文章目录
- 重学MySQL基础(一)
- MySQL 连接管理
- MySQL字符编码
- InnoDB 记录存储结构
- InnoDB 表的主键生成策略:
- InnoDB 数据页结构
- 页目录
- 页的效验和
- 索引
- 事务
- 报错记录
- 在MySQL中创建函数时出现这种错误
- 恶补SQL语句
- SQL中的条件语句
- SQL中的字符串函数
- SQL中的GROUP_CONCAT函数
- SQL 中的IFNULL函数
- SQL中的日期函数
- Docker 安装mysql
重学MySQL基础(一)
MySQL 连接管理
当有客户端连接到服务器时,服务器进程会创建一个线程来处理与这个客户端的交互。而当客户端断开连接时,服务器不会立即销毁处理客户端交互的线程,而是会将它缓存起来,在新的客户端与服务器建立连接时,再讲这个线程分配给新的客户端。
MySQL字符编码
character_set_client:客户端请求数据的字符集
character_set_connection:客户机/服务器连接的字符集
character_set_results:结果集,返回给客户端的字符集
character_set_server:数据库服务器的默认字符集
本地客户端常用编码格式:
IE6使用utf8,命令行是gbk,一般程序则是gb2312
要保证connection的字符集大于client字符集才能保证转换不丢失信息。
常见字符集 latin1 < gb2312 < gbk < utf8
InnoDB 记录存储结构
InnoDB 以页作为磁盘与内存之间交互的基本单位,InnoDB 中页的大小一般为16KB。
InnoDB 引擎中页的大小由系统变量innodb_page_size表明,该变量只能在第一次初始化MySQL数据目录时指定,服务器运行过程中不能被更改。
InnoDB 表的主键生成策略:
- 优先使用用户自定义的主键作为主键。
- 若用户没有定义主键,则选取一个不允许存储NULL值的UNIQUE键作为主键。
- 如果表中连不允许存储NULL值的UNIQUE都没有定义,则InnoDB会为表添加一个名为row_id的隐藏列作为主键。
COMPACT
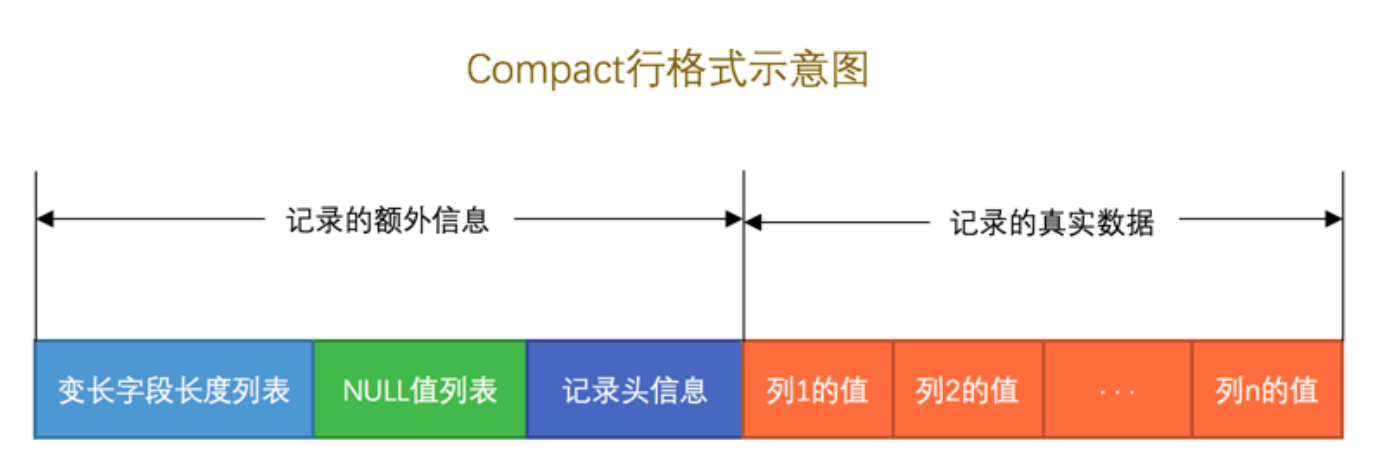
变长字段长度列表由各个变长字段的真实数据所占的字节数按照列的顺序逆序存放组成。
REDUNDANT
没有NULL值列表,将列对应的偏移量值的第一个比特位作为是否为NULL的依据(NULL比特位)
多了n_field(列的数量)和1byte_offs_flag(标记字段长度偏移列表中每个列对应的偏移量是使用1字节表示还是2字节表示)两个属性
没有record_type(表示当前记录类型,普通记录、目录表项记录等)属性
CHAR(M)类型的列在COMPACT行格式中,使用不同的字符集(定长编码字符集和变长编码的字符集),其存储方案也不同,而在REDUNDANT行格式中,该列真实数据所占空间的大小就是所用字符集表示一个字符最多需要的字节数与M的乘积。
在COMPACT和REDUNDANT行格式中,对于占用存储空间很多的列(溢出列,即off-page列),在记录真实数据的位置只会存储该列的一部分数据(前768字节),再将剩余的数据分散存储在几个其他的页(溢出页)中,并在记录真实数据的位置上用20字节存储指向这些页的地址(以及分散在各个页中数据所占的字节数)
DYNAMIC
大体与COMPACT相同,区别是溢出列真实数据存放处值记录溢出页位置与溢出页数据字节数,将所有真实数据全部存放至溢出页中。
COMPRESSED
与DYNAMIC大致相同,不同的一点是COMPRESSED会使用压缩算法对页面进行压缩。
InnoDB 数据页结构
MySQL 中规定一个页中至少要存放两行记录
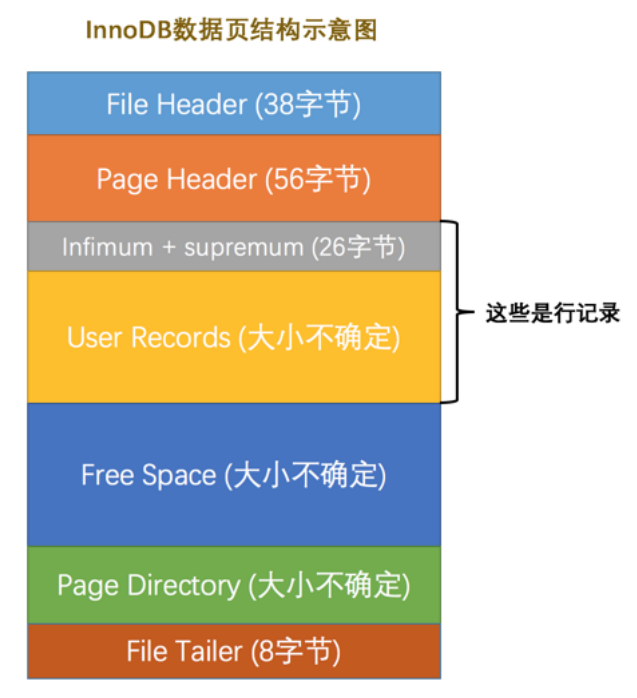
Infimum记录是一个页面中最小的记录;Supremum记录是一个页面中最大的记录。(由5字节大小的记录头信息和8字节大小的一个固定单词组成,人为规定)
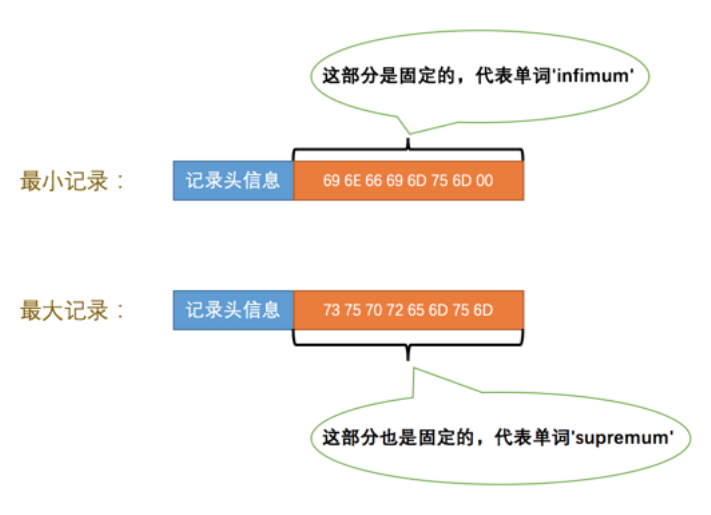
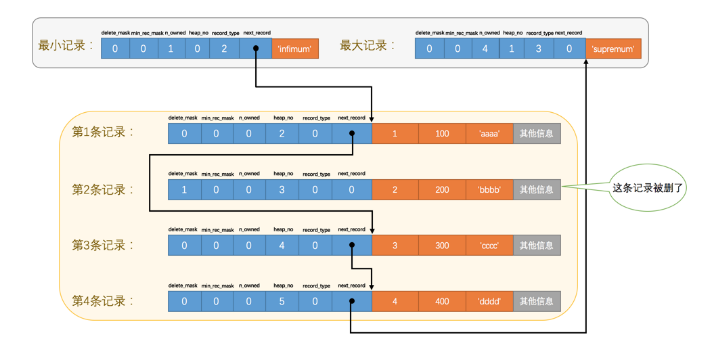
Infimum和Supremum记录的heap_no值分别为0和1。
堆中记录的heap_no值一旦分配便不可改变,即使记录被删除,该删除记录的heap_no值也依旧保持不变
next_record值记录从当前记录的真实数据到下一条记录的真实数据的距离(下一条数据指按照主键值从小到大排序的下一条记录)
 +
+
next_record指向真实数据开始的位置,该位置向左是记录头信息,向右是真实数据,这便与之前行结构部分变长字段列表、NULL值列表逆序存放相对应。
删除一条记录时
- 该条记录的
deleted_flag值设置为1 - 该条记录的上一条数据的
next_record值修改为该条记录的next_record值 - 该条记录的
next_record值为0 Supremun记录的n_owned值减小1
页目录
- 将所有记录(包括
Supremum和Infimum)划分为几个组。 - 每个组最后一条记录的
n_owned属性表示该组内有几条记录。 - 将每组最后一条数据在页面中的地址偏移量单独提取出来按顺序放在靠近页尾部的地方(Page Dictionary,页目录)。页目录中的地址偏移量称为槽(Slot)每个槽占2字节.页目录就是由多个槽组成。
每个分组的记录条数有以下规定:
- 对于
Infimum记录所在的分组只能有一条记录 Supremum记录所在的分组拥有的记录条数只能在1-8之间- 其他分组中记录的条数范围在4-8之间
给记录进行分组的步骤:
- 初始情况页面中只有
Infimum和Supremum两条记录,它们分属于两个分组。页目录中只有两个记录Infimum和Supremum记录偏移量的槽 - 每插入一条记录,都会从页目录中找到对应记录主键值比待插入记录的主键值大并且差值最小的槽,并将该槽的
n_owned值加1 - 当一个组中的记录数等于
8时,再插入一条记录便会将这两个组拆分为分别包含四条记录和五条记录的两个组。
页的效验和
File Header中的FIL_PAGE_LSN,表示页面被最后修改时对应的日志序列号的值
在将页从内存刷新到磁盘时,为保证页的完整性,页首和页尾都会存储页中数据的校验和,以及页面最后修改时对应的LSN值(页尾只会存储LSN值的后4字节)。若页首和页尾的校验和以及LSN值校验不成功,就说明刷新期间出现了问题。
索引
- 主键索引(PRIMARY KEY)
- 唯一标识,主键不可重复,只能有一个主键
- 唯一索引(UNIQUE KEY)
- 索引列
- 常规索引(KEY/INDEX)
- 全文索引(FullText)
- 可以快速定位数据
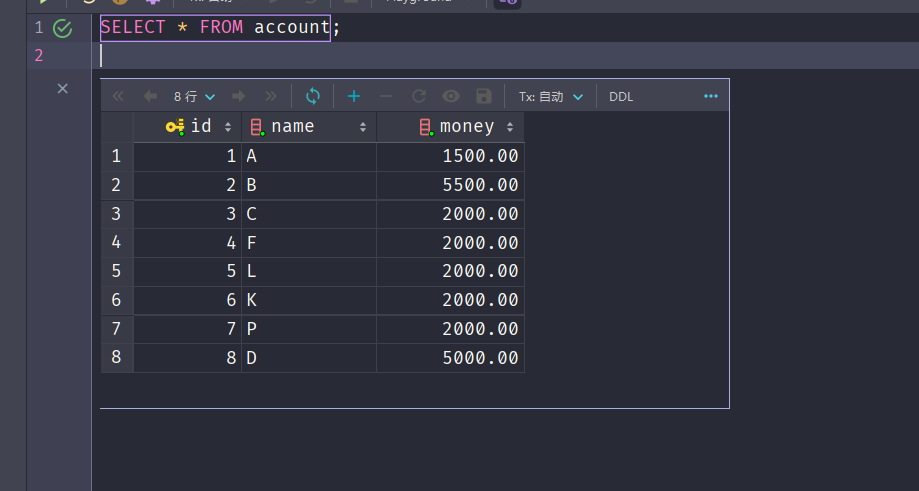
ALTER TABLE `account` ADD FULLTEXT INDEX `name`;

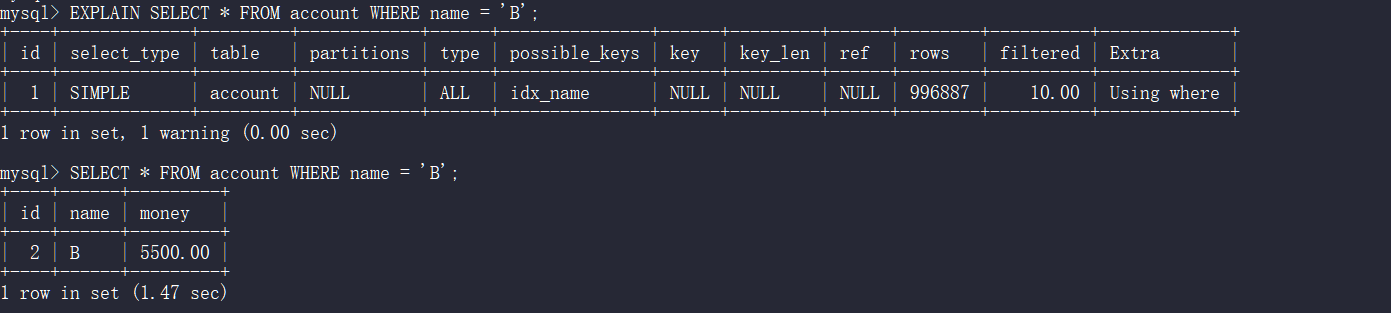
不使用全文索引
EXPLAIN SELECT * FROM account WHERE name = 'B';

使用全文索引
EXPLAIN SELECT * FROM account WHERE MATCH(name) AGAINST('B');

编写sql函数插入百万数据
DELIMITER $$ -- 写函数之前必须要写的标志
CREATE FUNCTION mock_data()
RETURNS INT
BEGIN
DECLARE num INT DEFAULT 1000000;
DECLARE i INT DEFAULT 0;
WHILE i < num DO
INSERT INTO account(`name`,`money`)
VALUES(CONCAT('用户',i),i);
SET i = i + 1;
END WHILE;
RETURN i;
END;
运行函数
SELECT mock_data();
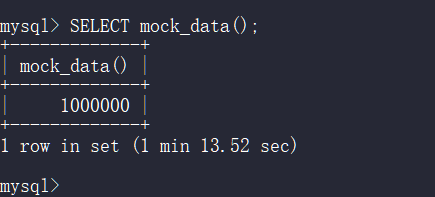
插入百万数据后测试
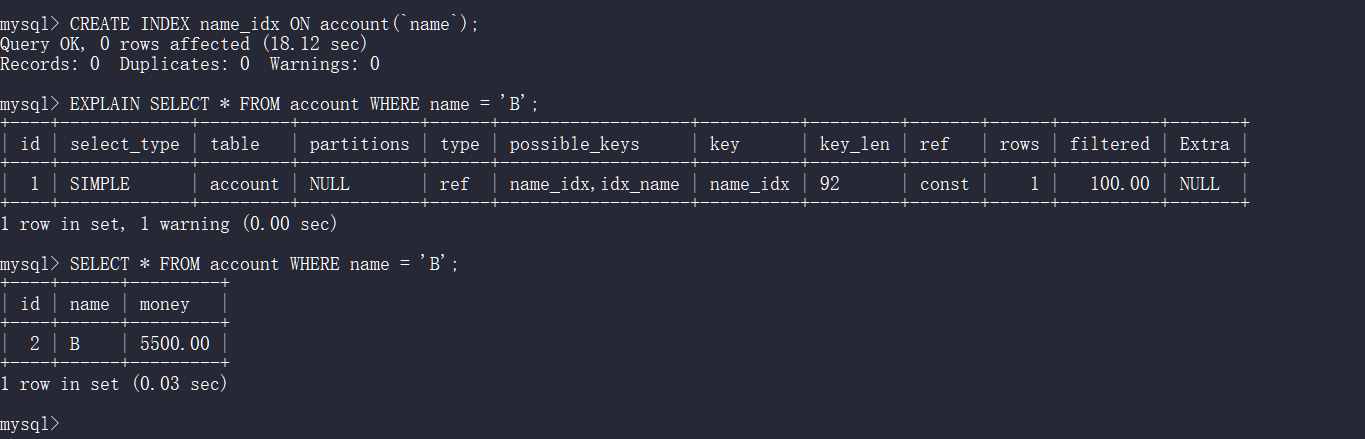
创建索引
CREATE INDEX name_idx ON account(`name`);
再查
索引原则
- 索引不是越多越好
- 不要对经常变动的数据加索引
- 小数据量表不需要加索引
- 一般加在常用来查询到字段上
回表:通过携带主键信息到聚簇索引中重新定位完整的用户记录的过程。
以非主键列的大小为排序规则而建立的B+树需要执行回表操作才可以定位到完整的用户记录,这种B+树也称为二级索引或辅助索引。
以两个或两个以上个列的大小为排序规则建立的B+树称为复合索引,本质也是二级索引。
一个B+树索引的根节点自创建之日起便不会再移动(页号不会改变)
要保证B+树同一层内节点的目录项记录除页号这个字段以外是唯一的。
二级索引的内节点的目录项记录的内容分为三部分(索引列的值、主键值、页号)。
先按照二级索引列的值进行排序,在二级索引列值相同的情况下,再按照主键值进行排序。故为 c 列建立的索引相当于为(c,主键)列建立了一个联合索引。
唯一二级索引:某个列被声明为UNIQUE属性时,便会建立一个唯一二级索引。
MyISAM 和 InnoDB 索引的区别
- InnoDB 中 索引和数据的存储格式相同,有record_type标识来区分用户记录和目录记录,而 MyISAM 中索引与数据存储格式不同,索引是索引,数据是数据。
- MyISAM 中 所有索引都是二级索引,它的主键索引叶子节点存的是主键值与行号(定长记录),而变长记录存储的是主键值与地址偏移量。
事务
ACID原则:原子性、一致性、隔离性、持久性
原子性(Atomicity):要么都成功,要么都失败。
一致性(Consistency):事务前后的数据完整性要保持一致。
隔离性(Isolation):每个事务之间相互隔离。
持久性(Durability): 事务一旦被提交则不可逆,会被持久化到数据库中。
隔离所导致的问题:
可重复读
begin;
select * from dept;
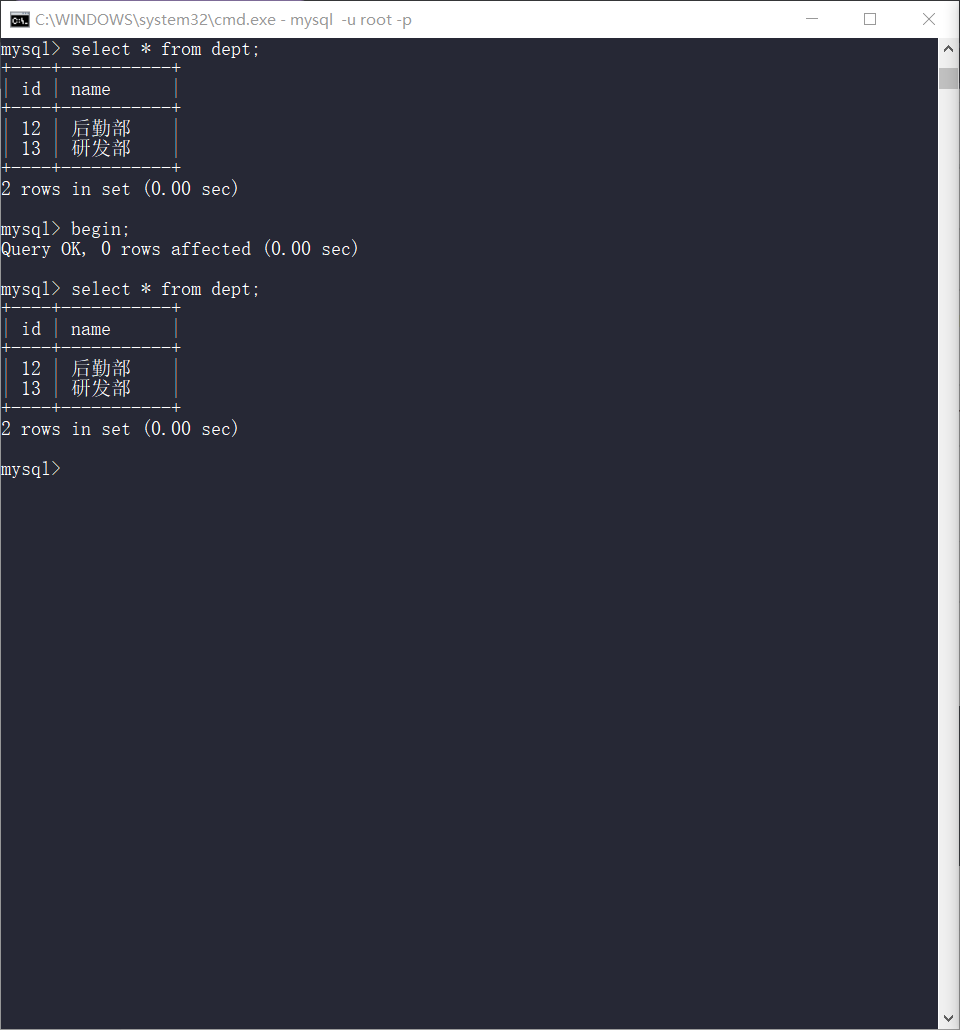
另一个窗口
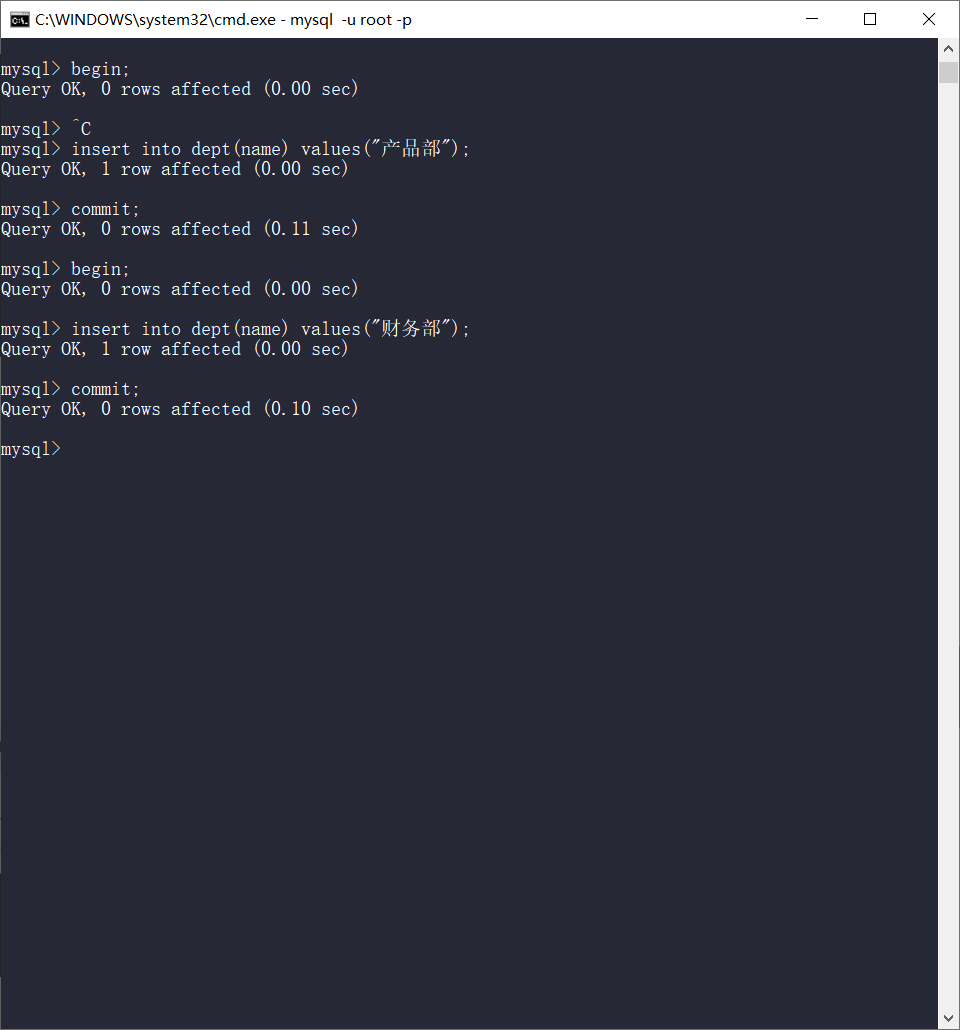
begin;
insert into dept(name) values("产品部");
commit;
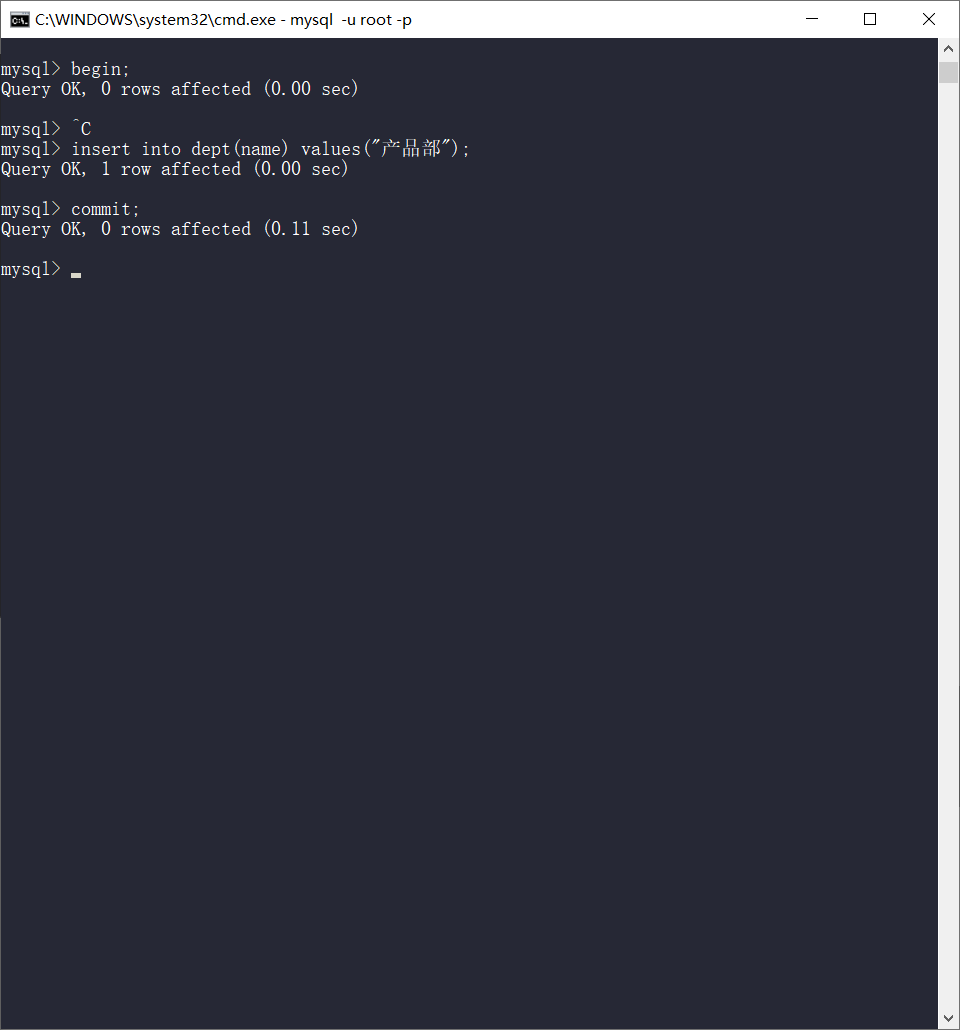
再查
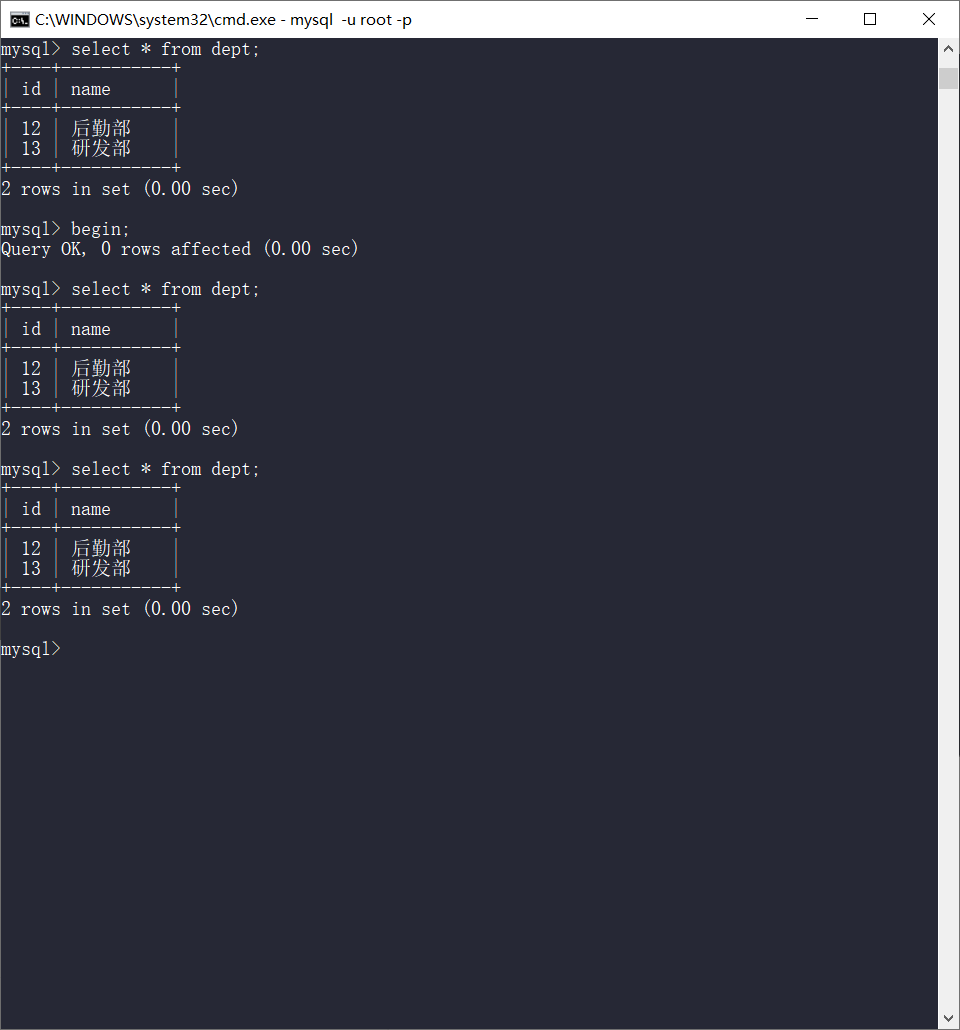
commit之后再差
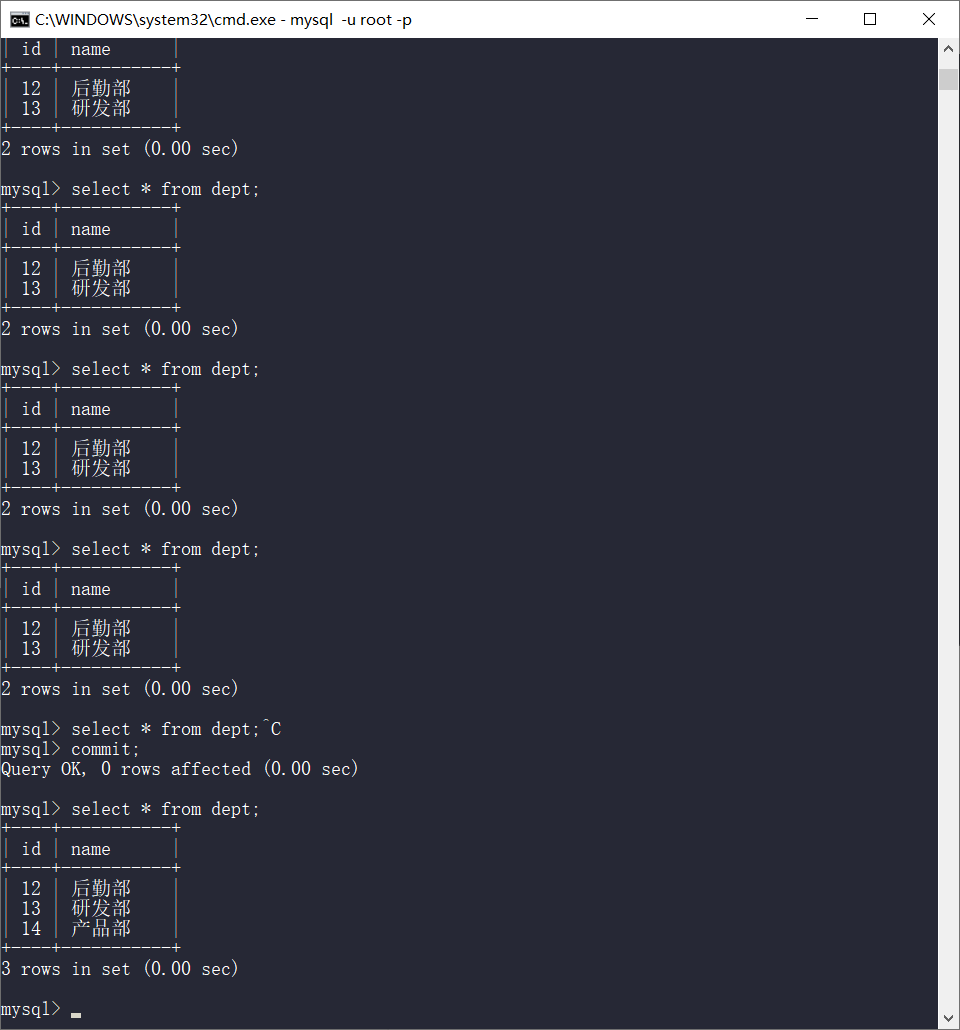
幻读
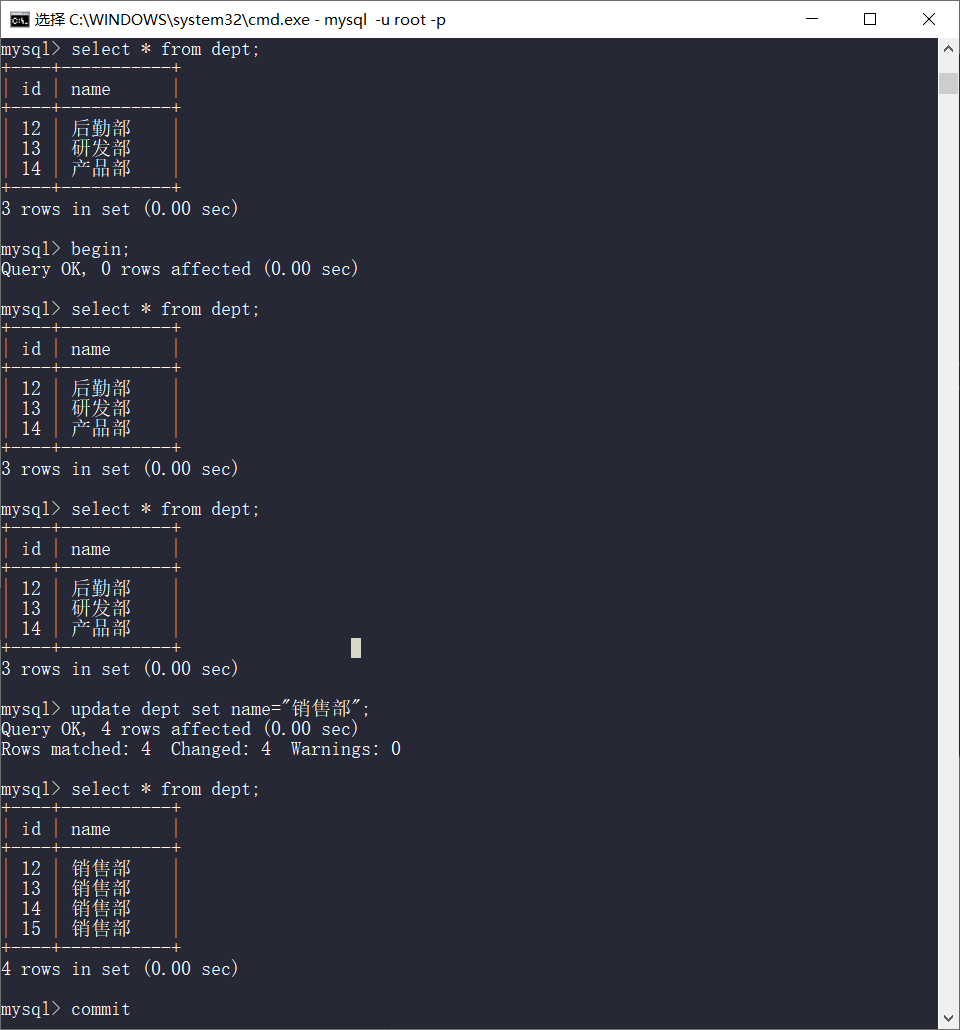
一个事务内读取到了其他事务插入的数据,导致前后数据不一致。
脏读
指一个事务读取到了另一个事务未提交的数据
不可重复读
一个事务内读取某一行数据,多次读取数据不同(不一定错误,以场景而定)
-- mysql 默认开启事务自动提交
SET autocommit = 0 -- 关闭
SET autocommit = 1 -- 开启(默认)
-- 手动处理事务
SET autocommit = 0 -- 关闭自动提交
-- 事务开启
START TRANSACTION -- 标记事务开始
INSERT ...
-- 提交事务
COMMIT
-- 回滚事务
ROLLBACK
-- 事务结束
SET autocommit = 1 -- 开启自动提交
-- 扩展
SAVEPOINT SAVE_POINT_NAME -- 设置一个事务保存点
ROLLBACK TO SAVEPOINT SAVE_POINT_NAME -- 回滚到保存点
RELEASE SAVEPOINT SAVE_POINT_NAME -- 撤销保存点
转账案例
-- 转账案例
CREATE DATABASE shop CHARACTER
SET utf8 COLLATE utf8_general_ci;
USE shop;
CREATE TABLE `account`
(
`id` INT(3) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(30) NOT NULL,
`money` DECIMAL(9, 2) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE = INNODB
DEFAULT CHARSET = utf8;
INSERT INTO account (`name`, `money`)
VALUES ('A', 2000.00),
('B',
5000.00);
-- 模拟转账事务
SET autocommit = 0;-- 关闭自动提交
START TRANSACTION;-- 开启一个事务
UPDATE account
SET money = money - 500
WHERE NAME = 'A';
UPDATE account
SET money = money + 500
WHERE NAME = 'B';
SELECT * FROM account;
ROLLBACK ;
COMMIT;
报错记录
在MySQL中创建函数时出现这种错误
在mysql数据库中执行以下语句 (临时生效,重启后失效)
set global log_bin_trust_function_creators=TRUE;
在配置文件my.cnf的[mysqld]配置log_bin_trust_function_creators=1
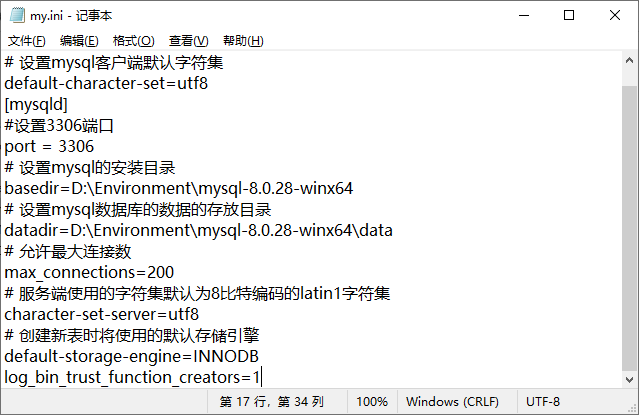
恶补SQL语句
SQL中的条件语句
使用CASE写条件语句
CASE
WHEN ... THEN ...
WHEN ... THEN ...
ELSE ...
END
或者类似三元运算符的IF函数
IF(a,b,c)
# 相当于 a?b:c
LeetCode 1873. 计算特殊奖金
表:
Employees+-------------+---------+ | 列名 | 类型 | +-------------+---------+ | employee_id | int | | name | varchar | | salary | int | +-------------+---------+ employee_id 是这个表的主键。 此表的每一行给出了雇员id ,名字和薪水。写出一个SQL 查询语句,计算每个雇员的奖金。如果一个雇员的id是奇数并且他的名字不是以’M’开头,那么他的奖金是他工资的100%,否则奖金为0。
Return the result table ordered by
employee_id.返回的结果集请按照
employee_id排序。例:
输入: Employees 表: +-------------+---------+--------+ | employee_id | name | salary | +-------------+---------+--------+ | 2 | Meir | 3000 | | 3 | Michael | 3800 | | 7 | Addilyn | 7400 | | 8 | Juan | 6100 | | 9 | Kannon | 7700 | +-------------+---------+--------+ 输出: +-------------+-------+ | employee_id | bonus | +-------------+-------+ | 2 | 0 | | 3 | 0 | | 7 | 7400 | | 8 | 0 | | 9 | 7700 | +-------------+-------+ 解释: 因为雇员id是偶数,所以雇员id 是2和8的两个雇员得到的奖金是0。 雇员id为3的因为他的名字以'M'开头,所以,奖金是0。 其他的雇员得到了百分之百的奖金。
AC代码:
SELECT employee_id, (
CASE WHEN name LIKE 'M%' OR MOD(employee_id,2) = 0 THEN 0
ELSE salary
END
) AS bonus FROM Employees ORDER BY employee_id;
LeetCode 627. 变更性别
Salary表:+-------------+----------+ | Column Name | Type | +-------------+----------+ | id | int | | name | varchar | | sex | ENUM | | salary | int | +-------------+----------+ id 是这个表的主键。 sex 这一列的值是 ENUM 类型,只能从 ('m', 'f') 中取。 本表包含公司雇员的信息。请你编写一个 SQL 查询来交换所有的
'f'和'm'(即,将所有'f'变为'm',反之亦然),仅使用 单个 update 语句 ,且不产生中间临时表。注意,你必须仅使用一条 update 语句,且 不能 使用 select 语句。
查询结果如下例所示。
例:
输入: Salary 表: +----+------+-----+--------+ | id | name | sex | salary | +----+------+-----+--------+ | 1 | A | m | 2500 | | 2 | B | f | 1500 | | 3 | C | m | 5500 | | 4 | D | f | 500 | +----+------+-----+--------+ 输出: +----+------+-----+--------+ | id | name | sex | salary | +----+------+-----+--------+ | 1 | A | f | 2500 | | 2 | B | m | 1500 | | 3 | C | f | 5500 | | 4 | D | m | 500 | +----+------+-----+--------+ 解释: (1, A) 和 (3, C) 从 'm' 变为 'f' 。 (2, B) 和 (4, D) 从 'f' 变为 'm' 。
AC代码:
UPDATE Salary SET sex = IF(sex = 'm','f','m');
SQL中的字符串函数
| Name | Description |
|---|---|
| UPPER(s) | 将字符串s全部大写 |
| CONCAT(s1,s2…) | 连接多个字符串 |
| LOWER(s) | 将字符串s全部小写 |
| SUBSTRING(s,n,len) | 截取字符串s从n位开始截取长度为len的字符串(从1开始!!!) |
| CHAR_LENGTH(s) | 返回s中的字符数 |
| TRIM(s) | 删除前导和尾随空格 |
| MID(s,n) | 返回s从指定位置n开始的子字符串 |
| LENGTH() | 返回字符串s的长度(以字节为单位) |
| BIT_LENGTH() | 返回s的长度(以位为单位) |
LeetCode 1667.修复表中的名字
SQL Schema
表:
Users+----------------+---------+ | Column Name | Type | +----------------+---------+ | user_id | int | | name | varchar | +----------------+---------+ user_id 是该表的主键。 该表包含用户的 ID 和名字。名字仅由小写和大写字符组成。编写一个 SQL 查询来修复名字,使得只有第一个字符是大写的,其余都是小写的。
返回按
user_id排序的结果表。查询结果格式示例如下。
例:
输入: Users table: +---------+-------+ | user_id | name | +---------+-------+ | 1 | aLice | | 2 | bOB | +---------+-------+ 输出: +---------+-------+ | user_id | name | +---------+-------+ | 1 | Alice | | 2 | Bob | +---------+-------+
AC代码:
SELECT user_id, CONCAT(
SUBSTRING(UPPER(name),1,1),
MID(LOWER(name),2)
) as name FROM Users ORDER BY user_id;
SQL中的GROUP_CONCAT函数
将组中字符串连接
使用示例
GROUP_CONCAT(DISTINCT product ORDER BY sell_date SEPARATOR ',')
LeetCode 1484. 按日期分组销售产品
表
Activities:+-------------+---------+ | 列名 | 类型 | +-------------+---------+ | sell_date | date | | product | varchar | +-------------+---------+ 此表没有主键,它可能包含重复项。 此表的每一行都包含产品名称和在市场上销售的日期。编写一个 SQL 查询来查找每个日期、销售的不同产品的数量及其名称。
每个日期的销售产品名称应按词典序排列。
返回按sell_date排序的结果表。
查询结果格式如下例所示。例 :
输入: Activities 表: +------------+-------------+ | sell_date | product | +------------+-------------+ | 2020-05-30 | Headphone | | 2020-06-01 | Pencil | | 2020-06-02 | Mask | | 2020-05-30 | Basketball | | 2020-06-01 | Bible | | 2020-06-02 | Mask | | 2020-05-30 | T-Shirt | +------------+-------------+ 输出: +------------+----------+------------------------------+ | sell_date | num_sold | products | +------------+----------+------------------------------+ | 2020-05-30 | 3 | Basketball,Headphone,T-shirt | | 2020-06-01 | 2 | Bible,Pencil | | 2020-06-02 | 1 | Mask | +------------+----------+------------------------------+ 解释: 对于2020-05-30,出售的物品是 (Headphone, Basketball, T-shirt),按词典序排列,并用逗号 ',' 分隔。 对于2020-06-01,出售的物品是 (Pencil, Bible),按词典序排列,并用逗号分隔。 对于2020-06-02,出售的物品是 (Mask),只需返回该物品名。
AC代码:
SELECT sell_date,
COUNT(DISTINCT product) as num_sold,
GROUP_CONCAT(DISTINCT product) as products
FROM Activities GROUP BY sell_date ORDER BY sell_date;
SQL 中的IFNULL函数
LeetCode 176. 第二高的薪水
Employee表:+-------------+------+ | Column Name | Type | +-------------+------+ | id | int | | salary | int | +-------------+------+ id 是这个表的主键。 表的每一行包含员工的工资信息。编写一个 SQL 查询,获取并返回
Employee表中第二高的薪水 。如果不存在第二高的薪水,查询应该返回null。查询结果如下例所示。
例 1:
输入: Employee 表: +----+--------+ | id | salary | +----+--------+ | 1 | 100 | | 2 | 200 | | 3 | 300 | +----+--------+ 输出: +---------------------+ | SecondHighestSalary | +---------------------+ | 200 | +---------------------+例 2:
输入: Employee 表: +----+--------+ | id | salary | +----+--------+ | 1 | 100 | +----+--------+ 输出: +---------------------+ | SecondHighestSalary | +---------------------+ | null | +---------------------+
AC代码:
SELECT (
SELECT DISTINCT salary
FROM Employee ORDER BY salary DESC LIMIT 1 OFFSET 1
) AS SecondHighestSalary
使用IFNULL优化代码:
SELECT IFNULL(
(
SELECT DISTINCT salary FROM Employee
ORDER BY salary DESC LIMIT 1 OFFSET 1
),
NULL
) AS SecondHighestSalary
SQL中的日期函数
| 函数名称 | 描述 |
|---|---|
| ADDDATE() | 相加日期 |
| ADDTIME() | 相加时间 |
| CONVERT_TZ() | 从一个时区转换到另一个时区 |
| CURDATE() | 返回当前日期 |
| CURRENT_DATE(), CURRENT_DATE | CURDATE() 函数的同义词 |
| CURRENT_TIME(), CURRENT_TIME | CURTIME() 函数的同义词 |
| CURRENT_TIMESTAMP(), CURRENT_TIMESTAMP | NOW() 函数的同义词 |
| CURTIME() | 返回当前时间 |
| DATE_ADD() | 两个日期相加 |
| DATE_FORMAT() | 按格式指定日期 |
| DATE_SUB() | 两个日期相减 |
| DATE() | 提取日期或日期时间表达式的日期部分 |
| DATEDIFF() | 两个日期相减 |
| DAY() | DAYOFMONTH() 函数的同义词 |
| DAYNAME() | 返回星期的名字 |
| DAYOFMONTH() | 返回该月的第几天 (1-31) |
| DAYOFWEEK() | 返回参数的星期索引 |
| DAYOFYEAR() | 返回一年中的天 (1-366) |
| EXTRACT | 提取日期部分 |
| FROM_DAYS() | 日期的数字转换为一个日期 |
| FROM_UNIXTIME() | 格式化日期为UNIX时间戳 |
| HOUR() | 提取小时部分 |
| LAST_DAY | 返回该参数对应月份的最后一天 |
| LOCALTIME(), LOCALTIME | NOW() 函数的同义词 |
| LOCALTIMESTAMP, LOCALTIMESTAMP() | NOW() 函数的同义词 |
| MAKEDATE() | 从一年的年份和日期来创建日期 |
| MAKETIME | MAKETIME() |
| MICROSECOND() | 从参数中返回微秒 |
| MINUTE() | 从参数返回分钟 |
| MONTH() | 通过日期参数返回月份 |
| MONTHNAME() | 返回月份的名称 |
| NOW() | 返回当前日期和时间 |
| PERIOD_ADD() | 添加一个周期到一个年月 |
| PERIOD_DIFF() | 返回两个时期之间的月数 |
| QUARTER() | 从一个日期参数返回季度 |
| SEC_TO_TIME() | 转换秒为“HH:MM:SS’的格式 |
| SECOND() | 返回秒 (0-59) |
| STR_TO_DATE() | 转换一个字符串为日期 |
| SUBDATE() | 当调用三个参数时,它就是 DATE_SUB() 的代名词 |
| SUBTIME() | 相减时间 |
| SYSDATE() | 返回函数执行时的时间 |
| TIME_FORMAT() | 格式化为时间 |
| TIME_TO_SEC() | 将参数转换成秒并返回 |
| TIME() | 提取表达式传递的时间部分 |
| TIMEDIFF() | 相减时间 |
| TIMESTAMP() | 带一个参数,这个函数返回日期或日期时间表达式。有两个参数,参数的总和 |
| TIMESTAMPADD() | 添加一个时间间隔到datetime表达式 |
| TIMESTAMPDIFF() | 从日期时间表达式减去的间隔 |
| TO_DAYS() | 返回日期参数转换为天 |
| UNIX_TIMESTAMP() | 返回一个UNIX时间戳 |
| UTC_DATE() | 返回当前UTC日期 |
| UTC_TIME() | 返回当前UTC时间 |
| UTC_TIMESTAMP() | 返回当前UTC日期和时间 |
| WEEK() | 返回周数 |
| WEEKDAY() | 返回星期的索引 |
| WEEKOFYEAR() | 返回日期的日历周 (1-53) |
| YEAR() | 返回年份 |
| YEARWEEK() | 返回年份和周 |
该表格摘于 https://www.yiibai.com/mysql/mysql_date_time_functions.html
使用Docker安装MySQL
Docker 安装mysql
先拉取官方的最新版本的镜像:
docker pull mysql:latest
运行容器
docker run -itd --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=73748156 mysql
映射到本地目录
docker run -itd -e MYSQL_ROOT_PASSWORD=73748156 --name mysql -v /data/mysql/my.cnf:/etc/mysql/my.cnf -v /data/mysql/data:/var/lib/mysql -p 3306:3306 mysql