美国国家健康与营养调查( NHANES, National Health and Nutrition Examination Survey)是一项基于人群的横断面调查,旨在收集有关美国家庭人口健康和营养的信息。
地址为:https://wwwn.cdc.gov/nchs/nhanes/Default.aspx
既往我们已经介绍过Nhanes临床数据库基线表的绘制,不少粉丝后台问非正态分布的数据怎么绘制基线表。今天来演示一下,继续使用文章《Nhanes临床数据库挖掘教程2—基线表绘制(table1)》中的数据,我们先导入数据
library(tableone)
library(survey)
bc<-read.csv("E:/nhanes/nhanes.csv",sep=',',header=TRUE)
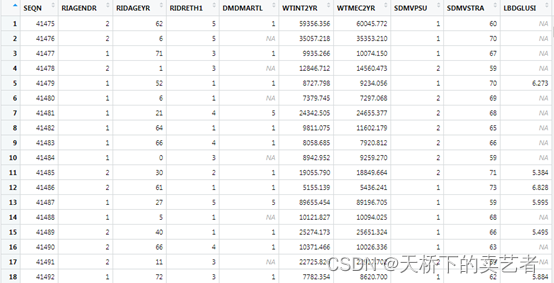
我介绍一下数据,SEQN:序列号,RIAGENDR, # 性别, RIDAGEYR, # 年龄,RIDRETH1, # 种族,DMDMARTL, # 婚姻状况,WTINT2YR,WTMEC2YR, # 权重,SDMVPSU, # psu,SDMVSTRA,# strata,LBDGLUSI, #血糖mmol表示,LBDINSI, #胰岛素( pmmol/L),PHAFSTHR #餐后血糖,LBXGH #糖化血红蛋白,SPXNFEV1, #FEV1:第一秒用力呼气量,SPXNFVC #FVC:用力肺活量,ml(估计肺容量),LBDGLTSI #餐后2小时血糖。
按照论文:Non-linear association between diabetes mellitus and pulmonary function: a population-based study的介绍

它的基线表是分为正常患者、糖尿病前期,糖尿病3个类型,
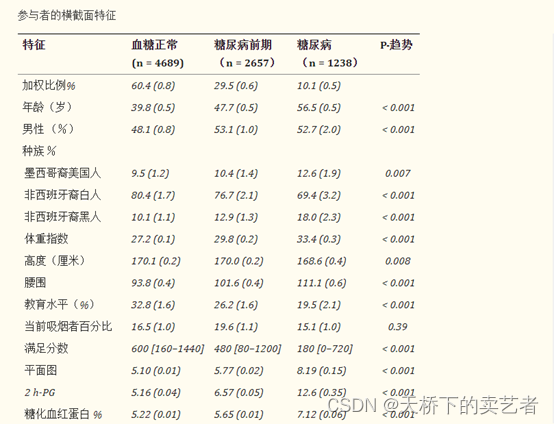
但是文中没有给出是怎么分类判断的,我就按照OGTT来随便分一下

OCTT小于7.8算是正常患者,7.8—11是糖尿病前期,大于11为糖尿病
bc$oGTT2<-ifelse(bc$LBDGLTSI<7.8,1,ifelse(bc$LBDGLTSI>=11,3,2))
上面代码的意思是把小于7.8的分类为1,大于11的分类为3,其余分类为2
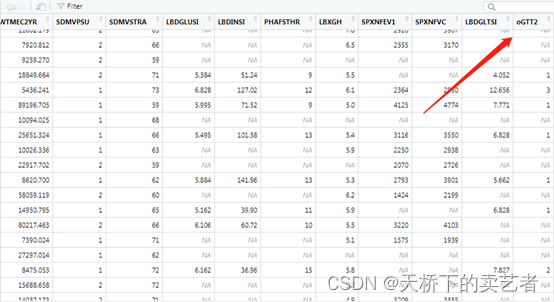
下面开始建立抽样调查函数svydesign,ids表示集群的意思,这里填入抽样单元SDMVPSU(PSU),如果没有的话填入1,strata = ~ SDMVSTRA,strata这里是分层的意思,这里填入SDMVSTRA,weights是权重的意思,参照别的大佬的意思,如WTINT2YR,WTMEC2YR,这两个权重就填入WTMEC2YR,data填入你的数据就可以了
bcSvy2<- svydesign(ids = ~ SDMVPSU, strata = ~ SDMVSTRA, weights = ~ WTMEC2YR,
nest = TRUE, data = bc)
接下来就是绘制基线表,使用的是svyCreateTableOne函数,先要定义全部变量和分类变量
dput(names(bc))##输出变量名
allVars <-c("RIAGENDR", "RIDAGEYR", "RIDRETH1", "DMDMARTL",
"LBDGLUSI", "LBDINSI", "PHAFSTHR",
"LBXGH", "SPXNFEV1", "SPXNFVC", "LBDGLTSI", "oGTT2")###所有变量名
fvars<-c("RIAGENDR", "RIDRETH1","DMDMARTL")#分类变量定义为fvars
绘制表格,我们是使用正常患者、糖尿病前期、糖尿病来分成比较的,所以strata填入oGTT2
Svytab2<- svyCreateTableOne(vars = allVars,
strata = "oGTT2",
data =bcSvy2 ,
factorVars = fvars)
Svytab2

假设"SPXNFEV1", "SPXNFVC"这两个变量为非正态分布的变量,我们先给它定义一下
bb<- c("SPXNFEV1","SPXNFVC")
变为非正态分布很容易,就是一句代码
tab3<-print(Svytab2, factorVars=fvars,nonnormal=bb)
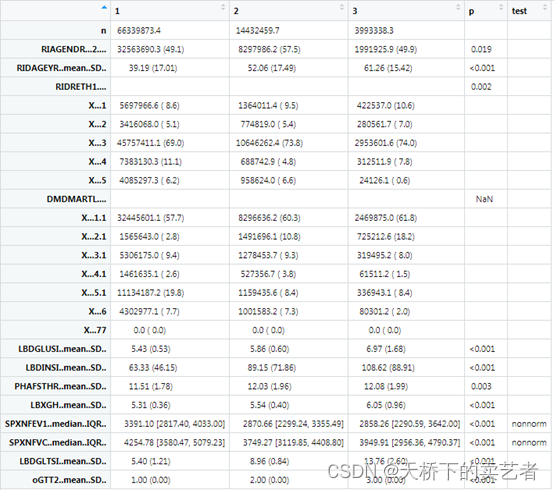
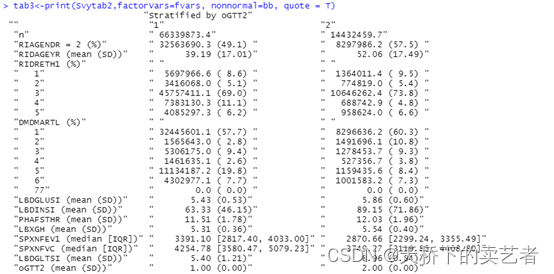
如果设置quote = T,则会给变量加上双引号,这样可以轻易复制到excel(作者的原话)
tab3<-print(Svytab2,factorVars=fvars, nonnormal=bb, quote = T)
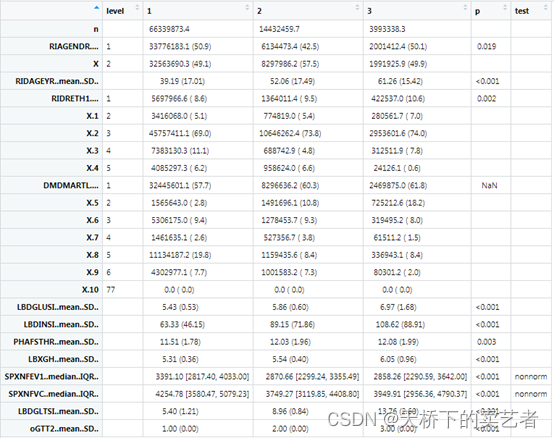
如果设置showAllLevels = T将会显示所有分类级别
tab3<-print(Svytab2,factorVars=fvars, nonnormal=bb, quote = F,showAllLevels = T)
加上smd = T可以显示smd
tab3<-print(Svytab2, factorVars=fvars,nonnormal=bb, quote = F,showAllLevels = T,smd = T)
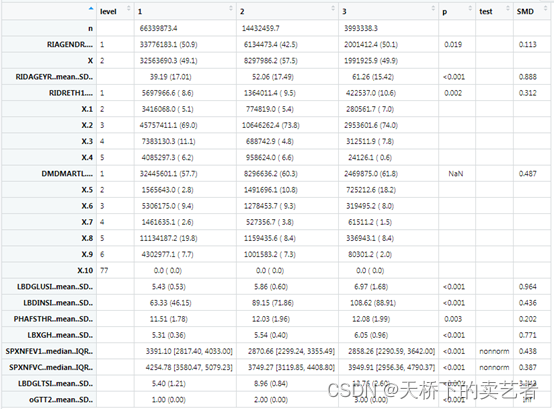
加上missing = T,可以显示缺失信息
tab3<-print(Svytab2,factorVars=fvars, nonnormal=bb, quote = F,showAllLevels = T,smd = T,missing = T)
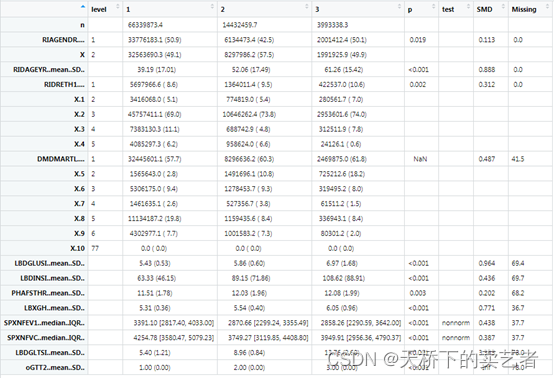
好了本期介绍到这里,如果想进一步了解参数,可以使用
?print.svyCatTable