这些视频是由定制T2I模型生成的图像样本构建的。
这种训练通过一种新颖的Motion Adapters模块得以实现,能够在静态视频上进行训练,同时保留视频模型的运动先验。在测试时,移除Motion Adapter 模块,仅保留训练好的Spatial Adapters。这恢复了T2V模型的运动先验,同时遵循了定制T2I模型的空间先验。在包括个性化、风格化和条件生成在内的多种任务中展示了本文方法的有效性。在所有评估场景中,本文的方法无缝集成了定制T2I模型的空间先验和T2V模型提供的运动先验。
方法
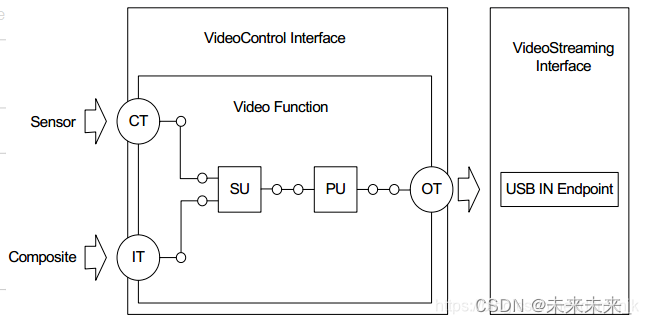
给定一个从T2I模型扩展而来的视频模型,以及一个从微调而来的定制T2I模型,本文的目标是实现将定制权重无缝插入V中。简单地将M替换为的方法由于特征分布的变化导致不满意的结果(下图2)。

为了缓解这种变化,本文提出训练轻量级的Spatial Adapters,这些Adapters的任务是将注入的层的输出激活投影回的时间层的分布。该方法的一个主要挑战是Adapters应该在定制视频数据上进行训练,而这种数据通常难以获得。注意,虽然静态图像可以复制形成(冻结)视频,但在这些冻结视频上进行原始训练会导致运动生成能力的丧失。为了解决这个问题,本文提出采用新颖的Motion Adapters来使能在图像数据上进行训练而不丧失模型的运动先验。
Motion Adapters
本文方法的一个关键组件是能够在冻结图像数据上训练视频模型V的权重。为了在不引入分布外输入的情况下实现这一目标,提出训练轻量级的Motion Adapters,以控制模型生成视频中运动的存在。Motion Adapters在普通、非定制的T2V模型上训练一次。本文的实现基于时间注意力投影矩阵的低秩适应(LoRA)(见下图3(a))

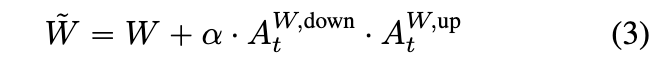
所有的 。这里, 是adapter scale,而 和 是adapter 矩阵。矩阵 以随机值初始化,而 初始化为零,这样在训练之前,模型等同于 。
在训练过程中,设置 ,并使用模型训练集中的一小部分视频。对于每个视频,随机选择一个帧,复制 次,并用扩散去噪目标训练adapter层。换句话说,Motion Adapters被训练生成展示从视频模型分布中复制的随机帧的冻结视频(见上面图3(a))。一旦训练完成,Motion Adapters就能够在冻结数据上训练视频模型权重。需要注意的是,通过设置 ,模型保留其生成运动的能力。
Motion Adapters控制运动量的能力可以推广到负尺度。例如,当设置 时,模型生成运动量增加的视频。因此,除了允许在图像上定制T2V模型外,Motion Adapters还可以在推理过程中用于控制生成视频中的运动量。
Spatial Adapters
本文方法的核心前提是特征分布的偏差可以通过简单的线性投影来修正。因此,建议在每个注入的定制T2I层之后添加Spatial Adapters(见上面图3(b))。这些adapters的任务是修正时间层输入的分布差距。因此,它们的训练需要通过整个视频模型传播梯度。与Motion Adapters类似,Spatial Adapters实现为低秩矩阵的乘法。
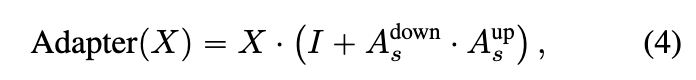
其中, 和 是特定层的低秩adapter矩阵。与Motion Adapters类似, 和 分别以随机值和零值初始化,这样在训练之前,模型等同于。使用扩散重建损失在图像和视频的组合上训练Spatial Adapters。具体来说,使用由定制T2I模型M1生成的图像和40个非定制视频来保留扩展模型的先验,按照DreamBooth 的方法进行(见上面图3(b))。对冻结视频使用尺度为 的Motion Adapters,对先验保留视频使用尺度为 的Motion Adapters。
实验
这里展示了广泛的定性和定量评估,并将本文的方法与主要baseline进行比较。在使用DreamBooth进行个性化和使用StyleDrop进行风格化的强大定制任务上进行了评估。此外,展示了本文的方法与ControlNet的结合,ControlNet能够在保持原始结构的同时,将现有视频定制为个性化对象或给定风格。在两个著名的扩展T2V模型上展示了结果,分别是基于Imagen构建的Lumiere和基于Stable Diffusion构建的AnimateDiff,以证明本文方法的鲁棒性。
Baselines
研究者们考虑了三种主要的baselines方法:
-
原始权重注入:在T2V模型中用定制T2I权重替换T2I模型权重,正如Guo等人和Liew等人所应用的那样;
-
权重插值:在定制权重和预训练T2I权重之间进行插值,正如Bar-Tal等人所应用的那样;
-
交错训练:受T2V训练常用方法的启发,使用以下方法微调视频模型中的T2I权重:(i) 禁用时间层的定制图像,和(ii) 启用时间层的自然视频。这个baseline方法与本文方法的关键区别在于,最终生成的视频没有像本文的方法框架那样,明确地使用定制图像数据进行监督。
评估数据
本文构建了一个包含个性化对象和风格的多样化数据集。对于个性化,包括了来自DreamBooth数据集的五个不同对象,包括现实的(例如狗、猫)和分布外的(例如玩具)对象。对于风格化评估,使用了Lumiere中展示的三种风格,另外还有两种具有挑战性的现实和高度详细的风格,见图4。每种风格都能够全面评估包含不同场景和对象的广泛提示。这构成了一个包含10种不同个性化对象和风格的数据集。对于数据集中的每个项目,生成了10个在相同随机种子和不同提示下的对比视频,共计每个baseline100个对比视频。
定性结果
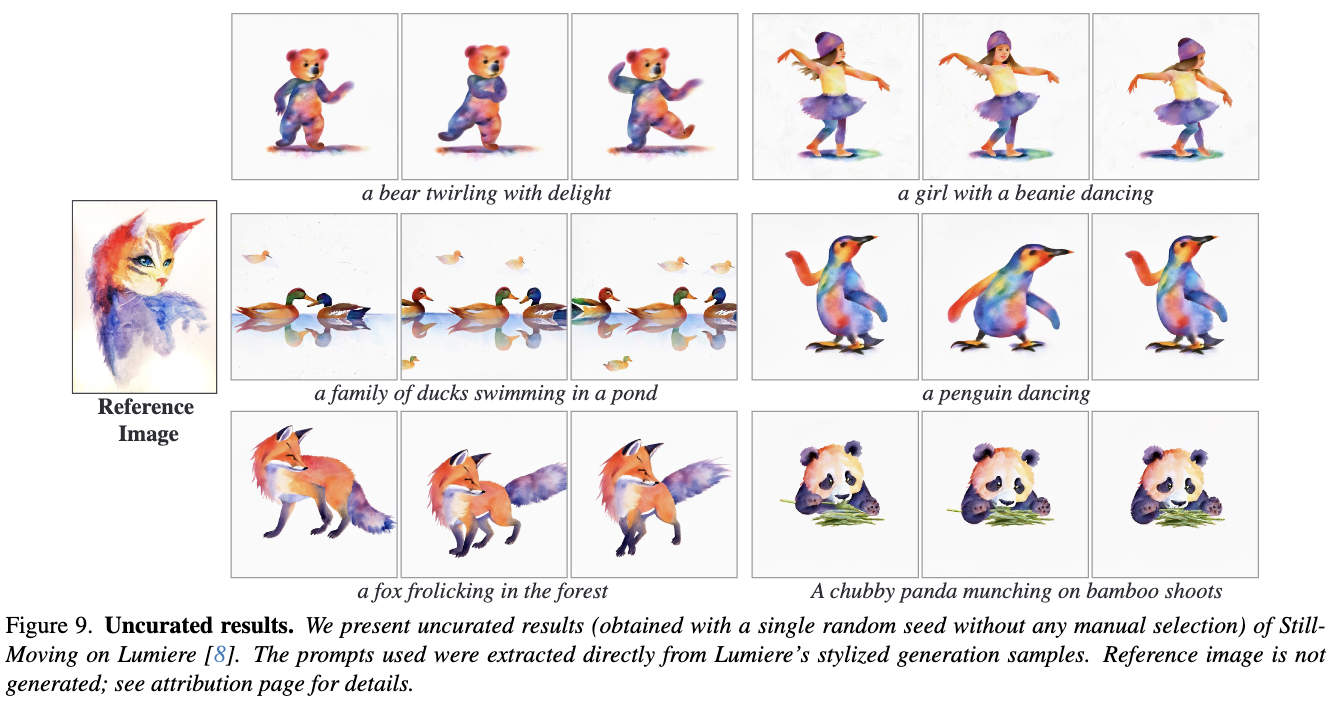
前面图1、下图4和图9展示了本文的方法在Lumiere上应用于视频个性化和风格化时,在各种具有挑战性的定制T2I模型上获得的结果。个性化角色来自Avrahami等人或由Google生成。同样,风格参考来自Hertz等人、Sohn等人或由Google生成。可以看出,本文的方法保持了M1的空间先验,同时匹配了来自V的创意运动先验。例如,“水彩飞溅”风格(图4(b))伴随着飞溅的颜色运动,“恐怖电影”风格(图4(b))结合了雾气运动等。对于个性化,本文的方法展示了对现实(例如图4(a)中的女人)和动画角色(例如图1中的猫)的内在动画能力,同时生成了多样的背景、场景和动态(例如冲浪、跳舞)。


下图13展示了本文的方法与在AnimateDiff上的原始注入baseline的定性比较。重要的是,AnimateDiff的作者强调了模型无缝插入微调T2I权重的能力。可以看出,这种方法对于复杂的定制数据往往会产生不满意的结果。对于风格化,“融化的金色”风格(顶部行)显示出背景失真,并且缺乏该风格特有的融化滴落效果。对于个性化,小松鼠的特征没有被准确捕捉(例如脸颊和前额的颜色)。此外,小松鼠的身份在不同帧中发生了变化。相比之下,应用本文的方法时,“融化的金色”背景与参考图像相匹配,模型生成了滴落的运动。同样,小松鼠保持了一致的身份,与参考图像相符。

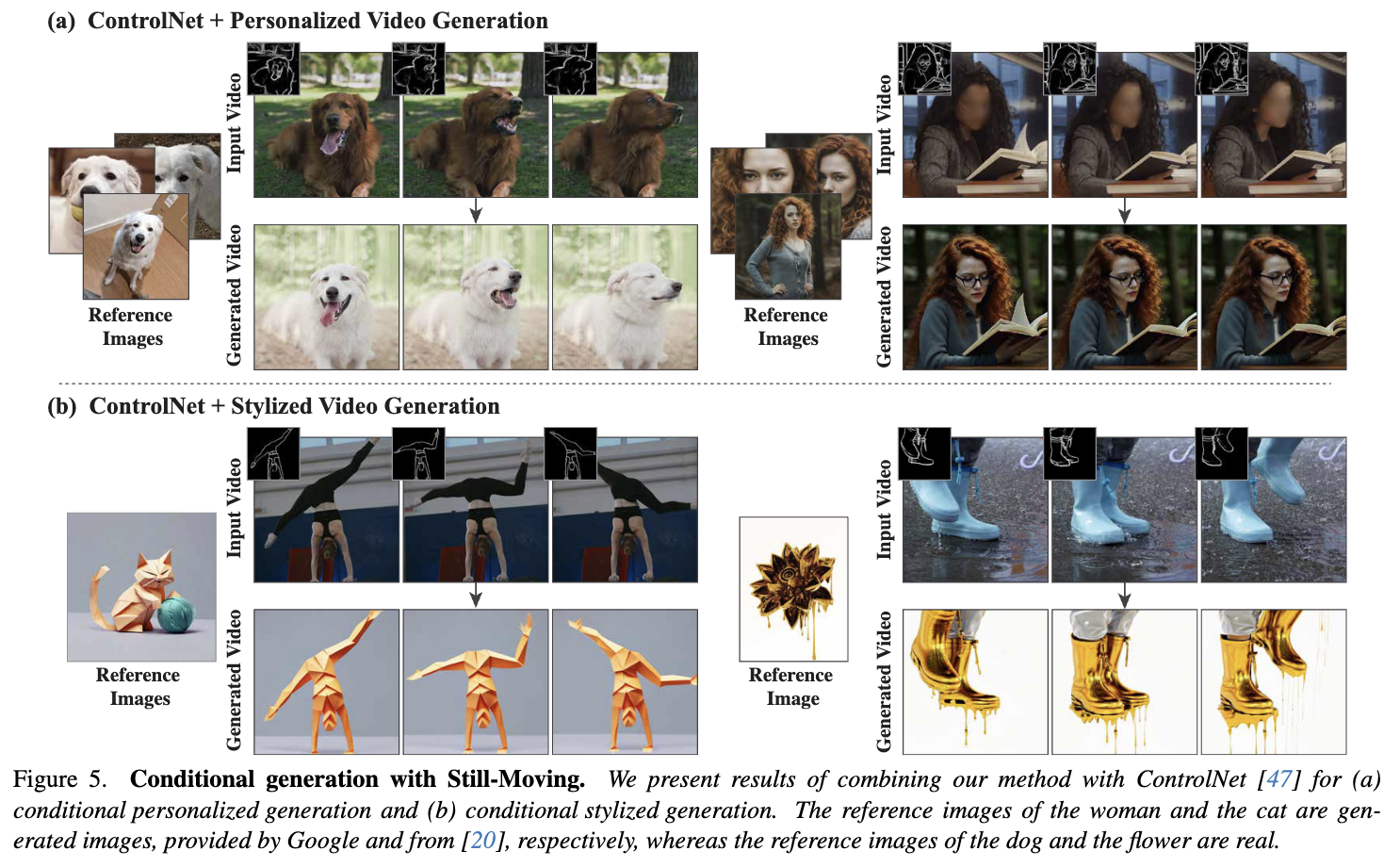
接下来,前面图1和下图5展示了本文的方法与ControlNet结合的结果。在给定驱动视频的情况下,本文的方法能够生成一个遵循其结构的定制视频,同时加入风格或角色。例如,图5顶部一行的视频被转换为展示参考女性形象,同时保持驱动视频的主要特征。有趣的是,ControlNet与Still-Moving的结合不仅能加入由条件决定的运动,还能加入由风格决定的动态运动。例如,图5中的“融化的金色”风格为场景添加了滴落的运动。
下图6展示了本文的方法与领先的baseline方法(即插值和交错训练)在评估数据集示例上的定性比较。可以看到,插值baseline在插值过程中本质上丢失了M1的信息。这在图6中的个性化示例中最为明显,插值过程中狗的身份丢失了。此外,可以看到插值并不总是足以克服分布差距,可能会保留显著的伪影。交错训练baseline在两种情况下都无法准确捕捉参考图像。这可以归因于baseline方法使用定制数据来修改模型的T2I层,同时忽略了时间层。如前面图2所示,微调后的空间层与预训练的时间层的结合经常会导致分布偏移,从而导致无法严格遵循定制数据。

定量结果
通过自动指标和用户研究对baseline方法进行了定量比较。
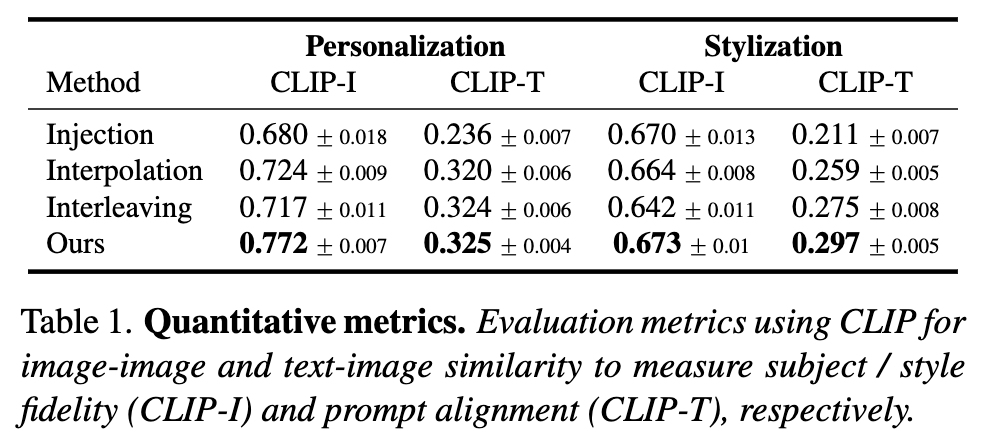
指标。根据图像定制领域类似工作的常见做法,研究者们考虑每帧相对于驱动提示的CLIP文本-图像相似度(CLIP-T)和每帧相对于定制数据的图像-图像相似度(CLIP-I)。在数据集的两个子集(个性化、风格化)上的自动评估结果报告在下表1和图7(a)、(b)中。本文的方法在所有评估子集和所有评估标准上均显著优于所有baseline方法,如图7和表1中报告的标准误差(SME)所示。图7中的趋势与在定性比较(上图6)中观察到的趋势类似。插值和注入baseline在风格化方面表现更好,这可以归因于个性化T2I模型的更大分布差距。相反,交错训练baseline无法适应新风格,因为它仅在定制数据上训练T2I模型权重。
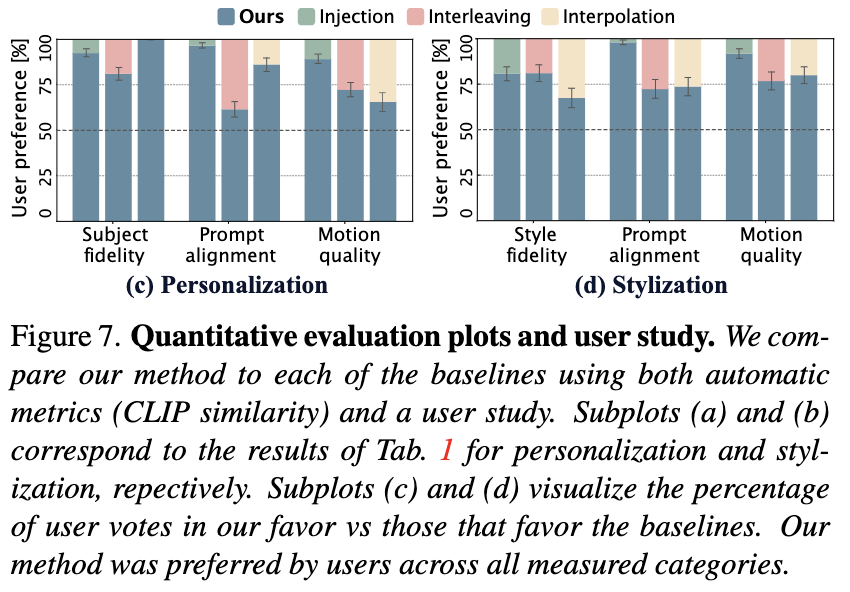
重要的是,简单地使用定制T2I模型生成单个图像并将其复制形成冻结视频,可以获得非常高的CLIP-I和CLIP-T分数。在缺乏评估生成运动质量的运动指标的情况下(正如多篇工作指出的[8, 16, 21]),采用用户研究进一步评估生成视频的质量。研究有31名参与者,每位参与者需对包含3个问题的20个比较进行投票。这共计1860票。在每个比较中,参与者会看到两个随机选自比较数据集的视频——一个由本文的方法生成,另一个由baseline生成,两个视频都描绘了相同的参考主体/风格,并使用相同的提示和种子生成。参与者被要求回答3个问题:
-
“哪个视频更好地遵循了提供的参考图像?”
-
“哪个视频与提供的文本提示更一致?”
-
“哪个视频显示了更好的运动质量?”。
如上如图7(c)、(d)所示,用户研究结果在主体保真度和提示一致性方面与自动指标一致。此外,研究表明,与baseline方法相比,本文的方法生成的视频在运动质量方面显著优越,如SME所示。
消融研究
对方法的三个主要设计选择进行了消融实验,即(i)应用Motion Adapters,(ii)应用Spatial Adapters,和(iii)使用先验保持损失。下图8展示了这些消融的结果。当移除Motion Adapters并在静态视频上训练时,模型生成的几乎是静态视频(顶行)。当移除Spatial Adapters并改为训练所有网络权重时,观察到运动仍然显著减少(第二行),并且背景不那么多样化。这可以归因于优化参数数量的显著增加,即使在存在Motion Adapters的情况下,模型也容易过拟合。这两个消融实验表明,本文方法的两个主要新颖组件都是获得有意义运动结果所必需的。最后,当移除先验保持组件时(图8第三行),模型在一定程度上失去了泛化能力,例如在图8第一列中,小松鼠没有戴帽子。此外,发现先验保持有助于模型更好地保持其运动先验,没有它,运动有所减少。

限制
本工作实现了定制T2I权重向T2V模型的即插即用注入。因此,结果本质上受限于定制T2I模型的结果。例如,当T2I模型未能准确捕捉定制对象的某些特征时,本文模型生成的视频可能会表现出类似的行为。同样,如果T2I定制模型对场景背景过拟合,本文的方法往往会产生类似的过拟合(图10)。

结论
文本到视频(T2V)模型变得越来越强大,现在可以生成复杂的高分辨率电影镜头。然而,如果生成的内容能够被整合到包含特定角色、风格和场景的更大叙事中,这些模型在实际应用中的潜力才能得到充分实现。因此,视频定制任务变得至关重要,但实现这一目标的方法论仍然探索不足。
这项工作克服了实现这一目标的一个主要挑战,即缺乏定制视频数据。开发了一个新颖的框架,直接将图像领域的巨大进展转化到视频领域。重要的是,本文的方法是通用的,可以应用于任何基于预训练的T2I模型构建的视频模型。本文的框架揭示了T2V模型所学习到的强大先验,正如成功生成从未见过运动的特定主题的运动所证明的那样。
参考文献
[1] Still-Moving: Customized Video Generation without Customized Video Data