索引(记录)的源码的工作流程图如下:
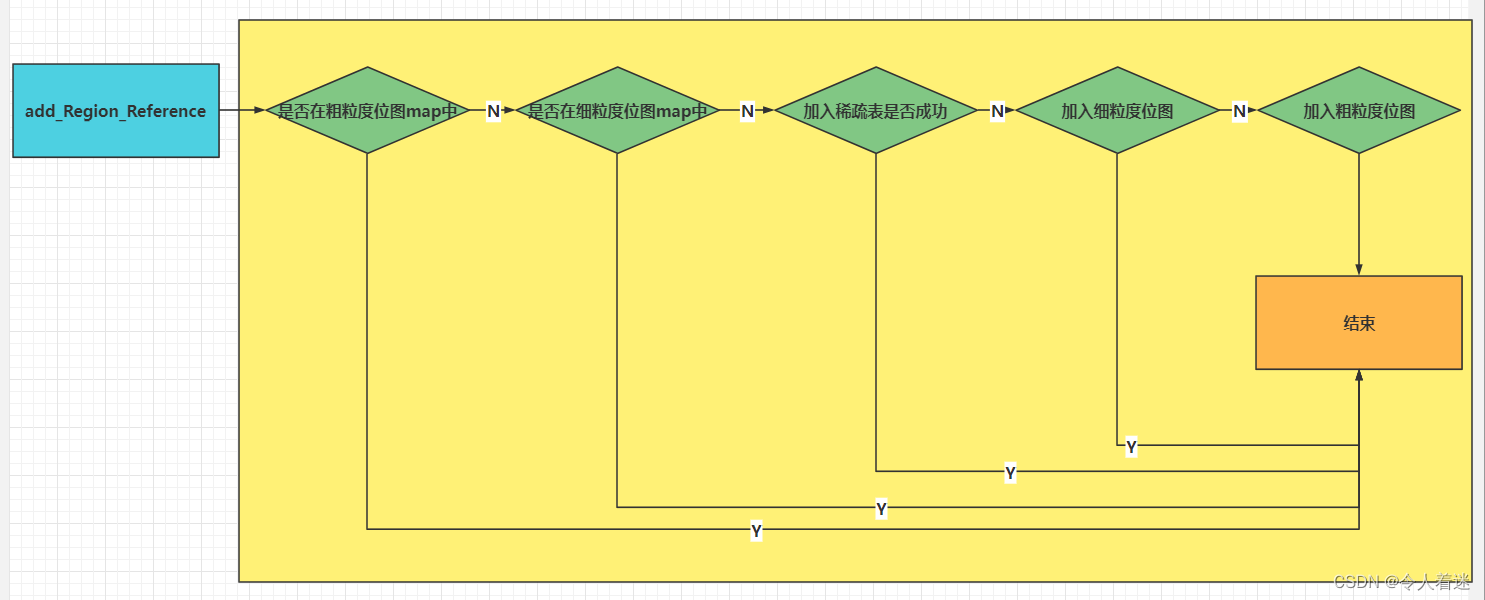
CSet(Collection Set 回收集合)
收集集合(CSet)代表每次GC暂停时回收的一系列目标分区。在任意一次收集暂停中,CSet所有分区都会被释放,内部存活的对象都会被转移到分配的空闲分区中。因此无论是年轻代收集,还是混合收集,工作的机制都是一致的。年轻代收集CSet只容纳年轻代分区,而混合收集会通过启发式算法,在老年代候选回收分区中,筛选出回收收益最高的分区添加到CSet中。
CSet根据两种不同的回收类型分为两种不同CSet。
1.CSet of Young Collection
2.CSet of Mix Collection
CSet of Young Collection 只专注回收 Young Region 跟 Survivor Region ,而CSet of Mix Collection 模式下的CSet 则会通过RSet计算Region中对象的活跃度,
活跃度阈值-XX:G1MixedGCLiveThresholdPercent(默认85%),只有活跃度高于这个阈值的才会准入CSet,混合模式下CSet还可以通过-XX:G1OldCSetRegionThresholdPercent(默认10%)设置,CSet跟整个堆的比例的数量上限。
App Thread (用户线程)
这个很简单,App thread 就是执行一个java程序的业务逻辑,实际运行的一些线程。
Concurrence Refinement Thread(同步优化线程)
这个线程主要用来处理代间引用之间的关系用的。当赋值语句发生后,G1通过Writer Barrier技术,跟G1自己的筛选算法,筛选出此次索引赋值是否是跨区(Region)之间的引用。如果是跨区索引赋值,在线程的内存缓冲区写一条log,一旦日志缓冲区写满,就重新起一块缓冲重新写,而原有的缓冲区则进入全局缓冲区。
Concurrence Refinement Thread 扫描全局缓冲区的日志,根据日志更新各个区(Region)的RSet。这块逻辑跟后面讲到的SATB技术十分相似,但又不同SATB技术主要更新的是存活对象的位图。
Concurrence Refinement Thread(同步优化线程) 可通过
**-XX:G1ConcRefinementThreads (默认等于-XX:ParellelGCThreads)设置。**
如果发现全局缓冲区日志积累较多,G1会调用更多的线程来出来缓冲区日志,甚至会调用App Thread 来处理,造成应用任务堵塞,所以必须要尽量避免这样的现象出现。可以通过阈值
**-XX:G1ConcRefinementGreenZone**
**-XX:G1ConcRefinementYellowZone**
**-XX:G1ConcRefinementRedZone**
这三个参数来设置G1调用线程的数量来处理全局缓存的积累的日志。
G1垃圾收集器的三种模式
young GC
young GC的触发条件
Eden区的大小范围 = [ -XX:G1NewSizePercent, -XX:G1MaxNewSizePercent ] = [ 整堆5%, 整堆60% ]
在[ 整堆5%, 整堆60% ]的基础上,G1会计算下现在Eden区回收大概要多久时间,如果回收时间远远小于参数-XX:MaxGCPauseMills设定的值(默认200ms),那么增加年轻代的region,继续给新对象存放,不会马上做YoungGC。
G1计算回收时间接近参数-XX:MaxGCPauseMills设定的值,那么就会触发YoungGC。
#### **具体步骤:**
根扫描:
GC并行任务包括根扫描、更新RSet、对象复制,主要逻辑在g1CollectedHeap.cpp G1ParTask类的work方法中;evacuate_roots方法为根扫描。
```C++
void work(uint worker_id) {
if (worker_id >= _n_workers) return; // no work needed this round
_g1h->g1_policy()->phase_times()->record_time_secs(G1GCPhaseTimes::GCWorkerStart, worker_id, os::elapsedTime());
{
ResourceMark rm;
HandleMark hm;
ReferenceProcessor* rp = _g1h->ref_processor_stw();
G1ParScanThreadState pss(_g1h, worker_id, rp);
G1ParScanHeapEvacFailureClosure evac_failure_cl(_g1h, &pss, rp);
pss.set_evac_failure_closure(&evac_failure_cl);
bool only_young = _g1h->g1_policy()->gcs_are_young();
// Non-IM young GC.
G1ParCopyClosure<G1BarrierNone, G1MarkNone> scan_only_root_cl(_g1h, &pss, rp);
G1CLDClosure<G1MarkNone> scan_only_cld_cl(&scan_only_root_cl,
only_young, // Only process dirty klasses.
false); // No need to claim CLDs.
// IM young GC.
// Strong roots closures.
G1ParCopyClosure<G1BarrierNone, G1MarkFromRoot> scan_mark_root_cl(_g1h, &pss, rp);
G1CLDClosure<G1MarkFromRoot> scan_mark_cld_cl(&scan_mark_root_cl,
false, // Process all klasses.
true); // Need to claim CLDs.
// Weak roots closures.
G1ParCopyClosure<G1BarrierNone, G1MarkPromotedFromRoot> scan_mark_weak_root_cl(_g1h, &pss, rp);
G1CLDClosure<G1MarkPromotedFromRoot> scan_mark_weak_cld_cl(&scan_mark_weak_root_cl,
false, // Process all klasses.
true); // Need to claim CLDs.
OopClosure* strong_root_cl;
OopClosure* weak_root_cl;
CLDClosure* strong_cld_cl;
CLDClosure* weak_cld_cl;
bool trace_metadata = false;
if (_g1h->g1_policy()->during_initial_mark_pause()) {
// We also need to mark copied objects.
strong_root_cl = &scan_mark_root_cl;
strong_cld_cl = &scan_mark_cld_cl;
if (ClassUnloadingWithConcurrentMark) {
weak_root_cl = &scan_mark_weak_root_cl;
weak_cld_cl = &scan_mark_weak_cld_cl;
trace_metadata = true;
} else {
weak_root_cl = &scan_mark_root_cl;
weak_cld_cl = &scan_mark_cld_cl;
}
} else {
strong_root_cl = &scan_only_root_cl;
weak_root_cl = &scan_only_root_cl;
strong_cld_cl = &scan_only_cld_cl;
weak_cld_cl = &scan_only_cld_cl;
}
pss.start_strong_roots();
_root_processor->evacuate_roots(strong_root_cl,
weak_root_cl,
strong_cld_cl,
weak_cld_cl,
trace_metadata,
worker_id);
G1ParPushHeapRSClosure push_heap_rs_cl(_g1h, &pss);
_root_processor->scan_remembered_sets(&push_heap_rs_cl,
weak_root_cl,
worker_id);
pss.end_strong_roots();
{
double start = os::elapsedTime();
G1ParEvacuateFollowersClosure evac(_g1h, &pss, _queues, &_terminator);
evac.do_void();
double elapsed_sec = os::elapsedTime() - start;
double term_sec = pss.term_time();
_g1h->g1_policy()->phase_times()->add_time_secs(G1GCPhaseTimes::ObjCopy, worker_id, elapsed_sec - term_sec);
_g1h->g1_policy()->phase_times()->record_time_secs(G1GCPhaseTimes::Termination, worker_id, term_sec);
_g1h->g1_policy()->phase_times()->record_thread_work_item(G1GCPhaseTimes::Termination, worker_id, pss.term_attempts());
}
_g1h->g1_policy()->record_thread_age_table(pss.age_table());
_g1h->update_surviving_young_words(pss.surviving_young_words()+1);
if (ParallelGCVerbose) {
MutexLocker x(stats_lock());
pss.print_termination_stats(worker_id);
}
assert(pss.queue_is_empty(), "should be empty");
// Close the inner scope so that the ResourceMark and HandleMark
// destructors are executed here and are included as part of the
// "GC Worker Time".
}
_g1h->g1_policy()->phase_times()->record_time_secs(G1GCPhaseTimes::GCWorkerEnd, worker_id, os::elapsedTime());
}
};
```
**g1RootProcessor.cpp的evacuate_roots主要逻辑如下**:
```java
void G1RootProcessor::evacuate_roots(OopClosure* scan_non_heap_roots,
OopClosure* scan_non_heap_weak_roots,
CLDClosure* scan_strong_clds,
CLDClosure* scan_weak_clds,
bool trace_metadata,
uint worker_i) {
// First scan the shared roots.
double ext_roots_start = os::elapsedTime();
G1GCPhaseTimes* phase_times = _g1h->g1_policy()->phase_times();
BufferingOopClosure buf_scan_non_heap_roots(scan_non_heap_roots);
BufferingOopClosure buf_scan_non_heap_weak_roots(scan_non_heap_weak_roots);
OopClosure* const weak_roots = &buf_scan_non_heap_weak_roots;
OopClosure* const strong_roots = &buf_scan_non_heap_roots;
// CodeBlobClosures are not interoperable with BufferingOopClosures
G1CodeBlobClosure root_code_blobs(scan_non_heap_roots);
process_java_roots(strong_roots,
trace_metadata ? scan_strong_clds : NULL,
scan_strong_clds,
trace_metadata ? NULL : scan_weak_clds,
&root_code_blobs,
phase_times,
worker_i);
// This is the point where this worker thread will not find more strong CLDs/nmethods.
// Report this so G1 can synchronize the strong and weak CLDs/nmethods processing.
if (trace_metadata) {
worker_has_discovered_all_strong_classes();
}
process_vm_roots(strong_roots, weak_roots, phase_times, worker_i);
process_string_table_roots(weak_roots, phase_times, worker_i);
{
// Now the CM ref_processor roots.
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::CMRefRoots, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_refProcessor_oops_do)) {
// We need to treat the discovered reference lists of the
// concurrent mark ref processor as roots and keep entries
// (which are added by the marking threads) on them live
// until they can be processed at the end of marking.
_g1h->ref_processor_cm()->weak_oops_do(&buf_scan_non_heap_roots);
}
}
if (trace_metadata) {
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::WaitForStrongCLD, worker_i);
// Barrier to make sure all workers passed
// the strong CLD and strong nmethods phases.
wait_until_all_strong_classes_discovered();
}
// Now take the complement of the strong CLDs.
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::WeakCLDRoots, worker_i);
ClassLoaderDataGraph::roots_cld_do(NULL, scan_weak_clds);
} else {
phase_times->record_time_secs(G1GCPhaseTimes::WaitForStrongCLD, worker_i, 0.0);
phase_times->record_time_secs(G1GCPhaseTimes::WeakCLDRoots, worker_i, 0.0);
}
// Finish up any enqueued closure apps (attributed as object copy time).
buf_scan_non_heap_roots.done();
buf_scan_non_heap_weak_roots.done();
double obj_copy_time_sec = buf_scan_non_heap_roots.closure_app_seconds()
+ buf_scan_non_heap_weak_roots.closure_app_seconds();
phase_times->record_time_secs(G1GCPhaseTimes::ObjCopy, worker_i, obj_copy_time_sec);
double ext_root_time_sec = os::elapsedTime() - ext_roots_start - obj_copy_time_sec;
phase_times->record_time_secs(G1GCPhaseTimes::ExtRootScan, worker_i, ext_root_time_sec);
// During conc marking we have to filter the per-thread SATB buffers
// to make sure we remove any oops into the CSet (which will show up
// as implicitly live).
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::SATBFiltering, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_filter_satb_buffers) && _g1h->mark_in_progress()) {









![Spring学习05-[AOP学习-AOP原理和事务]](https://i-blog.csdnimg.cn/direct/0a43360bcfb641daa0534fd4c4e6b9b8.png)







