前言👀~
上一章我们介绍了什么是定时器以及如何去实现一个定时器,今天我们来讲解在多线程中同样很重要的一个内容线程池
线程池的出现
线程池概念
标准库中的线程池
工厂模式
newCacheThreadPool方法
newFixedThreadPool方法
ThreadPoolExecutor类
ThreadPoolExecutor的构造方法(重要)
线程数相关参数的解释
关于线程池线程数目设置(重要)
时间参数的解释
阻塞队列参数的解释
工厂类参数的解释
线程池的拒绝策略参数的解释(重要)
手动模拟实现线程池
如果各位对文章的内容感兴趣的话,请点点小赞,关注一手不迷路,讲解的内容我会搭配我的理解用我自己的话去解释如果有什么问题的话,欢迎各位评论纠正 🤞🤞🤞
个人主页:N_0050-CSDN博客
相关专栏:java SE_N_0050的博客-CSDN博客 java数据结构_N_0050的博客-CSDN博客 java EE_N_0050的博客-CSDN博客

线程池的出现
我们知道线程诞生的意义,是因为进程的创建和销毁的操作开销太大并且效率不高,但是呢如果频繁的创建和销毁线程,开销也不小
下面使用两种办法,进一步提高线程效率
1.协程(轻量级线程):它比线程更轻,它把系统调度的过程省略,我们自己动手调度,当下流行的并发编程的手段,在java中不够流行,GO和Python使用的更多,java只能靠第三方库去使用协程,但是第三方库不一定靠谱
2.线程池:咋们使用它来提高效率,池这个词是计算机中一种比较重要的概念,很多地方涉及到,例如线程池、进程池、内存池、连接池
线程池概念
线程池:一种并发编程中常用的技术,用于管理和重用线程。它由线程池管理器(ThreadPoolExecutor)、工作队列(BlockingQueue)和线程池线程(Thread)组成。在我们使用一个线程的时候,提前把后面的线程创建好放在线程管理器中,这样接下来要使用这些线程的时候,直接从线程池管理器中取即可,并且从工作队列中取出任务,让线程池中的线程去执行任务。线程池最大的好处是为了避免频繁地创建和销毁线程的开销,以及控制并发执行的线程数量,从而提高系统的性能和资源利用率
简易解释:在应用程序启动时创建一定数量的线程,并将它们保存在线程池中。当需要执行任务时,从线程池中获取一个空闲的线程,将任务分配给该线程执行。当任务执行完毕后,线程将返回到线程池,可以被其他任务复用
线程池可以看作是海王的鱼塘,即使有女朋友的情况下,还会看一个喜欢一个并且直接出手,全是它鱼塘里的鱼,即使分手了,从鱼塘里取条鱼直接衔接上,此时效率嘎嘎高,体验拉满
为什么从线程池中取线程比创建线程的效率高?
因为从线程池中取线程,这个操作属于是完全用户态的操作
创建线程这个操作是属于用户态+内核态配合完成的操作,就像我们之前写的代码,创建一个线程都是通过系统调用API去创建线程的,之前又说过操作系统中包含一个重要的模块内核,其实就是通过内核去进行这一系列的操作
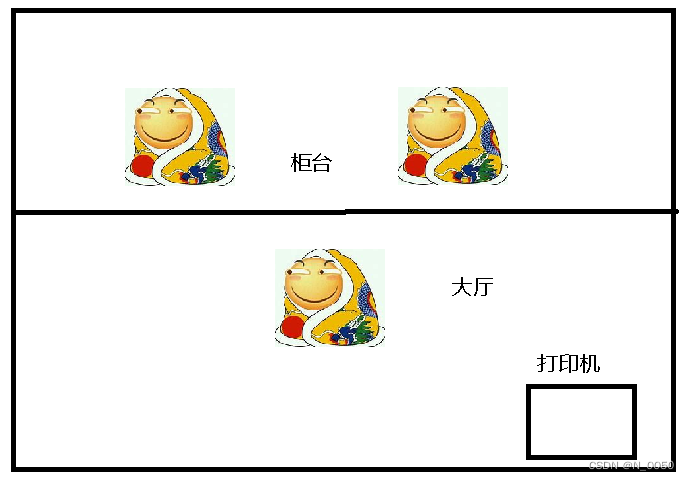
例子说明为什么是用户态+内核态配合完成的操作:比如说我们要去办理营业执照,身份证肯定要带上的吧以及其他的证明,然后你去大厅找柜台的人给你办理营业执照,这时候人家说需要什么什么的,但是还差个身份证复印件,你没有,人家跟你说要么你去大厅那个复印机打印,要么我来帮你打印。你自己去打印的过程这个过程就是从线程池中取线程,这个操作属于是完全用户态的操作,因为是你自己去打印的,打印完立马就回来接着办理。你让人家给你打印这里会涉及到内核态,人家不知道去哪给你打印,也不知道这个期间它会不会干其他事,还要等。就像是操作系统是给所有进程提供服务的,当你要创建线程的时候,它会帮你去创建但是呢它可能还会去干一些其他的事情,不可控。所以可以这样想你自己去打印机复印就相当于直接从线程池取线程,去柜台找人复印就相当于内核帮你去创建线程。
标准库中的线程池
线程池对象因为是接口所有不能直接创建,需要通过一个专门的方法,返回一个线程池对象,后面有详细讲解
ExecutorService service = Executors.newFixedThreadPool(3);工厂模式
我们创建一个对象是通过new关键字去实现的,new这个关键字又会触发构造方法从而实现。但是构造方法存在一定的局限性,什么局限呢?我们要创建多个构造方法的时候,会受到重载的约束,参数类型要不同或者参数个数不同
这时候我们可以通过工厂模式解决这个问题,单独搞一个类也就是工厂类,然后在这个类中搞些静态方法。通过一个static修饰的方法去代替构造方法完成初始化,只要把static修饰的方法名换一下,又可以代替一个不同的构造方法进行初始化,这样就不受重载的约束。由这样的静态方法负责构造出对象
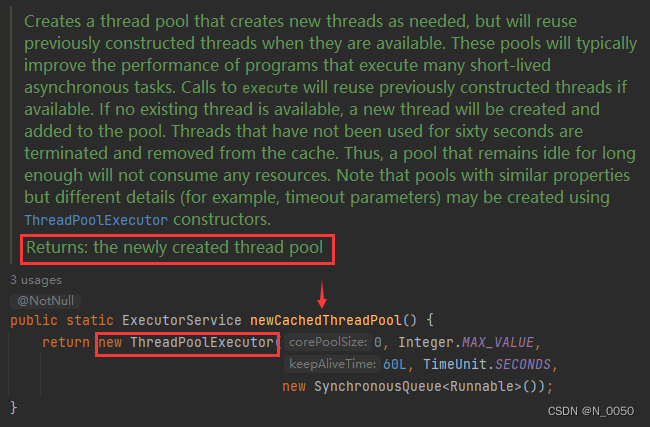
newCacheThreadPool方法
这个newCacheThreadPool方法,看这英文就可以读出创建一个缓存线程池对象,缓存这玩意之前就说过,这里缓存的意思就是对于用过的线程我们不着急销毁,先保留一段时间留着下次用。然后创建出这个对象,有个特点能动态适应,什么意思呢?就是根据你的任务自动给你创建出线程,就比如说你的任务涉及到三个线程要工作,线程池对象会根据你的任务所需,自动创建出线程,并且像前面说的创建出来不着急销毁,先保留一段时间,以备后续再使用
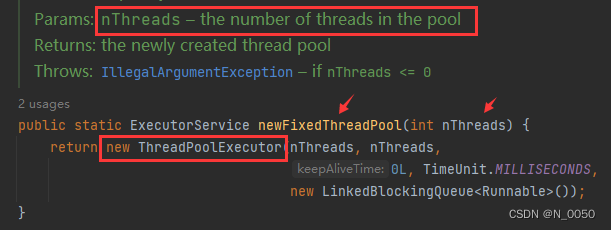
newFixedThreadPool方法
创建出线程数量固定的线程池
还有很多能创建出线程池对象的方法根据需求选择使用对应的线程池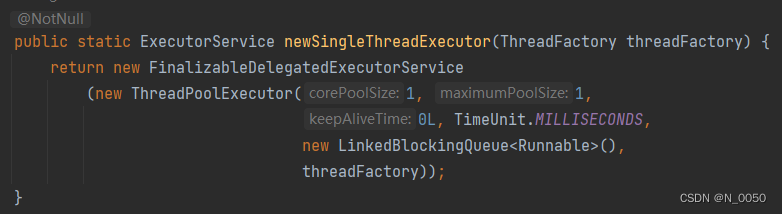

ThreadPoolExecutor类
上面的工厂方法生成的线程池,本质上都是对一个ThreadPoolExecutor类进行封装
,标准库的几个工厂方法就是给这个类提供了不同参数的构造方法来创建线程池
ThreadPoolExecutor这个类的核心就两个,一个构造线程池,然后在里面有submit方法接收用户传入的任务然后进行处理
public class Test {
public static void main(String[] args) {
//ExecutorService这是一个接口不能实例化 用到工厂模式 通过Executors类的方法去创建线程池对象ThreadPoolExecutor这个类又包含线程池的重要属性
//Executors这是一个类 这个方法能创建包含n个线程(不能说n是动态的)的线程池 返回值类型为 ExecutorService
ExecutorService service = Executors.newCachedThreadPool();
//通过 ExecutorService.submit 可以注册一个任务到线程池中
service.submit(new Runnable() {
//通过这个方法 把你要执行的任务添加到线程池中
@Override
public void run() {
System.out.println("我是线程池对象");
}
});
}
}可以看到创建线程池对象返回的是一个ExecutorService类型,这是一个接口,下面我把源码展示给你们看,就知道为什么了



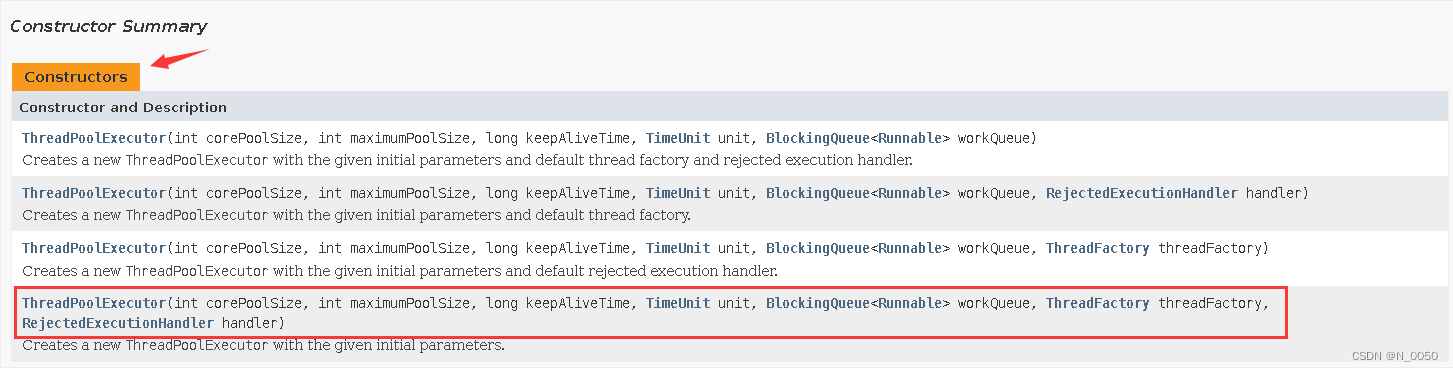
ThreadPoolExecutor的构造方法(重要)
ThreadPoolExecutor这个类的构造方法,最后一个构造方法涵盖所有的参数,我们围绕这个构造方法进行讲解,你也可以去官方文档看 https://docs.oracle.com/javase/8/docs/api/
线程数相关参数的解释
![]()
都是描述了线程的数目,corePoolSize是线程核心数目,maximmSize是线程最大数目,前面说了线程池里的线程数目是可以动态变化的,变化范围就是[线程核心数,线程最大数]
例子:可以把线程池理解为一个公司,我们都是公司的线程,但是有区别,正式员工是核心线程,有劳动法不会随便就被开除,实习生呢就是临时线程,随时都会被开除。正式员工的数目就是核心线程的数目,最大线程数目就是正式员工+实习生。这样设置就能避免公司忙不过来,并且开销也减少了,专业点说就是满足效率的同时降低了系统开销
补充:核心线程(正式员工)不会消失,然后如果丢进去的任务认为超过了核心线程数,他就会创造临时线程数(实习生),然后临时的用完等待一会就消失了
关于线程池线程数目设置(重要)
有个问题我们在使用线程池,线程数目设置多少比较合适?只要你说了一个具体数字,就是错的,因为没接触过项目代码之前我们无法进行确认
设cpu核心数(逻辑核心数)是N
一个线程执行的代码主要有以下两类:
1.cpu密集型:代码里主要的逻辑是进行算术运算和逻辑判断
如果一个线程执行的代码都是cpu密集型,那线程池的线程数量设置等于N的时候已经是极限了,所以不超过N。因为超过N也没有多的核心数来处理这些线程了,此时通过操作系统的调度执行这些线程到cpu上工作反而会降低效率,增加开销
2.IO密集型:代码里主要进行的是IO操作,读写硬盘、网络通信等操作
如果一个线程执行的代码都是IO密集型,这个时候不吃CPU,此时设置线程池的线程数量可以超过N,因为上面说的cpu会调度执行这些线程也就是并发执行
实际项目代码中不可能全是执行一类的代码,而是两类都有,所以正确的做法是对程序进行测试,根据设置不同的线程数目来判断哪个线程数目下程序的综合性更好,或者根据要求来选择
时间参数的解释
![]()
keepAliveTime就是描述你作为实习生可以在公司摸鱼的时间,unit就是描述你摸鱼时间的单位(ms,s,min)。专业点说数值加单位组成时间。这两个参数什么意思呢?就是公司的任务少了持续了好一段时间为了节省开销就把你裁掉了,专业点说就是当线程数大于corePoolSize时,多余的临时线程能等待新任务的最长时间。只有当线程池中的线程数超过核心线程数时,这个参数才会生效
阻塞队列参数的解释
![]()
阻塞队列存放任务的,也就是submit方法接收到的任务,存放到线程池中去进行处理,所以线程池中的任务是通过这个阻塞队列进行存储的。我们手动进行设置,也就是可以根据场景需求选择合适的队列,如果优先级优先采用PriorityBlockingQueue,如果任务数量比较固定采用ArrayBlockingQueue,如果任务数量不固定变化大用LinkedBlockingQueue
工厂类参数的解释
![]()
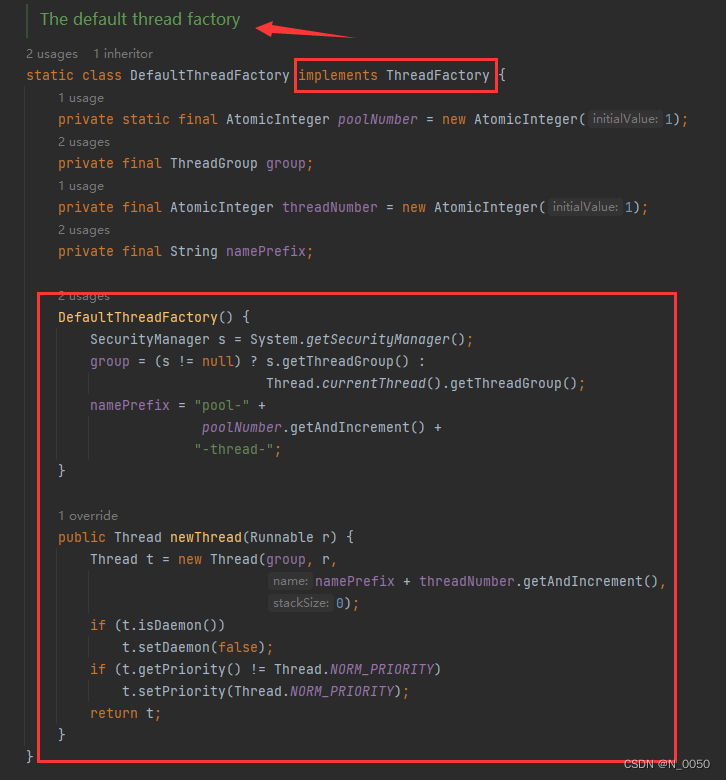
就是使用这个工厂类去创建线程,能省去手动设置线程的一些属性(例如name、守护线程等),直接用工厂方法进行封装。省的你自己创建线程设置那些属性
线程池的拒绝策略参数的解释(重要)
![]()
首先要知道线程池中能存放的任务是有限的,如果超出这个数量,继续添加会出现什么效果,就是由这个拒绝策略决定的,不同拒绝策略所展现的效果不一样,根据场景需求去选择对应的策略,下面有讲解,稍微会点英语就能知道什么意思了

ThreadPoolExecutor.AbortPolicy:这英文单词AbortPolicy的意思就是抛弃策略,超出能存放的任务数量,直接抛出异RejectedExecutionException
ThreadPoolExecutor.CallerRunsPolicy:这英文单词CallerRunsPolicy的意思就是调用者执行策略,超出能存放的任务数量,让添加新任务的这个线程执行
ThreadPoolExecutor.DiscardOldestPolicy:这英文单词DiscardOldestPolicy的意思就是丢掉最老策略,超出能存放的任务数量,丢掉队列中最老的任务
ThreadPoolExecutor.DiscardPolicy:这英文单词DiscardOldestPolicy的意思就是丢掉策略,超出能存放的任务数量,直接丢掉新添加的任务
手动模拟实现线程池
首先我们知道标准库线程池中有啥,有处理任务的线程,以及接收任务的submit方法,以及阻塞队列存放任务,下面是代码实现,简单模仿创建固定线程数目的线程池比较
class MyThreadPool {
BlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(100);//阻塞队列存储我们的任务
public MyThreadPool(int n) {
for (int i = 0; i < n; i++) {
Thread thread = new Thread(() -> {
try {
Runnable runnable = queue.take();
runnable.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
thread.start();
}
}
public void submit(Runnable runnable) throws InterruptedException {
//这里采用的拒绝策略 阻塞等待
queue.put(runnable);
}
}以上便是本章线程池的内容,内容不少好好消化,我们下一章再见💕