4.0 目录
[TOC]
4.1 概述
作用:主机到主机之间传输TCP segment或UDP datagram
将段封装成IP datagram以及解封装IP datagram【在网络边缘和路由器上都要进行】
A.两大功能:转发+路由
转发:从不同的端口接收数据,再通过合适的端口发送出去
路由:怎么样从源主机一步步选择路径发送到目的主机
转发是一个局部的功能,而路由是一个全局的功能
路由决定了路径,而转发则决定在一个路口走哪个方向
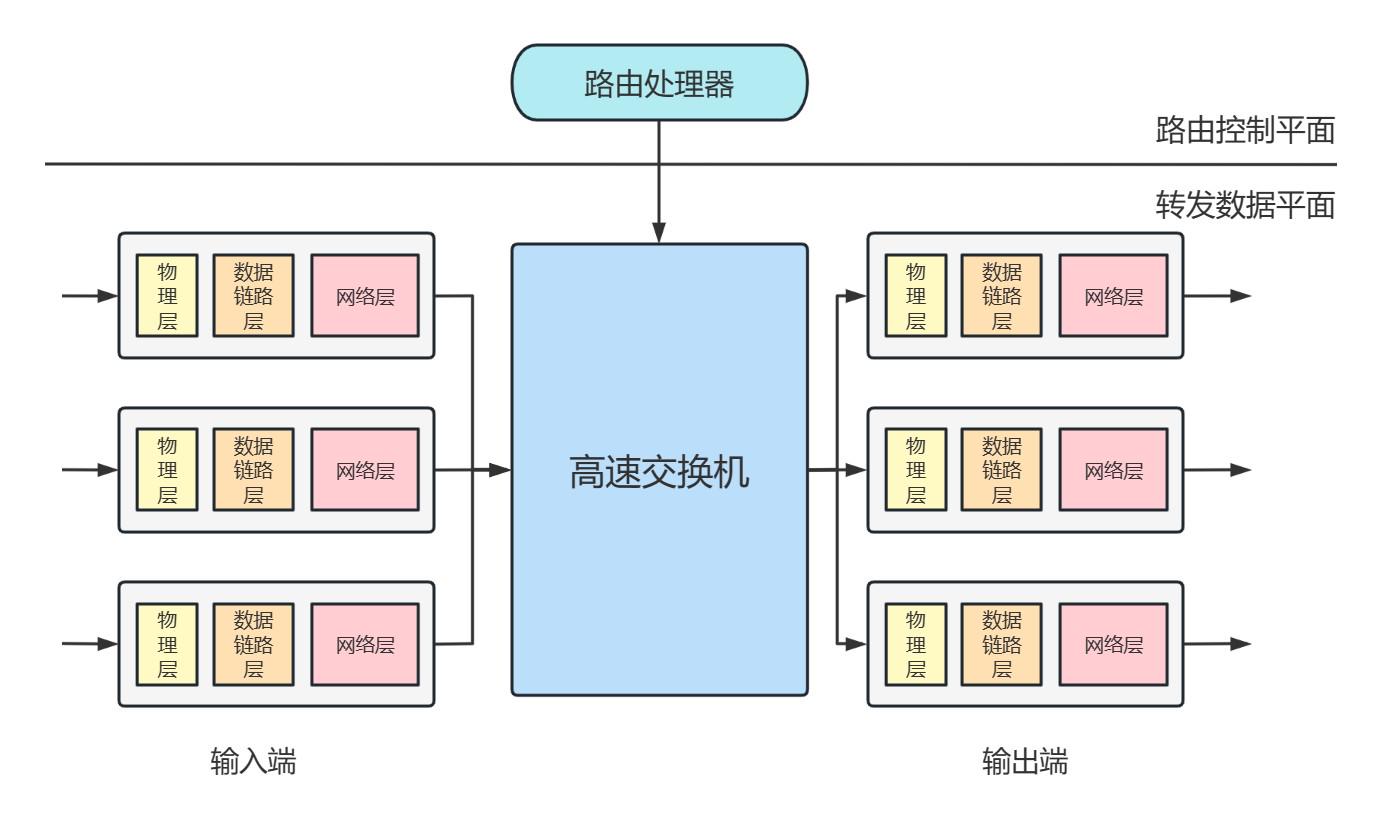
A. 数据平面介绍
负责转发功能
传统方式:直接根据目标地址,查路由表决定从哪个端口发送出去
SDN软件定义网络方式:基于多个字段+流表(传统方式只基于IP字段)
B. 控制平面介绍
负责路由的功能
需要通过路由选择协议(RIP,OSPF,BGP)计算出路由表,并交给数据平面进行转发
网络操作系统计算,通过南向接口Southbound Interface交给设备
SDN方式下可以有多种操作:转发,阻止Block,泛洪
C. 路由器介绍
C1. 传统模式下
在传统方式下,路由器集成了数据平面与控制平面的实现
在路由器上路由与转发功能是紧耦合的,路由选择协议计算出路由表,并且通过转发功能发送出去。
总体上,数据平面与控制平面都是分布式地完成的
不足:由于数据平面与控制平面是紧耦合的,行为逻辑是非常难改。因为路由器分布在全球,不可能全改,十分僵化
C2. SDN模式
由于流表的计算集成在服务器上,由网络操作系统进行计算,并且通过南向接口传递给每个路由器
因此当需要修改行为逻辑时,只需要修改服务器即可(服务器是集中式分布的,很好修改).而且每种行为都是可编程的
SDN模式下的'路由器'叫做:分组交换机

D.常用指标
服务模型 = 所有常用指标对应特定值时,提供服务的描述
如:IP协议啥都不保证,因此其服务模型叫:Best Effort
D1. 对单个数据报
是否可靠:如ATM网络是有连接的网络
有连接和面向连接是不同的,面向连接指的是只有两个端知道连接,而有连接是指中间每一个段节点都得维护连接关系
例如第一章中讲过的的虚电路网络,就通过虚电路表在每个节点都保障连接
延时是多少
D2.对一系列数据报
数据报保序性
保证的带宽
分组延迟差
4.2 路由器组成
传统路由器的结构示意图如下:
A. 输入端口缓存
输入端口缓存的作用:为了匹配进入输入端可能存在的速率不匹配问题
你可能会问:输入端口缓存是为了应对输入的速度比输出的速度大的情况,但是对于输入端口而言,他的输出是给告诉交换机的,怎么可能高速交换机的速度比输入数据的速度还慢?
的确,交换机的速度比输入数据的速度来的快,但是有可能出现头部阻塞的问题,也就是当下有非常多用户都要朝着一个网卡(输出端口)的方向去发送数据报【双十一的时候,都朝着淘宝服务器方向发请求】,那么数据报多了必然会造成排队,因而有必要设置输入端口的缓存
输入端口缓存的示意图如下:

在上图中,B和C端口来的报文都需要转发到紫色的出口,因此就会有报文需要等待,此时输入端口缓存就有用武之地了。
如果缓存区满了,那么数据包就会被直接抛弃掉
B. 交换结构
交换结构主要是在交换机中怎么从输入端口转到输出端口,有三种常见的结构
fabric交换机的交换速率一定要是输入端口的N倍(对于有N个输入端口的情况)。例如输入端口的交换速率为1000ppm:Packet Per Minute,且总共有3个输入端口,那么交换机的交换速率v ≥ 3000ppm
B1. Memory
第一代的路由器,相当于直接使用电脑作为交换设备,并且利用系统总线作为交换线路System Bus
Memory结构示意图如下:
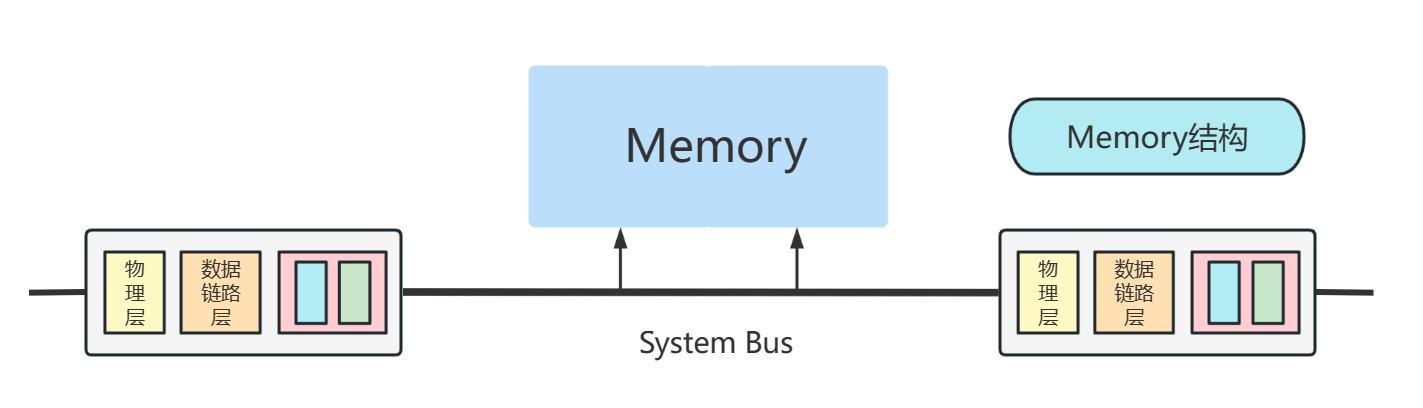
根据上图可以知道,一个分组传递需要两次经过系统总线,因此系统总线会大大限制交换的速率
B2. Bus总线
Bus总线结构改善了Memory问题,分组只需要经过一次总线,且总线也不采用电脑的系统总线,使得分组传输速率大大提升
该结构示意图如下:
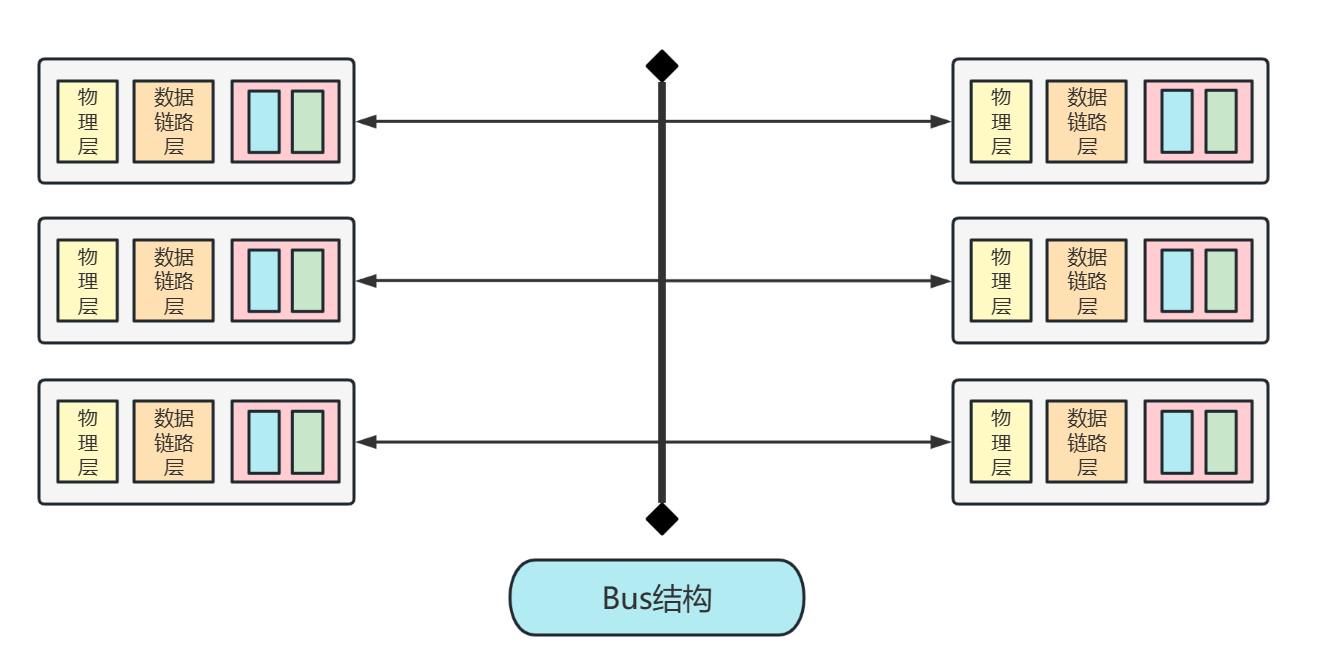
B3. CrossBar互联网络
CrossBar互联网络结构进一步优化结构,设计了一个类似多路并行的结构,即不同端口之间的数据传输并不需要共用整条总线,再次提升了传输速率,适合用作核心交换设备
结构示意图如下:
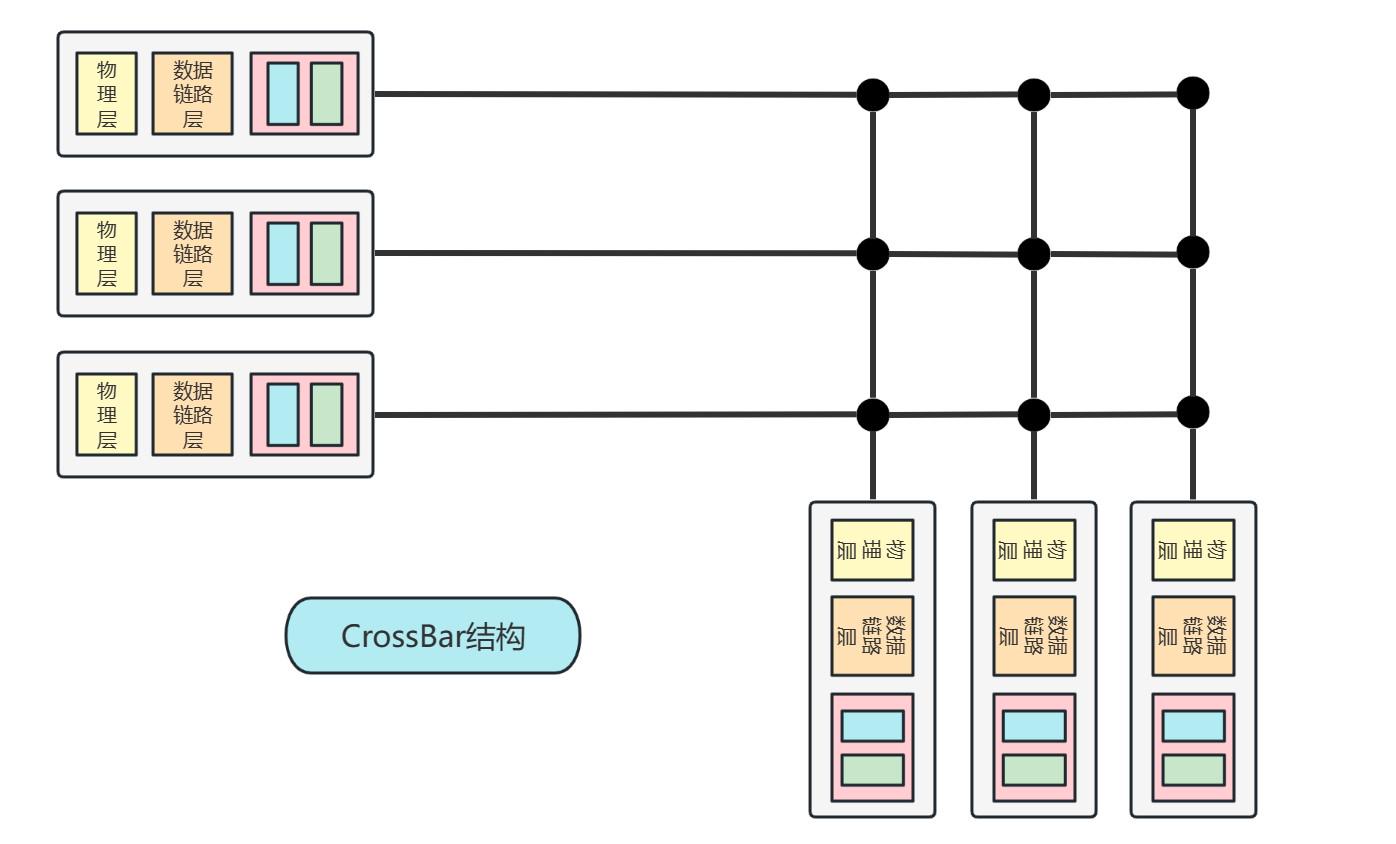
C. 输出端口缓存
同样是用来匹配输入和输出的速度的。输出端口缓存比较好理解,因为输入来自高速交换机,输入速度快,而输出速度慢,设置缓存区很有必要。
先来的一定先传吗?
不一定,依照一定的调度规则【见下面的C1】确定其优先级(例如优先传实时多媒体的应用)
C1. 调度方案
FIFO:First in first out按照分组到达的优先次序来发送
RR:Round Robin风水轮流转发送,依照头部等信息把分组分成不同的组别,例如分成红色,蓝色,绿色分组,那么就按照红绿蓝,红绿蓝的顺序依次发送
WFQ: Weight Fair Queuing按照每个类别分组数量的比例,分配服务时间,其实就是RR分配方式的普遍形式
丢弃策略:
tail drop:按照顺序,最晚来的分组被丢弃
priority:根据分组的优先级丢弃分组【可以根据头部等信息分类】
random:随机丢弃分组
4.3 IP协议
A. IP数据报的形式(头部+Body)
IP数据报的格式如下图所示:
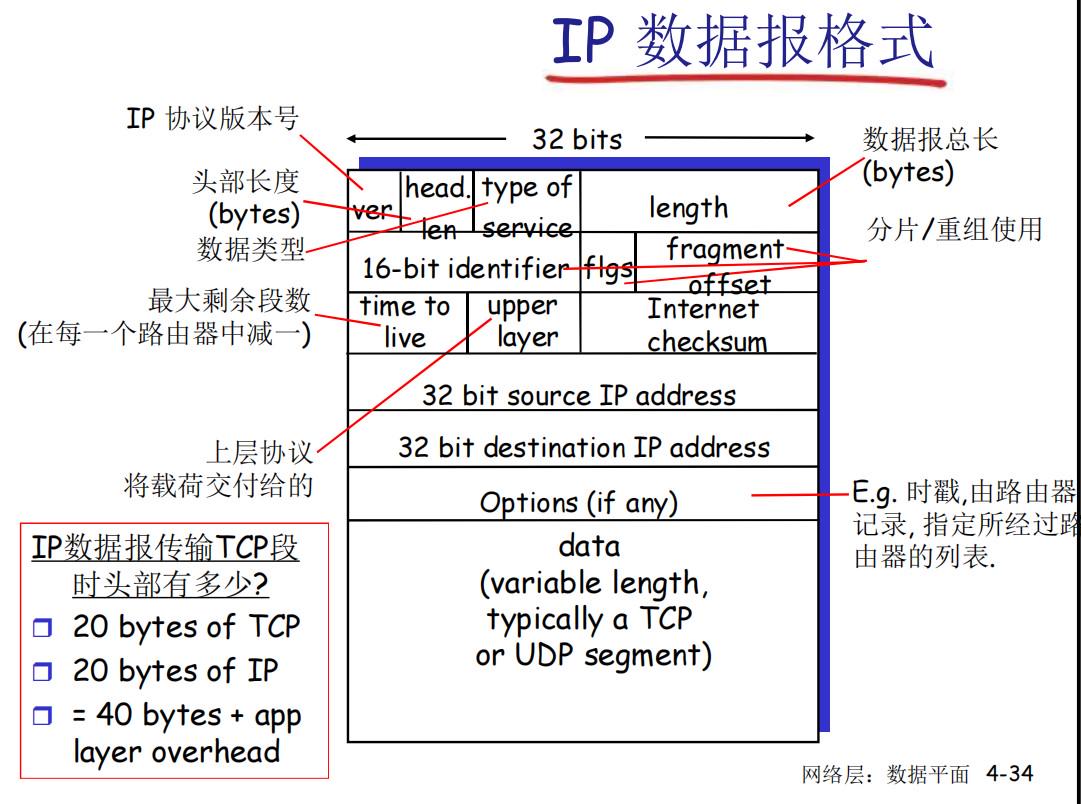
其中第一个ver是版本号:IPv4或IPv6
第二个时head len代表头部的长度,以四个字节为单位,最小为5【即当头部可选项为空的时候,总共20个字节,因此head len为5】
Internet checksum是对头部的校验和
B. IP分片与重组
为什么需要分片?
一个路由器不同接口所连接的网络很可能是不同的,有可能一个网卡连接的是FDDI:Fiber Distributed Data Interface光纤分布式数据接口网络而另外一个网课连接的是EtherNet以太网。而不同的数据链路网络可能会具有不同大小的MTU:Max Transfer Unit最大传输单元
因此,从帧较大的网络转发进入帧较小的网络就需要进行分片,否则无法进行传输。那么分片的时候需要保证IP地址的一致,并通过上面所说的16-bit identifier,flgs,fragment offset字段进行标记
需要进行IP Segmentation的情景如下图所示:

IP分片得到的结果,以及对应分片的报文头部字段如下图所示:
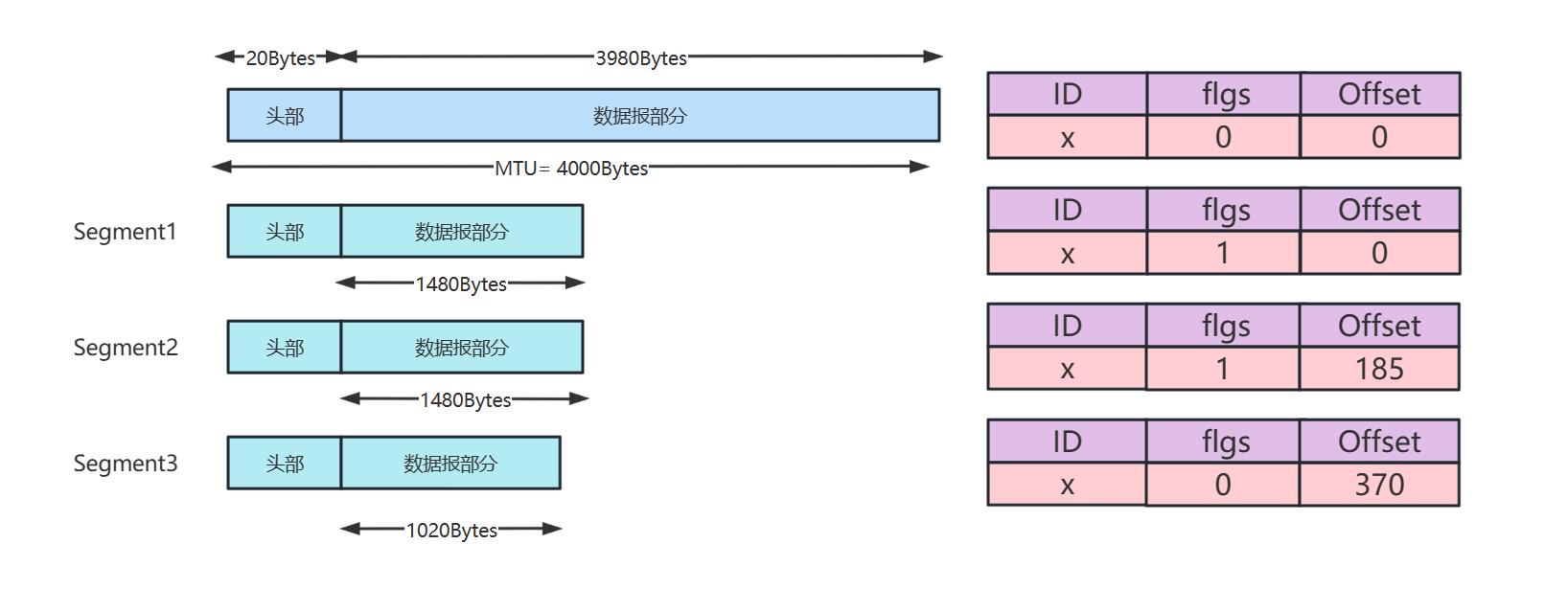
需要特别说明的是,报文头部的fragment offset分片偏移量字段是以8个字节为单位的,而不是一个字节,因此上述分片中的偏移量分别是185,370而不是1480,2960
C. IP地址
IP地址其实不是用来表示一台设备,而是一台设备中一个网络接口的标识,是标志一个点的
C1. 子网(Subnet)
纯子网
具有相同的前缀(就是IP地址与子网掩码相与得到相同的结果)
且一个子网内部所有主机在通信的时候不需要经过路由器,可以通过交换机等交换结构进行通信(在IP的层面是一跳可达的)
非纯子网
一个比较宏观抽象的概念,在外部的角度看,一定区域内的主机可以构成一个子网,但是里面含有路由器设备
子网内部更高的IP号相同,但每台主机的IP地址与对应的子网掩码号相与等到的结果可能不同
C2. IP地址的分类
IP地址约定全0和全1的地址不用来标识主机(全0是本网络,全1是广播地址)
互联网的转发是以整个网络为单位进行计算和转发的
因此对于一个路由器而言,只关心发往哪个网络,而不关心具体哪个主机
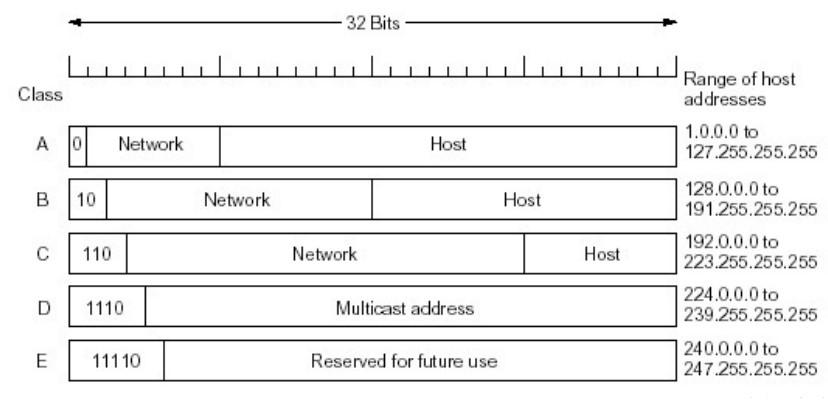
A类的网络号有7位,主机号共有24位,126个网络,每个网络1600万台主机
B类的网络号有14位,主机号共有16位,共有16382个网络,每个网络65534台主机
C类的网络号共有21位,主机号共有8位,因此共有200万个网络,每个网络只有254台主机
在上述的分类之下,其实并不需要子网掩码的存在,只需要按照网络的分类取出网络号即可
D. IP编址:CIDR
CIDR:Classless InterDomain Routing无类域间路由
由于前面对网络的分类会导致A类网络和B类网络数量很少,很快被分配完了,而数量很多的C类网络主机数量不够。且A类网络和B类网络中存在很严重的资源浪费问题,因此,而CIDR则可以更精准地划分网络规模
但是对于无类的网络,需要标记网络号的位置,因而需要子网掩码(子网掩码中,网络号的对应位全部是1,主机位对应的位全部是0)
E. 转发表与转发的过程
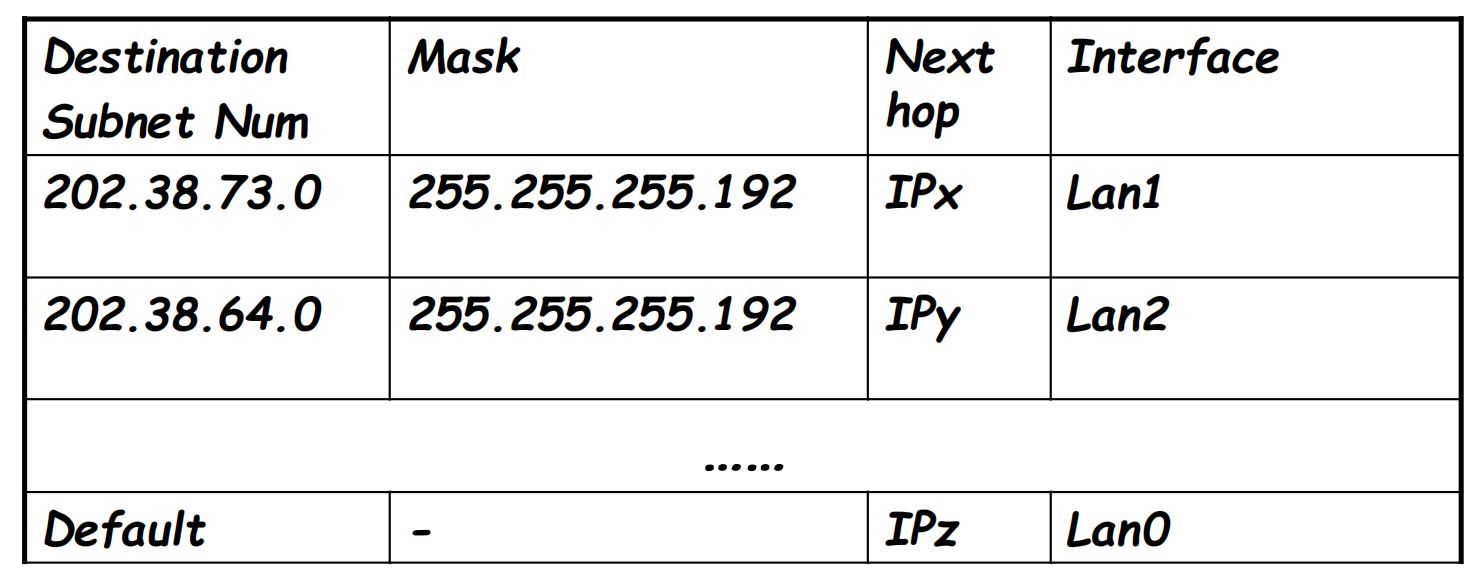
由上图可以知道,转发表需要包括四个字段:网络号,子网掩码,下一跳以及接口(对应的网卡)
首先将源IP地址与转发表中的子网掩码依次相与,看得到的网络号是否有与表中的网络号相匹配的,如果有,则根据表中的下一跳地址交给对应的接口(网卡)
如果所有表象都没能匹配上,那么就匹配default默认网关选项,默认网关一般是子网的出口路由器的方向
注:可能一个网络号可以匹配几个表项,选择最长前缀匹配的原则,进行最精确的匹配
F. IP地址怎么获取?
方法1:由网络管理员直接进行分配,需要分配四个信息:IP地址,子网掩码,默认网关以及Local Name Server本地的名字服务器,用于域名解析(DNS)
方法2(plug-and-play即插即用):利用DHCP:Dynamic Host Configuration Protocol动态主机配置协议,直接获取四个信息IP地址,子网掩码,默认网关以及Local Name Server本地的名字服务器
一台设备利用DHCP获取IP地址的过程如下:
首先当主机上先的时候需要用广播通知整个网路,包括DHCP服务器,但是当时主机还没有IP地址,也没有目的的IP地址,怎么发送报文呢?
直接以全0位源IP地址(代表本主机),并且以全1位目标IP地址,代表广播
DHCP通过UDP(事务性的用UDP)给主机发出分配的信息:IP地址,子网掩码,默认网关以及Local Name Server本地的名字服务器以及过期时间,时间到了之后需要更新一下信息
一个机构怎么获得和分配IP地址?
一个机构先从ISP出获取一个IP的网络号
例如,ISP给一个机构分配了20位的网络号,因此有12位可以用来分配给主机,那么该机构又有8个子机构,因此机构可以在12位中分出最高的3位用作子机构的标识,层层分配下去。
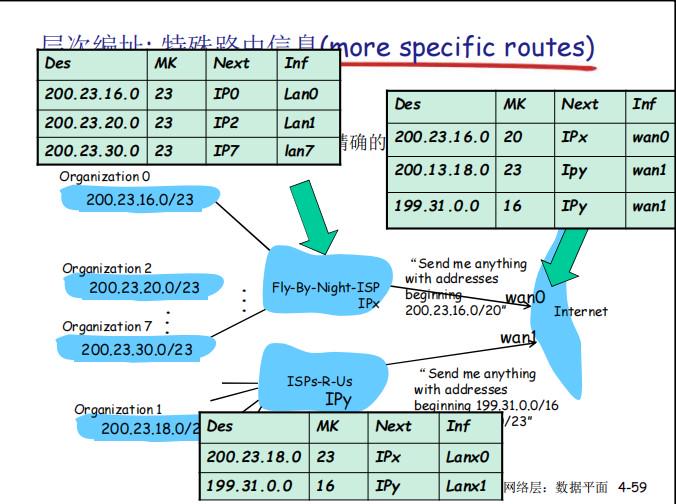
G.层次编址:路由聚集(Routing Aggression)
隶属于一个大网络的小子网可以通过路由通告告诉大网络的路由器
例如一个大机构下面有若干子机构,每个子机构的IP都由大机构进行分配,并连接到大机构的路由器,因此整个机构对外其实就可以看成只有大机构一个出口,而不用暴露出每个子机构的IP号,只有当报文到达大机构的路由器时,大机构才根据自己的路由表将数据报文转发给子机构的路由器
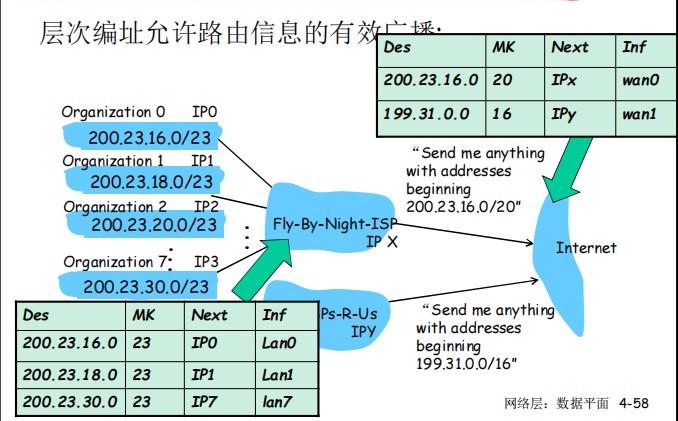
当然,机构对外的路由器也可以不只有一个,如下图所示(在匹配的时候依然使用最大前缀匹配的原则):
H. NAT:Network Address Translation
如果一个单位还没有拿到自己独享的IP地址(或者为了节省成本)而且有希望在自己的网络内部部署业务,就可以采用内网的IP,例如最常见的192.168.xxx.xxx就是内网地址
但是内网地址是物联网不承认的地址,因此,内网地址需要经过翻译才能得到互联网所承认的地址,因此需要NAT进行翻译
在数据报出去的时候,我们要替换IP地址和端口号,相当于建立一个内网IP地址,实际端口号与对外的IP地址和对外的端口号之间的映射,当数据报回来的时候就可以通过映射关系发给相应的主机进程