目录
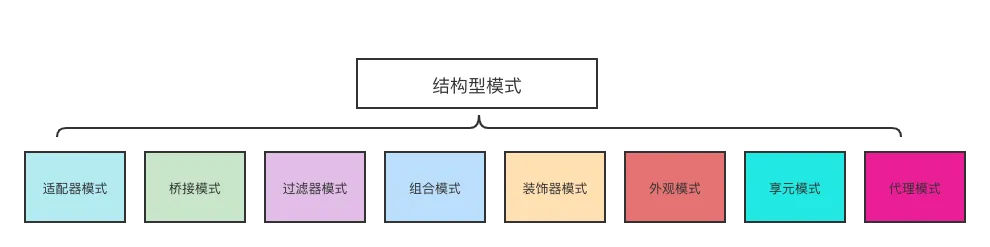
进程状态:
tracing stop:追踪暂停状态
Z:僵尸状态:
为什么要有僵尸进程呢?
孤儿进程
进程优先级:
其他概念:
进程切换:
pc/eip
环境变量:
PATH:全局的环境变量
echo +$:
history显示最近使用的指令:
env查看所有的环境变量
进程状态:
tracing stop:追踪暂停状态
我们使用Linux来理解tracing stop状态。
![]()
我们首先创建一个源文件,我们再创建一个文件makefile,makefile是该源文件对应的项目方案,我们先对makefile进行vim编辑操作。
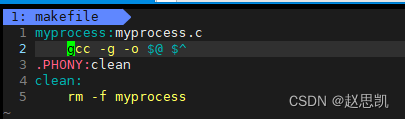
-g 表示生成调试信息,表示该可执行程序是可以被调试的
我们的依赖关系是myprocess依赖于源文件myprocess.c,$@对应的是左依赖列表,也就是myprocess,$^对应的是右依赖列表,对应的是myprocess.c
.PHONY表示我们的依赖关系是一个伪目标,我们不需要关心依赖关系,我们来看依赖方法:依赖方法是强制删除myprocess文件,并且.PHONY修饰的目标总是被执行。
接下来,我们对源文件进行文本编辑
我们的源文件只是打印几句话。
输入make指令,再调用可执行程序:

接下来,我们使用gdb指令进行调试:
![]()

我们在第八行打一个断点
![]()
接下来,我们使用r指令,表示把调试指针跳转到断点位置。
接下来,我们复制ssh渠道,然后通过行过滤查看名字中文件名含有myprocess的进程。

这时候,我们的进程状态是t,t状态就表示该进程正在被调试。
t是tracing的缩写,表示我们的进程正在被调试
Z:僵尸状态:
为什么要有僵尸进程呢?

僵尸进程的定义:一个进程正常的退出,但是没有被回收(父进程或者操作系统),那么该进程就是僵尸进程
那么我们如何对僵尸进程进行实验呢?
答:我们创建一个子进程,然后对父进程不处理,让子进程正常退出。
我们进行实验:
我们的思路是调用fork函数:


fork函数的作用是创建一个子进程,假如函数调用成功的时候,子进程的pid返回给父进程,并且把0返回给子进程,失败的话,-1返回给父进程,子进程不会被创建,并且设置对应的错误信息。
我们进行实验:
我们首先对没有process.c的文件进行文本编辑

exit函数可以退出一个进程。
当id为0时,就表示该语句中的进程是子进程,如果id不为0,就表示该进程是父进程
当id为0时,我们打印子进程的pid和ppid,然后休眠五秒,退出该进程。
当id不为0时,我们让父进程执行死循环:打印父进程的pid和ppid,然后休眠。
这样,子进程就会退出,但是父进程会一直运行。
![]()
接下来,我们调用可执行程序:
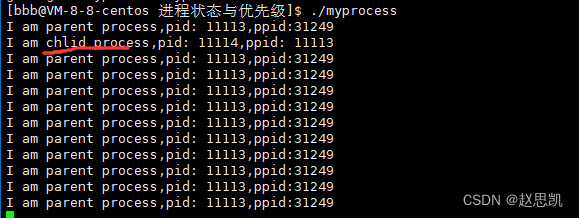
随着进程的运行,我们发现,子进程已经退出,但是父进程一直在不停的运行。
我们查看进程的详细信息:
![]()
我们的该条指令进行讲解:while :;do表示死循环显示,ps axj表示显示进程,head -1表示显示进程的标题,grep myprocess表示行过滤myprocess,grep -v表示过滤掉grep指令对应的进程,sleep表示休眠一秒。

这里的z就表示僵尸进程:


上面的进程是父进程,下面的进程是子进程,父进程继续运行,子进程已经退出,但是资源还没有被回收,这时候的子进程就是僵尸进程。
接下来,我们退出myprocess

然后再看对应的进程信息

这时候,什么都不显示了。
父进程对僵尸进程没有回收会导致内存泄漏
僵尸进程:进程退出并且父进程没有读取到子进程的返回代码时会产生僵尸进程。
僵尸进程会以终止状态保持在进程表,并且一直等父进程来回收返回代码。
只要子进程已经退出,父进程还在运行,但父进程没有读取到子进程的返回代码,该子进程就是僵尸进程。
僵尸进程的危害
僵尸进程的退出状态会被维持下去,直到父进程回收子进程的返回代码,但是父进程一直没有回收,维护退出状态本身就是一个进程数据,所以我们也要维持PCB。
一个父进程创建了很多子进程,子进程退出但是父进程不回收,就会造成内存资源的浪费。
孤儿进程
父进程先退出,剩下的子进程就是僵尸进程
我们进行实验:
我们对myprocess进行文本编辑:
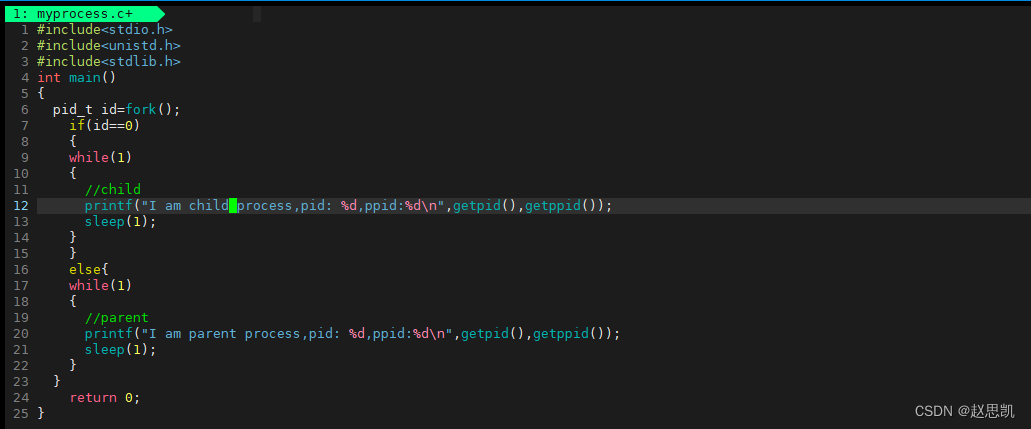
make之后,调用可执行程序:
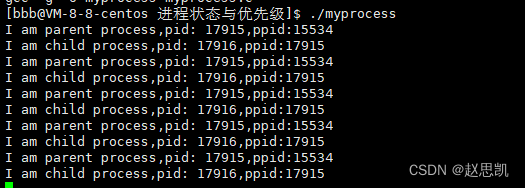
首先,我们可以先实验僵尸进程:
我们先找到子进程对应的pid
![]()
我们使用kill指令杀掉该子进程:

这时候,这个子进程就变成了僵尸进程。
我们接下来,实验孤儿进程。
我们重新调用可执行程序
![]()
![]()
我们杀掉父进程:
![]()
接下来,查看进程状态:
![]()
我们这里有一个问题:无论是父进程,还是子进程,都有自己对应的父进程,那么我们杀掉我们的父进程,这个父进程依然有他自己的父进程,为什么没有出现僵尸进程呢?
答:我们杀掉的这个进程的父进程是bash,bash及时的把该进程的资源回收了,所以没有出现僵尸进程。
![]()
我们杀掉这个进程对应的父进程之后,这个进程的父进程的pid就变成了1,这里的1指的是操作系统,这里的1号进程就是操作系统,1号进程领养的这个子进程就叫做孤儿进程。
为什么操作系统要成为孤儿进程的父进程呢?
答:这是必须的,因为该子进程的父进程已经死亡,假如操作系统不干预的话,当该子进程结束的时候,因为没有父进程对资源进行回收,该子进程就变成了僵尸进程,所以我们的操作系统及时的接手了这个子进程,当子进程结束的时候,对其资源进行回收。
我们发现,原来的子进程变成了孤儿进程,它的进程状态由原来的S+变成了S,表示当子进程变成孤儿进程时,该子进程会变成后台进程
后台进程的特点:
1:我们无法通过CTRL+c退出后台进程:

2:进程在运行时,我们依旧可以运行指令:

3:该进程只能被kill指令杀死。
总结:
孤儿进程:当子进程存在,父进程退出时,该子进程就变成了孤儿进程
孤儿进程的特点:
1:孤儿进程由操作系统领养,领养的原因是为了防止孤儿进程退出之后,由于没有对孤儿进程的资源回收导致该进程变成僵尸进程。
2:前台进程创建的子进程,假如该子进程变成了孤儿进程后,孤儿进程会变成后台进程。
进程优先级:
问题1:什么叫做优先级?
答:我们进行思考:权限和优先级是什么关系:首先,权限限制了能做与不能做,例如:只读的文件就不能进行写。优先级则是先做和晚做的问题。
问题2:为什么存在优先级?
答:因为资源太少了,这里的资源指的是cpu,我们的cpu很少,所以我们要把重要的进程的优先级设置的高一些,不重要的进程的优先级设置的低一些。
我们来查看优先级:

PRI和NI一起决定进程的优先级。
我们进行实验:
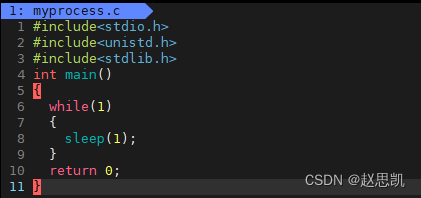
我们写一个简单的死循环程序。
make之后,我们调用该可执行程序
![]()

我们显示所有进程的详细信息。
我们发现,所有的进程的PRI和NI的值都一样。
我们要知道,PRI和NI的全拼英文,方便我们理解:
PRI是单词priority的缩写,这个单词的汉语是优先权
NI是单词nice的缩写,没什么具体的含义。
最终优先级=老的优先级+NICE
接下来,我们试着通过调整nice值来控制进程的优先级。

make之后,我们调用可执行程序:

我们输入top指令:
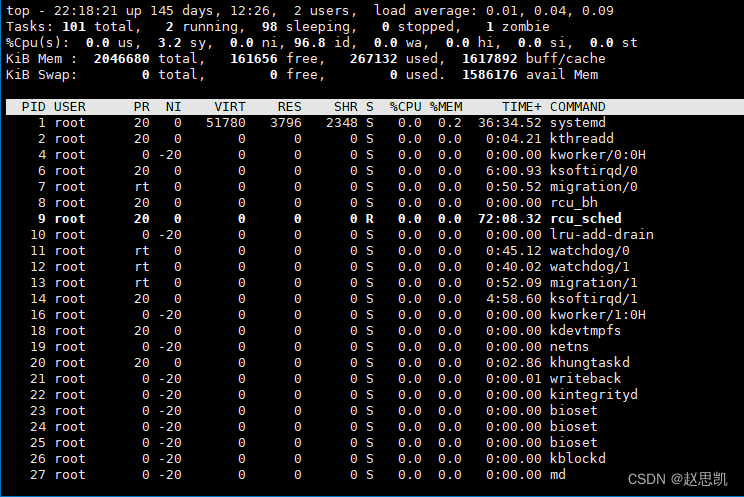
这里显示的是所有进程的优先级,然后我们输入r,这里的r是renice的缩写,表示重新输入nice值
![]()
这里的default的默认的意思,默认的pid是1450,我们输入我们调用程序的进程编号:
![]()
表示我们输入进程3342的nice值,我们先输入-100进行尝试:

但是我们发现该进程的NI值只有-20,因为NI的最小值是-20
我们重新设置NI,看看NI值的取值范围:
![]()
我们设置NI的值为100

所以NI的取值是[-20,19]
我们再把NI的值改成9试试:

所以PRI的初始值永远都是80。
最终优先级=原来的优先级(80)+NI值。
其他概念:
1:竞争性:系统进程数目众多,而cpu只有很少甚至只有一个,所以进程之间是存在进程属性的,进而引入了优先级。
2:独立性:多进程运行,需要独享各种资源,多进程之间互不干扰
3:并行:多个进程在多个cpu下同时运行,叫做并行
4:并发:多个进程在一个cpu下采用进程切换的方法,在一段时间内,让多个进程都得以推进,这就叫做并发。
我们提出一个问题:父子进程之间有独立性吗?
我们进行实验:
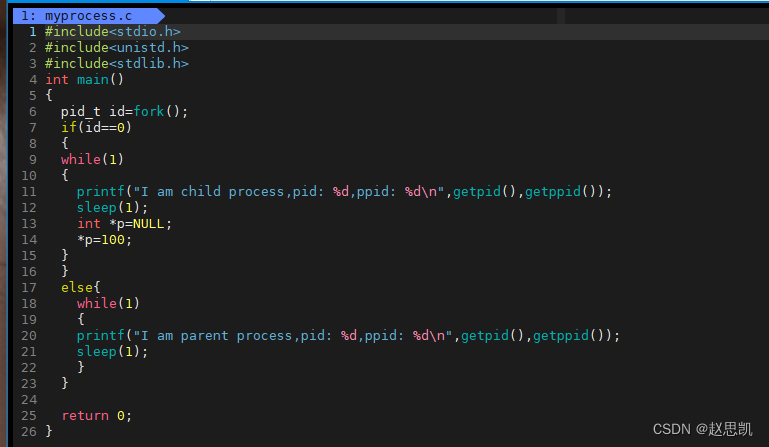
我们对myprocess.c进行文本编辑:
对于子进程,我们把指针p设置为空指针,对空指针的解引用会造成野指针的问题,程序会崩溃,我们make之后,对程序进行运行。
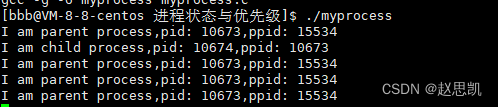
我们发现,子进程已经崩溃了,但是父进程依旧正常运行,所以父子进程之间也具有独立性。
进程切换:
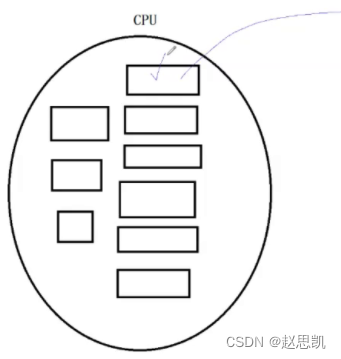
这个大圆代表的是cpu,小方框代表的是寄存器,一个cpu中有一整套寄存器。

当一个进程要运行时,首先把进程的pcb的地址加载到寄存器上,pcb上存储的是进程的属性,pcb指向进程的代码和数据,所以我们可以通过pcb来访问进程的数据,把进程上的数据放到寄存器上,方便cpu进行计算。
pc/eip
pc/eip是cpu上寄存器的一种,它上面存储的是当前执行指令的下一个指令的地址,我们通过pc/eip来实现指令的切换。
cpu只会做三件事情:取指令(pc/eip),分析指令,执行指令。
当我们的进程在运行的时候,一定会产生非常多的临时数据,这些临时数据存储在寄存器上,但是这些临时数据并不属于寄存器还是属于该进程
进程切换的理解:
进程在运行的时候,占有cpu,并非进程结束的时候,cpu才被释放,每一个进程在运行时,都有自己的时间片,当时间片到时,前一个进程会被剥离出cpu,下一个进程开始执行。
但是假如我们的前一个进程并没有执行完毕,我们执行后一个进程,这时候,当前一个进程回来时怎么办,难道让前一个进程重新执行吗?
答:并不是:进程切换是这样的:进程A首先在cpu上被执行,进程A在执行期间会产生很多的临时数据,这些临时数据存储在寄存器上,当进程A的时间片结束时,我们把寄存器上属于进程A的数据和代码的执行情况放置到进程A的PCB上,轮到进程B执行,当再次轮到进程A时,进程A的pcb会把进程A的数据和代码的执行情况重新返回给寄存器,然后cpu根据进程A代码的执行情况延续之前的继续执行。
当进程在切换时,要进行上下文的保护
当进程在恢复运行时,要进行上下文的恢复。
上下文指的是寄存器上存储的进程的数据和代码的执行情况。
保护指的是把进程的数据和代码的执行情况放置到进程的pcb中
恢复指的是把pcb中的进程的代码和数据放回到cpu上的寄存器中。
环境变量:
我们对myprocess.c进行文本编辑
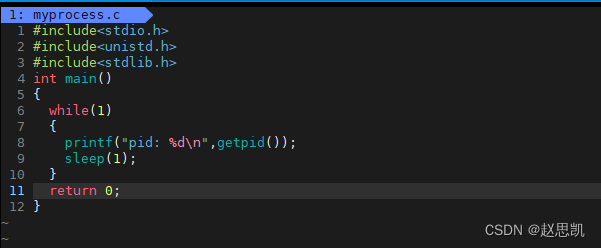
我们写一个死循环代码:
make之后,我们调用该可执行程序

我们发现一个问题:我们知道,这里的myprocess其实本质上也是指令,为什么myprocess的执行需要我们./,而普通的指令却不需要呢?
本质是这样的:要执行一个指令,首先要知晓指令所在的位置,./表示的是当前路径,表示我们myprocess指令的位置在当前路径,有了路径,我们就可以执行程序了。
假如我们想要不加上./就可以执行该指令的话,我们可以这样做:
![]()
表示把我们的指令拷贝到用户的指令集中,这样,相当于我们的指令的位置是可以被只晓得,我们直接输入指令就可以调用。

不建议这么干,因为我们的指令没有经过测试。
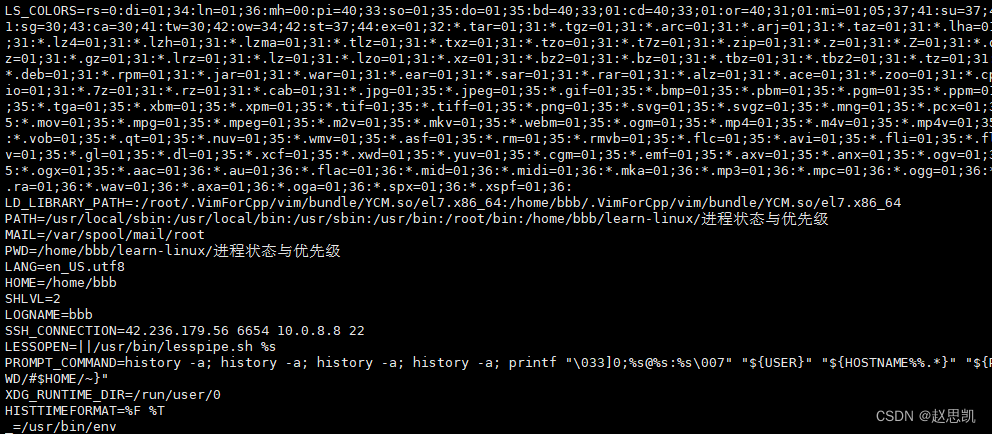
PATH:全局的环境变量
假如我们想要看全局的环境变量时,我们可以这样写:
![]()
这就是我们全局的环境变量。
假如我们不想用./调用进程的话,我们可以这样做
我们先显示当前位置的路径:
![]()
我们可以这样写:
![]()
这时候,我们不用./就可以调用myprocess

但是我们输入其他的指令却提示我们指令找不到了
![]()
因为我们把当前路径赋值给了环境变量,我们可以这样写:
![]()
表示把老的环境变量和当前位置赋值给新的环境变量,这样我们既可以调用myprocess,也可以使用普通指令了:

echo +$:

history显示最近使用的指令:
![]()
env查看所有的环境变量
![]()