JavaSE 复习
- 1.数据结构
- 1.1 查找
- 1.1.1 基本查找
- 1.1.2 二分查找
- 1.1.3 插值查找
- 1.1.4 斐波那契查找
- 1.1.5 分块查找
- 1.1.6 分块查找的扩展(无规律数据)
- 1.2 排序
- 1.2.1 冒泡排序
- 1.2.2 选择排序
- 1.2.3 插入排序
- 1.2.4 快速排序
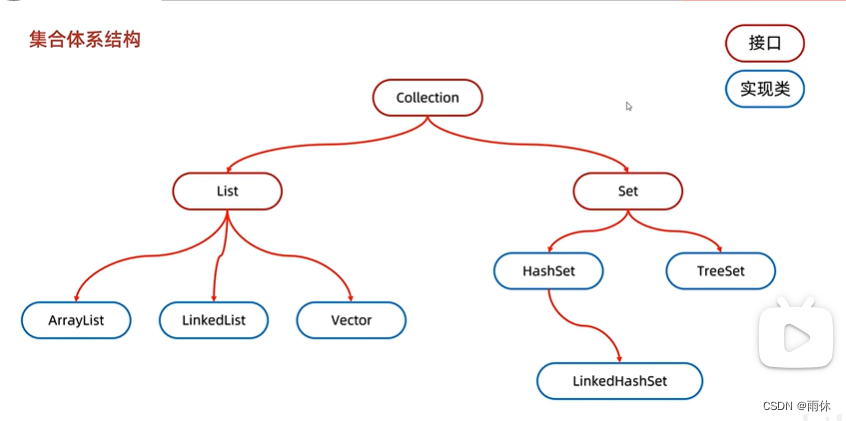
- 2. 集合
- 2.1 基础集合
- 2.1.1 集合和数组的对比
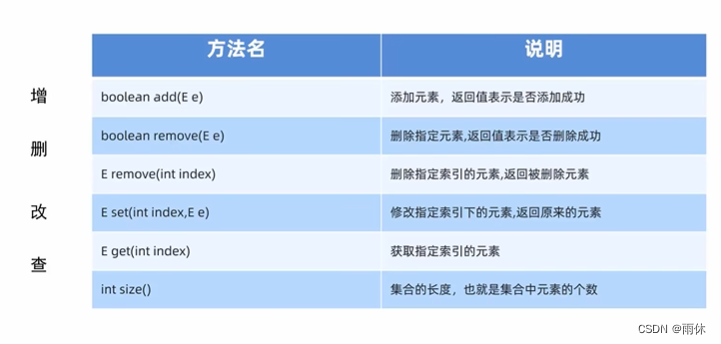
- 2.1.2 ArrayList
- 2.2 单列集合
- 2.2.1 Collection单列集合
- 2.2.1.1 Collection的遍历方式一:迭代器遍历
- 2.2.1.2 Collection的遍历方式二:增强for遍历
- 2.2.1.3 Collection的遍历方式三:Lambda表达式遍历
- 2.2.2 List集合
- 2.2.2.1 迭代器遍历
- 2.2.2.2 增强for遍历方式
- 2.2.2.3 Lambda表达式方式
- 2.2.2.4 普通for循环
- 2.2.2.5 列表迭代器
- 2.2.2.6 五种遍历方式对比
- 2.2.3 ArrayList集合
- 2.2.4 LinkedList集合
- 2.2.5 泛型深入
- 2.2.5.1 泛型类
- 2.2.5.2 泛型方法
- 2.2.5.3 泛型接口
- 2.2.6 Set集合
- 2.2.6 HashSet集合
- 2.2.7 HashSet集合
- 2.2.8 TreeSet集合
- 2.3 双列集合
- 2.3.1 Map集合
- 2.3.1.1 Map集合常用的API
- 2.3.1.2 遍历方式一:键找值
- 2.3.1.3 遍历方式二:键值对
- 2.3.1.4 遍历方式三:Lambda表达式
- 2.3.2 HashMap集合
- 2.3.3 LinkedHashMap
- 2.3.4 TreeMap
- 2.3.5 集合工具类Collections
- 3 Stream流和方法引用
- 3.1 Stream流的思想
- 3.1.1 得到stram流,把数据放上去
- 3.1.2 中间方法
- 3.1.3 终结方法
- 其他
- Arrays
- Lambda表达式
1.数据结构
1.1 查找
1.1.1 基本查找
for 循环直接查找
package searchdemo;
public class SearchDemo1 {
public static void main(String[] args) {
//基本查找
int[] arr = {131,127,147,81,103,23,7,79};
boolean b = basicSearch(arr, 81);
System.out.println(b);
}
public static boolean basicSearch(int[] arr,int number){
for (int i = 0; i < arr.length; i++) {
if(number == arr[i])
return true;
}
return false;
}
}
1.1.2 二分查找
折半查找,每次改变中间指针的位置,要求原序列有序
public class SearchDemo3 {
public static void main(String[] args) {
//折半查找
//min和max表示当前要查找的范围,mid是在min和max中间.
int[] arr = {7,23,79,81,103,127,131,147};
System.out.println(binarySearch(arr,81));
}
public static int binarySearch(int[] arr,int number){
int min = 0;
int max = arr.length-1;
while(true){
if(min > max){
return -1;
}
int mid = (min + max) / 2;
if(arr[mid] > number){
max = mid - 1;
}else if(arr[mid] < number){
min = mid + 1;
}else{
return mid;
}
}
}
}
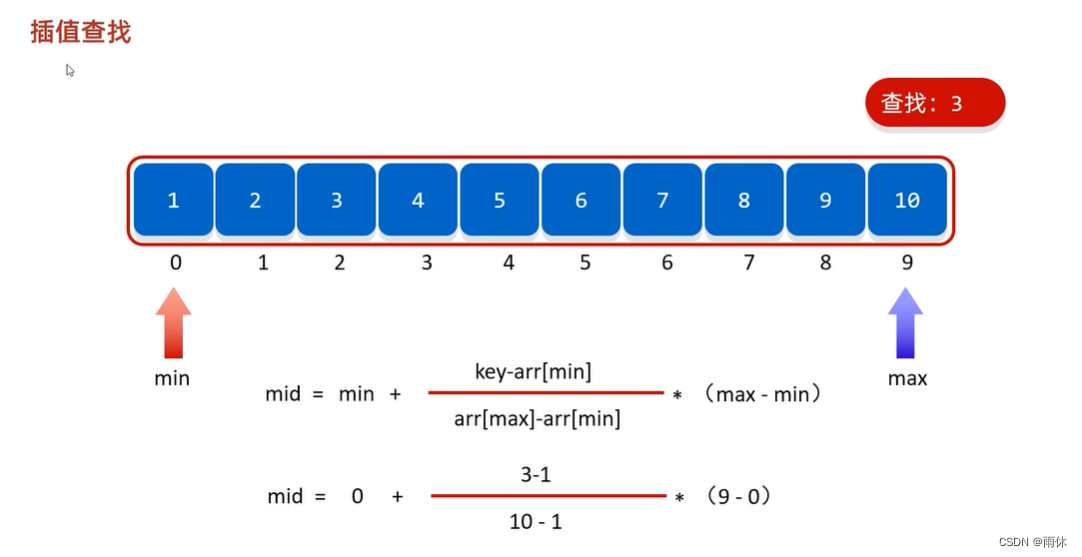
1.1.3 插值查找
mid = min+ key-arr[min]/arr[max]-arr[min] * (max-min)
1.1.4 斐波那契查找
根据黄金分割点来计算mid指向的位置
1.1.5 分块查找
原则:
- 前一块所有数据小于后一块所有数据(块内无序、块间有序)
- 块数的等于总数字个数开根号
- 思路:先确定查找的元素在哪一块,然后在块内查找
public class BlockSearch {
public static void main(String[] args) {
int[] arr = {16, 5, 9, 12, 21, 18, 32, 23, 37, 26, 45, 34, 50, 48, 61, 52, 73, 66};
// Creating blocks with their maximum values and their start and end indices in the array
Block b1 = new Block(21, 0, 5);
Block b2 = new Block(45, 6, 11);
Block b3 = new Block(73, 12, 17);
Block[] blockArr = {b1, b2, b3};
int number = 32; // The number we are searching for
// Find the block that might contain the number
int indexBlock = findIndexBlock(blockArr, number);
if (indexBlock == -1) {
System.out.println(false);
} else {
boolean found = false;
// Linear search within the identified block
for (int i = blockArr[indexBlock].getStartIndex(); i <= blockArr[indexBlock].getEndIndex(); i++) {
if (number == arr[i]) {
found = true;
System.out.println(true);
break;
}
}
if (!found) {
System.out.println(false);
}
}
}
private static int findIndexBlock(Block[] blockArr, int number) {
for (int i = 0; i < blockArr.length; i++) {
if (blockArr[i].getMax() >= number) {
return i;
}
}
return -1;
}
}
class Block {
private int max;
private int startIndex;
private int endIndex;
public Block(int max, int startIndex, int endIndex) {
this.max = max;
this.startIndex = startIndex;
this.endIndex = endIndex;
}
public int getMax() {
return max;
}
public int getStartIndex() {
return startIndex;
}
public int getEndIndex() {
return endIndex;
}
@Override
public String toString() {
return "Block{max = " + max + ", startIndex = " + startIndex + ", endIndex = " + endIndex + "}";
}
}
1.1.6 分块查找的扩展(无规律数据)
数据本身没有明显的规律,那么定义块的时候将(最大值,起始索引,结束索引)换成(最小值,最大值,起始索引),块的分割需要手动定义
public class BlockSearchDemo2 {
public static void main(String[] args) {
int[] arr = {27,22,30,40,36,
13,19,16,20,
7,10,
43,50,48};
int number = 30;
BlockSearch2 block1 = new BlockSearch2(22,40,0);
BlockSearch2 block2 = new BlockSearch2(13,20,5);
BlockSearch2 block3 = new BlockSearch2(7,10,9);
BlockSearch2 block4 = new BlockSearch2(43,50,11);
BlockSearch2[] blockArr = {block1,block2,block3,block4};
int index = findIndex(blockArr, number);
if(index == -1) {
System.out.println(false);
}else{
boolean flag = false;
for (int i = blockArr[index].getIndex(); i < blockArr[index + 1].getIndex(); i++) {
if(number == arr[i]){
flag = true;
System.out.println(true);
break;
}
}
if(!flag){
System.out.println(false);
}
}
}
private static int findIndex(BlockSearch2[] blockArr,int number){
for (int i = 0; i < blockArr.length; i++) {
if(number >= blockArr[i].getMin() && number <= blockArr[i].getMax()){
return i;
}
}
return -1;
}
}
class BlockSearch2 {
private int min;
private int max;
private int index;
public BlockSearch2() {
}
public BlockSearch2(int min, int max, int index) {
this.min = min;
this.max = max;
this.index = index;
}
/**
* 获取
* @return min
*/
public int getMin() {
return min;
}
/**
* 设置
* @param min
*/
public void setMin(int min) {
this.min = min;
}
/**
* 获取
* @return max
*/
public int getMax() {
return max;
}
/**
* 设置
* @param max
*/
public void setMax(int max) {
this.max = max;
}
/**
* 获取
* @return index
*/
public int getIndex() {
return index;
}
/**
* 设置
* @param index
*/
public void setIndex(int index) {
this.index = index;
}
public String toString() {
return "BlockSearch2{min = " + min + ", max = " + max + ", index = " + index + "}";
}
}
1.2 排序
1.2.1 冒泡排序
1.相邻元素两两比较,小的放前面,大的放后面
2.一轮循环结束,最大值已经找到,在数组最右
3.第二轮循环在剩余元素中找最大值
4.N个数据,进行N-1轮比较
public class sortdemo1 {
public static void main(String[] args) {
int[] arr = {2,4,5,3,1};
for(int i = 0; i < arr.length - 1;i++){//轮数
for(int j = 0;j < arr.length - i - 1;j++){//每一轮中如何比较数据并找到当前的最大值
if(arr[j] > arr[j + 1]){
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
}
1.2.2 选择排序
从0索引开始,拿着每一个元素跟后面的元素一次比较,小的放前面,大的放后面,以此类推.
public class SortDemo2 {
public static void main(String[] args) {
int[] arr = {2,4,5,3,1};
for (int i = 0; i < arr.length - 1; i++) {//这一轮拿哪个索引跟后面的数据比较
for (int j = i + 1; j < arr.length; j++) {//每一轮的比较
if(arr[i] > arr[j]){
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
}
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
}
1.2.3 插入排序
将0索引到N索引元素看作有序,将N+1索引到最后元素看作无序。遍历无序数据,将遍历到的元素插入适当位置,如果遇到相同数据,插在后面。
public class SortDemo3 {
public static void main(String[] args) {
int[] arr = {3,44,38,5,47,15,36,26,27,2,46,4,19,50,48};
//找到无序的那一组数据是从哪个索引开始的
int startIndex = -1;
for(int i = 0;i < arr.length; i++){
if(arr[i] > arr[i+1]){
startIndex = i; //有序的最后一个元素
break;
}
}
//遍历startindex开始到最后一个元素,依次得到无序的那一组每一个元素
for (int i = startIndex; i < arr.length-1; i++) {
for(int j = i + 1;j > 0;j--){ //从后往前找位置
if(arr[j] < arr[j-1]){
int temp = arr[j];
arr[j] = arr[j - 1];
arr[j - 1] = temp;
}else if(arr[j] >= arr[j-1]){
break;
}
}
}
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + " ");
}
}
}
1.2.4 快速排序
递归算法
递归指的是方法中调用方法本身的现象
注意: 递归一定要有出口,否则就会出现内存溢出
可以将一个复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解,递归策略只需少量程序就可以描述出解题过程所需要的多次重复计算.
快速排序
第一轮:把0索引的数组作为基准数,确定基准数在数组中正确的位置,比基准数小的或等于的全部在左边,比基准数大的全部在右边
画图!!!
public class QuickSortDemo {
public static void main(String[] args) {
int[] arr = {27, 22, 30, 40, 36, 13, 19, 16, 20, 7, 10, 43, 50, 48};
System.out.println("Unsorted array:");
printArray(arr);
quickSort(arr, 0, arr.length - 1);
System.out.println("Sorted array:");
printArray(arr);
}
// 快速排序主方法
public static void quickSort(int[] arr, int low, int high) {
if (low < high) {
int pi = partition(arr, low, high); // 获取分区索引
quickSort(arr, low, pi - 1); // 递归排序左子数组
quickSort(arr, pi + 1, high); // 递归排序右子数组
}
}
// 分区方法
public static int partition(int[] arr, int low, int high) {
int pivot = arr[low]; // 选择最左元素为基准
int i = low + 1; // 从第二个元素开始
int j = high;
while (i <= j){
// 找到第一个大于基准的元素
while (i <= j && arr[i] <= pivot) {
i++;
}
// 找到第一个小于基准的元素
while (i <= j && arr[j] > pivot) {
j--;
}
// 交换 arr[i] 和 arr[j]
if (i < j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
// 将基准放到正确的位置
int temp = arr[low];
arr[low] = arr[j];
arr[j] = temp;
return j; // 返回基准的索引
}
// 打印数组方法
public static void printArray(int[] arr) {
for (int i : arr) {
System.out.print(i + " ");
}
System.out.println();
}
}
2. 集合
2.1 基础集合
2.1.1 集合和数组的对比
1.长度:数组长度固定,集合长度可变
2.存储类型:数组:基本数据类型和引用数据类型;集合:引用数据类型,基本数据类型需要借用包装类来存储
2.1.2 ArrayList
1.打印:打印一个对象,默认情况下打印的是对象的类型名加上它的哈希码的十六进制形式,
ArrrayList重写了toString()方法,打印集合中存储的元素内容。
2.泛型: 进一步限定了集合中存储的对象类型,确保类型安全和明确的类型定义。(下面的String)
ArrayList<String> list = new ArrayList<String>();
ArrayList<String> list2 = new ArrayList<>();
ArrayList<Integer> intList = new ArrayList<>();
3.基本数据类型对应的包装类
byte->Byte
short->Short
char->Character
int->Integer
long->Long
float->Float
double->Double
boolean->Boolean
2.2 单列集合
List系列集合: 元素有序,可重复,有索引,添加元素永远返回值为True
Set系列集合: 元素无序,不可重复,无索引,添加元素已存在返回值为False
2.2.1 Collection单列集合
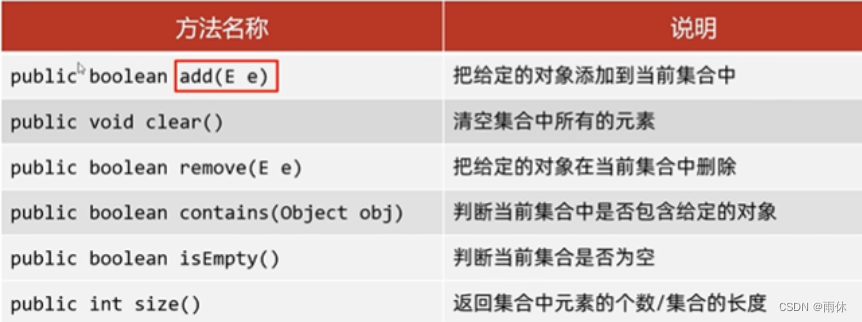
Collection 是单列集合的祖宗接口,功能是全部单列集合都可以继承使用
1.不能通过索引删除
2.删除元素不存在返回False
3.判断是否存在时,底层用equals方法实现的,集合存储自定义对象想通过contains方法判断,一定要重写equals方法
public class CollectionDemo1 {
public static void main(String[] args) {
Collection<String> coll= new ArrayList<>();
coll.add("aaa");
coll.add("bbb");
coll.add("ccc");
coll.clear();
coll.remove("ccc");
coll.contains("aaa");
boolean result2 = coll.isEmpty();
int size = coll.size();
}
}
2.2.1.1 Collection的遍历方式一:迭代器遍历
public class CollectionDemo2 {
public static void main(String[] args) {
Collection<String> coll = new ArrayList<>();
coll.add("aaa");
coll.add("bbb");
coll.add("ccc");
coll.add("ddd");
//获取迭代器对象,迭代器对象就好比是一个箭头,指向集合的0索引
Iterator<String> it = coll.iterator();
while(it.hasNext()){
String next = it.next();
System.out.println(next);
}
}
}
2.2.1.2 Collection的遍历方式二:增强for遍历
public class CollectionDemo3 {
public static void main(String[] args) {
Collection<String> coll = new ArrayList<>();
coll.add("aaa");
coll.add("bbb");
coll.add("ccc");
coll.add("ddd");
//简写:coll.for+回车
//注意:S其实就是一个第三方变量,在循环过程中依次表示集合中的每一个数据
for (String s : coll) {
System.out.println(s);
}
}
}
2.2.1.3 Collection的遍历方式三:Lambda表达式遍历
coll.forEach(s->System.out.println(s));
2.2.2 List集合
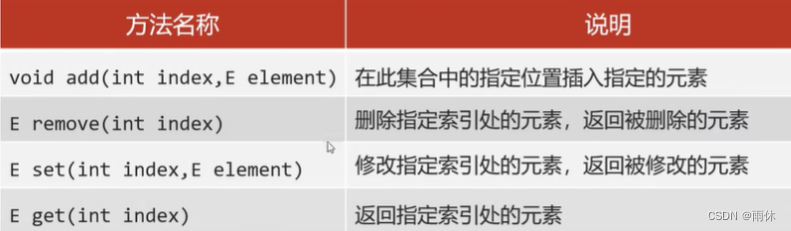
List集合独有的方法
public class ListDemo1 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
//再次集合中的指定位置插入指定元素
//细节:原来索引上的元素会依次后移
list.add(2,"ddd");
list.remove("ddd");
list.remove(0);//删除0索引上对应元素,并且将被删除元素作为返回值,其他元素前移
list.set(0,"qqq");//修改之后会将被修改的元素做一个返回
String s = list.get(0);
}
}
2.2.2.1 迭代器遍历
Iterator<String> it = list.iterator();
while(it.hasNext()){
sout(it.next());
}
2.2.2.2 增强for遍历方式
for(String s : list){
System.out.println(s);
}
2.2.2.3 Lambda表达式方式
list.forEach(s -> System.out.println(S));
2.2.2.4 普通for循环
for (int i = 0; i < list.size(); i++) {//集合的大小是list.size()
System.out.println(list.get(i));
}
2.2.2.5 列表迭代器
//列表迭代器
//获取列表迭代器的对象,里面的指针默认也是指向0索引的
//额外添加了一个方法:在便利的过程中,可以添加元素
ListIterator<String> it2 = list.listIterator();
while(it2.hasNext()){
String s = it2.next();
if(s.equals("bbb")){
it2.add("eee");
}
}
2.2.2.6 五种遍历方式对比

2.2.3 ArrayList集合
ArrayList集合底层原理
1.利用空参创建的集合,在底层创建一个默认长度为0的数组
2.添加第一个元素时,底层会创建一个新的长度为10的数组
3.存满时,会扩容1.5倍
4.如果一次添加多个元素,1.5倍放不下则新创建数组长度以实际为准
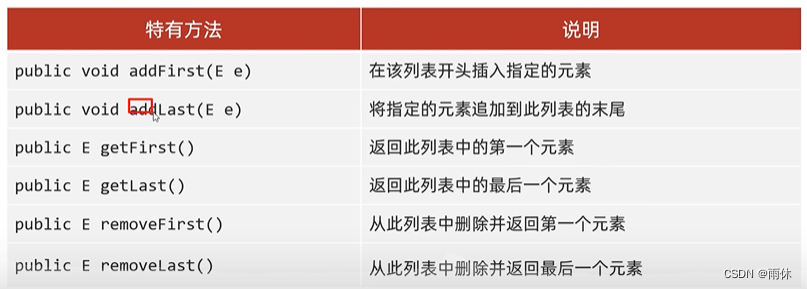
2.2.4 LinkedList集合
底层数据结构是双链表,查询慢,增删快,但是如果操作的是首尾元素,速度也是极快的
LinkList本身多了很多直接操作首尾元素的特有API
2.2.5 泛型深入
1.泛型: 是JDK5中引入的特性,可以在编译阶段约束操作的数据类型,并进行检查
2.格式: List
3.限制: 泛型只能支持引用数据类型
4.好处: 如果没有给集合指定类型,Java 默认认为集合中的所有数据类型都是 Object。这样,集合可以存储任意类型的数据。
在运行时期的问题提前到了编译期间,避免了强制类型转换可能出现的异常,因为在编译阶段类型就能确定下来。
5.劣势: 在获取数据时,由于数据类型被认为是 Object,无法直接使用其特有的方法和行为,需要进行类型转换。
6.泛型的扩展: Java中的泛型是伪泛型
当集合中想要添加元素时,集合验证数据类型与集合泛型是否符合,若符合加入集合。在集合内的存储中,数据类型为Object,当将数据取出集合后,又将数据类型转换为原来数据类型。
7.泛型的细节:
指定泛型的具体类型后,传递数据时,可以传入该类类型或者其子类类型
如果不写泛型,类型默认是Object
2.2.5.1 泛型类
当一个类中,某个变量的数据类型不确定时,就可以定义带有泛型的类
public class ArrayList<E>{
//此处E可以理解为变量,但是不是用来记录数据的,而是记录数据的类型,可以写成:T,E,K,V等
}
2.2.5.2 泛型方法
方法中形参类型不确定时,可以使用类名后面定义的泛型
1.使用类名后面定义的泛型-所有方法都能用
2.在方法申明上定义自己的泛型-只有本方法能用
public <T> void show(T t){
}
public static<E> void addAll(ArrayList<E> list,E...e){
// public:方法的访问修饰符,表示该方法可以被任何类调用。
// static:方法是静态的,可以直接通过类名调用,而不需要实例化该类。
// <E>:这是方法的泛型类型参数声明,表示方法是泛型方法。
// ArrayList<E> list:方法的第一个参数,类型为 ArrayList<E>,表示要添加元素的列表。
// E... e:方法的第二个参数,是一个可变参数,类型为 E。可变参数表示可以传入任意数量的 E 类型的参数(包括零个)。
for (E e1 : e) {
list.add(e1);
}
}
2.2.5.3 泛型接口
public interface List<E>{
}
使用方式
1.实现类给出具体类型
2.实现类延续泛型,创建对象时再确定
泛型的继承和通配符
1.泛型不具备继承性,但数据具备继承性
在泛型中,List 并不是 List 的子类,即使 Dog 是 Animal 的子类。
这意味着你不能将 List 赋值给 List。可以将 Dog 类型的数据放入 Animal 类型的容器中(例如 ArrayList)
2.2.6 Set集合
HashSet: 无序,不重复,无索引
LinkedHashSet: 有序,不重复,无索引
TreeSet: 可排序,不重复,无索引
Set接口中的方法上基本上与Collection的API一致
public class SetDemo1 {
public static void main(String[] args) {
Set<String> s= new HashSet<>();
boolean r1 = s.add("张三");
boolean r2 = s.add("lisi");
boolean r3 = s.add("wangwu");
//迭代器的方法遍历
Iterator<String> it = s.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
//Lamdba表达式方法
s.forEach(i-> System.out.println(i));
}
}
2.2.6 HashSet集合
HashSet底层原理
HashSet集合底层采取哈希表 存储数据
哈希值
1.哈希值根据HashCode方法算出来的int类型的整数
2.该方法定义在Object类中,所有对象都可以调用,默认使用地址值进行计算
3.一般情况下,会重写HashCode方法,利用对象内部的属性值计算哈希值
对象的哈希值特点
1.如果没有重写HashCode方法,不同对象 计算出的哈希值是不同的
2.如果已经重写HashCode方法,不同的对象只要属性值 相同,计算出的哈希值就是一样的
3.在小部分情况下,不同的属性值或者不同的地址值计算出来的哈希值也有可能一样(哈希碰撞 )
HashSet底层原理
1.创建一个默认长度为16,默认加载因子为0.75的数组,数组名为table
2.根据元素的哈希值跟数组长度计算出应存入的位置
3.判断当前位置是否为null,如果是null直接存入
4.如果位置不为null,表示有元素,则调用equals方法比较属性值
5.一样:不存 不一样:存入数组,形成链表
JDK8以前:新元素存入数组,老元素挂在新元素下面
JDK8以后:新元素直接挂在老元素下面
2.2.7 HashSet集合
有序,不重复,无索引
原理: 底层数据结构是依然哈希表,只是每个元素又额外的多了一个双链表的机制记录存储顺序
2.2.8 TreeSet集合
无重复,无索引,可排序
可排序:按照元素的默认规则(有小有大)排序
TreeSet集合底层是基于红黑树的数据结构实现排序的,增删改查性能都较好
TreeSet集合默认的规则
1.对于数值类型:Integer,Double,默认按照从小到大的顺序进行排序
2.对于字符,字符串:按照字符在ASCII码表中的数字升序进行排序a->b->c->…
TreeSet的两种比较方式
方式一:默认排序/自然排序: Javabean实现Comparable接口指定比较规则
方式二:比较器排序 创建TreeSet对象的时候,传递比较器Comparator制定规则
使用原则:默认使用第一种,如果第一种不能满足条件,再使用第二种

2.3 双列集合
特点:
1.单列集合每次添加一个元素,双列集合每次添加一对元素(键——不可重复,值——可以重复)
2.一对键和值称为键值对对象、键值对、Entry对象

2.3.1 Map集合
2.3.1.1 Map集合常用的API
1.Map是双列集合的顶层接口,它的功能是全部双列集合都可以继承使用的

2.put方法的细节:添加、覆盖
在添加数据时,如果键不存在,那么直接把键值对对象添加到map集合当中,方法返回null。
在添加数据时,如果键存在,那么会把原有的键值对对象覆盖,会把覆盖的原值进行返回。
3.remove方法的细节
在删除数据时,如果键存在,那么把键值对对象删除,返回被删除对象的值
在删除数据时,如果键不存在,返回null
2.3.1.2 遍历方式一:键找值
键不能重复,所以用set
1)将双列集合中的键统一提取出来,存入一个单列集合。
map.KeySet();返回值为双列集合的所有键,直接存入单列set集合
2)在单列集合中通过get方法获得对应的值
map.get(Key);通过键值找到双列集合中对应的值
public class A02_MapDemo2 {
public static void main(String[] args) {
//Map集合的第一种遍历方式
//创建Map对象
Map<String,String> m = new HashMap<>();
//添加元素
m.put("a","b");
m.put("c","d");
m.put("e","f");
//获取所有键,将键存入一个 单列集合当中
Set<String> keys = m.keySet();
//遍历单列集合,得到每一个键
for (String key : keys) {
String value = m.get(key);
System.out.println(key + "=" + value);
}
}
}
2.3.1.3 遍历方式二:键值对
1)获取双列集合中的所有键值对
map.entrySet();返回值为键值对对象entry的单列set集合,set集合里面的对象为entry对象
2)分别获取每一个键值对中的键和值
entry.getKey();
entry.getValue();
public class A03_MapDemo3 {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("a","b");
map.put("c","d");
map.put("e","f");
//通过键值对对象进行遍历
Set<Map.Entry<String, String>> entries = map.entrySet();//set里面是entry对象,entry里面装键和值
//由于entry是map接口里面的内部接口,所以需要外部接口.调用即Map.Entry
//遍历entries集合
for (Map.Entry<String, String> entry : entries) {
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key);
System.out.println(value);
}
}
}
2.3.1.4 遍历方式三:Lambda表达式
public class A04_MapDemo4 {
public static void main(String[] args) {
Map<String,String> map = new HashMap<>();
map.put("a","b");
map.put("c","d");
map.put("e","f");
//匿名内部类遍历
map.forEach(new BiConsumer<String, String>() {
@Override
public void accept(String key, String value) {
System.out.println(key + " " + value);
}
});
//lambda表达式遍历
map.forEach((String key, String value)-> {
System.out.println(key + " " + value);
}
);
map.forEach((key,value)->System.out.println(key + " " + value));
}
}
2.3.2 HashMap集合

2.3.3 LinkedHashMap
1)由键决定:有序、无重复、无索引
2)这里的有序指的是保证存储和取出元素的顺序一致
3)原理:底层数据元素依然是哈希表,只是每个键值对元素又额外多了一个双链表的机制记录存储的顺序。

2.3.4 TreeMap
1)TreeMap和TreeSet底层原理一样,都是红黑树结构的
2)由键决定特性:不重要、无索引、可排序
3)可排序:对键进行排序
4)注意:默认按照键的从小到大进行排序,也可以自己规定键的排序规则
代码书写两种规则
1)实现Comparable接口,指定比较规则
2)创建 集合时传递Comparator比较器对象,指定比较规则(二者都存在,以2为准)
2.3.5 集合工具类Collections
1)java.util.Collections:是集合工具类
2)作用:Collection不是集合,而是集合的工具类

public class CollectionsDemo1 {
public static void main(String[] args) {
//1.创建集合对象
ArrayList<String> list = new ArrayList<>();
//2.批量添加
Collections.addAll(list,"abc","aa","bb","cc");
System.out.println(list);
//3.打乱shuffle
Collections.shuffle(list);
System.out.println(list);
}
}
3 Stream流和方法引用
3.1 Stream流的思想
作用
结合了Lambda表达式,简化集合、数组的操作
使用步骤
1.得到stram流,把数据放上去
2.利用stream中的API进行各种操作
分类
1.中间方法:过滤、转换
2.终结方法:统计、打印
3.1.1 得到stram流,把数据放上去
1.单列集合
public class StreamDemo2 {
public static void main(String[] args) {
//1.单列集合获取Stream流
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list,"a","b","c","d","e");
//获取到一条流水线,并把集合中的数据放到流水线上
Stream<String> stream1 = list.stream();
//使用终结方法打印流水线上的数据
stream1.forEach(name-> System.out.println(name));
//list.stream().forEach(name-> System.out.println(name));
}
}
2.双列集合
public class SreamDemo3 {
public static void main(String[] args) {
//1.创建双列集合
HashMap<String,Integer> hm = new HashMap<>();
//2.添加数据
hm.put("aaa",111);
hm.put("bbb",222);
hm.put("ccc",333);
hm.put("ddd",444);
//3.获取stream流
hm.keySet().stream().forEach(s -> System.out.println(s));
hm.entrySet().stream().forEach(s -> System.out.println(s));
}
}
3.数组
public class StreamDemo4 {
public static void main(String[] args) {
//1.创建数组
int[] arr = {1,2,3,4,5,6,7,8,9,10};
String[] arr2 = {"a","b","c"};
//2.获取Stream流
Arrays.stream(arr).forEach(s-> System.out.println(s));
Arrays.stream(arr2).forEach(s-> System.out.println(s));
}
}
4.其他零散数据
public class StreamDemo5 {
public static void main(String[] args) {
//一堆零散数据,要求数据的种类相同
Stream.of(1,2,3,4,5).forEach(s-> System.out.println(s));
Stream.of("a","b","c","d","e").forEach(s-> System.out.println(s));
}
}
注意
1)方法的形参是一个可变参数,可以传递一堆零散的数据,也可以传递数组
2)但是数组必须是引用数据类型,如果传递基本数据类型,是会把整个数组当作一个元素,放到Stream当中。
3.1.2 中间方法

1)中间方法返回新的Stream流,原来的Stream流只能使用一次,建议使用链式编程
2)修改Stream流中的数据,不会影响原来集合或者数组中的数据
//filter 过滤,把开头的留下,其余的数据不要
list.stream().filter(s->s.startsWith("张")).forEach(s-> System.out.println(s));
//limit获取前几个元素
list.stream().
limit(3).
forEach(s-> System.out.println(s));
//skip跳过前几个元素
list.stream().
skip(3).
forEach(s-> System.out.println(s));
//distinct 元素去重,依赖(hashCode和equals方法)
list1.stream().distinct().forEach(s-> System.out.println(s));
//concat 合并a和b两个流为一个流
Stream.concat(list1.stream(),list2.stream()).forEach(s-> System.out.println(s));
list.stream().
map(s->Integer.parseInt(s.split("-")[1])).
forEach(s-> System.out.println(s));
3.1.3 终结方法

list.stream().forEach(s-> System.out.println(s));
long count = list.stream().count();
System.out.println(count);
String[] arr2 = list.stream().toArray(value -> new String[value]);
其他
Arrays
操作数组的工具类
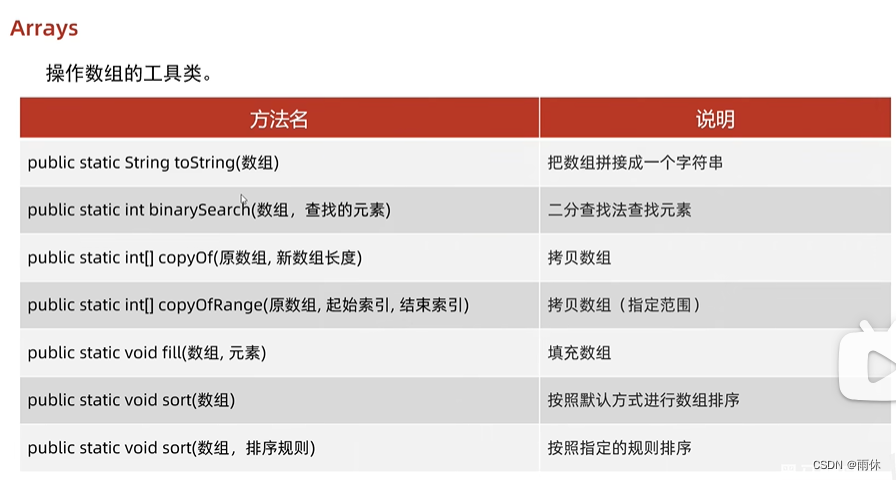
import java.util.Arrays;
public class ToStringDemo {
public static void main(String[] args) {
int[] intArray = {1, 2, 3, 4, 5};
System.out.println(Arrays.toString(intArray)); // 输出: [1, 2, 3, 4, 5]
String[] stringArray = {"Hello", "World", "Java"};
System.out.println(Arrays.toString(stringArray)); // 输出: [Hello, World, Java]
char[] charArray = {'a', 'b', 'c', 'd'};
System.out.println(Arrays.toString(charArray)); // 输出: [a, b, c, d]
double[] doubleArray = {1.1, 2.2, 3.3, 4.4};
System.out.println(Arrays.toString(doubleArray)); // 输出: [1.1, 2.2, 3.3, 4.4]
}
}
Lambda表达式
函数式编程
面向对象先找对象,让对象做事情
Arrays.sort(arr,new Comparator<Integer>(){
public int compare(Integer o1,Integer o2){
return o1 - o2;
}
});
函数式编程忽略面向对象的复杂语法,强调做什么,而不是谁去做
Lambda表达式就是函数式思想的体现
格式
() -> {
}
1.() 对应着方法的形参
2.-> 固定格式
3.{} 对应方法的方法体
Arrays.sort(arr,(Integer o1,Integer o2)->{
return o1 - o2;
});
注意:
1.Lambda表达式可以用来简化匿名内部类的书写
2.Lambda表达式只能简化函数式接口 的匿名内部类的写法
3.函数式接口 :有且只有一个抽象方法的接口叫做函数式接口,接口上方可以加@FunctionalInterface注解