"山,请你慢些走向我呀~"
一、异常初始
每当我们使用传统C写一些诸如malloc\realloc,或者不允许传入的参数为空(nullptr)时,我们时长会加一个断言(assert),一旦条件为false立即终止程序,不仅如此,当申请的空间够大,malloc有时也会失败,由此不得不对malloc返回值进行判断是否为NULL……
以上举的些许例子,我想只要你习惯使用C,总不会陌生。
(1)为什么引入了异常?
C语言传统的处理错误的方式
终止程序,如assert,缺陷:用户难以接受。如发生内存错误,除0错误时就会终止程序
返回错误码,缺陷:需要程序员自己去查找对应的错误。如系统的很多库的接口函数都是通
过把错误码放到errno中,表示错误。
终止程序的方式往往显得暴力而没有必要。比如说,当我们在电梯里使用QQ、微信,此时由于网络环境差,信号不好,与朋友发送的消息难免此时会显红!(这即是一个异常),然而出现这种状况的时候,应用程序并没有立即被"干掉"。
回到错误码上,比如我们开始写一个新的程序,第一行就写出的 int main(),其中main()返回的整型0,对应的错误码描述是Success。
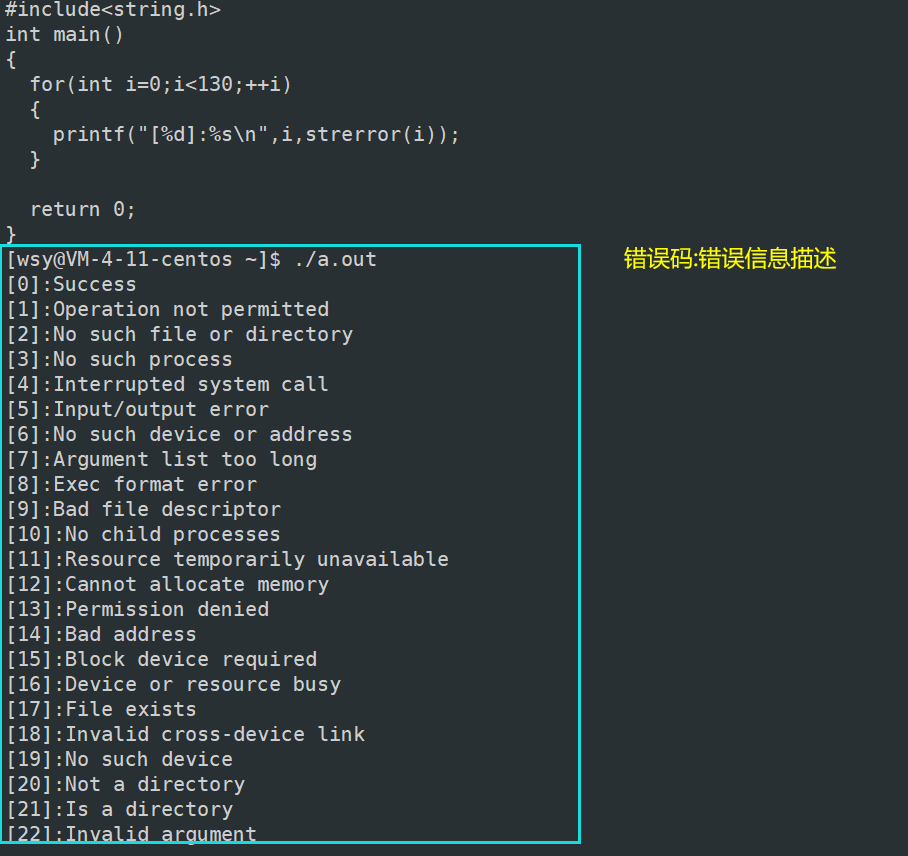
当我们调用库函数失败时,都会设置错误码,该错误码放在errno全局变量。
其实从那一大串错误码+错误码描述信息,你就该知道,作为程序员如果仅仅拿到错误码,还得去挨个儿从0~100(假设)去寻找对应的错误信息,在"error=100","Network is down",噢~是这个问题。
显然作为懒人的先行者,一定不欢喜这样种做法。其次,当遇到复杂的嵌套函数返回时,return 只能解决当前函数栈帧的返回值,如果调用链路太深,深层函数返回了错误,那么我们只得层层返回,到最外层处理错误。
(2)C++异常概念
异常是一种处理错误的方式,当一个函数发现自己无法处理的错误时就可以抛出异常,让函数的
直接或间接的调用者处理这个错误。
throw:当问题出现时,程序会抛出一个异常。这是通过使用 throw 关键字来完成的。
catch: 在您想要处理问题的地方,通过异常处理程序捕获异常.catch 关键字用于捕获异
常,可以有多个catch进行捕获。
try: try 块中的代码标识将被激活的特定异常,它后面通常跟着一个或多个 catch 块。
如果有一个块抛出一个异常,捕获异常的方法会使用 try 和 catch 关键字。try 块中放置可能抛
出异常的代码,try 块中的代码被称为保护代码。使用 try/catch 语句的语法如下所示:
try
{
// 保护的标识代码
}catch( ExceptionName e1 )
{
// catch 块
}catch( ExceptionName e2 )
{
// catch 块
}catch( ExceptionName eN )
{
// catch 块
}
注:catch()可以包含的是任意类型的对象。二、异常使用
(1)异常的抛出和匹配原则
1.异常是通过抛出对象而引发的,该对象的类型决定了应该激活哪个catch的处理代码。
2.被选中的处理代码是调用链中与 该对象类型匹配且离抛出异常位置最近的那一个 。
3.抛出异常对象后, 会生成一个异常对象的拷贝,因为抛出的异常对象可能是一个临时对象 ,
所以会生成一个拷贝对象,这个拷贝的临时对象会在被catch以后销毁。(这里的处理类似
于函数的传值返回)。
4.catch(...) 可以捕获任意类型的异常 ,问题是不知道异常错误是什么。
5.实际中抛出和捕获的匹配原则有个例外,并不都是类型完全匹配, 可以抛出的派生类对象,
使用基类捕获 。
接下来的代码,是为了演示异常抛出的规则。
(2)异常的抛出和捕获
可以抛出任意类型的异常,catch严格按照类型匹配捕捉异常。
我们简单写一个除0错误的异常代码。
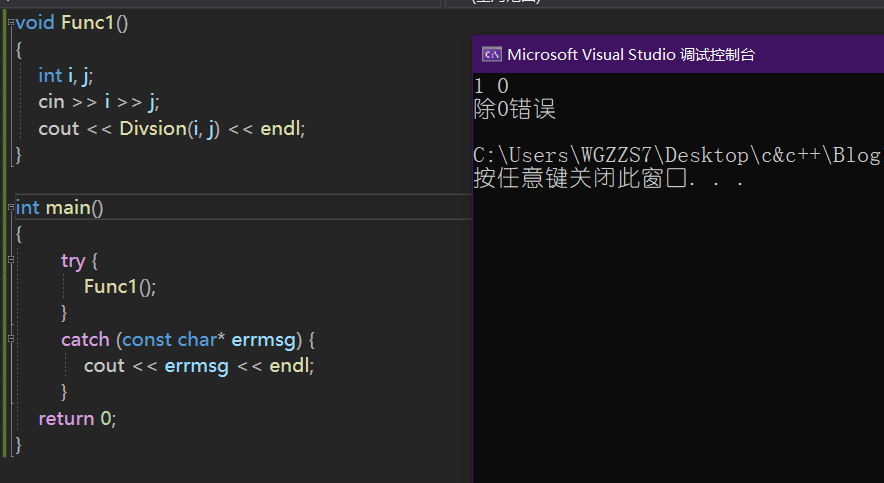
抛出const char*:
double Divsion(int a, int b)
{
if (b == 0)
{
throw "除0错误"; //抛出异常 类型是 const char*
}
return(double)((double)a / (double)b);
}
void Func1()
{
int i, j;
cin >> i >> j;
cout << Divsion(i, j) << endl;
}
int main()
{
try {
Func1();
}
catch (const char* errmsg) { //catch处接收 const char* 类型
cout << errmsg << endl;
}
return 0;
}
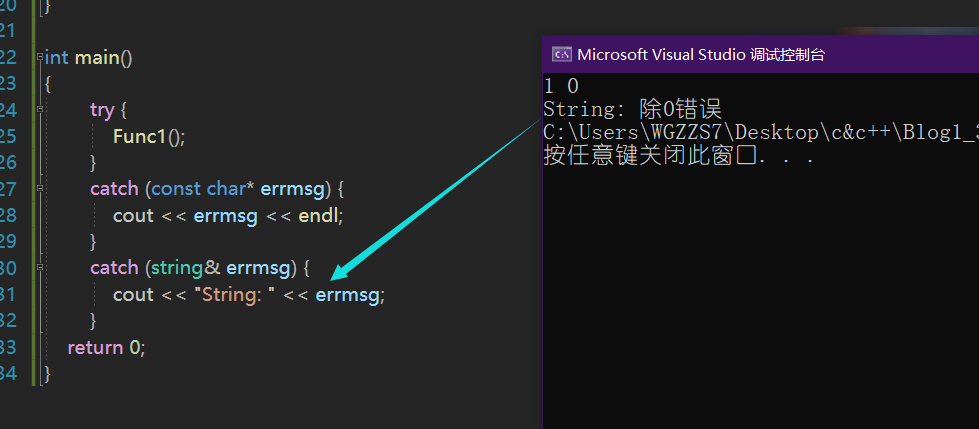
抛出string对象:
double Divsion(int a, int b)
{
if (b == 0)
{
//throw "除0错误";
//返回string对象
throw string("除0错误");
}
return(double)((double)a / (double)b);
}
void Func1()
{
int i, j;
cin >> i >> j;
cout << Divsion(i, j) << endl;
}
int main()
{
try {
Func1();
}
catch (const char* errmsg) {
cout << errmsg << endl;
}
catch (string& errmsg) {
cout << "String: " << errmsg;
}
return 0;
}
catch(...) 可以捕捉任意类型的异常:
double Divsion(int a, int b)
{
if (b == 0)
{
//throw "除0错误";
//throw string("除0错误");
throw 1;
}
return(double)((double)a / (double)b);
}
void Func1()
{
int i, j;
cin >> i >> j;
cout << Divsion(i, j) << endl;
}
int main()
{
try {
Func1();
}
catch (const char* errmsg) {
cout << errmsg << endl;
}
catch (string& errmsg) {
cout << "String: " << errmsg;
}
catch (...) {
cout << "Unknow errormst" << endl;
}
return 0;
}此时,我们抛出整型1,但是我们在catch时,没有对应类型匹配的catch捕获。
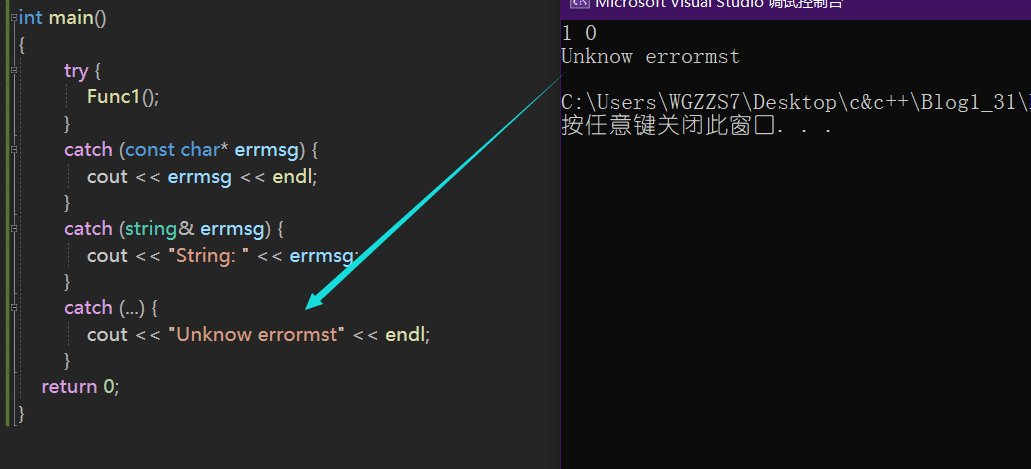
在函数调用链中异常栈展开匹配原则
1. 首先检查throw本身是否在try块内部,如果是再查找匹配的catch语句 。如果有匹配的,则
调到catch的地方进行处理。
2. 没有匹配的catch则退出当前函数栈 ,继续在调用函数的栈中进行查找匹配的catch。
3. 如果到达main函数的栈,依旧没有匹配的,则终止程序 。上述这个沿着调用链查找匹配的
4.catch子句的过程称为栈展开。所以实际中我们最后都要加一个catch(...)捕获任意类型的异
常,否则当有异常没捕获,程序就会直接终止
5.找到匹配的catch子句并处理以后,会继续沿着catch子句后面继续执行
我们照着上份代码,我们此时在func里也进行进行异常捕捉。
double Divsion(int a, int b)
{
if (b == 0)
{
//throw "除0错误";
throw string("除0错误");
//throw 1;
}
return(double)((double)a / (double)b);
}
void Func1()
{
//我们在函数调用外捕获异常
try
{
int i, j;
cin >> i >> j;
cout << Divsion(i, j) << endl;
} //int errmsg
catch (string& errmsg) {
cout << "Func1 String: " << errmsg;
}
}
int main()
{
try {
Func1();
}
catch (const char* errmsg) {
cout << errmsg << endl;
}
catch (string& errmsg) {
cout << "String: " << errmsg;
}
catch (...) {
cout << "Unknow errormst" << endl;
}
return 0;
}
上述代码更加应证了catch捕获的匹配规则。

捕获异常就意味着进程终止?
找到匹配的catch子句并处理以后,会继续沿着catch子句后面继续执行。
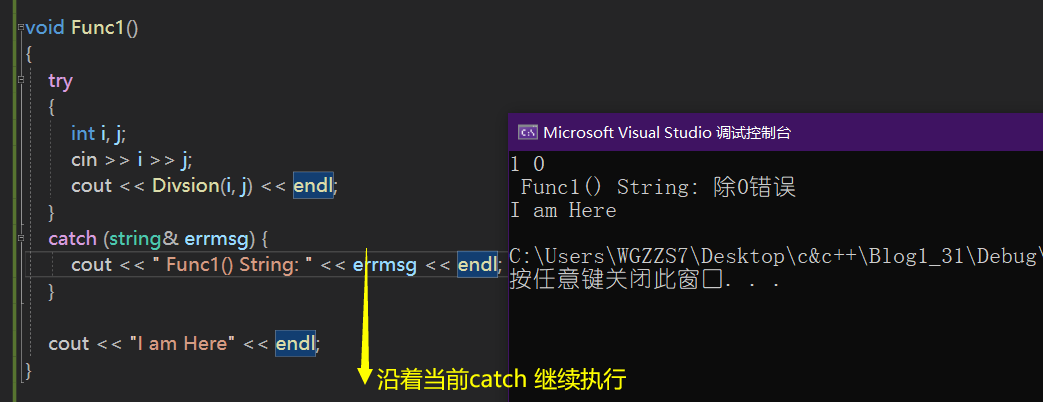
什么情况会出现进程终止?
如果到达main函数的栈,依旧没有匹配的,则终止程序
我们此时将main函数里的catch(...)注释掉。
double Divsion(int a, int b)
{
if (b == 0)
{
//抛出一个double类型
throw 2.2;
}
return(double)((double)a / (double)b);
}
void Func1()
{
try
{
int i, j;
cin >> i >> j;
cout << Divsion(i, j) << endl;
}
catch (string& errmsg) {
cout << " Func1() String: " << errmsg << endl;
}
cout << "I am Here" << endl;
}
int main()
{
try {
Func1();
}
catch (const char* errmsg) {
cout << errmsg << endl;
}
catch (string& errmsg) {
cout << "main() String: " << errmsg;
}
//catch (...) {
// cout << "Unknow errormst" << endl;
//}
return 0;
}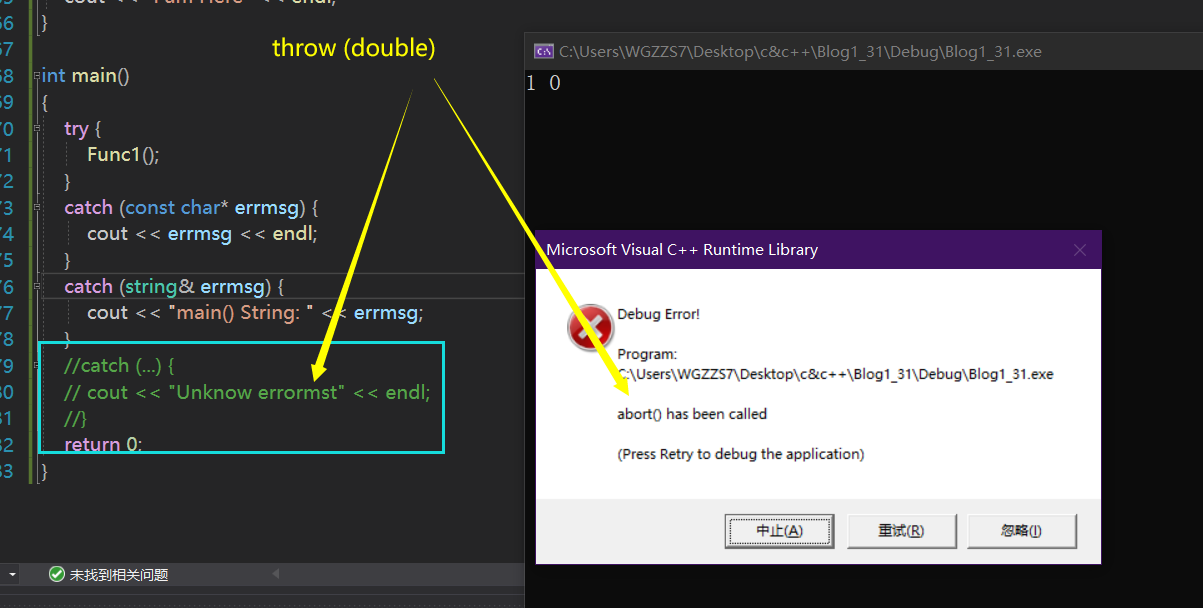
通常出现这样的警告,就是异常没捕获到~
(3)异常的重新抛出
有可能单个的catch无法处理一个异常。在本层进行一些校正后,又会将该异常重新抛出,抛给更外层的调用处来处理,catch则可以通过重新抛出将异常传递给更上层的函数进行处理。
double Divsion(int a, int b)
{
if (b == 0)
{
throw "Division by zero condition!";
throw 2.2;
}
return(double)((double)a / (double)b);
}
void Func1()
{
int* arr = new int[10];
try
{
int i, j;
cin >> i >> j;
cout << Divsion(i, j) << endl;
}
catch (string& errmsg) {
cout << " Func1() String: " << errmsg << endl;
}
cout << "delete[] arr" << endl;
delete[] arr;
}
int main()
{
try {
Func1();
}
catch (const char* errmsg) {
cout << errmsg << endl;
}
catch (string& errmsg) {
cout << "main() String: " << errmsg;
}
catch (...) {
cout << "Unknow errormst" << endl;
}
return 0;
}我们在Func里动态开一堆int类型的数组,它是否能正常释放呢?
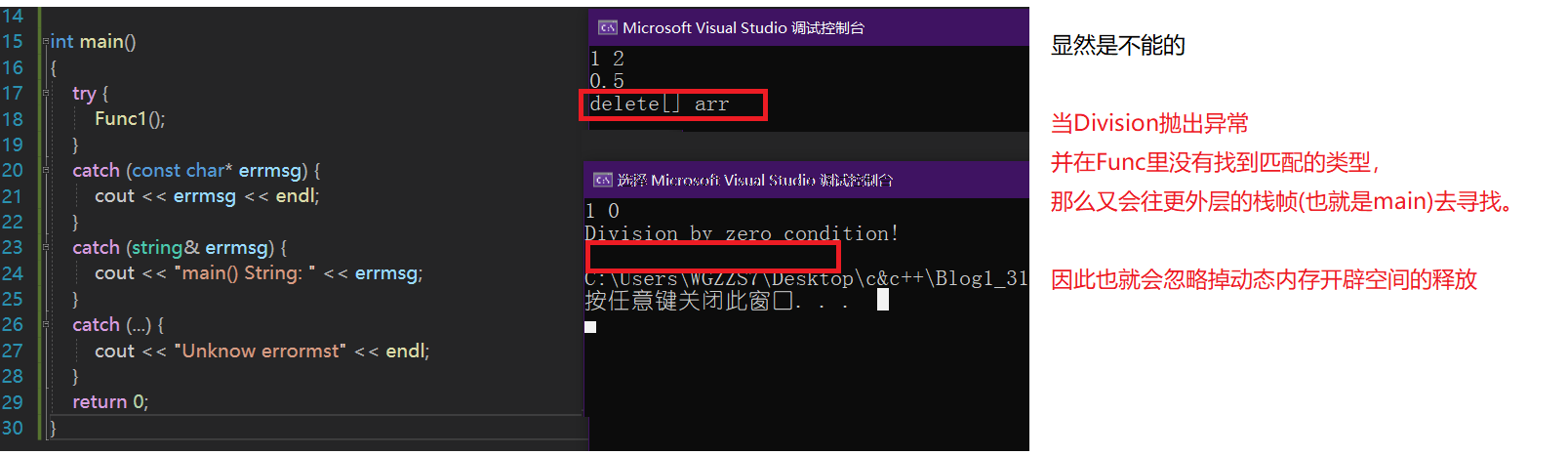
这已经提到了一部分关于异常安全的隐患,这个我们之后会谈及。
void Func1()
{
int* arr = new int[10];
try
{
int i, j;
cin >> i >> j;
cout << Divsion(i, j) << endl;
}
//catch (string& errmsg) {
// cout << " Func1() String: " << errmsg << endl;
//}
catch (...) {
cout << "delete [] arr"<< endl;
delete[] arr;
throw;
}
cout << "delete[] arr" << endl;
delete[] arr;
}为此,我们在内层函数func捕获任意类型,并throw抛出原对象,但是在这之前释放掉函数开头开辟的动态内存块。
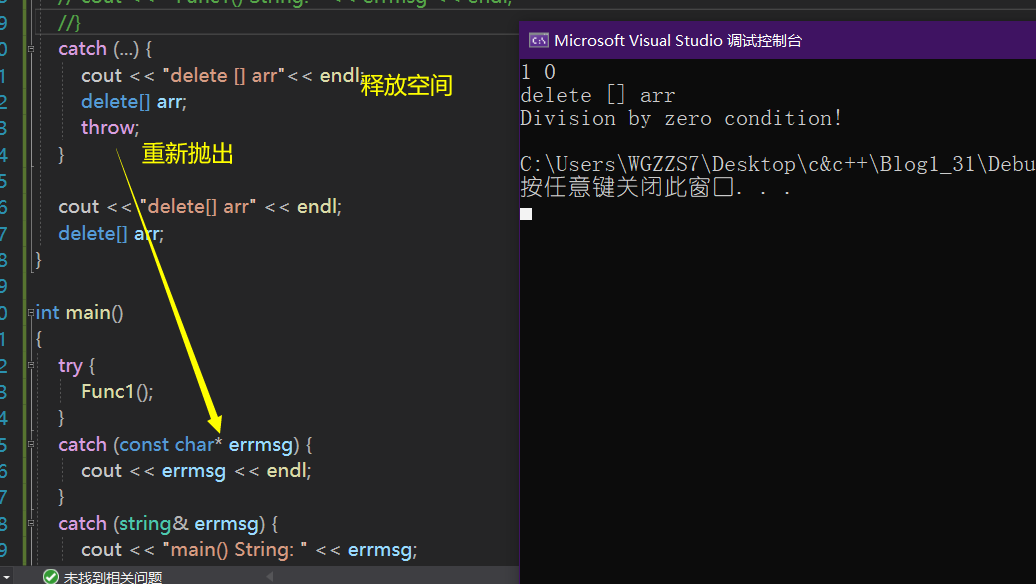
(4)异常安全
前面举例异常重新抛出的时候,遇到了一个问题,那就是当释放资源的动作在受到异常抛出、捕捉的影响时,可能会被忽略掉,从而导致内存泄漏的问题。
异常的使用范围也因此会受到限制。
1.构造函数完成对象的构造和初始化,最好不要在构造函数中抛出异常,否则可能导致对象不
完整或没有完全初始化。
2.析构函数主要完成资源的清理,最好不要在析构函数内抛出异常,否则可能导致资源泄漏(内
存泄漏、句柄未关闭等)。
3.C++中异常经常会导致资源泄漏的问题,比如在new和delete中抛出了异常,导致内存泄
漏。(new\delete抛出的异常通常悄无声息,却见血封喉!但是C++并没有坐以待毙,之后经常会使用RAII(智能指针)来解决上述恼人的问题)。
(5)异常规范
异常规范的出现,本质目的就是为了方便程序员一眼就能看清,这个函数是否抛异常,抛什么类型的异常……
// 这里表示这个函数会抛出A/B/C/D中的某种类型的异常
void fun() throw(A,B,C,D);
// 这里表示这个函数只会抛出bad_alloc的异常
void* operator new (std::size_t size) throw (std::bad_alloc);
// 这里表示这个函数不会抛出异常
void* operator delete (std::size_t size, void* ptr) throw()但是规范这个东西,也只是一种约束。并不是一种语法。
在C++11新增了noexcept关键字,表示不会抛异常,我想从不管是阅读性还是新颖性 都是后者占有吧~
thread() noexcept;
thread (thread&& x) noexcept;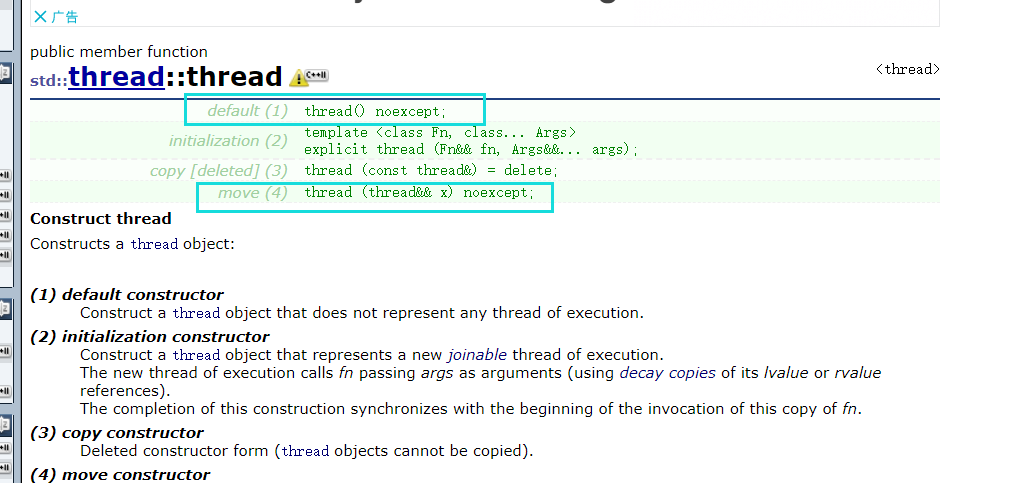
三、异常体系
实际中,很多公司都会指定一套属于自己的异常体系、异常规范。比较,在同一个项目中,程序员A
觉得这个地方抛string对象好点,但是程序员B死活喜欢抛int……外层调用难道要单独,为他们的捕捉列表catch中添加string与int吗?那又来个程序员C这次更疯狂,想抛自己的自定义类型?显然!这根本是在"玩死"外层调用者。
(1)官方库异常体系
提供了一系列标准的异常,定义在 中,我们可以在程序中使用这些标准的异常。它们是以父子类层次结构组织起来。
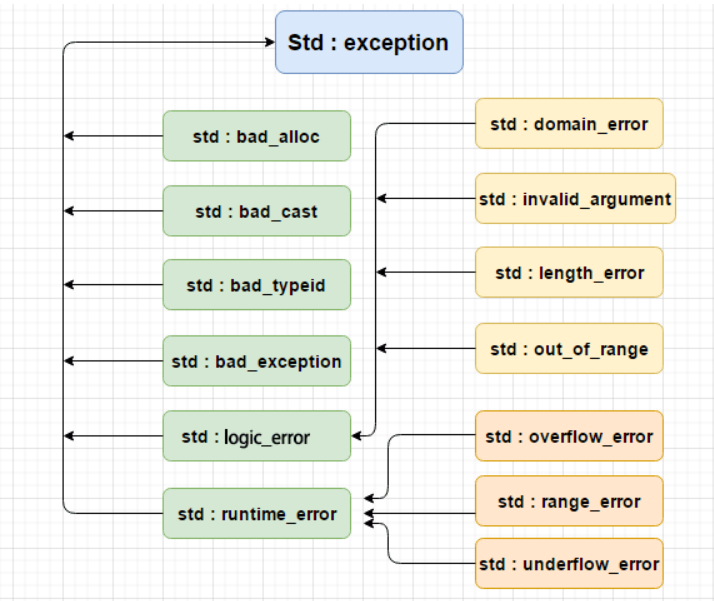
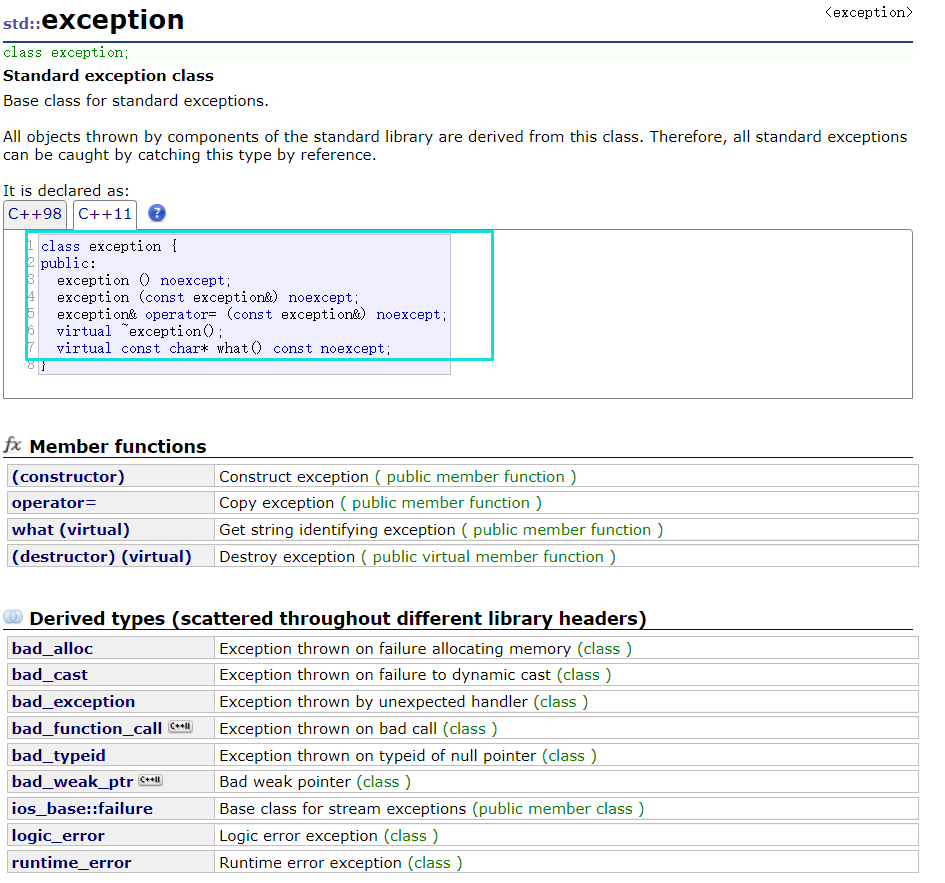
我们常见到的bad_alloc,其实就是exception继承父类的对象。我们来试试吧~
#include<exception>
void new_alloc()
{
int* a = nullptr;
if (a == nullptr) {
//抛出对象
throw std::bad_alloc();
}
}
int main()
{
try {
new_alloc();
}
catch (const std::exception e) { //捕获官方库的对象
std::cout << e.what() << std::endl; //e.what()打印信息
}
return 0;
}
但是我们实际中很少用到官方库提供的exception类,因为设计得不是很好用。很多大公司都会有自己的一套异常继承体系。
(2)自定义异常体系
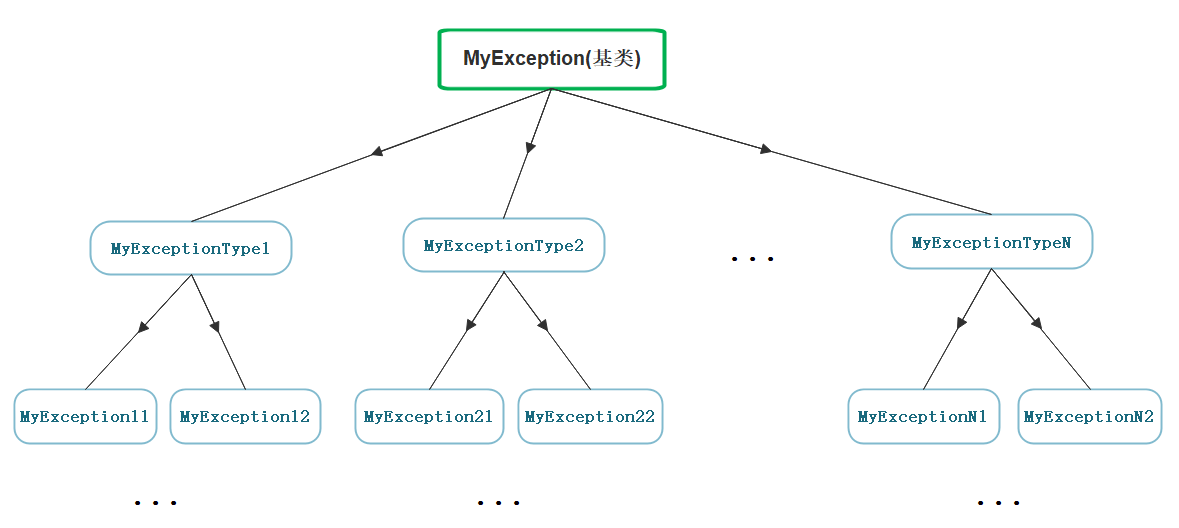
在实际中,都会定义一套规范的继承异常体系,这样大家抛出的都是继承后的派生类(derived),外层调用都可以捕获它们的基类(base)即可。
Exception
比如我们实现一个Http连接sql的继承异常类:
class Exception
{
public:
Exception(const string& errmsg,int id)
:_errmsg(errmsg),
_id(id)
{}
//打印错误
string what()const
{
return _errmsg;
}
//注意这里 不能用private 否则子类访问不到
protected:
string _errmsg;
int _id;
};
class SqlException:public Exception
{
public:
SqlException(const string& errmsg,int id,const string& sql)
:Exception(errmsg,id), //初始化继承Exception的部分
_sql(sql)
{}
private:
const string _sql;
};
class HttpServerException:public Exception
{
HttpServerException(const string& errmsg, int id, const string& type)
:Exception(errmsg,id),
_type(type)
{}
private:
const string _type;
};为了实现多态,即不抛出不同的异常对象,虽然用基类对象捕捉,但是打印的内容不同。
多态的条件:virtual + 重写。
class Exception
{
public:
Exception(const string& errmsg,int id)
:_errmsg(errmsg),
_id(id)
{}
virtual string what()const
{
return _errmsg;
}
protected:
string _errmsg;
int _id;
};
class SqlException:public Exception
{
public:
SqlException(const string& errmsg,int id,const string& sql)
:Exception(errmsg,id),
_sql(sql)
{}
virtual string what()const
{
string str = "SqlException: ";
str += _errmsg;
str += "->";
str += _sql;
return str;
}
private:
const string _sql;
};
class HttpServerException:public Exception
{
public:
HttpServerException(const string& errmsg, int id, const string& type)
:Exception(errmsg,id),
_type(type)
{}
string what()const
{
string str = "HttpServerException:";
str += _type;
str += ":";
str += _errmsg;
return str;
}
private:
const string _type;
};我们对what()进行重写。
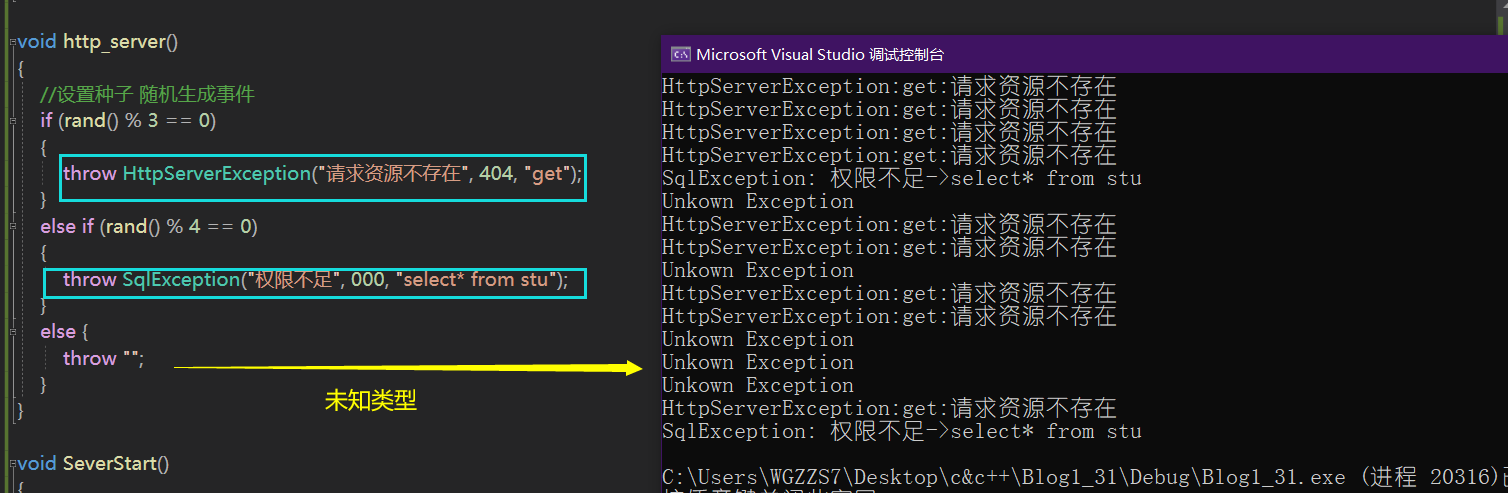
我们也就完成一份简单的http_server异常类~
四、异常优缺点
看待任何问题,都不能一刀切。好是绝对得好,差是绝对得差。异常的出现,相对于传统对待错误方式如:错误码、assert断言……更加地合理,详细,为程序员定位bug找问题提供了更便捷的途径。
优点:
1.异常对象定义好了,相比错误码的方式可以清晰准确的展示出错误的各种信息,甚至可以包
含堆栈调用的信息,为程序员定位bug找问题提供了更便捷的途径。
2.抛出异常不是返回给上层调用层,而是捕获异常的位置。
3.很多的第三方库都包含异常,比如boost、gtest、gmock等等常用的库,那么我们使用它们
也需要使用异常。
4.部分函数使用异常更好处理,比如T& operator这样的函数,如果pos越界了只能使用异常或者终止程序处理,没办法通过返回值表示错误。
缺点:
1.异常会导致程序的执行流乱跳(让人不得不想起goto语句),并且非常的混乱,并且是运行时出错抛异常就会乱跳。这会导致我们跟踪调试时以及分析程序时,比较困难。
2.异常会有一些性能的开销。当然在现代硬件速度很快的情况下,这个影响其实可以忽略不计。
3.从语言层面上的负担,在于C++没有垃圾回收机制,资源需要自己管理。有了异常非常容易导致内存泄漏、死锁等异常安全问题。这个需要使用RAII智能指针来处理资源的管理问题。学习成本较高。
4.C++标准库的异常体系定义得不好,导致大家各自定义各自的异常体系,非常的混乱。
5.异常尽量规范使用,否则后果不堪设想,随意抛异常,外层捕获的用户苦不堪言。所以异常
规范有两点:一、抛出异常类型都继承自一个基类。二、函数是否抛异常、抛什么异常,都
使用 func() throw();的方式规范化。
总结:
①异常是面向对象语言如java/c++等等,处理错误的一种方式。
②异常就是程序运行期间的一种error,不同于编译期间的error。
③捕获的规则:被选中的处理代码是调用链中与该对象类型匹配且离抛出异常位置最近的那一个。
④异常安全+规范
⑤异常优缺点
本篇到此结束,感谢你的阅读。
祝你好运,向阳而生~


![[Ansible系列]ansible tag介绍](https://img-blog.csdnimg.cn/44edd5ffd33d41159cbd2783a4980685.png)