文章目录
- 1.字符串中大小写字母的转变
- 2.字符串的左右中对齐
- 3.字符串查找的方法
- 4.字符串的替换
- 5. 字符串的判断
- 6.字符串的截取
- 7.字符串的拆分
- 8.字符串的拼接
- 9.格式化字符串
- 10.格式化字符串的语法
- 10.12.1 对齐选项([align])
- 10.2 填充选项([fill])
- 10.3 符号([sign])选项
- 10.4 精度([.precision])选项
- 10.5 类型([type])选项
- 10.7 灵活的玩法
- 10.8 f-字符串
1.字符串中大小写字母的转变
(1)capitalize():将首字母变成大写,其余的变成小写。
>>> x = "I love FishC"
>>> x.capitalize()
'I love fishc'
(2)casefold():全部字母小写化。
>>> x = "I love FishC"
>>> x.casefold()
'i love fishc'
(3)title():将每个单词的首字母都大写
>>> x = "I love FishC"
>>>> x.title()
'I Love Fishc'
(4)swapcase():将大小写翻转
>>> x = "I love FishC"
>>>> x.swapcase()
'i LOVE fISHc'
(5)upper()将所有字母都大写化
>>> x = "I love FishC"
>>> x.upper()
'I LOVE FISHC'
(6)lower()将所有字母小写化
>>> x = "I love FishC"
>>> x.lower()
'i love fishc'
2.字符串的左右中对齐
(1)center(width, fillchar=’ '):作用是中对齐;参数width表示一共有几个字符;可选参数fillchar,没有的时候自动填充空格,有事填充相应的字符。
>>> x = "有内鬼,停止交易!"
>>> x.center(15)
' 有内鬼,停止交易! '
>>> x.center(15, "淦")
'淦淦淦有内鬼,停止交易!淦淦淦'
(2)ljust(width, fillchar=’ ‘):作用是左对齐;参数同上。
(3)rjust(width, fillchar=’ '):作用是右对齐;参数同上。
(4)zfill(width):作用是右对齐,补充0,识别正负号
>>> x.zfill(15)
'000000有内鬼,停止交易!'
>>> "520".zfill(5)
'00520'
>>> "-520".zfill(5)
'-0520'
3.字符串查找的方法
(1)count(sub[, start[, end]]) 作用是:统计某个字符在字符串中有几个
参数
sub:表示要找的字符;中括号表示可选的参数
stat和end表示起始位置和终止位置。
>>> x = "上海自来水来自海上"
>>> x.count("海")
2
>>> x.count("海", 0, 5)
1
(2)find(sub[, start[, end]]) 作用是:从左往右寻找某个字符在字符串中的下标位置,找到第一个出现字符时,就立刻返回;找不到的时候放回-1
>>> x = "上海自来水来自海上"
>>> x.find("海")
1
(3)rfind(sub[, start[, end]]):从右往左
>>> x = "上海自来水来自海上"
>>> x.rfind("海")
7
(4)index(sub[, start[, end]])、rindex(sub[, start[, end]])和前面基本一样
和find不一样的是,当找不到元素的时候,会直接报错。
4.字符串的替换
(1)expandtabs()
首先是 expandtabs([tabsize=8]) 方法,它的作用是使用空格替换制表符并返回新的字符串。
>>> code = """
print("I love FishC.")
print("I love my wife.")"""
那么使用 expandtabs(tabsize=4) 方法,就可以将字符串中的 Tab 转换成空格,其中 tabsize 参数指定的是一个 Tab 使用多少个空格来代替:
>>> new_code = code.expandtabs(4)
>>> print(new_code)
print("I love FishC.")
print("I love my wife.")
>>>
(2)replace(old, new, count=-1) 方法返回一个将所有 old 参数指定的子字符串替换为 new 的新字符串。另外,还有一个 count 参数是指定替换的次数,默认值 -1 表示替换全部。
>>> "在吗!我在你家楼下,快点下来!!".replace("在吗", "想你")
'想你!我在你家楼下,快点下来!!'
(3)translate(table) 方法,这个是返回一个根据 table 参数(用于指定一个转换规则的表格)转换后的新字符串。
需要使用 str.maketrans(x[, y[, z]]) 方法制定一个包含转换规则的表格。
>>> table = str.maketrans("ABCDEFG", "1234567")
>>> "I love FishC.com".translate(table)
'I love 6ish3.com'
这个 str.maketrans() 方法还支持第三个参数,表示将其指定的字符串忽略:
>>> "I love FishC.com".translate(str.maketrans("ABCDEFG", "1234567", "love"))
'I 6ish3.cm'
5. 字符串的判断
判断是真与否,所以返回值都是True或False
(1)startswith(prefix[, start[, end]]) 方法用于判断 prefix 参数指定的子字符串是否出现在字符串的起始位置:
>>> x = "我爱Python"
>>> x.startswith("我")
True
>>> x.startswith("小甲鱼")
False
(2)对应的,endswith(suffix[, start[, end]]) 方法则相反,用于判断 suffix 参数指定的子字符串是否出现在字符串的结束位置:
>>> x.endswith("Python")
True
>>> x.endswith("C")
False
(1&2)对与这两种方法来说,参数里面都可规定起始位置。
这个 prefix 和 suffix 参数呀,其实是支持以元组的形式传入多个待匹配的字符串的:
>>> x = "她爱Pyhon"
>>> if x.startswith(("你", "我", "她")):
... print("总有人喜爱Pyhon")
...
总有人喜爱Pyhon
(3) istitle() 方法来判断一个字符串中是否所有单词的首字母都是大写的
>>> x = "I Love Python"
>>> x.istitle()
True
(4)isupper()方法判断一个字符串中所有的单词是否都是大写的
>>> x.isupper()
False
>>> x.upper().isupper()
True
相反,判断是否所有字母都是小写,用 islower() 方法,我们这里就不再赘述了。
(5)如果你希望判断一个字符串中是否只是由 ASCII 字符组成,可以使用 isascii() 方法进行检测:
>>> x.isascii()
True
>>> "我爱Pyhon".isascii()
False
(6)如果你希望判断是否为一个空白字符串,可以用 isspace() 方法进行检测:
>>> " \t\n".isspace()
True
(7)如果你希望判断一个字符串中是否所有字符都是可打印的,可以使用 isprintable() 方法:
>>> x.isprintable()
True
>>> "I love FishC\n".isprintable()
False
转义字符是不可以打印的
(8)isdecimal()、isdigit() 和 isnumeric() 三个方法都是用来判断数字的。
首先是十进制的数字:
>>> x = "12345"
>>> x.isdecimal()
True
>>> x.isdigit()
True
>>> x.isnumeric()
True
其次是罗马数字
>>> x = "ⅠⅡⅢⅣⅤ"
>>> x.isdecimal()
False
>>> x.isdigit()
False
>>> x.isnumeric()
True
接着是中文数字
>>> x = "一二三四五"
>>> x.isdecimal()
False
>>> x.isdigit()
False
>>> x.isnumeric()
True
最后是繁体的中文数字
>>> x = "壹贰叁肆伍"
>>> x.isdecimal()
False
>>> x.isdigit()
False
>>> x.isnumeric()
True
isalnum() 方法则是集大成者,只要 isalpha()、isdecimal()、isdigit() 或者 isnumeric() 任意一个方法返回 True,结果都为 True。
(8)isidentifier() 方法用于判断该字符串是否一个合法的 Python 标识符
>>> "I a good gay".isidentifier()
False
>>> "I_a_good_gay".isidentifier()
True
>>> "FishC520".isidentifier()
True
>>> "520FishC".isidentifier()
False
(i)就是如果你想判断一个字符串是否为 Python 的保留标识符,就是像 “if”、“for”、“while” 这些关键字的话,可以使用 keyword 模块的 iskeyword() 函数来实现:
>>> import keyword
>>> keyword.iskeyword("if")
True
>>> keyword.iskeyword("py")
False
6.字符串的截取
(1)lstrip(chars=None)、rstrip(chars=None)、strip(chars=None)
>>> " 左侧不要留白".lstrip()
'左侧不要留白'
>>> "右侧不要留白 ".rstrip()
'右侧不要留白'
>>> " 左右不要留白 ".strip()
'左右不要留白'
这三个方法都有一个 chars=None 的参数,None 在 Python 中表示没有,意思就是去除的是空白。
那么这个参数其实是可以给它传入一个字符串的:
>>> "www.ilovefishc.com".lstrip("wcom.")
'ilovefishc.com'
>>> "www.ilovefishc.com".rstrip("wcom.")
'www.ilovefish'
>>> "www.ilovefishc.com".strip("wcom.")
'ilovefish'
传入的字符串是以字符为单位来一个一个截取的
(2)如果只是希望踢掉一个具体的子字符串,应该怎么办?
那么你可以考虑 removeprefix(prefix) 和 removesuffix(suffix) 这两个方法。
它们允许你指定将要删除的前缀或后缀:
>>> "www.ilovefishc.com".removeprefix("www.")
'ilovefishc.com'
>>> "www.ilovefishc.com".removesuffix(".com")
'www.ilovefishc'
7.字符串的拆分
partition(sep)、rpartition(sep)、split(sep=None, maxsplit=-1)、rsplit(sep=None, maxsplit=-1)、splitlines(keepends=False)
(1)拆分字符串,言下之意就是把字符串给大卸八块,比如 partition(sep) 和 rpartition(sep) 方法,就是将字符串以 sep 参数指定的分隔符为依据进行切割,返回的结果是一个 3 元组(3 个元素的元组):
>>> "www.ilovefishc.com".partition(".")
('www', '.', 'ilovefishc.com')
partition(sep) 和 rpartition(sep) 方法的区别是前者是从左往右找分隔符,后者是从右往左找分隔符:
>>> "ilovefishc.com/python".partition("/")
('ilovefishc.com', '/', 'python')
注意:它俩如果找不到分隔符,返回的仍然是一个 3 元组,只不过将原字符串放在第一个元素,其它两个元素为空字符串。
(2)plit(sep=None, maxsplit=-1) 和 rsplit(sep=None, maxsplit=-1) 方法则是可以将字符串切成一块块:
>>> "苟日新,日日新,又日新".split(",")
['苟日新', '日日新', '又日新']
>>> "苟日新,日日新,又日新".rsplit(",")
['苟日新', '日日新', '又日新']
>>> "苟日新,日日新,又日新".split(",", 1)
['苟日新', '日日新,又日新']
>>> "苟日新,日日新,又日新".rsplit(",", 1)
['苟日新,日日新', '又日新']
参数sep表示切割标志,参数maxsplit表示切多少个标志,-1表示全部切割
(3)splitlines(keepends=False) 方法会将字符串进行按行分割,并将结果以列表的形式返回:
>>> "苟日新\n日日新\n又日新".splitlines()
['苟日新', '日日新', '又日新']
>>> "苟日新\r日日新\r又日新".splitlines()
['苟日新', '日日新', '又日新']
>>> "苟日新\r日日新\r\n又日新".splitlines()
['苟日新', '日日新', '又日新']
keepends 参数用于指定结果是否包含换行符,True 是包含,默认 False 则表示是不包含:
>>> "苟日新\r日日新\r\n又日新".splitlines(True)
['苟日新\r', '日日新\r\n', '又日新']
8.字符串的拼接
join(iterable) 方法是用于实现字符串拼接的。
虽然的它的用法在初学者看来是非常难受的,但是在实际开发中,它却常常是受到大神追捧的一个方法。
字符串是作为分隔符使用,然后 iterable 参数指定插入的子字符串:
>>> ".".join(["www", "ilovefishc", "com"])
'www.ilovefishc.com'
>>> "^".join(("F", "ish", 'C'))
'F^ish^C'
>>> "".join(("FishC", "FishC"))
'FishCFishC'
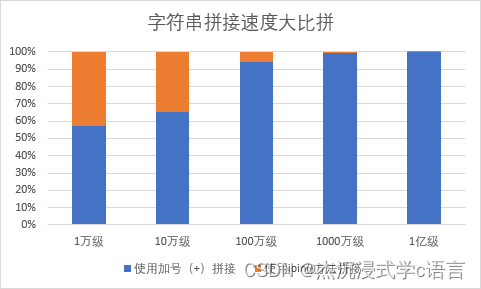
join()方法的速度快得多
9.格式化字符串
在字符串中,格式化字符串的套路就是使用一对花括号({})来表示替换字段,就在原字符串中先占一个坑的意思,然后真正的内容被放在了 format() 方法的参数中。
>>> year = 2010
>>> "鱼C工作室成立于 year 年。"
'鱼C工作室成立于 year 年。'
>>> "鱼C工作室成立于 {} 年。".format(year)
'鱼C工作室成立于 2010 年。'
>>> "1+2={}, 2的平方是{},3的立方是{}".format(1+2, 2*2, 3*3*3)
'1+2=3, 2的平方是4,3的立方是27'
在花括号里面,可以写上数字,表示参数的位置:
>>> "{1}看到{0}就很激动!".format("小甲鱼", "漂亮的小姐姐")
'漂亮的小姐姐看到小甲鱼就很激动!'
注意,同一个索引值是可以被多次引用的:
>>> "{0}{0}{1}{1}".format("是", "非")
'是是非非'
还可以通过关键字进行索引,比如:
>>> "我叫{name},我爱{fav}。".format(name="小甲鱼", fav="Pyhon")
'我叫小甲鱼,我爱Pyhon。'
当然,位置索引和关键字索引可以组合使用:
>>> "我叫{name},我爱{0}。喜爱{0}的人,运气都不会太差^o^".format("python", name="小甲鱼")
'我叫小甲鱼,我爱python。喜爱python的人,运气都不会太差^o^'
如果我只是想单纯的输出一个纯洁的花括号,那应该怎么办呢?
有两种办法可以把这个纯洁的花括号安排进去:
>>> "{}, {}, {}".format(1, "{}", 2)
'1, {}, 2'
>>> "{}, {{}}, {}".format(1, 2)
'1, {}, 2'
10.格式化字符串的语法
format_spec ::= [[fill]align][sign][#][0][width][grouping_option][.precision][type]
fill ::=
align ::= “<” | “>” | “=” | “^”
sign ::= “+” | “-” | " "
width ::= digit+
grouping_option ::= “_” | “,”
precision ::= digit+
type ::= “b” | “c” | “d” | “e” | “E” | “f” | “F” | “g” | “G” | “n” | “o” | “s” | “x” | “X” | “%”
10.12.1 对齐选项([align])
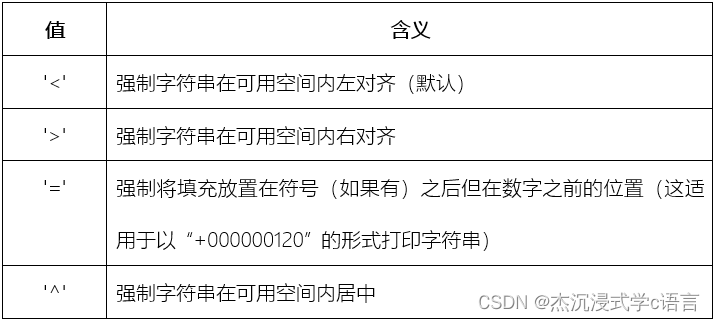
>>> "{:^}".format(250)
'250'
>>> "{:^10}".format(250)
' 250 '
>>> "{1:>10}{0:<10}".format(520, 250)
' 250520 '
>>> "{left:>10}{right:<10}".format(right=520, left=250)
' 250520 '
10.2 填充选项([fill])
在指定宽度的前面还可以添加一个 ‘0’,则表示为数字类型启用感知正负号的 ‘0’ 填充效果:
>>> "{:010}".format(520)
'0000000520'
>>> "{:010}".format(-520)
'-000000520'
注意,这种用法只对数字有效:
>>> "{:010}".format("FishC")
Traceback (most recent call last):
File "<pyshell#39>", line 1, in <module>
"{:010}".format("FishC")
ValueError: '=' alignment not allowed in string format specifier
还可以在对齐([align])选项的前面通过填充选项([fill])来指定填充的字符:
>>> "{1:%>10}{0:%<10}".format(520, 250)
'%%%%%%%250520%%%%%%%'
>>> "{:0=10}".format(520)
'0000000520'
>>> "{:0=10}".format(-520)
'-000000520'
10.3 符号([sign])选项
符号选项有三个选项:

10.4 精度([.precision])选项
精度([.precision])选项是一个十进制整数,对于不同类型的参数,它的效果是不一样的:
- 对于以 ‘f’ 或 ‘F’ 格式化的浮点数值来说,是限定小数点后显示多少个数位
- 对于以 ‘g’ 或 ‘G’ 格式化的浮点数值来说,是限定小数点前后共显示多少个数位
- 对于非数字类型来说,限定最大字段的大小(换句话说就是要使用多少个来自字段内容的字符)
- 对于整数来说,则不允许使用该选项值
10.5 类型([type])选项
类型([type])选项决定了数据应该如何呈现。
以下类型适用于整数:
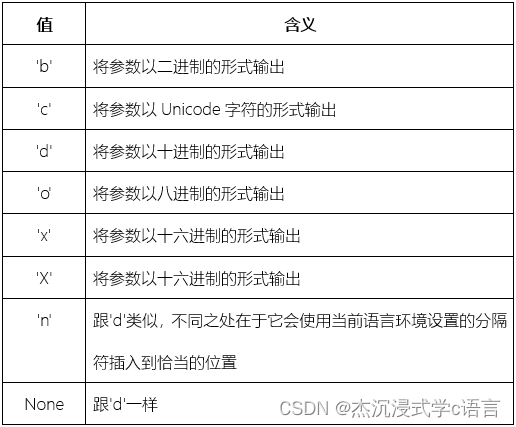
以下类型值适用于浮点数、复数和整数(自动转换为等值的浮点数)如下:
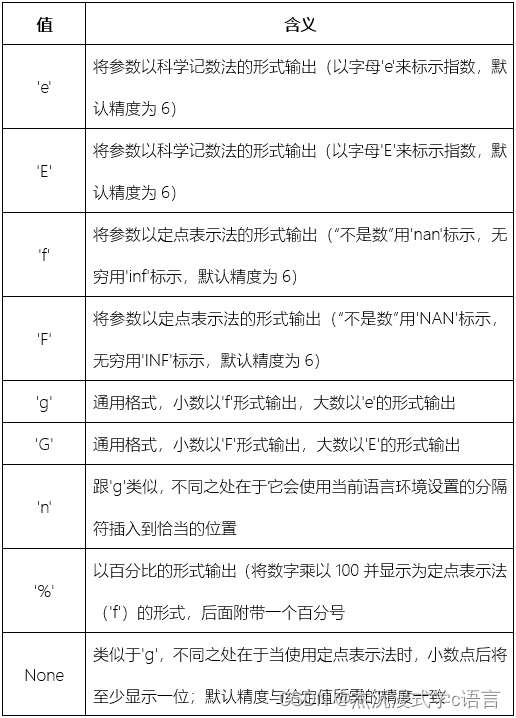
10.7 灵活的玩法
Python 事实上支持通过关键参数来设置选项的值,比如下面代码通过参数来调整输出的精度:
>>> "{:.{prec}f}".format(3.1415, prec=2)
'3.14'
同时设置多个选项也是没问题的,只要你自己不乱,Python 就不会乱:
>>> "{:{fill}{align}{width}.{prec}{ty}}".format(3.1415, fill='+', align='^', width=10, prec=3, ty='g')
'+++3.14+++'
10.8 f-字符串
Python 随着版本的更迭,它的语法也是在不断完善的。“简洁胜于复杂”是 Python 之禅中强调的理念。
因此,在 Python3.6 的更新中,他们给添加了一个新的语法,叫 f-string,也就是 f-字符串。
f-string 可以直接看作是 format() 方法的语法糖,它进一步简化了格式化字符串的操作并带来了性能上的提升。
注:语法糖(英语:Syntactic sugar)是由英国计算机科学家彼得·兰丁发明的一个术语,指计算机语言中添加的某种语法,这种语法对语言的功能没有影响,但是更方便程序员使用。语法糖让程序更加简洁,有更高的可读性。
来,我们使用 f-string 将前面讲解 format() 方法的例子给大家修改一遍,你就知道该怎么玩了:
>>> year = 2010
>>> f"鱼C工作室成立于 {year} 年"
'鱼C工作室成立于 2010 年'
>>>
>>> f"1+2={1+2}, 2的平方是{2*2},3的立方是{3*3*3}"
'1+2=3, 2的平方是4,3的立方是27'
>>>
>>> "{:010}".format(-520)
>>> f"{-520:010}"
'-000000520'
>>>
>>> "{:,}".format(123456789)
>>> f"{123456789:,}"
'123,456,789'
>>>
>>> "{:.2f}".format(3.1415)
>>> f"{3.1415:.2f}"
'3.14'