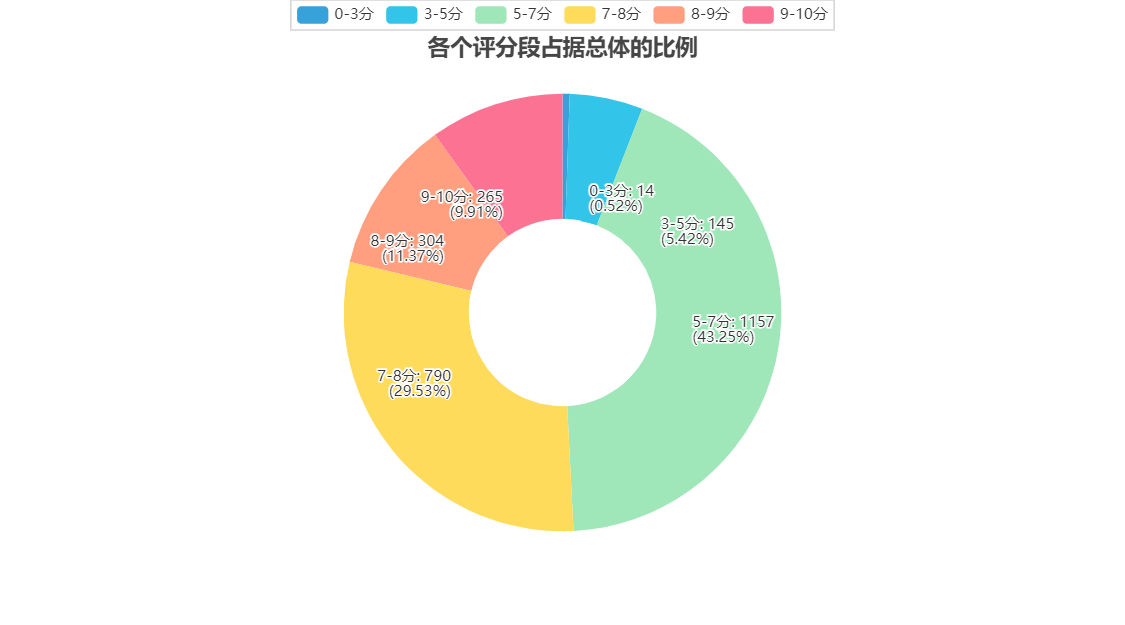
Mindspore 应用(2)ResNet50迁移学习
在实际应用场景中,由于训练数据集不足,所以很少有人会从头开始训练整个网络。普遍的做法是,在一个非常大的基础数据集上训练得到一个预训练模型,然后使用该模型来初始化网络的权重参数或作为固定特征提取器应用于特定的任务中。本章将使用迁移学习的方法对ImageNet数据集中的狼和狗图像进行分类。
迁移学习详细内容见Stanford University CS231n。
数据准备
下载数据集
下载案例所用到的狗与狼分类数据集,数据集中的图像来自于ImageNet,每个分类有大约120张训练图像与30张验证图像。使用download接口下载数据集,并将下载后的数据集自动解压到当前目录下。
def say_hi(name: str) -> str:
return f'Hi {name}'
greeting = say_hi(123)
print(greeting)
Hi 123
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14
# 查看当前 mindspore 版本
!pip show mindspore
Name: mindspore
Version: 2.2.14
Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios.
Home-page: https://www.mindspore.cn
Author: The MindSpore Authors
Author-email: contact@mindspore.cn
License: Apache 2.0
Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages
Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy
Required-by:
from download import download
dataset_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/intermediate/Canidae_data.zip"
download(dataset_url, "./datasets-Canidae", kind="zip", replace=True)
Creating data folder...
Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/intermediate/Canidae_data.zip (11.3 MB)
file_sizes: 100%|██████████████████████████| 11.9M/11.9M [00:00<00:00, 92.3MB/s]
Extracting zip file...
Successfully downloaded / unzipped to ./datasets-Canidae
'./datasets-Canidae'
数据集的目录结构如下:
datasets-Canidae/data/
└── Canidae
├── train
│ ├── dogs
│ └── wolves
└── val
├── dogs
└── wolves
加载数据集
狼狗数据集提取自ImageNet分类数据集,使用mindspore.dataset.ImageFolderDataset接口来加载数据集,并进行相关图像增强操作。
首先执行过程定义一些输入:
batch_size = 18 # 批量大小
image_size = 224 # 训练图像空间大小
num_epochs = 50 # 训练周期数
lr = 0.001 # 学习率
momentum = 0.9 # 动量
workers = 4 # 并行线程个数
import mindspore as ms
import mindspore.dataset as ds
import mindspore.dataset.vision as vision
# 数据集目录路径
data_path_train = "./datasets-Canidae/data/Canidae/train/"
data_path_val = "./datasets-Canidae/data/Canidae/val/"
# 创建训练数据集
def create_dataset_canidae(dataset_path, usage):
"""数据加载"""
data_set = ds.ImageFolderDataset(dataset_path,
num_parallel_workers=workers,
shuffle=True,)
# 数据增强操作
mean = [0.485 * 255, 0.456 * 255, 0.406 * 255]
std = [0.229 * 255, 0.224 * 255, 0.225 * 255]
scale = 32
if usage == "train":
# Define map operations for training dataset
trans = [
vision.RandomCropDecodeResize(size=image_size, scale=(0.08, 1.0), ratio=(0.75, 1.333)),
vision.RandomHorizontalFlip(prob=0.5),
vision.Normalize(mean=mean, std=std),
vision.HWC2CHW()
]
else:
# Define map operations for inference dataset
trans = [
vision.Decode(),
vision.Resize(image_size + scale),
vision.CenterCrop(image_size),
vision.Normalize(mean=mean, std=std),
vision.HWC2CHW()
]
# 数据映射操作
data_set = data_set.map(
operations=trans,
input_columns='image',
num_parallel_workers=workers)
# 批量操作
data_set = data_set.batch(batch_size)
return data_set
dataset_train = create_dataset_canidae(data_path_train, "train")
step_size_train = dataset_train.get_dataset_size()
dataset_val = create_dataset_canidae(data_path_val, "val")
step_size_val = dataset_val.get_dataset_size()
数据集可视化
从mindspore.dataset.ImageFolderDataset接口中加载的训练数据集返回值为字典,用户可通过 create_dict_iterator 接口创建数据迭代器,使用 next 迭代访问数据集。本章中 batch_size 设为18,所以使用 next 一次可获取18个图像及标签数据。
data = next(dataset_train.create_dict_iterator())
images = data["image"]
labels = data["label"]
print("Tensor of image", images.shape)
print("Labels:", labels)
Tensor of image (18, 3, 224, 224)
Labels: [0 1 0 1 0 0 0 0 1 1 0 0 0 1 1 0 0 1]
对获取到的图像及标签数据进行可视化,标题为图像对应的label名称。
import matplotlib.pyplot as plt
import numpy as np
# class_name对应label,按文件夹字符串从小到大的顺序标记label
class_name = {0: "dogs", 1: "wolves"}
plt.figure(figsize=(5, 5))
for i in range(4):
# 获取图像及其对应的label
data_image = images[i].asnumpy()
data_label = labels[i]
# 处理图像供展示使用
data_image = np.transpose(data_image, (1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
data_image = std * data_image + mean
data_image = np.clip(data_image, 0, 1)
# 显示图像
plt.subplot(2, 2, i+1)
plt.imshow(data_image)
plt.title(class_name[int(labels[i].asnumpy())])
plt.axis("off")
plt.show()

训练模型
本章使用ResNet50模型进行训练。搭建好模型框架后,通过将pretrained参数设置为True来下载ResNet50的预训练模型并将权重参数加载到网络中。
构建Resnet50网络
from typing import Type, Union, List, Optional
from mindspore import nn, train
from mindspore.common.initializer import Normal
weight_init = Normal(mean=0, sigma=0.02)
gamma_init = Normal(mean=1, sigma=0.02)
class ResidualBlockBase(nn.Cell):
expansion: int = 1 # 最后一个卷积核数量与第一个卷积核数量相等
def __init__(self, in_channel: int, out_channel: int,
stride: int = 1, norm: Optional[nn.Cell] = None,
down_sample: Optional[nn.Cell] = None) -> None:
super(ResidualBlockBase, self).__init__()
if not norm:
self.norm = nn.BatchNorm2d(out_channel)
else:
self.norm = norm
self.conv1 = nn.Conv2d(in_channel, out_channel,
kernel_size=3, stride=stride,
weight_init=weight_init)
self.conv2 = nn.Conv2d(in_channel, out_channel,
kernel_size=3, weight_init=weight_init)
self.relu = nn.ReLU()
self.down_sample = down_sample
def construct(self, x):
"""ResidualBlockBase construct."""
identity = x # shortcuts分支
out = self.conv1(x) # 主分支第一层:3*3卷积层
out = self.norm(out)
out = self.relu(out)
out = self.conv2(out) # 主分支第二层:3*3卷积层
out = self.norm(out)
if self.down_sample is not None:
identity = self.down_sample(x)
out += identity # 输出为主分支与shortcuts之和
out = self.relu(out)
return out
class ResidualBlock(nn.Cell):
expansion = 4 # 最后一个卷积核的数量是第一个卷积核数量的4倍
def __init__(self, in_channel: int, out_channel: int,
stride: int = 1, down_sample: Optional[nn.Cell] = None) -> None:
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channel, out_channel,
kernel_size=1, weight_init=weight_init)
self.norm1 = nn.BatchNorm2d(out_channel)
self.conv2 = nn.Conv2d(out_channel, out_channel,
kernel_size=3, stride=stride,
weight_init=weight_init)
self.norm2 = nn.BatchNorm2d(out_channel)
self.conv3 = nn.Conv2d(out_channel, out_channel * self.expansion,
kernel_size=1, weight_init=weight_init)
self.norm3 = nn.BatchNorm2d(out_channel * self.expansion)
self.relu = nn.ReLU()
self.down_sample = down_sample
def construct(self, x):
identity = x # shortscuts分支
out = self.conv1(x) # 主分支第一层:1*1卷积层
out = self.norm1(out)
out = self.relu(out)
out = self.conv2(out) # 主分支第二层:3*3卷积层
out = self.norm2(out)
out = self.relu(out)
out = self.conv3(out) # 主分支第三层:1*1卷积层
out = self.norm3(out)
if self.down_sample is not None:
identity = self.down_sample(x)
out += identity # 输出为主分支与shortcuts之和
out = self.relu(out)
return out
def make_layer(last_out_channel, block: Type[Union[ResidualBlockBase, ResidualBlock]],
channel: int, block_nums: int, stride: int = 1):
down_sample = None # shortcuts分支
if stride != 1 or last_out_channel != channel * block.expansion:
down_sample = nn.SequentialCell([
nn.Conv2d(last_out_channel, channel * block.expansion,
kernel_size=1, stride=stride, weight_init=weight_init),
nn.BatchNorm2d(channel * block.expansion, gamma_init=gamma_init)
])
layers = []
layers.append(block(last_out_channel, channel, stride=stride, down_sample=down_sample))
in_channel = channel * block.expansion
# 堆叠残差网络
for _ in range(1, block_nums):
layers.append(block(in_channel, channel))
return nn.SequentialCell(layers)
from mindspore import load_checkpoint, load_param_into_net
class ResNet(nn.Cell):
def __init__(self, block: Type[Union[ResidualBlockBase, ResidualBlock]],
layer_nums: List[int], num_classes: int, input_channel: int) -> None:
super(ResNet, self).__init__()
self.relu = nn.ReLU()
# 第一个卷积层,输入channel为3(彩色图像),输出channel为64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, weight_init=weight_init)
self.norm = nn.BatchNorm2d(64)
# 最大池化层,缩小图片的尺寸
self.max_pool = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode='same')
# 各个残差网络结构块定义,
self.layer1 = make_layer(64, block, 64, layer_nums[0])
self.layer2 = make_layer(64 * block.expansion, block, 128, layer_nums[1], stride=2)
self.layer3 = make_layer(128 * block.expansion, block, 256, layer_nums[2], stride=2)
self.layer4 = make_layer(256 * block.expansion, block, 512, layer_nums[3], stride=2)
# 平均池化层
self.avg_pool = nn.AvgPool2d()
# flattern层
self.flatten = nn.Flatten()
# 全连接层
self.fc = nn.Dense(in_channels=input_channel, out_channels=num_classes)
def construct(self, x):
x = self.conv1(x)
x = self.norm(x)
x = self.relu(x)
x = self.max_pool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avg_pool(x)
x = self.flatten(x)
x = self.fc(x)
return x
def _resnet(model_url: str, block: Type[Union[ResidualBlockBase, ResidualBlock]],
layers: List[int], num_classes: int, pretrained: bool, pretrianed_ckpt: str,
input_channel: int):
model = ResNet(block, layers, num_classes, input_channel)
if pretrained:
# 加载预训练模型
download(url=model_url, path=pretrianed_ckpt, replace=True)
param_dict = load_checkpoint(pretrianed_ckpt)
load_param_into_net(model, param_dict)
return model
def resnet50(num_classes: int = 1000, pretrained: bool = False):
"ResNet50模型"
resnet50_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/models/application/resnet50_224_new.ckpt"
resnet50_ckpt = "./LoadPretrainedModel/resnet50_224_new.ckpt"
return _resnet(resnet50_url, ResidualBlock, [3, 4, 6, 3], num_classes,
pretrained, resnet50_ckpt, 2048)
固定特征进行训练
使用固定特征进行训练的时候,需要冻结除最后一层之外的所有网络层。通过设置 requires_grad == False 冻结参数,以便不在反向传播中计算梯度。
import mindspore as ms
import matplotlib.pyplot as plt
import os
import time
net_work = resnet50(pretrained=True)
# 全连接层输入层的大小
in_channels = net_work.fc.in_channels
# 输出通道数大小为狼狗分类数2
head = nn.Dense(in_channels, 2)
# 重置全连接层
net_work.fc = head
# 平均池化层kernel size为7
avg_pool = nn.AvgPool2d(kernel_size=7)
# 重置平均池化层
net_work.avg_pool = avg_pool
# 冻结除最后一层外的所有参数
for param in net_work.get_parameters():
if param.name not in ["fc.weight", "fc.bias"]:
param.requires_grad = False
# 定义优化器和损失函数
opt = nn.Momentum(params=net_work.trainable_params(), learning_rate=lr, momentum=0.5)
loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
def forward_fn(inputs, targets):
logits = net_work(inputs)
loss = loss_fn(logits, targets)
return loss
grad_fn = ms.value_and_grad(forward_fn, None, opt.parameters)
def train_step(inputs, targets):
loss, grads = grad_fn(inputs, targets)
opt(grads)
return loss
# 实例化模型
model1 = train.Model(net_work, loss_fn, opt, metrics={"Accuracy": train.Accuracy()})
Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/models/application/resnet50_224_new.ckpt (97.7 MB)
file_sizes: 100%|█████████████████████████████| 102M/102M [00:00<00:00, 137MB/s]
Successfully downloaded file to ./LoadPretrainedModel/resnet50_224_new.ckpt
训练和评估
开始训练模型,与没有预训练模型相比,将节约一大半时间,因为此时可以不用计算部分梯度。保存评估精度最高的ckpt文件于当前路径的./BestCheckpoint/resnet50-best-freezing-param.ckpt。
import mindspore as ms
import matplotlib.pyplot as plt
import os
import time
dataset_train = create_dataset_canidae(data_path_train, "train")
step_size_train = dataset_train.get_dataset_size()
dataset_val = create_dataset_canidae(data_path_val, "val")
step_size_val = dataset_val.get_dataset_size()
num_epochs = 5
# 创建迭代器
data_loader_train = dataset_train.create_tuple_iterator(num_epochs=num_epochs)
data_loader_val = dataset_val.create_tuple_iterator(num_epochs=num_epochs)
best_ckpt_dir = "./BestCheckpoint"
best_ckpt_path = "./BestCheckpoint/resnet50-best-freezing-param.ckpt"
import mindspore as ms
import matplotlib.pyplot as plt
import os
import time
# 开始循环训练
print("Start Training Loop ...")
best_acc = 0
for epoch in range(num_epochs):
losses = []
net_work.set_train()
epoch_start = time.time()
# 为每轮训练读入数据
for i, (images, labels) in enumerate(data_loader_train):
labels = labels.astype(ms.int32)
loss = train_step(images, labels)
losses.append(loss)
# 每个epoch结束后,验证准确率
acc = model1.eval(dataset_val)['Accuracy']
epoch_end = time.time()
epoch_seconds = (epoch_end - epoch_start) * 1000
step_seconds = epoch_seconds/step_size_train
print("-" * 20)
print("Epoch: [%3d/%3d], Average Train Loss: [%5.3f], Accuracy: [%5.3f]" % (
epoch+1, num_epochs, sum(losses)/len(losses), acc
))
print("epoch time: %5.3f ms, per step time: %5.3f ms" % (
epoch_seconds, step_seconds
))
if acc > best_acc:
best_acc = acc
if not os.path.exists(best_ckpt_dir):
os.mkdir(best_ckpt_dir)
ms.save_checkpoint(net_work, best_ckpt_path)
print("=" * 80)
print(f"End of validation the best Accuracy is: {best_acc: 5.3f}, "
f"save the best ckpt file in {best_ckpt_path}", flush=True)
Start Training Loop ...
--------------------
Epoch: [ 1/ 5], Average Train Loss: [0.667], Accuracy: [0.583]
epoch time: 175554.276 ms, per step time: 12539.591 ms
--------------------
Epoch: [ 2/ 5], Average Train Loss: [0.572], Accuracy: [0.817]
epoch time: 1043.899 ms, per step time: 74.564 ms
--------------------
Epoch: [ 3/ 5], Average Train Loss: [0.506], Accuracy: [0.983]
epoch time: 849.647 ms, per step time: 60.689 ms
--------------------
Epoch: [ 4/ 5], Average Train Loss: [0.439], Accuracy: [0.983]
epoch time: 885.925 ms, per step time: 63.280 ms
--------------------
Epoch: [ 5/ 5], Average Train Loss: [0.418], Accuracy: [0.983]
epoch time: 1015.336 ms, per step time: 72.524 ms
================================================================================
End of validation the best Accuracy is: 0.983, save the best ckpt file in ./BestCheckpoint/resnet50-best-freezing-param.ckpt
可视化模型预测
使用固定特征得到的best.ckpt文件对对验证集的狼和狗图像数据进行预测。若预测字体为蓝色即为预测正确,若预测字体为红色则预测错误。
import matplotlib.pyplot as plt
import mindspore as ms
def visualize_model(best_ckpt_path, val_ds):
net = resnet50()
# 全连接层输入层的大小
in_channels = net.fc.in_channels
# 输出通道数大小为狼狗分类数2
head = nn.Dense(in_channels, 2)
# 重置全连接层
net.fc = head
# 平均池化层kernel size为7
avg_pool = nn.AvgPool2d(kernel_size=7)
# 重置平均池化层
net.avg_pool = avg_pool
# 加载模型参数
param_dict = ms.load_checkpoint(best_ckpt_path)
ms.load_param_into_net(net, param_dict)
model = train.Model(net)
# 加载验证集的数据进行验证
data = next(val_ds.create_dict_iterator())
images = data["image"].asnumpy()
labels = data["label"].asnumpy()
class_name = {0: "dogs", 1: "wolves"}
# 预测图像类别
output = model.predict(ms.Tensor(data['image']))
pred = np.argmax(output.asnumpy(), axis=1)
# 显示图像及图像的预测值
plt.figure(figsize=(5, 5))
for i in range(4):
plt.subplot(2, 2, i + 1)
# 若预测正确,显示为蓝色;若预测错误,显示为红色
color = 'blue' if pred[i] == labels[i] else 'red'
plt.title('predict:{}'.format(class_name[pred[i]]), color=color)
picture_show = np.transpose(images[i], (1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
picture_show = std * picture_show + mean
picture_show = np.clip(picture_show, 0, 1)
plt.imshow(picture_show)
plt.axis('off')
plt.show()
visualize_model(best_ckpt_path, dataset_val)


import time
L = time.localtime()
print(time.
心得
迭代50次,效果还是很显著的,不错不错。