目录
1 引言
1.1 研究背景
1.2 研究目的
1.3 研究意义
2 相关技术介绍
2.1 Python语言及其应用领域
2.2 网络爬虫技术
2.3 数据可视化技术
2.4 PyCharm
2.5 Jupyter Notebook
3 数据爬取
4 数据预处理
5 数据分析及可视化
5.1数据分析背景
5.2从电影评分角度分析
5.3从评论人数与评分角度分析
5.4从电影年份角度分析
5.5从电影数量及类型分析
结 论
附 录
1 引言
1.1 研究背景
随着电影市场规模的不断扩大,越来越多的人开始关注电影市场和电影数据。然而,市面上的电影数据分析工具相对较少,而且大多需要付费,因此,自己使用Python编写爬虫程序爬取电影数据并进行可视化分析成为了一种较为便捷的方法。
1.2 研究目的
本报告旨在使用Python编写爬虫程序,爬取2016至2023年电影市场的相关数据,并进行可视化分析,以探讨电影市场的发展趋势、不同类型电影的受众群体以及电影市场的经济效益等问题。
1.3 研究意义
这个研究的意义在于,通过利用Python编程语言和网络爬虫技术,对电影信息进行爬取、清洗和存储,并利用数据可视化技术对数据进行分析和展示,从而揭示出电影市场的一些规律和趋势,为电影从业者和观众提供决策支持和参考。
具体来说,这个研究可以帮助电影从业者了解电影市场的竞争情况,找到更加有利的电影制作方向和策略,提高电影的票房和口碑;同时,观众可以通过分析和评估电影的评分、类型、时长、制片国家、发行时间等信息,更好地选择自己感兴趣的电影,提高观影体验和满意度。
此外,这个研究还可以为数据科学和数据可视化领域的研究提供一个具体的应用案例,拓展了相关领域的研究范围和深度,对于推动数据科学和数据可视化技术的发展和应用具有积极的促进作用。
2 相关技术介绍
2.1 Python语言及其应用领域
Python是一种高级编程语言,具有简单易学、优雅简洁、功能强大、可移植性好等特点,在科学计算、数据分析、人工智能、Web开发、自动化测试等领域广泛应用。
Python的应用领域包括但不限于以下几个方面:
1. 数据科学和数据分析:Python拥有丰富的数据处理和分析库,如NumPy、Pandas、SciPy、Matplotlib等,可以用于数据清洗、可视化和分析,被广泛应用于数据科学和数据分析领域。
2. 人工智能和机器学习:Python拥有强大的机器学习和深度学习库,如TensorFlow、PyTorch、Keras等,可以用于图像识别、自然语言处理、智能推荐等领域的开发和应用。
3. Web开发:Python拥有流行的Web框架,如Django、Flask等,可以用于Web应用的开发和部署。
4. 自动化测试:Python可以用于自动化测试,如Selenium、Pytest等,可以用于Web应用、移动应用、桌面应用等领域的自动化测试和持续集成。
5. 游戏开发:Python可以用于游戏开发,如Pygame等,可以用于2D/3D游戏的开发和制作。
总之,Python具有广泛的应用领域和优秀的生态系统,成为了现代编程语言中的热门选项之一。
2.2 网络爬虫技术
网络爬虫技术(Web scraping)是指利用计算机程序自动化地抓取互联网上的数据,通常是从网页中提取文本、图片、视频等信息。网络爬虫技术可以帮助我们快速地获取互联网上的大量数据,从而进行数据分析、挖掘和应用开发。
网络爬虫技术通常分为以下几个步骤:
1. 确定目标网站:确定需要爬取的目标网站,并确定需要爬取的信息类型和格式。
2. 分析网站结构:分析目标网站的网页结构和数据布局,以便能够准确地提取所需数据。
3. 编写爬虫程序:根据分析结果,编写爬虫程序,使用HTTP请求和解析HTML等技术实现网页抓取和数据提取。
4. 存储数据:将抓取的数据存储到本地文件或数据库中,以备后续分析和应用。
网络爬虫技术在各个领域都有着广泛的应用,如商业数据分析、舆情监测、搜索引擎优化、新闻媒体采集、科学研究等。但需要注意的是,在使用网络爬虫技术时,需要遵守相关法律法规和网站的使用条款,不得对他人的隐私和知识产权造成侵犯。
2.3 数据可视化技术
数据可视化技术是指利用图形、图表、地图等视觉化方式,将数据转化为易于理解和分析的形式,以便更好地发现数据之间的关系、趋势和规律。数据可视化技术可以帮助我们更加直观地理解和展示数据,从而支持数据驱动的决策和应用开发。
数据可视化技术通常包括以下几个方面:
1. 数据预处理:在进行数据可视化之前,需要对数据进行清洗、处理和转换,以便更好地适应数据可视化的需求。
2. 可视化设计:根据数据特点和分析目的,选择合适的可视化技术和设计风格,以便更好地呈现数据。
3. 可视化实现:使用数据可视化库或工具,如D3.js、Tableau、matplotlib等,将数据转化为图形或图表进行展示。
4. 可视化交互:通过添加交互功能,如鼠标悬停、点击、拖动等,增强数据可视化的互动性和体验性。
数据可视化技术在各个领域都有着广泛的应用,如商业数据分析、科学研究、新闻媒体采集、政府公共服务等。它可以帮助我们更好地理解和发现数据,从而支持决策和创新。但需要注意的是,在进行数据可视化时,需要遵循一些设计原则和规范,以便更好地传达数据信息和表达分析结果。
2.4 PyCharm
PyCharm是一款由JetBrains公司开发的Python集成开发环境(IDE),是Python开发者广泛使用的工具之一。PyCharm提供了丰富的功能和工具,可以帮助开发者提高开发效率和代码质量。
PyCharm的功能包括但不限于以下几个方面:
1. 代码编辑:PyCharm提供了强大的代码编辑功能,包括代码补全、语法高亮、代码格式化等,可以帮助开发者快速编写Python代码。
2. 代码调试:PyCharm提供了强大的调试功能,可以帮助开发者快速定位和修复代码中的错误。
3. 版本控制:PyCharm集成了多种版本控制工具,包括Git、SVN等,可以帮助开发者管理代码版本和协作开发。
4. 集成开发环境:PyCharm集成了多个Python开发相关工具和库,如Pip、Virtualenv、Django等,可以帮助开发者更加便捷地进行开发。
5. 自动化测试:PyCharm提供了多种自动化测试工具和框架,如unittest、pytest等,可以帮助开发者快速编写和运行自动化测试。
总之,PyCharm是一款功能强大的Python集成开发环境,可以帮助开发者提高开发效率和代码质量,是Python开发者不可或缺的工具之一。
2.5 Jupyter Notebook
Jupyter Notebook是一款交互式的Web应用程序,可以创建、编辑和共享包含代码、公式、可视化和说明文档等多种元素的文档,支持多种编程语言,包括Python、R、Julia等。Jupyter Notebook通常作为Anaconda Python发行版的一部分提供,也可以单独安装使用。
Jupyter Notebook的特点包括但不限于以下几个方面:
1. 交互性:Jupyter Notebook可以与用户进行交互,允许用户在Web界面中编写和执行代码,并实时显示代码执行结果。
2. 可视化:Jupyter Notebook支持多种可视化元素,如图表、图片、视频等,可以帮助用户更好地展示数据和分析结果。
3. 共享性:Jupyter Notebook可以通过互联网和本地网络共享,方便用户分享和协作开发。
4. 可扩展性:Jupyter Notebook支持多种插件和扩展,可以增强其功能和应用范围。
5. 支持多种编程语言:Jupyter Notebook支持多种编程语言,如Python、R、Julia等,可以满足不同用户的需求。
总之,Jupyter Notebook是一款强大的交互式Web应用程序,可以帮助用户更好地展示和分析数据,提高工作效率和代码质量。作为Anaconda Python发行版的一部分,Jupyter Notebook已经成为Python数据科学和机器学习领域的重要工具之一。
3 数据爬取
爬取数据的步骤如下:
- 确定爬取的目标网站:首先需要确定需要爬取的目标网站,并了解该网站的数据结构和页面布局。
- 分析目标网站的数据结构和页面布局:对于目标网站的数据结构和页面布局,可以使用浏览器的开发者工具进行查看分析。
- 编写爬虫程序:在了解目标网站的数据结构和页面布局之后,可以开始编写爬虫程序。
- 运行爬虫程序:运行爬虫程序时,需要注意一些反爬虫机制,如请求头、访问频率、验证码等,可以使用一些反反爬虫技巧,如使用代理、设置访问间隔、分布式爬虫等。
- 存储数据:将爬取到的数据存储到本地文件或数据库中,以便后续的使用和分析。
本报告从名为阳光电影的网站上爬取电影信息。脚本使用requests库发送GET请求来获取网站的HTML内容。然后,使用lxml库解析HTML内容并提取相关信息。脚本还使用csv库将提取的信息写入CSV文件。脚本还使用fake_useragent库为每个请求生成一个随机的用户代理,以防止被网站屏蔽。最后,脚本使用logging库记录任何在爬取过程中出现的错误。
脚本定义了两个函数“get_detail”和“spider”:
“get_detail”函数接受两个参数:视频详情页的URL和CSV写入器(csvwriter),用于获取视频的详情信息并将其写入CSV文件中。函数首先将详情页的URL拼接成完整的URL,然后使用requests库向该URL发送GET请求,获取详情页面的HTML文本。接下来,使用GBK编码解码HTML文本,并使用lxml.etree解析HTML文本,然后从HTML文本中提取出各种电影详情信息,如电影的中文译名、原名、产地、类型、语言、上映日期、豆瓣评分、时长、导演和演员列表等信息,并将其保存在一个字典中。在提取完所有的视频详情信息后,函数会使用logging库记录日志,并将视频信息写入CSV文件中。如果写入CSV文件时发生错误,将会使用error_logger记录错误日志。
“spider”函数接受一个参数pages,用于指定爬取的页数,其主要功能是爬取指定页数的视频信息,并将其保存到CSV文件中。函数首先打开CSV文件,并使用csv.DictWriter写入表头。然后,使用循环遍历每一页,构造每一页的URL,并发送GET请求,获取每一页的HTML文本,并使用lxml.etree解析HTML文本。接下来,从每一页中提取出所有的详情链接,并遍历每个详情链接,调用get_video_detail函数获取视频详情信息,并使用csv.DictWriter将其写入CSV文件中。在遍历每个详情链接时,函数还会随机暂停1-3秒,以防止被反爬识别。在每一页爬取完毕后,函数会使用logging库记录日志,提示每一页爬取完毕。
最后,启动爬虫程序。调用“spider”函数,并传递了一个参数120,表示需要爬取120页的电影信息。
4 数据预处理
在真实世界里,数据来源各式各样质量良莠不齐,所以原始数据一般是有缺陷的,不完整的,重复的,是极易受侵染的。这样的数据处理起来不仅效率低下而且结果也不尽人意,这种情况下数据的预处理显得尤为重要。一方面,数据预处理把原始数据规范化、条理化,最终整理成结构化数据,极大地节省了处理海量信息的时间;另一方面,数据预处理可以使得挖掘愈发准确并且结果愈发真实有效。
5 数据分析及可视化
5.1数据分析背景
随着电影行业的不断发展,必将越来越依靠于数据分析 的手段来获取收益。对演员和其电影口碑分析可以得出演员的的票房号召力;从票房分析影片类型对于观众的接受度、导演 的人气指数等等,都具有很强的经济效益。观众群体的广泛性和个人情感的复杂性都影响着影业的未来发展。报告从四个角度对电影信息数据进行分析:第一,从评分的占比角度入手分析观众对电影市场的认可程度;第二,从评论人数与评分入手分析观影潮流,第三,从电影年份和评分关系入手分析历年电影口碑分化趋势;第四,从电影类型入手分析时下热门电影素材类型。
5.2从电影评分角度分析
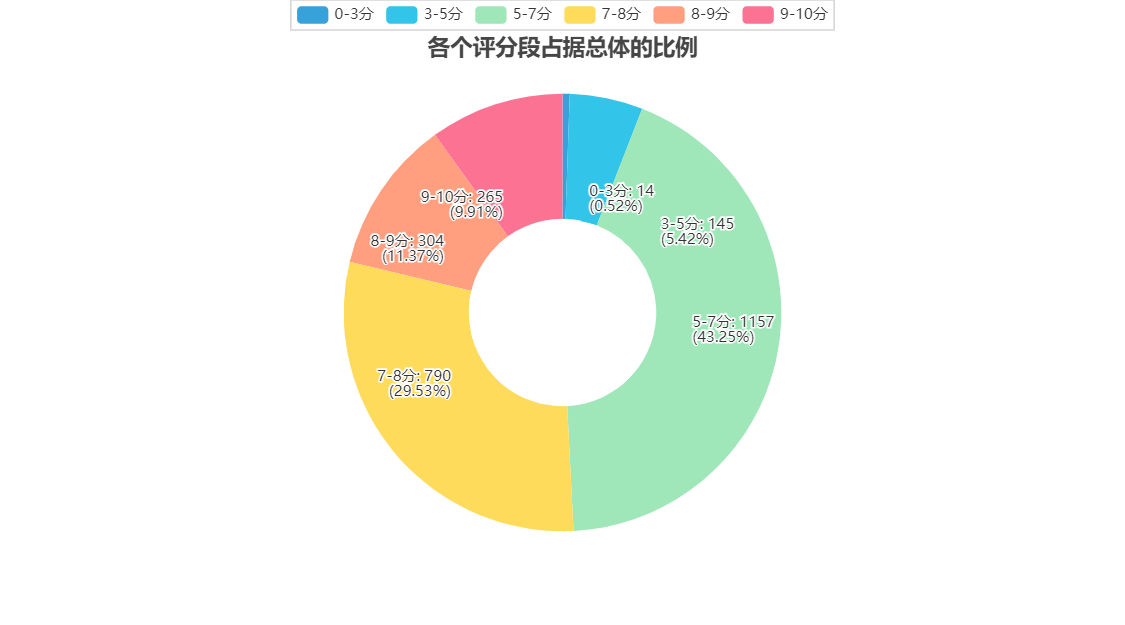
评分是观众从接受的角度对影片进行的评价和回馈,一方面取决于电影本身的艺术质量,另一方面则取决于观众本身的需求,即影片在多大程度上与观众的期待视域达到融。图5-1可以看出评分在8-9分的电影占据11.37%,说明观众对于电影市场的认可程度比较高;而9分以上电影仅占比9.91%,表明电影市场高质量电影数量有待提高。而7分以下电影占据78.72%,则说明电影市场质量还有很大的提升空间。
图 5-1 各个评分段占据总体的比例
5.3从评论人数与评分角度分析
评论人数与评分之间呈现正相关关系,相关系数为0.52,属于中等程度相关(相关系数在[-1,1],在统计学意义成立的基础上,相关系数越接近于1,评论人数与票房之间正相关性越大),表现为评价人数越多,评分高可能性越大。评论人数多的电影评分也普遍较高,反映出当下大众的观影潮流。
5.4从电影年份角度分析
电影行业从1950年后开始兴起,在90年代后迎来了高潮;80年代后电影的评分有质的飞跃。可能在于电影制作的技术的到了提升,具体体现在画质、特性等方面;2000年以后的 电影评分逐渐倾向于两极分化的趋势。总体来说电影年份与电影评分呈正相关关系。
5.5从电影数量及类型分析
观众对于喜剧题材和爱情题材类的电影认可度明显要高于其他类型。而武侠、功夫类题材的电影观众的认可度普遍偏低,说明动作类型电影品质还有很大提升空间,观众口味多元 化,并不是很喜欢单纯的动作片,相比之下,奇幻、科幻类题材的电影更受观众追捧。喜剧类影片一直以来都是电影市场的一大支柱,受到了制片商的极大追捧。近年来低成本、高回报的喜剧电影扎堆,其整体质量也不错,未来喜剧电影任然存在很大的发展前景。爱情题材电影虽然受观众认可度相对较高,但比之于喜剧题材电影任然有很大的上升空间,爱情片应该多在多元化和现代化方面下功夫,以更好适应在大众文化的时代背景下高速增长的观影需求。惊悚题材和恐怖题材无论在数量还是质量上都明显低于其他类型的电影,情况堪忧。
结 论
大数据时代的到来使这个社会中的海量数据变成了巨大的潜在财富,大数据的作用是不可估量的,而且大数据已经渗透 到了社会的各个领域。运用网络爬虫爬取海量数据在信息繁荣 的大数据时代更加行之有效。Python作为一门脚本语言,它有着简单易学,面向对象,开源和拥有丰富的库等优点。报告阐述了Python语言在数据爬取及可视化分析中的应用。通过对电影信息的可视化分析,可以给影片公司一些制片提示,也可以给观影者提供重要的参考信息。因此,数据分析观念无论是概念的本身,还是它对于自身发展都具有很高的价值。
附 录
网络爬虫代码:
# 导入需要的库
import csv
import logging
import time
from random import randint
import requests
import urllib3
from fake_useragent import UserAgent
from lxml import etree
# 禁用SSL警告
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
# 配置日志记录,记录日志级别为INFO,并将日志输出到文件spider.log中
logging.basicConfig(filename='spider.log', level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# 初始化error_logger,用于记录错误日志,记录日志级别为ERROR,并将日志输出到文件error.log中
error_logger = logging.getLogger('error_logger')
error_logger.setLevel(logging.ERROR)
# 请求头信息,包括User-Agent和Referer
HEADERS = {
'User-Agent': UserAgent().random,
'Referer': 'https://www.*.net/html/*/*/index.html'
}
# 基础URL
BASE_URL = 'https://www.*.net'
# 定义一个字典,用于存储电影信息
video_info = {
'Video_Name_CN': None,
'Video_Name': None,
'Video_Address': None,
'Video_Type': None,
'Video_Language': None,
'Video_Date': None,
'Video_Number': None,
'Video_Time': None,
'Video_Director': None,
'Video_Cast': []
}
# 定义函数,用于获取电影详情页的信息
def get_video_detail(details_url, csvwriter):
detail_url = BASE_URL + details_url
with requests.Session() as session:
response = session.get(url=detail_url, headers=HEADERS, verify=False)
detail_html_text = response.content.decode('gbk')
detail_html = etree.HTML(detail_html_text)
detail_content = detail_html.xpath("//div[@id='Zoom']//text()")
# 遍历详情页的信息,提取出需要的信息,并存储到video_info字典中
for index, info in enumerate(detail_content):
if info.startswith('◎译 名'):
video_info['Video_Name_CN'] = info.replace('◎译 名', '').strip()
if info.startswith('◎片 名'):
video_info['Video_Name'] = info.replace('◎片 名', '').strip()
if info.startswith('◎产 地'):
video_info['Video_Address'] = info.replace('◎产 地', '').strip()
if info.startswith('◎类 别'):
video_info['Video_Type'] = info.replace('◎类 别', '').strip()
if info.startswith('◎语 言'):
video_info['Video_Language'] = info.replace('◎语 言', '').strip()
if info.startswith('◎上映日期'):
video_info['Video_Date'] = info.replace('◎上映日期', '').strip()
if info.startswith('◎豆瓣评分'):
video_info['Video_Number'] = info.replace('◎豆瓣评分', '').strip()
if info.startswith('◎片 长'):
video_info['Video_Time'] = info.replace('◎片 长', '').strip()
if info.startswith('◎导 演'):
video_info['Video_Director'] = info.replace('◎导 演', '').strip()
if info.startswith('◎主 演'):
video_info['Video_Cast'] = []
video_actor = info.replace('◎主 演', '').strip()
video_info['Video_Cast'].append(video_actor)
for actor in detail_content[index + 1:]:
actor = actor.strip()
if actor.startswith("◎"):
break
video_info['Video_Cast'].append(actor)
# 将获取到的电影信息写入到CSV文件中,并记录日志
logging.info(f"{video_info['Video_Name_CN']}, {video_info['Video_Date']}, {video_info['Video_Time']}")
try:
csvwriter.writerow(video_info)
except Exception as e:
error_logger.error(f"Error occurred while writing to csv: {e}")
# 定义爬虫函数,用于爬取指定页数的电影信息
def spider(pages):
# 打开CSV文件,并写入表头
with open('movies.csv', 'a', encoding='utf-8', newline='') as file:
csvwriter = csv.DictWriter(file, fieldnames=video_info.keys())
csvwriter.writeheader()
# 遍历每一页,获取电影列表页的信息,并提取出电影详情页的链接
for page in range(1, pages + 1):
page_url = f'{BASE_URL}/html/*/*/list_23_{page}.html'
with requests.Session() as session:
request = session.get(url=page_url, headers=HEADERS)
page_html_text = request.text
page_html = etree.HTML(page_html_text)
detail_urls = page_html.xpath('//*[@class="co_content8"]//a/@href')
# 遍历每个电影详情页,并调用get_video_detail函数获取电影信息
for detail_url in detail_urls:
if detail_url.startswith('/'):
try:
get_video_detail(detail_url, csvwriter)
except Exception as e:
error_logger.error(f"Error occurred: {e}")
# 随机等待1-3秒,防止被网站封IP
time.sleep(randint(1, 3))
# 记录日志,表示该页已经爬取完成
logging.info(f"==============第{page}页爬取完毕!=================")
if __name__ == '__main__':
spider(120)
数据分析代码:
# In[1]:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from pyecharts.charts import Pie, Bar, Line, WordCloud
from pyecharts import options as opts
from pyecharts.globals import ThemeType
import collections
import warnings
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
# 忽略警告信息
warnings.filterwarnings('ignore')
# In[2]:
# 读取电影数据集
data = pd.read_csv('./movies.csv')
# In[3]:
# 删除缺失值和重复行
data.dropna(inplace=True)
data.drop_duplicates(inplace=True)
# In[4]:
# 对数据集进行预处理
data['Video_Name_CN'] = data['Video_Name_CN'].apply(
lambda x: x.split('/')[0]) # 处理Video_Name_CN
data['Video_Name'] = data['Video_Name'].apply(
lambda x: x.split('/')[0]) # 处理Video_Name
data['Video_Address'] = data['Video_Address'].apply(
lambda x: x.split('/')[0].split(',')[0].strip()) # 处理Video_Address
data['Video_Language'] = data['Video_Language'].apply(
lambda x: x.split('/')[0].split(',')[0]) # 处理Video_Language
data['Video_Date'] = data['Video_Date'].apply(
lambda x: x.split('(')[0].strip()) # 处理Video_Date
data['Year'] = data['Video_Date'].apply(lambda x: x.split('-')[0]) # 提取年份信息
data = data[data['Year'] >= '2016'] # 只保留2016年及以后的电影数据
data['Num_of_Users'] = data['Video_Number'].apply(lambda x: str(x).split(
'from')[-1].split('users')[0].replace(',', '').strip()) # 处理Num_of_Users
data['Num_of_Users'] = pd.to_numeric(data['Num_of_Users'],
errors='coerce') # 将Num_of_Users列转换为数值类型
data['Video_Number'] = data['Video_Number'].apply(
lambda x: x.split('/')[0].strip()) # 处理Video_Number
data['Video_Number'] = pd.to_numeric(data['Video_Number'],
errors='coerce') # 将Video_Number列转换为数值类型
data['Video_Time'] = data['Video_Time'].apply(
lambda x: x.split('分钟')[0]) # 处理Video_Time
data['Video_Time'] = pd.to_numeric(data['Video_Time'],
errors='coerce') # 将Video_Time列转换为数值类型
data['Video_Director'] = data['Video_Director'].apply(
lambda x: x.split()[0]) # 处理Video_Director
data.dropna(inplace=True) # 再次删除缺失值
# In[5]:
# 分析各个国家发布的电影数量占比
df1 = data.groupby('Video_Address').size().sort_values(
ascending=False).head(10)
pie1 = Pie(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
pie1.add(
series_name='电影数量',
data_pair=[list(z) for z in zip(df1.index.tolist(), df1.values.tolist())],
radius='70%',
)
pie1.set_series_opts(tooltip_opts=opts.TooltipOpts(trigger='item'))
pie1.render_notebook()
# In[6]:
# 发布电影数量最高Top5导演
df2 = data['Video_Director'].value_counts().head()
bar1 = Bar(init_opts=opts.InitOpts(theme=ThemeType.DARK))
bar1.add_xaxis(df2.index.tolist())
bar1.add_yaxis('电影数量', df2.values.tolist())
bar1.set_series_opts(itemstyle_opts=opts.ItemStyleOpts(color='#B87333'))
bar1.set_series_opts(label_opts=opts.LabelOpts(position="top"))
bar1.render_notebook()
# In[7]:
# 分析电影平均评分最高的前十名国家
df3 = data.groupby('Video_Address')['Video_Number'].mean().sort_values(
ascending=False).head(10)
# 创建水平条形图
def create_barh_chart(x_data, y_data):
ax = x_data.plot(kind='barh', color='#6495ED')
ax.set_xlabel('平均评分')
ax.set_ylabel('国家')
ax.invert_yaxis()
for i, v in enumerate(y_data):
ax.text(v + 0.1, i - 0.15, str(round(v, 2)))
return ax
# 生成水平条形图
ax = create_barh_chart(df3, df3.values)
plt.show()
# In[8]:
# 分析哪种语言最受欢迎
result_list = []
for i in data['Video_Language'].values:
word_list = str(i).split('/')
for j in word_list:
result_list.append(j)
word_counts = collections.Counter(result_list)
word_counts_top = word_counts.most_common(100)
wc1 = WordCloud()
wc1.add('', word_counts_top)
wc1.render_notebook()
# In[9]:
# 分析哪种类型电影最受欢迎
result_list = []
for i in data['Video_Type'].values:
result_list.extend(str(i).split('/'))
word_counts = collections.Counter(result_list)
word_counts_top = word_counts.most_common(100)
wc2 = WordCloud()
wc2.add('', word_counts_top)
wc2.render_notebook()
# In[10]:
# 分析各种类型电影的比例
word_counts_top = word_counts.most_common(10)
pie2 = Pie(init_opts=opts.InitOpts(theme=ThemeType.MACARONS))
pie2.add(series_name='类型',
data_pair=word_counts_top,
rosetype='radius',
radius='60%')
pie2.set_global_opts(title_opts=opts.TitleOpts(
title="各种类型电影的比例", pos_left='center', pos_top=50))
pie2.set_series_opts(tooltip_opts=opts.TooltipOpts(
trigger='item', formatter='{a} <br/>{b}:{c} ({d}%)'))
pie2.render_notebook()
# In[11]:
# 分析电影片长的分布
sns.displot(data['Video_Time'], kde=True)
plt.show()
# In[12]:
# 分析片长和评分的关系
plt.scatter(data['Video_Time'], data['Video_Number'])
plt.title('片长和评分的关系', fontsize=15)
plt.xlabel('片长', fontsize=15)
plt.ylabel('评分', fontsize=15)
plt.show()
# In[13]:
# 统计2016年到至今的电影年产量
df4 = data.groupby('Year').size()
line = Line()
line.add_xaxis(xaxis_data=df4.index.to_list())
line.add_yaxis('年产量', y_axis=df4.values.tolist(), is_smooth=True)
line.set_global_opts(
xaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True)),
title_opts=opts.TitleOpts(title="2016年到至今的电影年产量",
pos_left='center',
pos_bottom='5%'))
line.render_notebook()
# In[14]:
# 各个评分段占据总体的比例
bins = [0, 3, 5, 7, 8, 9, 10]
labels = ['0-3分', '3-5分', '5-7分', '7-8分', '8-9分', '9-10分']
data['score_range'] = pd.cut(data['Video_Number'],
bins=bins,
labels=labels,
include_lowest=True)
df5 = data.groupby('score_range').size()
pie3 = Pie(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
pie3.add(
series_name='评分比例',
data_pair=[list(z) for z in zip(df5.index.tolist(), df5.values.tolist())],
radius=['70%', '30%'])
pie3.set_global_opts(title_opts=opts.TitleOpts(
title="各个评分段占据总体的比例", pos_left='center', pos_top='5%'))
pie3.set_series_opts(tooltip_opts=opts.TooltipOpts(trigger='item'))
pie3.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}\n({d}%)"))
pie3.render_notebook()