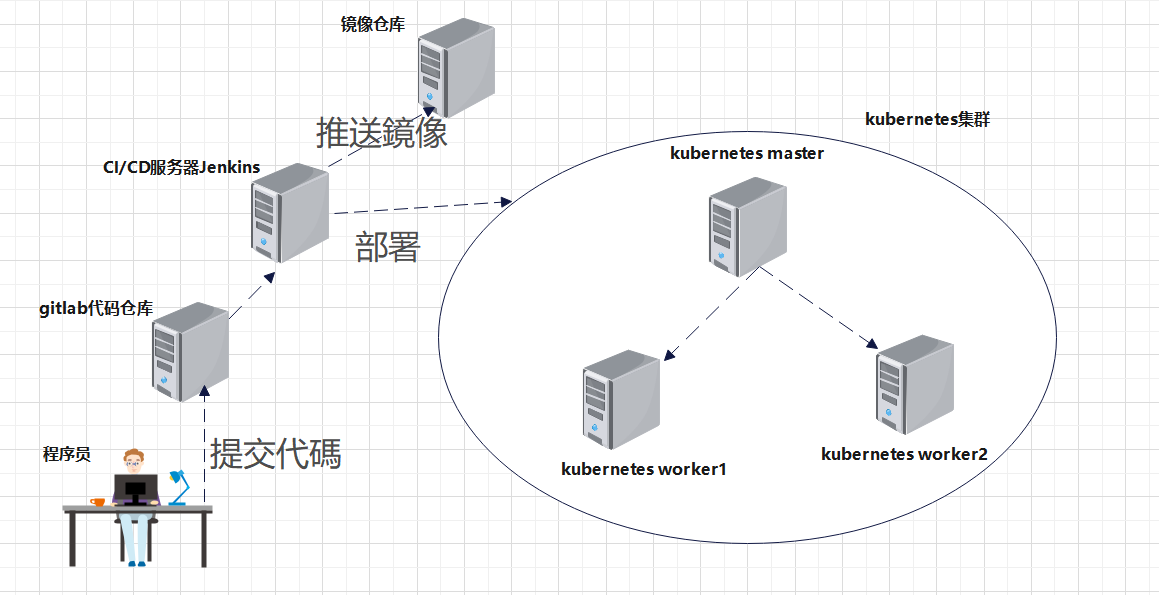
上一篇我们介绍了transform专题一:Seq2seq model,也知道了transfrom属于seq2seq模型,这一排篇咱们接着介绍另外几种seq2seq架构的模型。)RNN(循环神经网络)CNN(卷积神经网络),最后我们还会介绍一种transformer采用的self-attention模型
RNN(Recurrent Neural Network)和CNN(Convolutional Neural Network)是两种不同类型的神经网络架构,分别适用于不同类型的数据和任务。下面我们来详细介绍这两种网络的原理、特点和应用场景。
RNN(循环神经网络)
原理
RNN是一类用于处理序列数据的神经网络,其结构允许信息在序列的各个时间步之间传递。与传统的前馈神经网络不同,RNN具有循环连接,使其能够处理时间序列数据或其他顺序相关的数据。
RNN的基本单元是一个神经元,它在每个时间步都接收当前输入和前一时间步的隐藏状态,然后计算出当前的隐藏状态。这个隐藏状态不仅包含当前输入的信息,还包含前一时间步的信息。
数学表达
RNN的核心公式如下:
[ h_t = \sigma(W_h \cdot h_{t-1} + W_x \cdot x_t + b) ]
其中:
- ( h_t ) 是当前时间步的隐藏状态
- ( h_{t-1} ) 是前一时间步的隐藏状态
- ( x_t ) 是当前时间步的输入
- ( W_h ) 和 ( W_x ) 是权重矩阵
- ( b ) 是偏置向量
- ( \sigma ) 是激活函数(如tanh或ReLU)
特点
- 处理序列数据:RNN擅长处理和预测序列数据,能够捕捉时间步之间的依赖关系。
- 记忆能力:通过循环连接,RNN能够记忆序列中的信息,适用于需要上下文信息的任务。
- 梯度消失和爆炸:RNN在处理长序列时可能会遇到梯度消失或梯度爆炸问题,影响训练效果。
变种
为了克服RNN的缺点,研究人员提出了多种RNN的变种:
- LSTM(长短期记忆网络):通过引入门机制(输入门、遗忘门和输出门),LSTM能够更好地捕捉长距离依赖关系。
- GRU(门控循环单元):GRU是LSTM的简化版,通过减少门的数量,保留了LSTM的优势,同时提高了计算效率。
应用场景
- 自然语言处理(NLP):如机器翻译、文本生成、语音识别等。
- 时间序列预测:如股票价格预测、天气预报等。
- 语音和视频处理:如语音识别、视频分析等。
CNN(卷积神经网络)
原理
CNN是一类专门用于处理图像数据的神经网络,通过卷积操作提取图像的空间特征。CNN利用局部连接和共享权重的机制,能够有效地处理高维图像数据。
CNN的基本组成部分包括卷积层(Convolutional Layer)、池化层(Pooling Layer)和全连接层(Fully Connected Layer)。
卷积层
卷积层通过卷积核(也称为滤波器)在输入图像上进行滑动窗口操作,提取局部特征。每个卷积核可以检测不同的特征,如边缘、角点等。
卷积操作的公式如下:
[ (I * K)(i, j) = \sum_m \sum_n I(i+m, j+n) \cdot K(m, n) ]
其中:
- ( I ) 是输入图像
- ( K ) 是卷积核
- ( (i, j) ) 是卷积操作的位置
池化层
池化层通过对卷积层的输出进行下采样,减少数据量和计算量,同时保留重要的特征。常见的池化操作包括最大池化(Max Pooling)和平均池化(Average Pooling)。
全连接层
全连接层将前面的特征图展平,并进行分类或回归任务。全连接层与传统的前馈神经网络类似,所有的输入节点与输出节点相连。
特点
- 局部连接:卷积操作只在局部区域内进行,有效减少了参数数量。
- 共享权重:同一卷积核在整个图像上共享参数,减少了过拟合的风险。
- 平移不变性:卷积操作能够有效识别图像中的特征位置,使模型对图像的平移具有鲁棒性。
应用场景
- 图像分类:如手写数字识别(MNIST)、物体识别(ImageNet)等。
- 目标检测:如人脸检测、车辆检测等。
- 图像分割:如语义分割、实例分割等。
- 医学影像分析:如病灶检测、图像重建等。
RNN与CNN的对比
| 特点 | RNN | CNN |
|---|---|---|
| 主要应用领域 | 序列数据处理,如NLP、时间序列预测 | 图像数据处理,如图像分类、目标检测 |
| 数据类型 | 时间序列、文本、语音等 | 图像、视频等 |
| 核心操作 | 循环连接 | 卷积操作 |
| 处理长序列的能力 | 可能遇到梯度消失或爆炸问题 | 不适用于处理长序列 |
| 参数量 | 参数量较多,尤其是长序列 | 通过局部连接和共享权重减少参数量 |
| 平移不变性 | 不具备平移不变性 | 具有平移不变性 |
| 记忆能力 | 能够记忆和处理序列中的上下文信息 | 主要用于捕捉图像中的局部特征 |
| 变种 | LSTM、GRU | 卷积神经网络变种,如ResNet、DenseNet |
总之,RNN和CNN是两种重要的神经网络架构,分别擅长处理不同类型的数据。RNN适用于处理序列数据,能够捕捉时间步之间的依赖关系,而CNN则适用于处理图像数据,能够有效提取图像的空间特征。在实际应用中,选择哪种网络架构取决于具体的任务和数据类型。
自注意力机制(Self-Attention)是Transformer模型的核心部分,它在自然语言处理(NLP)任务中取得了显著的成功。与传统的RNN和CNN不同,自注意力机制能够在序列的所有位置之间直接建立联系,使模型能够捕捉长距离的依赖关系。以下是对自注意力机制的详细介绍。
自注意力机制的基本原理
自注意力机制通过对输入序列中的每个元素计算其与其他元素的相关性(注意力分数),从而生成新的表示。这个过程可以分为以下几个步骤:
1. 计算查询(Query)、键(Key)和值(Value)
对于输入序列中的每个元素,我们首先计算三个向量:查询向量 (Q)、键向量 (K) 和值向量 (V)。这些向量通过与可训练的权重矩阵进行线性变换得到:
[ Q = XW_Q ]
[ K = XW_K ]
[ V = XW_V ]
其中,(X) 是输入序列,(W_Q)、(W_K) 和 (W_V) 是可训练的权重矩阵。
2. 计算注意力分数
接下来,我们计算查询向量 (Q) 与键向量 (K) 的点积,并进行缩放(除以 (\sqrt{d_k})),然后通过Softmax函数得到注意力分数:
[ \text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V ]
其中,(\sqrt{d_k}) 是缩放因子, (d_k) 是键向量的维度。
3. 计算加权和
使用注意力分数对值向量 (V) 进行加权求和,得到最终的输出向量。
4. 多头注意力机制
为了使模型能够捕捉更多的特征,自注意力机制通常会使用多头注意力(Multi-Head Attention)。多头注意力机制将查询、键和值向量分为多个子空间,并在每个子空间上独立计算注意力,最后将这些结果拼接在一起:
[ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \text{head}_2, \ldots, \text{head}_h)W_O ]
其中,每个头的计算方式为:
[ \text{head}i = \text{Attention}(QW{Q_i}, KW_{K_i}, VW_{V_i}) ]
自注意力机制的优势
- 并行化:与RNN不同,自注意力机制可以在计算时并行处理输入序列中的所有位置,提高了训练效率。
- 长距离依赖:自注意力机制能够直接在序列的所有位置之间建立联系,更好地捕捉长距离依赖关系。
- 灵活性:自注意力机制可以用于各种类型的输入数据,不仅限于时间序列。
Transformer模型
自注意力机制是Transformer模型的核心组件。Transformer模型由编码器和解码器组成,每个编码器和解码器包含多个堆叠的自注意力层和前馈神经网络(Feed-Forward Neural Network)层。
编码器(Encoder)
每个编码器层包含两个主要部分:
- 多头自注意力层(Multi-Head Self-Attention Layer):计算输入序列中每个元素之间的注意力分数。
- 前馈神经网络层(Feed-Forward Neural Network Layer):对自注意力层的输出进行进一步处理。通常包含两个全连接层和一个ReLU激活函数。
此外,每个层还有残差连接(Residual Connection)和层归一化(Layer Normalization),以提高训练稳定性和模型性能。
解码器(Decoder)
解码器的结构与编码器类似,但包含额外的注意力层,用于计算解码器输入与编码器输出之间的注意力分数。每个解码器层包含三个主要部分:
- 掩码多头自注意力层(Masked Multi-Head Self-Attention Layer):类似于编码器的自注意力层,但对未来的时间步进行掩码,以防止信息泄露。
- 多头注意力层(Multi-Head Attention Layer):计算解码器输入与编码器输出之间的注意力分数。
- 前馈神经网络层(Feed-Forward Neural Network Layer):与编码器中的前馈神经网络层类似。
Transformer模型的应用
Transformer模型在各种NLP任务中取得了显著的成功,包括:
- 机器翻译:如Google的翻译服务,使用Transformer模型实现高质量的翻译。
- 文本生成:如OpenAI的GPT系列模型,可以生成连贯且有意义的文本。
- 文本分类:如BERT模型,通过预训练和微调,实现了各种文本分类任务的高性能。
- 问答系统:如BERT和GPT,可以用于构建智能问答系统,回答用户的问题。
代码示例
以下是使用PyTorch实现自注意力机制的简化示例:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# Split the embedding into self.heads different pieces
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys]) / (self.embed_size ** (1 / 2))
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(energy, dim=3)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
out = self.fc_out(out)
return out
# 示例输入
embed_size = 256
heads = 8
seq_length = 10
batch_size = 32
values = torch.randn(batch_size, seq_length, embed_size)
keys = torch.randn(batch_size, seq_length, embed_size)
query = torch.randn(batch_size, seq_length, embed_size)
mask = None
attention = SelfAttention(embed_size, heads)
out = attention(values, keys, query, mask)
print(out.shape) # 输出的形状应该是 (batch_size, seq_length, embed_size)
总结
自注意力机制是现代自然语言处理模型(如Transformer)的核心,具有处理并行化、捕捉长距离依赖和灵活性强等优点。通过多头注意力机制,自注意力模型能够有效地捕捉序列中的多种特征,广泛应用于机器翻译、文本生成、文本分类和问答系统等任务。




![[图解]SysML和EA建模住宅安全系统-11-接口块](https://i-blog.csdnimg.cn/direct/bb7ddea205744947a0cdd6abb14fb3e8.png)