随着人工智能和机器学习技术的不断发展,OCR(Optical Character Recognition,光学字符识别)技术已经成为处理图像中文本信息的强大工具。TensorFlow是一个广泛使用的开源机器学习框架,它提供了丰富的API和工具,使得开发者能够轻松地构建和训练深度学习模型。本文将介绍如何使用TensorFlow进行OCR识别,特别是针对包含表格的图片,如病历、成绩单、答题卡等,将其中的文本信息识别并转换为结构化数据。
随着人工智能和机器学习技术的不断发展,OCR(Optical Character Recognition,光学字符识别)技术已经成为处理图像中文本信息的强大工具。TensorFlow是一个广泛使用的开源机器学习框架,它提供了丰富的API和工具,使得开发者能够轻松地构建和训练深度学习模型。本文将介绍如何使用TensorFlow进行OCR识别,特别是针对包含表格的图片,如病历、成绩单、答题卡等,将其中的文本信息识别并转换为结构化数据。
一、TensorFlow简介
TensorFlow是一个由Google开发的开源机器学习框架,它提供了丰富的API和工具,支持分布式训练,能够在不同平台上高效运行。TensorFlow的核心是一个高效的数值计算库,它允许开发者使用数据流图进行数值计算,这使得构建和训练深度学习模型变得更加容易和高效。
二、OCR识别技术概述
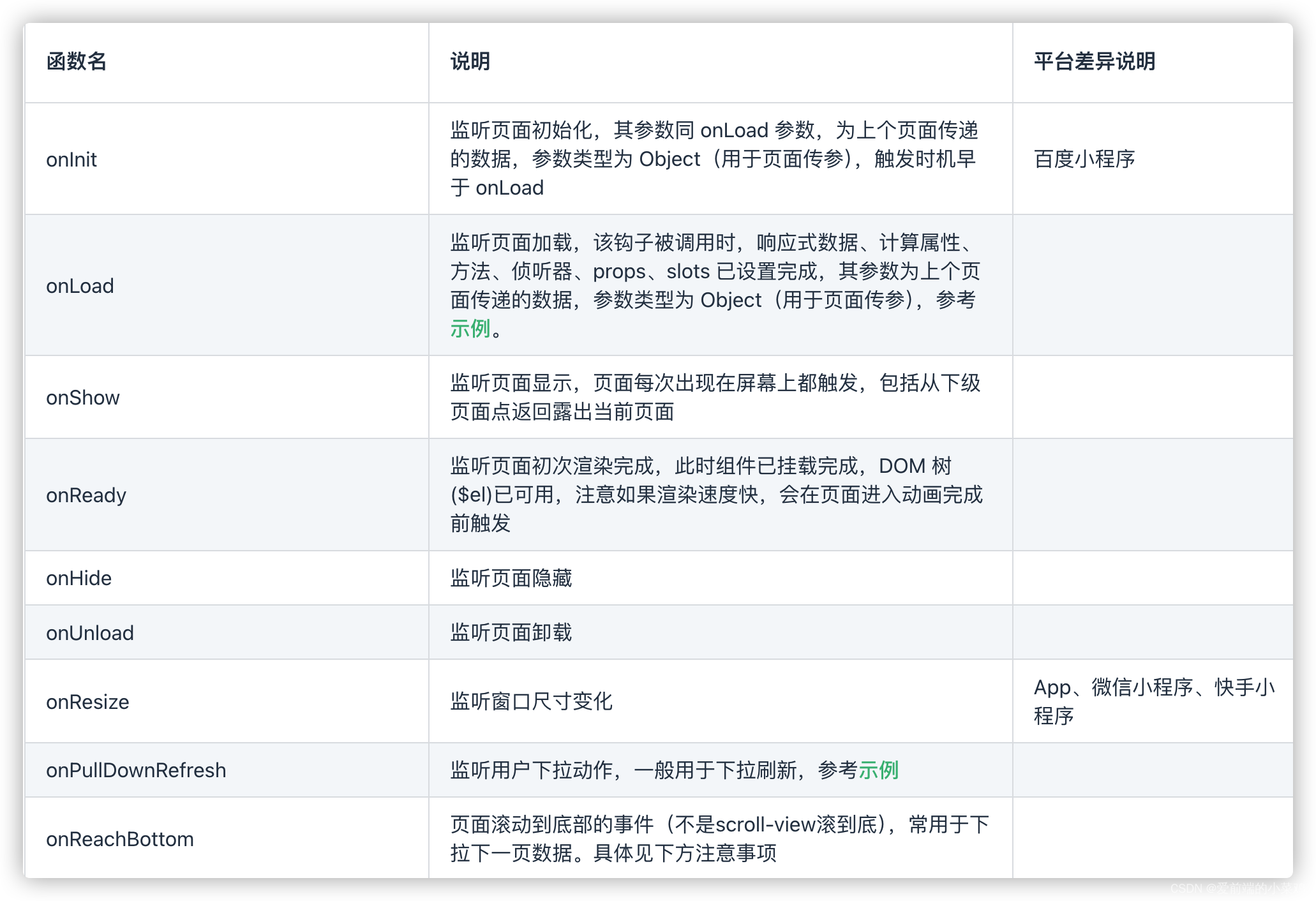
OCR技术是一种将图像中的文本信息转换为机器可编辑和检索的文本格式的技术。它通常包括图像预处理、文本检测、字符识别和文本后处理等步骤。在深度学习时代,基于卷积神经网络(CNN)和循环神经网络(RNN)的OCR模型已经取得了显著的识别效果。
三、使用TensorFlow进行OCR识别
虽然TensorFlow本身没有直接的OCR功能,但我们可以使用TensorFlow来构建和训练OCR模型。以下是一个基本的步骤指南:
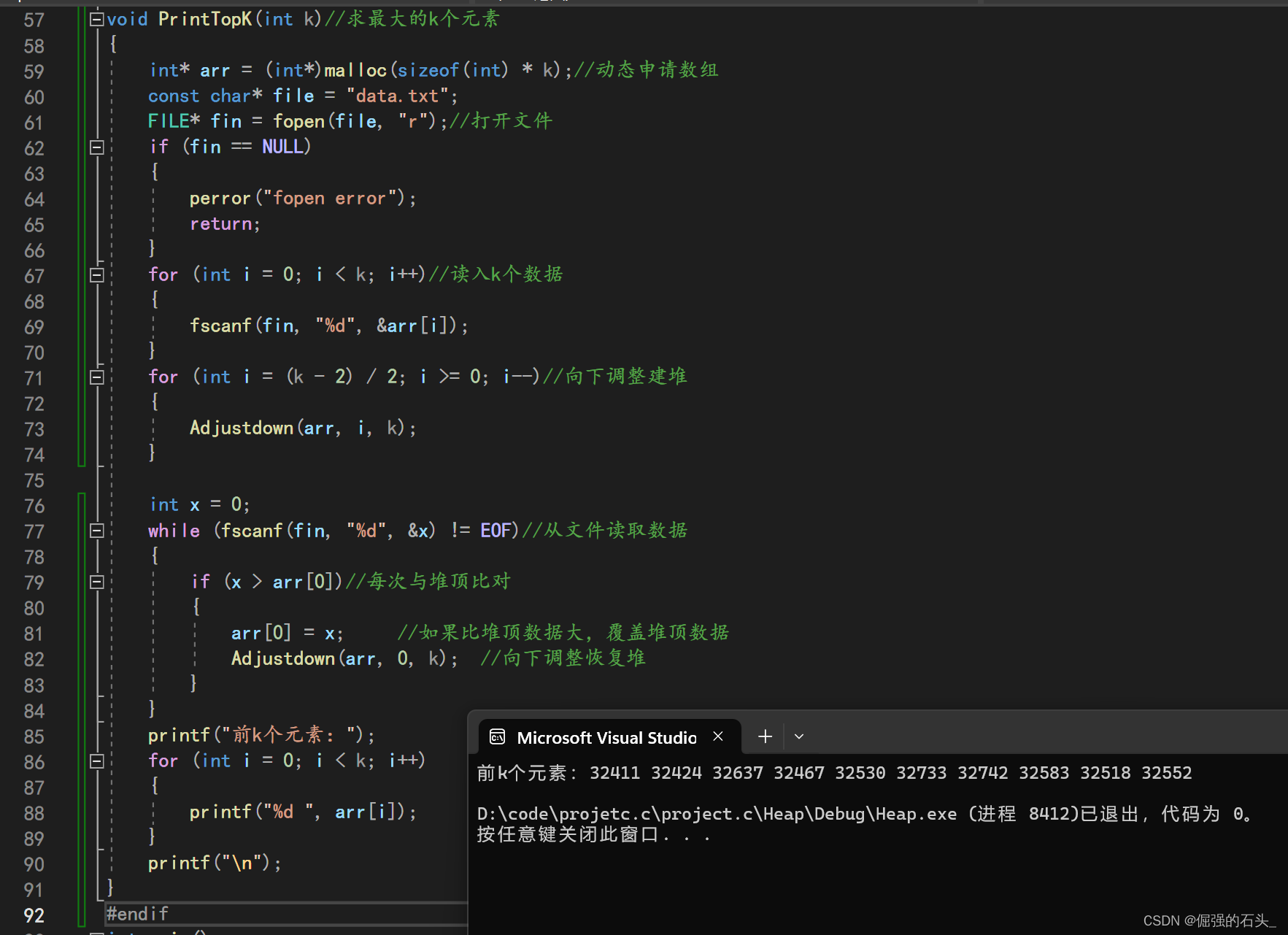
数据准备:收集并标注大量的表格图片数据,包括病历、成绩单、答题卡等。使用标注工具对图片中的文本进行标注,生成训练数据集。
模型选择:根据任务需求选择合适的OCR模型。常见的OCR模型包括基于CNN和RNN的CRNN模型、基于注意力机制的Transformer模型等。
模型训练:使用TensorFlow构建OCR模型,并使用标注好的训练数据集进行训练。通过调整模型参数和学习率等超参数,优化模型的识别效果。
文本后处理:对OCR模型的输出进行后处理,包括文本清洗、格式化、纠错等步骤。特别是对于表格图片,需要解析文本并映射到键值对形式,如将“症状:过敏性鼻炎”保存为{“症状”:“过敏性鼻炎”}。
结构化数据保存:将识别并后处理后的文本信息保存为结构化数据格式,如JSON或CSV文件。这使得后续的数据分析和处理变得更加方便和高效。

四、实际应用与挑战
将TensorFlow应用于OCR识别任务具有广泛的应用前景。例如,在医疗领域,可以自动识别病历中的文本信息,提高数据处理效率;在教育领域,可以自动识别成绩单和答题卡,减轻教师的工作负担。然而,实际应用中也面临着一些挑战,如表格结构的多样性、文本的复杂性和识别准确率等。
为了进一步提高OCR识别的效果和应用范围,我们可以采取以下措施:
扩大训练数据集:收集更多样化的表格图片数据,并进行标注,以提高模型的泛化能力。
优化模型结构:尝试不同的模型结构和超参数设置,以提高识别准确率和速度。
引入先验知识:利用领域先验知识对OCR模型进行约束和引导,提高识别效果。
后处理优化:开发更智能的文本后处理算法,提高结构化数据的准确性和可读性。
总之,使用TensorFlow进行OCR识别是一项具有挑战性的任务,但通过不断优化和改进模型和算法,我们可以将表格图片中的文本信息有效地转换为结构化数据,为各种应用场景提供有力的支持。