文章目录
- 学习内容
- LLaMA
- LLaMA模型结构
- LLaMA下载和使用
- 好用的开源项目[Chinese-Alpaca](https://github.com/ymcui/Chinese-LLaMA-Alpaca)
- Chinese-Alpaca使用
- 量化
- 评估
学习内容
- 完整学习LLaMA
LLaMA
- 2023年2月,由FaceBook公开了LLaMA,包含7B,13B,30B,65B。
- 2023年7月,发布LLaMA2,包含7B,13B,65B。
- 可商用
- 模型架构不变,但训练数据增加了40%
- 34B模型由于未满足安全要求并未发布
- 包含基座模型和Chat模型:LLaMA 2 - chat
论文部分介绍:
- 数据来源于公开数据集
- 目的:在推理预算有限的情况下,达到更好的效果。
- LLaMA 13B在大多数测试中优于GBT3-175B,65B相比当时最好的模型也有竞争力。
- 主要工作:通过更多的token训练语言模型。
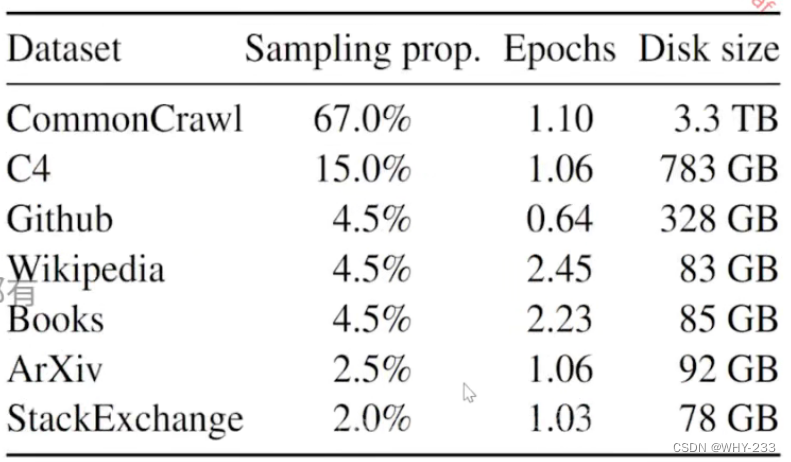
- 主要针对英语进行训练,也使用了部分其他语言。
LLaMA模型结构
和 GPT 系列一样,LLaMA 模型也是 Decoder-only 架构,但结合前人的工作做了一些改进,比如:
- Pre-normalization [GPT3]. 为了提高训练稳定性,LLaMA 对每个 transformer 子层的输入进行归一化,使用 RMSNorm 归一化函数,Pre-normalization 由Zhang和Sennrich(2019)引入。
- SwiGLU 激活函数 [PaLM]. 将 ReLU 非线性替换为 SwiGLU 激活函数,且使用 2 3 4 d \frac{2}{3} 4d 324d 而不是 PaLM 论文中的 4d,SwiGLU 由 Shazeer(2020)引入以提高性能。
- Rotary Embeddings [GPTNeo]. 模型的输入不再使用 positional embeddings,而是在网络的每一层添加了 positional embeddings (RoPE),RoPE 方法由Su等人(2021)引入。
LLaMA下载和使用
- 模型申请:地址
- 模型代码:地址(可以使用download脚本,只保留7b)
- 我对校验不太了解,大家可以校验一下,我就肉眼看大小校验了。
- 模型无法运行LLaMA初始权重,需要用transformers的脚本,convert_llama_weight_to_hf.py
- 简单推理函数脚本和其中的文件
好用的开源项目Chinese-Alpaca
-
本地GPU、CPU部署
-
开源中文LLaMA模型,和指令微调的Alpaca大模型
-
在原模型的基础上,扩充vocab词表,使用中文数据进行“继续训练”,并使用中文指令数据进行微调。
-
该仓库的中包含的大模型。Chinese-LLaMA-7B是在原版LLaMA-7B的基础上,在20GB的通用中文语料库上进行预训练。Chinese-LLaMA-Plus-7B是在原版LLaMA-7B的基础上,在120GB的通用中文语料库上进行预训练
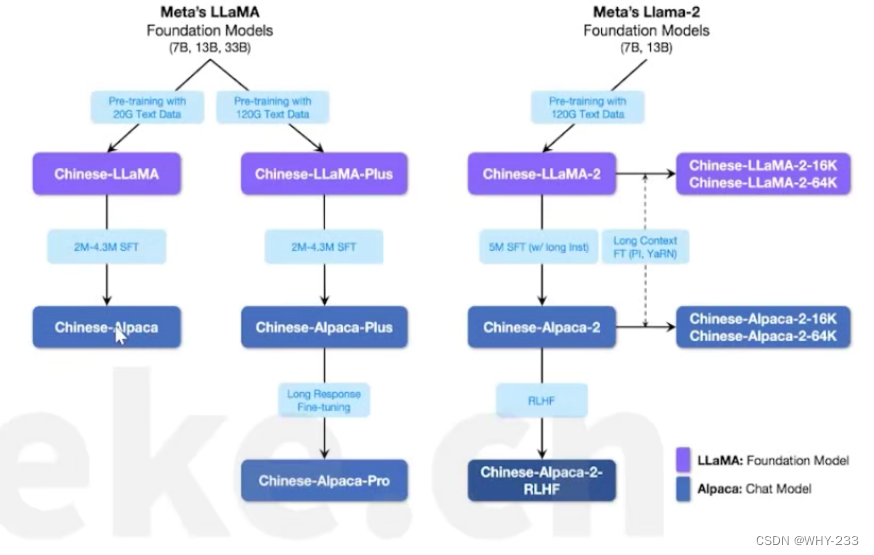

ea26e0bbd92aba9b6.jpeg) -
完全使用LoRA进行预训练和微调,需要原版的LLaMA模型。
-
LoRA居然能有这么强……太离谱了。
Chinese-Alpaca使用
- 根据官方教程即可,仅记录不同之处。
- 单LoRA权重合并效果一般,建议使用多LoRA合并。(Plus和Pro)
量化
- 量化:使用llama.cpp进行量化
- 加入-t和别的参数之后效果极快
评估
- 使用wikitext或自己构建数据集评估困惑度
- 也可以使用GPT4或人类打分


![[JS]正则表达式](https://img-blog.csdnimg.cn/img_convert/778fd76ce8dc7f915d6457224766a20e.png)