文章目录
- 感知机
- 简单感知机
- 基础形式
- 偏置值形式
- 逻辑门感知机
- 机器学习的任务
- (单层)感知机的局限@线性和非线性
- 多层感知机
- 从与非门到计算机
- 小结
- 从感知机到神经网络
- 激活函数🎈
- 非线性激活函数
- step 函数
- 阶跃函数的实现(numpy)
- sigmoid function
- sigmoid函数
- sigmoid 函数和阶跃函数的比较
- 图像
- 相同点
- 不同点
- ReLU 函数
- 神经网络的运算
- 实现神经网络
- 记号说明🎈
- 权重
- 神经元
- 使用上述符号表示公式
- 不考虑激活函数的简化版本
- 例
- 考虑激活函数
- 小结
感知机
简单感知机
- 人工神经元-朴素感知机
- 下面的形式考虑的是输入向量只含有2个分量的情况
基础形式
- T = T ( x , w ) = w 1 x 1 + w 2 x 2 = ( x 1 , x 2 ) ( w 1 w 2 ) y = { 0 ( T ⩽ θ ) 1 ( T > θ ) T=T(x,w)=w_{1} x_{1}+w_{2} x_{2} \\ =(x_1,x_2)\binom{w_1}{w_2} \\ y=\left\{\begin{array}{ll} 0 & \left(T \leqslant \theta\right) \\ 1 & \left(T>\theta\right) \end{array}\right. T=T(x,w)=w1x1+w2x2=(x1,x2)(w2w1)y={01(T⩽θ)(T>θ)
偏置值形式
-
y = { 0 , T − θ ⩽ 0 1 , T − θ > 0 取 b = − θ , 则形式进一步变为 : T = T ( x , w ) = w 1 x 1 + w 2 x 2 y = { 0 , T + b ⩽ 0 1 , T + b > 0 y=\begin{cases} 0,&T-\theta\leqslant{0}\\ 1,&T-\theta>0 \end{cases} \\取b=-\theta,则形式进一步变为: \\ T=T(x,w)=w_{1} x_{1}+w_{2} x_{2}\\ y=\begin{cases} 0,&T+b\leqslant{0}\\ 1,&T+b>0 \end{cases} y={0,1,T−θ⩽0T−θ>0取b=−θ,则形式进一步变为:T=T(x,w)=w1x1+w2x2y={0,1,T+b⩽0T+b>0
- 称b为偏置值
- 称 w 1 , w 2 w_1,w_2 w1,w2为权重
逻辑门感知机
-
实现与门的感知机
- 满足与门(and gate)的真值表的感知机参数取法有无穷多中,
- 例如取 ( w 1 , w 2 , θ ) = ( 0.5 , 0.5 , 0.7 ) (w_1,w_2,\theta)=(0.5,0.5,0.7) (w1,w2,θ)=(0.5,0.5,0.7),能够满足只有当 x 1 , x 2 = 1 , 1 x_1,x_2=1,1 x1,x2=1,1时才输出1
-
这里决定感知机参数的并不是计算机,而是我们人。我们看着真值表这种“训练数据”,人工考虑(想到)了参数的值。
机器学习的任务
-
而机器学习的课题就是将这个决定参数值的工作交由计算机自动进行。
- 学习是确定合适的参数的过程,而人要做的是思考感知机的构造(模型),并把训练数据交给计算机。
-
这里把 −θ命名为偏置 b,但是请注意,偏置和权重 w1、w2 的作用是不一样的。
- 具体地说,w1 和 w2 是控制输入信号的重要性的参数
- 假设输入参数
(
x
1
,
x
2
)
(x_1,x_2)
(x1,x2)分别对应权重参数为
w
1
,
w
2
w_1,w_2
w1,w2,
- 若 w 2 > w 1 w_2>w_1 w2>w1,说明, x 2 x_2 x2比 x 1 x_1 x1更加重要
- 假设输入参数
(
x
1
,
x
2
)
(x_1,x_2)
(x1,x2)分别对应权重参数为
w
1
,
w
2
w_1,w_2
w1,w2,
- 而偏置是调整神经元被激活的容易程度(输出信号为 1的程度)的参数。
- 某个分量 x i x_i xi权重参数 w i w_i wi很小或者很大,只能用于区分分量间的重要性,
- 神经元能否被激活(激活的难易程度)更直接的体现在偏置上(基础形式中的 θ \theta θ能直接体现这一点)
- 比如,
- 若 b为−0.1,则只要输入信号的加权总和超过 0.1,神经元就会被激活。
- 但是如果 b为 −20.0,则输入信号的加权总和必须超过 20.0,神经元才会被激活。
- 像这样,偏置的值决定了神经元被激活的容易程度。
- 另外,这里我们将 w1 和 w2 称为权重,将 b称为偏置,
- 但是根据上下文,有时也会将 b、w1、w2 这些参数统称为权重。
- 具体地说,w1 和 w2 是控制输入信号的重要性的参数
(单层)感知机的局限@线性和非线性
-
上述的模型无法处理异或门(XOR gate)
-
可以建立二维坐标 x 2 O x 1 x_2Ox_1 x2Ox1
- 直线
f
(
x
1
,
x
2
)
=
∑
i
=
1
2
w
i
x
i
=
θ
f(x_1,x_2)=\sum\limits_{i=1}^{2}w_ix_i=\theta
f(x1,x2)=i=1∑2wixi=θ无法将点
(
0
,
0
)
和
(
1
,
1
)
(0,0)和(1,1)
(0,0)和(1,1)归为
⩽
θ
\leqslant{\theta}
⩽θ同时还把
(
0
,
1
)
,
(
1
,
0
)
(0,1),(1,0)
(0,1),(1,0)归为
>
θ
>{\theta}
>θ
- 0 + 0 = θ 0+0=\theta 0+0=θ
- w 1 + w 2 ⩽ θ w_1+w_2\leqslant{\theta} w1+w2⩽θ
- w 1 > θ w_1>\theta w1>θ
- w 2 > θ w_2>\theta w2>θ
- 其中,由第3,4条得 w 1 + w 2 > 2 θ w_1+w_2>2\theta w1+w2>2θ这显然和第二条矛盾,因此无法从该模型学习得到能够完成XOR得分类任务
- 但是上述模型可以解决 A N D , O R AND,OR AND,OR等逻辑门
- 直线
f
(
x
1
,
x
2
)
=
∑
i
=
1
2
w
i
x
i
=
θ
f(x_1,x_2)=\sum\limits_{i=1}^{2}w_ix_i=\theta
f(x1,x2)=i=1∑2wixi=θ无法将点
(
0
,
0
)
和
(
1
,
1
)
(0,0)和(1,1)
(0,0)和(1,1)归为
⩽
θ
\leqslant{\theta}
⩽θ同时还把
(
0
,
1
)
,
(
1
,
0
)
(0,1),(1,0)
(0,1),(1,0)归为
>
θ
>{\theta}
>θ
-
感知机的局限性就在于它只能表示由一条直线分割的空间。弯曲的曲线无法用感知机表示。
-
曲线分割而成的空间称为非线性空间,
-
由直线分割而成的空间称为线性空间。
-
线性、非线性这两个术语在机器学习领域很常见.
多层感知机
-
使用多层感知机可以解决亦或门问题
-
通过组合[与门/或门/与非门],可以实现和亦或运算功能一样的逻辑函数
-
A ⊕ B = A ‾ B + A B ‾ = A ‾ B ‾ ⋅ A B ‾ ‾ ‾ = ( A + B ‾ ) ⋅ ( A ‾ + B ) ‾ = A B + A ‾ B ‾ ‾ = A B ‾ ⋅ A ‾ B ‾ ‾ = A B ‾ ⋅ ( A + B ) A\oplus{B}=\overline{A}B+A\overline{B} =\overline{\overline{\overline{A}B} \cdot \overline{A\overline{B}}} \\=\overline{({A+\overline{B}}) \cdot (\overline{A}+{B})} =\overline{AB+\overline{A}\ \overline{B}} =\overline{AB}\cdot\overline{\overline{A}\ \overline{B}} \\ =\overline{AB}\cdot(A+B) A⊕B=AB+AB=AB⋅AB=(A+B)⋅(A+B)=AB+A B=AB⋅A B=AB⋅(A+B)
- 推到使用数字逻辑基本知识,不过也可以直接计算上述式子的真值表来验证等价性
-
-
异或门是一种多层结构的神经网络。
-
这里,将最左边的一列称为第 0层,中间的一列称为第 1层,最右边的一列称为第 2层
-
异或门(XOR)感知机与前面介绍的与门、或门的感知机不同。实际上,与门、或门是单层感知机,而异或门是 2层感知机。
-
叠加了多层的感知机也称为多层感知机(multi-layered perceptron)
-
-
上图中的感知机总共由 3 层构成,但是因为拥有权重的层实质上只有 2 层(第 0 层和第 1 层之间,第 1 层和第 2 层之间),所以称为“2 层感知机”。
- 先在第 0层和第 1层的神经元之间进行信号的传送和接收,然后在第 1层和第 2层之间进行信号的传送和接收,具体如下所示。
- 第0层的两个神经元接收输入信号,并将信号发送至第1层的神经元。
- 第1层的神经元将信号发送至第2层的神经元,第2层的神经元输出y。
- 这种 2层感知机的运行过程可以比作流水线的组装作业。
- 第 1段(第 1层)的工人对传送过来的零件进行加工,完成后再传送给第 2段(第 2层)的工人。
- 第 2层的工人对第 1层的工人传过来的零件进行加工,完成这个零件后出货(输出)。
- 像这样,在异或门的感知机中,工人之间不断进行零件的传送。通过这样的结构(2层结构),感知机得以实现异或门。
- 这可以解释为“单层感知机无法表示的东西,通过增加层就可以解决”。也就是说,通过叠加层(加深层),感知机能进行更加灵活的表示。
- 不过,有的文献认为是由 3 层构成的,因而将其称为“3 层感知机”。
- 先在第 0层和第 1层的神经元之间进行信号的传送和接收,然后在第 1层和第 2层之间进行信号的传送和接收,具体如下所示。
-
从与非门到计算机
-
多层感知机可以实现比之前见到的电路更复杂的电路。比如,进行加法运算的加法器也可以用感知机实现。此外,将二进制转换为十进制的编码器、满足某些条件就输出 1的电路(用于等价检验的电路)等也可以用感知机表示。
-
实际上,使用感知机甚至可以表示计算机!
-
计算机是处理信息的机器。向计算机中输入一些信息后,它会按照某种既定的方法进行处理,然后输出结果。所谓“按照某种既定的方法进行处理”是指,计算机和感知机一样,也有输入和输出,会按照某个既定的规则进行计算。
-
如果通过组合与非门可以实现计算机的话,那么通过组合感知机也可以表示计算机(感知机的组合可以通过叠加了多层的单层感知机来表示)。
-
综上,多层感知机能够进行复杂的表示,甚至可以构建计算机。那么,什么构造的感知机才能表示计算机呢?层级多深才可以构建计算机呢?
- 理论上可以说 2 层感知机就能构建计算机。
- 已有研究证明,2层感知机(严格地说是激活函数使用了非线性的 sigmoid函数的感知机)可以表示任意函数。
- 但是,使用 2层感知机的构造,通过设定合适的权重来构建计算机是一件非常累人的事情。
- 实际上,在用与非门等低层的元件构建计算机的情况下,分阶段地制作所需的零件(模块)会比较自然,即先实现与门和或门,然后实现半加器和全加器,接着实现算数逻辑单元(ALU),然后实现 CPU。
- 因此,通过感知机表示计算机时,使用叠加了多层的构造来实现是比较自然的流程。
-
小结
- 感知机通过叠加层能够进行非线性的表示,理论上还可以表示计算机进行的处理。
- 单层感知机只能表示线性空间,而多层感知机可以表示非线性空间
- 感知机是神经网络的基础
- 关于感知机,既有好消息,也有坏消息。
- 好消息是,即便对于复杂的函数,感知机也隐含着能够表示它的可能性。即便是计算机进行的复杂处理,感知机(理论上)也可以将其表示出来。
- 坏消息是,设定权重的工作,即确定合适的、能符合预期的输入与输出的权重,现在还是由人工进行的。
- 借助与门、或门的真值表,可以人工决定合适的权重实现具体的感知机。
- 神经网络的出现就是为了解决刚才的坏消息。
- 具体地讲,神经网络的一个重要性质是它可以自动地从数据中学习到合适的权重参数。
从感知机到神经网络
-
我们把最左边的一列称为输入层,最右边的一列称为输出层,中间的一列称为中间层。
-
中间层有时也称为隐藏层。“隐藏”一词的意思是,隐藏层的神经元(和输入层、输出层不同)肉眼看不见。
-
可以把输入层到输出层依次称为:第 0层、第1层、第 2层(层号之所以从 0开始,是为了方便后面基于 Python进行实现)。
第 0层对应输入层,第 1层对应中间层,第 2层对应输出层。-
-
就神经元的连接方式而言,与上一章的感知机并没有任何差异
-
-
偏置 b并没有被画出来。如果要明确地表示出 b,可以这么表示:
-
-
上图添加了权重为 b的输入信号 1( x 0 = 1 x_0=1 x0=1)
-
这个感知机将 x1、x2、1三个信号作为神经元的输入,将其和各自的权重相乘后,传送至下一个神经元。
-
在下一个神经元中,计算这些加权信号的总和。如果这个总和超过 0,则输出 1,否则输出 0。
- 另外,由于偏置的输入信号一直是 1(通过创建这个额外的输入信号,来达到偏置效果),为了区别于其他神经元,我们在图中把这个神经元整个用圆角矩形表示。现在将式(3.1)改写成更加简洁的形式。
-
为了简化感知机表达式
- T = T ( x , w ) = w 1 x 1 + w 2 x 2 x , w 作为向量 y = { 0 , T + b ⩽ 0 1 , T + b > 0 T=T(x,w)=w_{1} x_{1}+w_{2} x_{2}\\ x,w作为向量 \\ y=\begin{cases} 0,&T+b\leqslant{0}\\ 1,&T+b>0 \end{cases} T=T(x,w)=w1x1+w2x2x,w作为向量y={0,1,T+b⩽0T+b>0
-
我们用一个新函数 h ( x ) h(x) h(x)来表示这种分情况的动作(超过 0则输出 1,否则输出 0)。
- y = h ( b + w 1 x 1 + w 2 x 2 ) 记 T 1 = T ( x , w ) + b = b + w 1 x 1 + w 2 x 2 , 表示的是 ( 包括偏置的 ) 输入信号 ( 乘以各自权重 ) 的总和 则 y = h ( T 1 ) , 将字母 T 1 改为 a , 表达的是 : y = h ( a ) = { 0 , a ⩽ 0 1 , a > 0 y = h(b + w_1x_1 + w_2x_2) \\记T_1=T(x,w)+b=b+w_{1} x_{1}+w_{2} x_{2}, \\表示的是(包括偏置的)输入信号(乘以各自权重)的总和 \\则y=h(T_1),将字母T_1改为a,表达的是: \\\\ y=h(a)=\begin{cases} 0,&a\leqslant{0}\\ 1,&a>0 \end{cases} y=h(b+w1x1+w2x2)记T1=T(x,w)+b=b+w1x1+w2x2,表示的是(包括偏置的)输入信号(乘以各自权重)的总和则y=h(T1),将字母T1改为a,表达的是:y=h(a)={0,1,a⩽0a>0
-
-
激活函数🎈
-
上面的 h ( x ) h(x) h(x)函数会将输入信号的总和转换为输出信号,这种函数一般称为激活函数(activation function)。
-
激活函数的作用在于决定如何来激活输入信号的总和。
-
-
一般而言,“朴素感知机”是指单层网络,指的是激活函数使用了阶跃函数(指一旦输入超过阈值,就切换输出的函数)的模型。
- 可以说感知机中使用了阶跃函数作为激活函数。
- 也就是说,在激活函数的众多候选函数中,感知机使用了阶跃函数。
- 那么,如果感知机使用其他函数作为激活函数的话会怎么样呢?
- 实际上,如果将激活函数从阶跃函数换成其他函数,就可以进入神经网络的世界了。
-
“多层感知机”是指神经网络,即使用 sigmoid 函数等平滑的激活函数的多层网络。
非线性激活函数
- 神经网络的激活函数必须使用非线性函数。换句话说,激活函数不能使用线性函数。为什么不能使用线性函数呢?因为使用线性函数的话,加深神经网络的层数就没有意义了。
- 线性函数的问题在于,不管如何加深层数,总是存在与之等效的“无隐藏层的神经网络”。
- 例:
- 这里我们考虑把线性函数 h ( x ) = c x h(x) = cx h(x)=cx 作为激活函数,把 y ( x ) = h ( h ( h ( x ) ) ) y(x) = h(h(h(x))) y(x)=h(h(h(x)))的运算对应 3层神经网络 A。
- 这个运算会进行 y ( x ) = ( c ( c ( c x ) ) ) = c 3 x y(x)=(c(c(cx)))=c^3x y(x)=(c(c(cx)))=c3x的乘法运算
- 但是同样的处理可以由 y ( x ) = a x y(x) = ax y(x)=ax(注意, a = c 3 a = c^3 a=c3)这一次乘法运算(即没有隐藏层的神经网络)来表示。
- 如本例所示,使用线性函数时,无法发挥多层网络带来的优势。
- 因此,为了发挥叠加层所带来的优势,激活函数必须使用非线性函数。
step 函数
阶跃函数的实现(numpy)
-
def step_function(x): y = x > 0 return y.astype(np.int)-
import numpy as np def step_function(x): y=x>0#array of boolean values print(y)#check the bool type y return y.astype(int)#np.int32 or64 ## rng=np.random.default_rng() # x=rng.random() #生成-5,5之间的n=7个随机数 x=-5+(5-(-5))*rng.random(7) y=step_function(x) print(y) -
[ True False True True False True True] [1 0 1 1 0 1 1]
-
-
可以用 astype()方法转换 NumPy数组的类型。astype()方法通过参数指定期望的类型,这个例子中是 np.int型。
-
Python中将布尔型转换为 int型后,True会转换为 1,False会转换为 0。
sigmoid function
-
神经网络中经常使用的一个激活函数就是式表示的 sigmoid 函数(sigmoid function)。
-
h ( x ) = 1 1 + e x p ( − x ) h(x)=\frac{1}{1+exp(-x)} h(x)=1+exp(−x)1
-
h ( x ) h(x) h(x)仅仅是个函数而已。
- 而函数就是给定某个输入后,会返回某个输出的转换器
-
感知机和神经网络的主要区别就在于这个激活函数。
-
其他方面,比如神经元的多层连接的构造、信号的传递方法等,基本上和感知机是一样的。
-
-
通过和阶跃函数的比较来详细学习作为激活函数的 sigmoid函数
sigmoid函数
-
def sigmoid(x): return 1 / (1 + np.exp(-x))- 利用numpy可以方便的编写
sigmoid 函数和阶跃函数的比较
-
import numpy as np import matplotlib.pyplot as plt def step_function(x): y=x>0#array of boolean values # print(y)#check the bool type y return y.astype(int)#np.int32 or64 def sigmoid(x): return 1 / (1 + np.exp(-x)) def show(x,y): plt.scatter(x,y) plt.plot(x, y) plt.ylim(0, 1.1) # 指定 y轴的范围(留白设置) plt.show() def compare_add(x,y): # plt.scatter(x,y) plt.plot(x, y) plt.ylim(0, 1.1) # 指定 y轴的范围(留白设置) # return plt ## rng=np.random.default_rng() # x=rng.random() #生成-5,5之间的n=7个随机数 x=-5+(5-(-5))*rng.random(7) y=step_function(x) print(y) ## matplot display the figure of the step function x = np.arange(-5.0, 5.0, 0.2) y = step_function(x) y_sig=sigmoid(x) # step function figure show show(x,y) # sigmoid figure show show(x,y_sig) # compare_add(x, y) compare_add(x, y_sig) plt.show()
图像
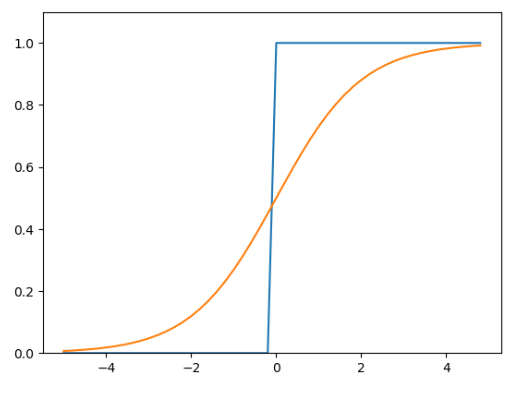
相同点
- 阶跃函数和 sigmoid函数虽然在平滑性上有差异,但是如果从宏观视角看图象,可以发现它们具有相似的形状。
- 实际上,两者的结构均是“输入较小时,输出接近 0(为 0);随着输入增大,输出向 1靠近(变成 1)”。
- 也就是说,当输入信号为重要信息时,阶跃函数和 sigmoid函数都会输出较大的值;
- 当输入信号为不重要的信息时,两者都输出较小的值。还有一个共同点是,不管输入信号有多小,或者有多大,输出信号的值都在 0到 1之间。
- 阶跃函数和 sigmoid函数还有其他共同点,就是两者均为非线性函数。
- sigmoid函数是一条曲线,阶跃函数是一条像阶梯一样的折线,两者都属于非线性的函数。
不同点
- 首先注意到的是“平滑性”的不同。
- sigmoid函数是一条平滑的曲线,输出随着输入发生连续性的变化。
- 阶跃函数以 0为界,输出发生急剧性的变化。sigmoid函数的平滑性对神经网络的学习具有重要意义
- 信号的连续性
- 相对于阶跃函数只能返回 0或 1,sigmoid函数可以返回实数(浮点数)(这一点和刚才的平滑性有关)
- 感知机中神经元之间流动的是 0或 1的二元信号,而神经网络中流动的是连续的实数值信号。
ReLU 函数
-
在神经网络发展的历史上,sigmoid函数很早就开始被使用了,而最近则主要使用 ReLU(Rectified Linear Unit)函数。
-
ReLU函数在输入大于 0时,直接输出该值;在输入小于等于 0时,输出 0.ReLU函数可以表示为下面的式
- h ( x ) = { 0 , x > 0 1 , x ⩽ 0 h(x)= \begin{cases} 0,&x>0\\ 1,&x\leqslant 0 \end{cases} h(x)={0,1,x>0x⩽0
-
ReLU 函数是一个非常简单的函数。因此,ReLU函数的实现也很简单
神经网络的运算
-
以下神经网络省略了偏置和激活函数,只有权重.(神经网络的内积)
-
通过矩阵的乘积进行神经网络的运算
-
-
X = ( x 1 , x 2 ) = ( 1 , 2 ) W = ( w 11 w 12 w 13 w 21 w 22 w 23 ) = ( 1 3 5 2 4 6 ) Y = ( y 1 , y 2 , y 3 ) y i = ∑ j = 1 2 x j w j i 例如 : y 1 = x 1 w 11 + x 2 w 21 = 1 × 1 + 2 × 2 = 5 \\ \begin{aligned} X&=(x_1,x_2)=(1,2) \\ W&= \begin{pmatrix} w_{11}&w_{12}&w_{13}\\ w_{21}&w_{22}&w_{23} \end{pmatrix}\\ &=\begin{pmatrix} 1&3&5\\ 2&4&6 \end{pmatrix}\\ Y&=(y_1,y_2,y_3) \end{aligned} \\ y_i=\sum\limits_{j=1}^{2}x_{j}w_{ji} \\例如:y_1=x_1w_{11}+x_2w_{21}=1\times1+2\times{2}=5 XWY=(x1,x2)=(1,2)=(w11w21w12w22w13w23)=(123456)=(y1,y2,y3)yi=j=1∑2xjwji例如:y1=x1w11+x2w21=1×1+2×2=5
- 上述的矩阵公式和字母下标是沿用线性代数中的习惯
- 后续会用神经网络惯用的方式来标识权重
实现神经网络
-
- 输入层记为第0层
- 中间由2个隐藏层(第1层,底2层)
- 输出层为第3层
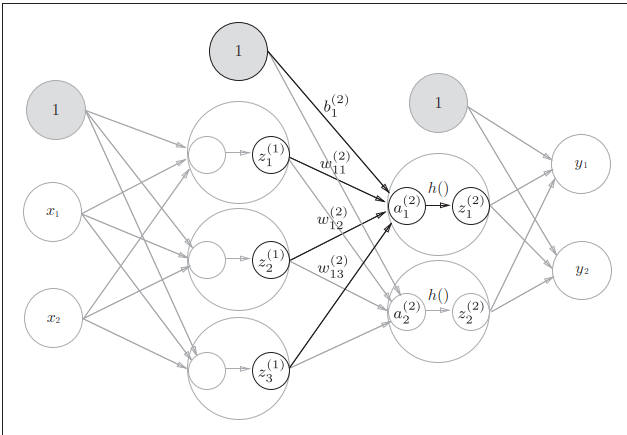
记号说明🎈
-
-
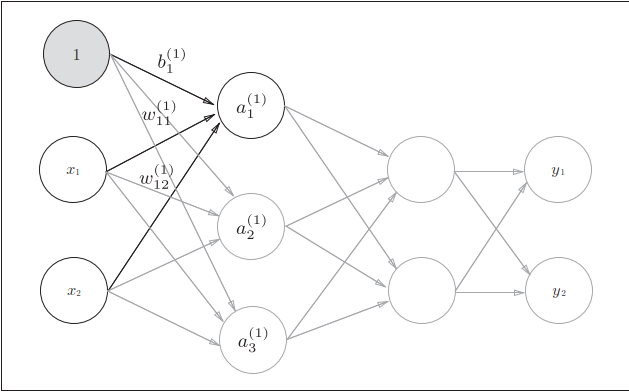
在介绍神经网络中的处理之前,我们先导入 w 12 ( 1 ) , a 1 ( 1 ) w_{12}^{(1)},a_{1}^{(1)} w12(1),a1(1) 等符号
-
任意相邻两层间的某一对神经元连线(权边)可以表示为
-
a j ( k − 1 ) → w i j ( 1 ) a i ( k ) ( k > 0 ) a^{(k-1)}_{j}\xrightarrow{w_{ij}^{(1)}}a^{(k)}_{i} (k>0) aj(k−1)wij(1)ai(k)(k>0)
权重
-
w i j ( k ) w_{ij}^{(k)} wij(k)
- 这个符号包含了类似于
图的数据结构中边的要素 - ( k ) (k) (k)表示第k层的权重(边)
- i i i表示后一层的第 i i i个神经元
- j j j表示前一层的第 j j j个神经元
- 其他形式:
w
N
i
B
j
(
k
)
\huge w_{\small N_iB_j}^{\small(k)}
wNiBj(k)
- N i N_i Ni表示后一层的第i个神经元(N表示Next,指代权重边的后一层)
- B j B_j Bj表示前一层的第j个神经元(B表示Before,指代权重边的前一层)
- 由于第N层是第B层的相邻后一层(都表示神经元层号),所以 N − B = 1 N-B=1 N−B=1
- 这个符号包含了类似于
-
特别的:偏置神经元(值为1的神经元))
-
任何前一层的偏置神经元“1”都只有一个。
- 各层可以由自己的偏置神经元
- 增加了表示偏置的神经元“1”。
- 偏置的右下角的索引号只有一个。
- 这是因为前一层的偏置神经元(神经元“1”)只有一个(不需要区分)
-
偏置权重的数量取决于后一层的神经元的数量(不包括后一层的偏置神经元“1”)
-
神经元
- a i ( k ) a_{i}^{(k)} ai(k)表示的是第 k k k层的 i i i个神经元
使用上述符号表示公式
不考虑激活函数的简化版本
-
一般地 : a i ( k ) = ∑ j = 0 s k − 1 a j ( k − 1 ) w i j ( k ) + b i ( k ) 例如 : a 1 ( 1 ) = w 11 ( 1 ) x 1 + w 12 ( 1 ) x 2 + b 1 ( 1 ) 一般地:\\ a_i^{(k)}=\sum\limits_{j=0}^{s_{k-1}}a_{j}^{(k-1)}w_{ij}^{(k)}+b^{(k)}_i \\例如:a_{1}^{(1)}=w_{11}^{(1)} x_{1}+w_{12}^{(1)} x_{2}+b_{1}^{(1)} 一般地:ai(k)=j=0∑sk−1aj(k−1)wij(k)+bi(k)例如:a1(1)=w11(1)x1+w12(1)x2+b1(1)
- 其中 s k − 1 s_{k-1} sk−1表示的是当前神经元层(第k层)的前一层包含的神经元个数(不包括偏置神经元)
- 偏置的右下角的索引号只有一个
- 结构上类似于数据结构中的带权图(AOE)
-
如果使用矩阵的乘法运算, 则可以将第 i i i 层的加权和表示成下面的式子
-
A ( k − 1 ) = ( x 1 ⋯ x p ) , W ( k ) = ( w 11 ( k ) w 21 ( k ) ⋯ w q 1 ( k ) w 12 ( k ) w 22 ( k ) ⋯ w q 2 ( k ) ⋮ ⋮ ⋮ w 1 p ( k ) w 2 p ( k ) ⋯ w q p ( k ) ) 其中 , p 为前一层 ( 第 k − 1 层的神经元个数 , 决定权重矩阵的行数 ) q 为当前层 ( 第 k 层 ) 的神经元个数 ( 决定了权重矩阵的列数 ) A^{(k-1)} =\begin{pmatrix} x_{1}& \cdots& x_{p} \end{pmatrix}, \\ W^{(k)} =\begin{pmatrix} w_{11}^{(k)} & w_{21}^{(k)}&\cdots & w_{q1}^{(k)} \\ w_{12}^{(k)} & w_{22}^{(k)}&\cdots & w_{q2}^{(k)}\\ \vdots&\vdots&&\vdots\\ w_{1p}^{(k)} & w_{2p}^{(k)}&\cdots & w_{qp}^{(k)} \end{pmatrix} \\ 其中,p为前一层(第k-1层的神经元个数,决定权重矩阵的行数) \\ q为当前层(第k层)的神经元个数(决定了权重矩阵的列数) A(k−1)=(x1⋯xp),W(k)= w11(k)w12(k)⋮w1p(k)w21(k)w22(k)⋮w2p(k)⋯⋯⋯wq1(k)wq2(k)⋮wqp(k) 其中,p为前一层(第k−1层的神经元个数,决定权重矩阵的行数)q为当前层(第k层)的神经元个数(决定了权重矩阵的列数)
A ( k ) = A ( k − 1 ) W ( k ) + B ( k ) B ( k ) = ( b 1 ( k ) ⋯ b q ( k ) ) ( a 1 ( k ) ⋯ a q ( k ) ) = ( x 1 ⋯ x p ) ( w 11 ( k ) w 21 ( k ) ⋯ w q 1 ( k ) w 12 ( k ) w 22 ( k ) ⋯ w q 2 ( k ) ⋮ ⋮ ⋮ w 1 p ( k ) w 2 p ( k ) ⋯ w q p ( k ) ) + ( b 1 ( k ) ⋯ b q ( k ) ) \\ \begin{aligned} A^{(k)}&=A^{(k-1)}W^{(k)}+B^{(k)}\\ B^{(k)} &=\begin{pmatrix} b_{1}^{(k)} & \cdots & b_{q}^{(k)} \end{pmatrix} \\ \begin{pmatrix} a_{1}^{(k)} & \cdots & a_{q}^{(k)} \end{pmatrix} &=\begin{pmatrix} x_{1}& \cdots& x_{p} \end{pmatrix} \begin{pmatrix} w_{11}^{(k)} & w_{21}^{(k)}&\cdots & w_{q1}^{(k)} \\ w_{12}^{(k)} & w_{22}^{(k)}&\cdots & w_{q2}^{(k)}\\ \vdots&\vdots&&\vdots\\ w_{1p}^{(k)} & w_{2p}^{(k)}&\cdots & w_{qp}^{(k)} \end{pmatrix} +\begin{pmatrix} b_{1}^{(k)} & \cdots & b_{q}^{(k)} \end{pmatrix} \end{aligned} A(k)B(k)(a1(k)⋯aq(k))=A(k−1)W(k)+B(k)=(b1(k)⋯bq(k))=(x1⋯xp) w11(k)w12(k)⋮w1p(k)w21(k)w22(k)⋮w2p(k)⋯⋯⋯wq1(k)wq2(k)⋮wqp(k) +(b1(k)⋯bq(k))
- 特别的 k = 1 k=1 k=1时, A ( 1 ) = X W ( 1 ) + B ( 1 ) A^{(1)}=XW^{(1)}+B^{(1)} A(1)=XW(1)+B(1),即 A ( 0 ) = X A^{(0)}=X A(0)=X
-
例
-
A ( 1 ) = X W ( 1 ) + B ( 1 ) 其中 , A ( 1 ) 、 X 、 B ( 1 ) 、 W ( 1 ) 如下所示。 A ( 1 ) = ( a 1 ( 1 ) a 2 ( 1 ) a 3 ( 1 ) ) , X = ( x 1 x 2 ) , B ( 1 ) = ( b 1 ( 1 ) b 2 ( 1 ) b 3 ( 1 ) ) W ( 1 ) = ( w 11 ( 1 ) w 21 ( 1 ) w 31 ( 1 ) w 12 ( 1 ) w 22 ( 1 ) w 32 ( 1 ) ) A^{(1)}=X W^{(1)}+B^{(1)} 其中, A^{(1)} 、 X 、 B^{(1)} 、 W^{(1)} 如下所示。 \\ \begin{aligned} A^{(1)} &=\left(\begin{array}{lll} a_{1}^{(1)} & a_{2}^{(1)} & a_{3}^{(1)} \end{array}\right), X=\left(\begin{array}{ll} x_{1} & x_{2} \end{array}\right), B^{(1)}=\left(\begin{array}{lll} b_{1}^{(1)} & b_{2}^{(1)} & b_{3}^{(1)} \end{array}\right) \\ W^{(1)}&=\left(\begin{array}{lll} w_{11}^{(1)} & w_{21}^{(1)} & w_{31}^{(1)} \\ w_{12}^{(1)} & w_{22}^{(1)} & w_{32}^{(1)} \end{array}\right) \end{aligned} A(1)=XW(1)+B(1)其中,A(1)、X、B(1)、W(1)如下所示。A(1)W(1)=(a1(1)a2(1)a3(1)),X=(x1x2),B(1)=(b1(1)b2(1)b3(1))=(w11(1)w12(1)w21(1)w22(1)w31(1)w32(1))
-
考虑偏置,但暂不考虑函数 同时考虑激活函数 -
以第一层隐藏层为例,计算加权和
X = np.array([1.0, 0.5]) W1 = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]]) B1 = np.array([0.1, 0.2, 0.3]) print(W1.shape) # (2, 3) print(X.shape) # (2,) print(B1.shape) # (3,) A1 = np.dot(X, W1) + B1
考虑激活函数
-
隐藏层的加权和(加权信号和偏置的总和)用 a a a表示.
-
a a a被激活函数转换后的信号用 z表示。
-
用 h ( ) h() h()表示激活函数,例如sigmoid函数
-
A ( k ) = A ( k − 1 ) W ( k ) + B ( k ) Z ( k ) = h ( A ( k ) ) \\ \begin{aligned} A^{(k)}&=A^{(k-1)}W^{(k)}+B^{(k)}\\ Z^{(k)}&=h(A^{(k)}) \end{aligned} A(k)Z(k)=A(k−1)W(k)+B(k)=h(A(k))
-
例如,由加权和 A ( 1 ) A^{(1)} A(1)(简记为
A1,采用激活函数h=sigmoid计算 Z ( 1 ) Z^{(1)} Z(1),简记为Z1Z1 = sigmoid(A1) print(A1) # [0.3, 0.7, 1.1] print(Z1) # [0.57444252, 0.66818777, 0.75026011]
-
-
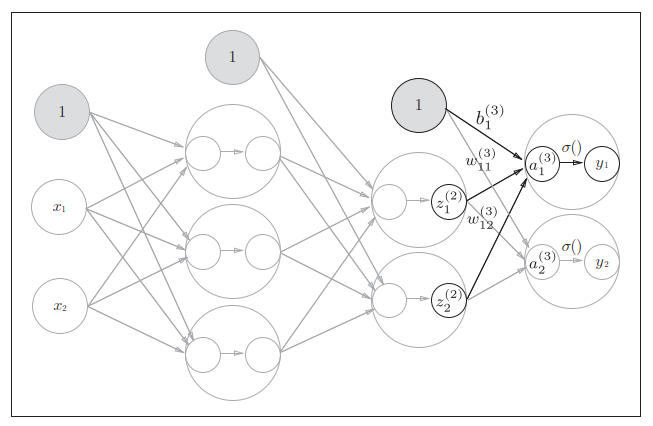
第1层(神经元隐藏层)到第2层 第2层(最后一层隐藏层)到输出层 -
第 2层到输出层的信号传递是最后一次信号传递
-
输出层的实现也和之前的实现基本相同。
-
不过,最后的激活函数和之前的隐藏层使用的激活函数有所不同。
-
最后一层隐藏层( k = s k=s k=s层),使用不同的激活函数,记为 σ ( ) \sigma() σ(),不同于隐藏层的激活函数 h ( ) h() h();则
- y = A ( s + 1 ) = σ ( Z ( s ) ) y=A^{(s+1)}=\sigma(Z^{(s)}) y=A(s+1)=σ(Z(s))
-
本例以 σ = i n d e n t i t y _ f u n c t i o n ( ) \sigma=indentity\_function() σ=indentity_function()作为激活函数
-
#numpy 描述 def identity_function(x): return x W3 = np.array([ [0.1, 0.3], [0.2, 0.4] ]) B3 = np.array([0.1, 0.2]) A3 = np.dot(Z2, W3) + B3 Y = identity_function(A3) # 或者 Y = A3 -
这里我们定义了
identity_function()函数(也称为“恒等函数”),并将其作为输出层的激活函数。- 恒等函数会将输入按原样输出,因此,这个例子中没有必要特意定义 identity_function()。
- 这里这样实现只是为了和之前的流程保持统一。
-
-
小结
-
这里,我们按照神经网络的实现惯例,只把权重记为大写字母 W,
-
其他的(偏置或中间结果等)都用小写字母(a,b,z)表示。
import numpy as np #定义激活函数 def sigmoid(x): return 1 / (1 + np.exp(-x)) def identity_function(x): return x #初始化函数 def init_network(): """ 初始一个三层隐藏层的神经网络: 不设定输入层 给定层间权重矩阵参数3层 给定各层的偏置权重向量3层 输出层由外部计算 """ # 创建空字典 network = {} # 添加网络数据 network['W1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]]) network['b1'] = np.array([0.1, 0.2, 0.3]) network['W2'] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]]) network['b2'] = np.array([0.1, 0.2]) network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]]) network['b3'] = np.array([0.1, 0.2]) return network def z(zk, Wk, bk, activation_func=sigmoid): """将激活函数对加权和的加工打包成一个函数 Parameters ---------- zk : int 第k层的激活函数处理后的向量; 第1层输入可以令z0=a0=x; Wk : int 第k层权重参数 bk : int 第k层偏置权重 activation_func : function, optional 输出层所采用的激活函数和隐藏层的激活函数可能不同,借助此参数指定激活函数, by default sigmoid Returns ------- ndarray 返回下一层神经元隐藏层激活函数处理后的结果向量,可以传递各下一次z函数调用,作为第一个参数 """ A_next = zk@Wk+bk return activation_func(A_next) def forward_v1(network, x): W1, W2, W3 = network['W1'], network['W2'], network['W3'] b1, b2, b3 = network['b1'], network['b2'], network['b3'] a1 = np.dot(x, W1) + b1 z1 = sigmoid(a1) a2 = np.dot(z1, W2) + b2 z2 = sigmoid(a2) a3 = np.dot(z2, W3) + b3 y = identity_function(a3) return y def forward_v2(nextwork, x): W1, W2, W3 = network['W1'], network['W2'], network['W3'] b1, b2, b3 = network['b1'], network['b2'], network['b3'] z0 = a0 = x z1 = z(z0, W1, b1) z2 = z(z1, W2, b2) z3 = z(z2, W3, b3, activation_func=identity_function) # print("z1,z2,z3=", z1, z2, z3) y = z3 return y network = init_network() x = np.array([1.0, 0.5]) y_v1 = forward(network, x) y_v2 = forward_v2(network, x) # print(y) # [ 0.31682708 0.69627909] # print("y_v1=%s" % y_v1,"\n", "y_v2=%s" % y_v2) print(f'{y_v1=}\n{y_v2=}')