目 录
摘 要
Abstract
第1章 前 言
1.1 项目的背景和意义
1.2 研究现状
1.3 项目的目标和范围
1.4 论文结构简介
第2章 技术与原理
2.1 开发原理
2.2 开发工具
2.3 关键技术
第3章 需求建模
3.1 系统可行性分析
3.2 功能需求分析
3.3 非功能性需求
第4章 系统总体设计
4.1 系统总体目标
4.2 系统架构设计
4.3 数据库设计
第5章 系统详细设计与实现
5.1 实现系统功能所采用技术
5.2 用户模块设计
5.3 自媒体人模块设计
5.4 后台管理员模块设计
第6章 系统测试与部署
6.1 测试内容
6.2 测试报告
6.3 系统运行
第7章 结论
7.1 总结
7.2 展望
参考文献
致 谢
股票分析与推荐系统设计与实现
摘 要
推动大数据技术在金融领域的应用:随着大数据技术的发展,基于Hadoop和Spark的大数据平台在各个行业得到了广泛应用。然而,在金融领域,特别是在股票市场,这些技术的应用还相对较少[1]。通过本课题的研究,可以进一步推动大数据技术在金融领域的应用,提高股票市场的效率和准确性。
构建高效的股票分析与推荐系统:传统的股票分析方法主要依赖于人工分析和专家的经验。这种方法在处理大量数据时往往效率低下,且容易受到人为因素的影响。通过本课题的研究,可以构建高效的股票分析与推荐系统,提高股票分析的效率和准确性,同时降低人为因素的影响[2]。
扩展机器学习和深度学习在金融领域的应用:机器学习和深度学习是当前人工智能领域的重要分支,其在金融领域的应用也得到了广泛的关注[3]。本课题将探讨如何利用机器学习和深度学习技术对股票数据进行挖掘和分析,进一步扩展这些技术在金融领域的应用。
促进混合计算模型的研究与发展:本课题将研究如何将Hadoop和Spark两种不同的计算模型进行有效的结合,以实现优势互补。这将为混合计算模型在金融领域的应用提供新的思路和方法,同时也将促进混合计算模型的研究与发展。
本系统采用了Pandas+numpy、Hadoop+Mapreduce、Hive_sql、Springboot+Vue.js、MySQl等技术栈进行开发构建,具有良好的扩展性和并发性。同时,系统还使用了Sqoop将分析结果导入MySQL数据库,使用Flask+echarts搭建可视化大屏界面,用Springboot+vue.js搭建web系统,实现智能推荐、股票预测、情感分析、知识图谱等业务功能。
关键词:股票分析与推荐系统;大数据;Pandas+numpy;Hadoop+Mapreduce;Springboot+Vue.js;;MySQL;
Stock analysis and recommendation system design and implementation
Abstract
Promoting the application of big data technology in the financial field: With the development of big data technology, big data platforms based on Hadoop and Spark have been widely used in various industries. However, in the financial field, especially in the stock market, these technologies are relatively small. Through the research of this project, the application of big data technology in the financial field can be further promoted, and the efficiency and accuracy of the stock market can be improved.
Establish an efficient stock analysis and recommendation system: Traditional stock analysis methods mainly depend on artificial analysis and expert experience. This method is often inefficient when processing a large amount of data and is easily affected by human factors. Through the research of this project, you can build an efficient stock analysis and recommendation system, improve the efficiency and accuracy of stock analysis, and reduce the impact of human factors.
The application of extended machine learning and deep learning in the financial field: Machine learning and deep learning are important branches in the current field of artificial intelligence, and their applications in the financial field have also received widespread attention. This topic will explore how to use machine learning and deep learning technology to dig and analyze stock data, and further expand the application of these technologies in the financial field.
第1章 前 言
1.1 项目的背景和意义
随着信息技术的飞速发展和全球金融市场的日益繁荣,股票投资已成为广大投资者的重要选择之一。然而,股票市场的复杂性和不确定性使得投资者在做出投资决策时面临巨大的挑战。传统的股票分析方法往往依赖于人工收集、整理和分析大量的市场数据,这不仅效率低下,而且难以准确捕捉市场的细微变化。因此,利用大数据技术构建一个高效、准确的股票分析与推荐系统,对于提高投资者的投资效率、降低投资风险具有重要意义。
近年来,大数据技术的快速发展为股票分析与推荐系统的构建提供了强有力的技术支持。通过收集、整合和分析来自多个渠道的股票市场数据,大数据技术可以揭示市场的内在规律和趋势,为投资者提供有价值的投资参考。同时,随着人工智能、机器学习等技术的不断进步,股票分析与推荐系统的智能化水平也在不断提高,能够更准确地预测市场走势,为投资者提供更加精准的投资建议。
项目可以提高投资效率:股票分析与推荐大数据系统能够自动收集、整理和分析市场数据,为投资者提供实时的股票信息和分析报告。投资者可以通过系统快速了解市场动态、公司财务状况等信息,从而更加高效地做出投资决策。降低投资风险:系统利用大数据技术和人工智能算法对市场进行深度分析,能够揭示市场的内在规律和趋势,为投资者提供准确的投资建议。这有助于投资者规避潜在的风险因素,降低投资风险。推动金融科技发展:股票分析与推荐大数据系统的构建需要综合运用大数据、人工智能、机器学习等多种技术手段。该项目的实施将推动金融科技领域的创新和发展,为金融行业的数字化转型提供有力支持。促进经济发展:股票市场的稳定健康发展对于国家经济的繁荣具有重要意义。股票分析与推荐大数据系统能够为投资者提供更加精准的投资建议,有助于提高投资者的投资效率和信心,从而促进股票市场的稳定健康发展,为经济发展注入强劲动力。
1.2 研究现状
在数据采集方面,现代股票分析与推荐大数据系统能够自动从多个渠道获取包括历史交易数据、新闻报道、公司财务报告等在内的海量信息。这些数据的准确性和完整性对于后续的分析和推荐至关重要。在数据处理方面,系统运用数据清洗、标准化和特征提取等技术,将原始数据转换为可用于模型训练的数值型向量。
在分析与推荐算法方面,股票分析与推荐大数据系统主要采用了机器学习、深度学习等先进技术。这些算法通过对历史数据的学习和训练,能够揭示市场的内在规律和趋势,为投资者提供有价值的投资建议。具体来说,系统可以采用基于监督学习的分类和回归算法,预测股票价格的涨跌趋势和具体数值;采用基于无监督学习的聚类算法,发现具有相似特征的股票群体;采用深度学习算法,自动提取市场数据中的关键特征,提高分析和推荐的准确性。
1.3 项目的目标和范围
本项目旨在构建一个高效、准确、智能的股票分析和推荐大数据系统,以满足投资者在股票投资过程中的多元化需求。具体目标包括:
(1)提供全面数据支持:系统能够收集、整合来自多个渠道的股票市场数据,包括历史交易数据、新闻资讯、公司财务报告等,为投资者提供全面、丰富的信息支持。
(2)实现智能分析:通过运用先进的数据挖掘和机器学习算法,系统能够自动分析市场数据,揭示市场的内在规律和趋势,为投资者提供有价值的投资参考。基于投资者的风险偏好、投资目标和历史投资行为,系统能够生成个性化的股票推荐列表,帮助投资者快速筛选出符合其需求的投资标的。
(3)提高投资效率:通过自动化和智能化的分析与推荐流程,系统能够大大缩短投资者的投资决策时间,提高投资效率。通过为投资者提供准确、及时的投资建议,系统有助于引导市场资金的合理流动,促进股票市场的稳定健康发展。
本项目的范围涵盖了从数据收集、处理、分析到推荐的全过程,具体包括以下几个方面:
(1)据源管理:系统需要定义和管理从多个渠道获取的数据源,包括证券交易所、财经媒体、公司官方网站等,确保数据的准确性和完整性。
(2)数据处理:系统需要对原始数据进行清洗、标准化和特征提取等处理,以提高数据的质量和可用性。同时,系统还需要支持流式处理,实现对市场数据的实时更新和分析。
(3)分析与推荐算法:系统需要实现多种先进的股票分析和推荐算法,包括基于监督学习的分类和回归算法、基于无监督学习的聚类算法以及深度学习算法等。这些算法需要能够准确地预测股票价格的涨跌趋势和具体数值,并为投资者提供个性化的投资建议。
(4)用户界面设计:系统需要设计直观、易用的用户界面,方便投资者查看市场数据、分析结果和推荐列表。同时,系统还需要支持多种终端设备的访问,如电脑、手机和平板电脑等。
(5)系统测试与维护:在项目开发过程中,需要进行全面的系统测试,确保系统的稳定性和可靠性。在项目上线后,还需要进行持续的维护和更新,以适应市场变化和投资者需求的变化。
1.4 论文结构简介
本论文主要研究校园新闻发布系统的架构设计与具体实现问题,主要包含前沿、技术与原理、需求建模、系统总体设计、系统详细设计与实现、系统测试与部署和总结和展望这几个部分。通过从零到一,从无到有,从底层到具体实现,描述项目的构建过程。
第2章 技术与原理
2.1 开发原理
本系统利用Hadoop和Hive对股票数据进行深入分析和可视化,为投资者提供更加准确、全面的决策支持。本研究的成果将有助于提高投资者的决策效率和准确性,同时为金融领域的大数据应用提供新的思路和方法。本研究将采用以下步骤进行:
1、数据采集:收集股票市场的历史数据和实时数据,包括股票价格、成交量、财务指标等。
2、门户系统:首页股票信息展示;股票推荐(根据协同过滤基于用户、物品、SVD神经网络、MLP模型);股票K线预测(CNN卷积神经预测 );股票信息详情(股票代码,涨跌幅度,成交量,成交额,换手率,股票市值); 支付宝购买股票;订单管理;股票信息评论(lstm情感分析模型)。
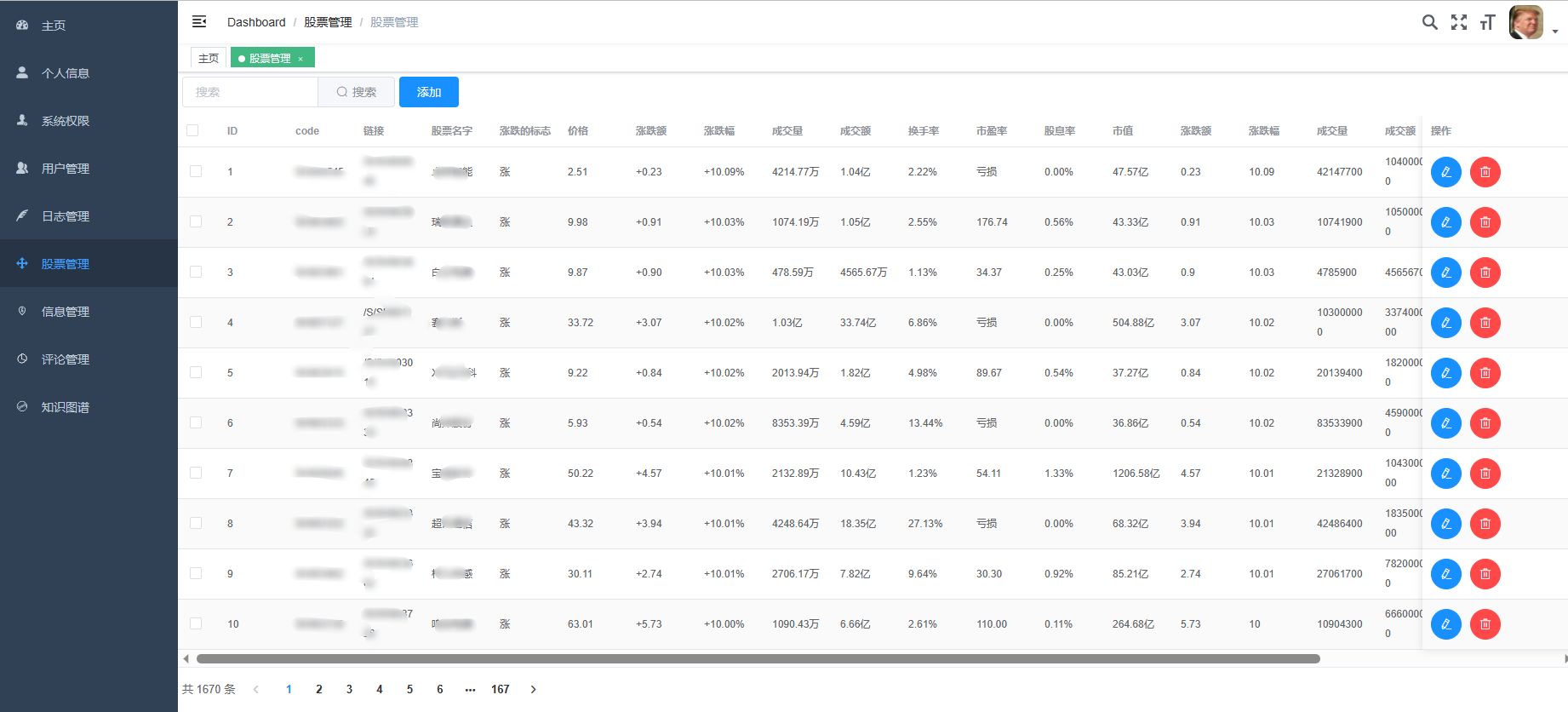
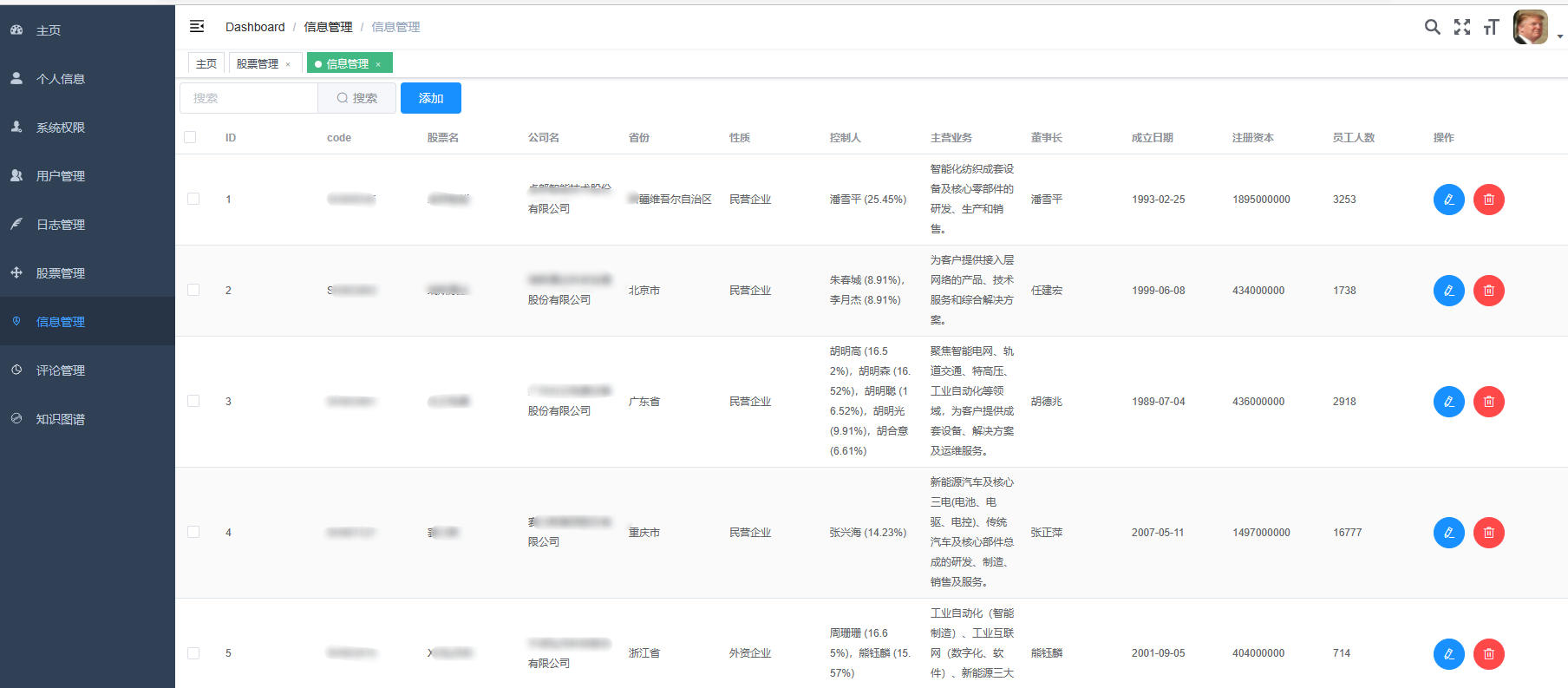
3、后台管理系统:个人信息管理;系统管理;用户管理;股票信息管理;评论信息管理;知识图谱。
2.2 开发工具
2.2.1 Pandas
Pandas是Python语言的一个扩展程序库,主要用于数据分析。它最初由AQR Capital Management于2008年4月开发,并在2009年底作为开源项目发布,之后由PyData开发团队继续开发和维护。Pandas的名称来源于“panel data”(面板数据)和“Python data analysis”(Python数据分析),这体现了其作为数据分析工具的核心价值。
Pandas提供了高性能、易于使用的数据结构和数据分析工具,这些工具基于高性能数学运算库Numpy,能够支持从各种文件格式如CSV、JSON、SQL和Excel等导入数据。Pandas的主要特点包括功能强大、兼容性强和处理速度快。
Pandas的一些常见使用场景包括:
数据整理和清洗:Pandas可以将不同的数据源整理成一张表格,方便数据的整合和清洗。它支持缺失值的处理、数据类型的转换、重复数据的删除、不一致数据的纠正等。
数据探索性分析:Pandas可以用于数据的探索性分析,它可以给出数据的一些基本统计信息,如平均数、中位数、标准差、最大值、最小值等。同时,Pandas还可以绘制数据的各种图表,如直方图、散点图、折线图等,方便数据可视化。
数据建模和分析:Pandas可以用于数据建模和分析,它可以将数据集中的一些变量作为自变量,另一些变量作为因变量,进行各种建模和分析。Pandas支持线性回归、逻辑回归、决策树、聚类等各种模型。
2.2.2 Numpy
NumPy(Numerical Python)是Python的一个开源数值计算扩展库,也是Python科学计算的基础软件包。它提供了强大的N维数组对象、精密的广播功能函数、线性代数、傅里叶变换和随机数生成等功能。NumPy的主要特点包括:
多维数组对象:NumPy引入了多维数组对象(称为numpy.ndarray或简称为数组),允许在单个数据结构中存储和操作多维数据,如向量、矩阵和张量。这使得NumPy在处理大型矩阵和进行复杂数学运算时非常高效。
高效的数值运算:NumPy的底层实现是用C语言编写的,因此它能够执行高效的数值计算。此外,由于ndarray中的所有元素类型相同,数据在内存中是连续存储的,这进一步提高了批量操作数组元素的速度。
丰富的数学函数库:NumPy包含了大量的数学函数,用于执行各种数值计算,如三角函数、指数函数、对数函数等。此外,它还提供了线性代数操作的函数,如矩阵乘法、特征值分解、奇异值分解等,使其成为数值线性代数的强大工具。
强大的索引和切片功能:NumPy提供了丰富的索引和切片功能,允许用户高效地访问和操作数组的元素。这使得在处理大型数据集时能够快速地提取所需信息。
互操作性:NumPy与其他常用的科学计算库(如SciPy、pandas和Matplotlib)紧密集成,使得在不同库之间传递数据变得非常容易。这使得NumPy在数据科学、机器学习、图像处理等领域得到了广泛应用。
NumPy的主要用途包括:
矩阵运算:NumPy提供了各种矩阵运算功能,如矩阵乘法、转置和分解等,方便进行矩阵运算。
存储和处理大型矩阵:NumPy可以用来存储和处理大型矩阵,并能够高效地进行矩阵运算。
数组操作:NumPy的核心功能是ndarray对象,它是一个多维数组,可以进行快速的数值计算和数组操作。
数值计算:NumPy提供了大量的数学函数,包括线性代数、傅里叶变换、随机数生成等。
数据处理:NumPy可以方便地处理和操作多维数组,可以对数据进行排序、去重、筛选、统计等操作。
科学计算:NumPy广泛应用于科学计算领域,如物理学、生物学、化学、地理学等。
2.2.2 Springboot
Spring Boot是一个基于Spring框架的开源框架,旨在简化新Spring应用的初始搭建以及开发过程。
Pivotal团队于2013年开始研发Spring Boot,并在2014年4月发布了全新开源的轻量级框架的第一个版本。Spring Boot通过自动化配置(Auto-configuration)的机制,根据项目中引入的依赖和约定,自动配置应用程序中的各种组件和功能。这减少了开发人员手动编写大量XML或注解配置的工作量,降低了出错的可能性。
Spring Boot提供了强大的插件体系和广泛的集成,可以轻松地与其他技术栈集成,如Thymeleaf模板、JPA、MyBatis、Redis、MongoDB等,同时也支持对微服务的开发和管理.Spring Boot在项目中的主要用途包括快速开发、自动配置、内嵌服务器和监控与管理。它大大简化了Spring应用程序的开发和部署过程,使开发人员可以更加专注于业务逻辑的实现。
2.2.2 虚拟机
VirtualBox:VirtualBox是一款由Oracle开发和维护的免费开源虚拟化软件。它允许用户在单个物理计算机上运行多个操作系统,如Windows、Linux、macOS等。VirtualBox提供了一个完整的虚拟化环境,包括虚拟机配置、启动、关闭、快照、网络设置等功能。
VMware Workstation/Fusion:VMware是全球最知名的虚拟化企业之一,其Workstation和Fusion产品分别针对PC和Mac用户提供虚拟化解决方案。这些产品支持广泛的操作系统,并提供强大的虚拟机管理功能,如虚拟机克隆、快照、网络设置等。VMware Fusion还特别针对Mac用户提供了Unity View模式,使得不同操作系统界面之间无缝衔接。
oVirt:oVirt是一款开源虚拟化管理平台,专注于管理大规模虚拟化数据中心。它作为红帽企业虚拟化(RHEV)的核心组件起步,现已发展成为一个独立、功能齐全的虚拟化管理解决方案。oVirt强调可扩展性、稳定性和与其他开源工具的集成,为经济高效且功能强大的虚拟化管理平台提供了理想选择。
QEMU:QEMU是一个快速、可移植的开源机器模拟器和虚拟化器。它可以模拟多种处理器架构,并在多种主机操作系统上运行。QEMU支持广泛的设备模拟和操作系统,为用户提供了强大的虚拟机模拟和虚拟化能力。
KVM(Kernel-based Virtual Machine):KVM是一种基于Linux内核的虚拟化技术。它将Linux内核转换为虚拟机监控器(Hypervisor),使得用户可以在Linux系统上直接运行虚拟机。KVM与QEMU结合使用,提供了强大的虚拟机管理和性能优化功能。
Parallels Desktop:Parallels Desktop是一款专为Mac用户设计的虚拟化软件。它允许用户在Mac计算机上同时运行多个操作系统,如Windows、Linux等。Parallels Desktop提供了卓越的虚拟化技术,确保流畅稳定的运行,并支持多种特色功能,如共享打印、TouchID集成等。
2.3 关键技术
2.3.1 Hdoop+Mapreduce
HDFS(Hadoop Distributed File System):HDFS是Hadoop的分布式文件系统,用于存储大数据集。它是Hadoop生态系统中的核心项目之一,是分布式计算中数据存储管理的基础。HDFS将数据分散存储在一组计算机上,形成分布式存储,具有高容错性、高吞吐量的特点,适合存储大规模数据集。
MapReduce:MapReduce是一种编程模型,用于处理大规模数据集(大于1TB)。MapReduce将复杂的运行于大规模集群上的并行计算过程高度地抽象为了两个函数:Map和Reduce。Map阶段将输入数据划分为多个数据块,并对每个数据块进行独立处理,产生一系列中间结果;Reduce阶段则将具有相同键的中间结果合并,得到最终结果。MapReduce提供了高效的数据处理框架,能够自动处理数据的划分、调度、执行和结果收集等过程。
YARN(Yet Another Resource Negotiator):YARN是Hadoop 2.0中的资源管理器,用于管理Hadoop集群中的计算资源。YARN的主要功能是跟踪集群中的资源使用情况,协调和监控运行在集群上的应用程序。YARN将JobTracker的两个主要功能(资源管理和作业调度/监控)分离成单独的组件,从而提高了集群的可靠性和可扩展性。
HBase:HBase是一个分布式的、面向列的开源数据库,可以认为是HDFS的封装,本质是数据存储、NoSQL数据库。HBase适用于非结构化数据存储的场合,在需要实时读写、随机访问超大规模数据集时,表现得尤为出色。
Sqoop:Sqoop是一款开源的数据导入导出工具,主要用于在Hadoop与传统的数据库间进行数据的转化。Sqoop通过JDBC/ODBC连接数据库,将数据库中的数据导入到HDFS中,或将HDFS中的数据导出到数据库中。
2.3.2 Hive
在大数据领域,Hive是一个非常重要的工具,它基于Hadoop构建,主要用于数据仓库的存储、查询和分析。以下是Hive的主要特点和功能:
数据仓库角色:Hive可以存储和管理大规模的结构化和半结构化数据。它使用分布式文件系统(如HDFS)来存储数据,并提供了对底层存储系统的抽象,使得用户可以快速查询和分析存储在Hadoop集群中的数据。
查询引擎角色:Hive提供了类似于SQL的查询语言(HiveQL),使得用户可以用熟悉的SQL语法来查询和分析数据。Hive将HiveQL查询转换为MapReduce作业来执行,利用Hadoop集群的并行处理能力进行高效的数据处理。通过这种方式,Hive使得用户可以轻松地进行复杂的计算和分析操作。
数据存储:Hive可以将大量结构化和半结构化数据存储在Hadoop分布式文件系统中,以便后续查询和分析。
数据查询和分析:Hive支持类SQL语言的查询操作,用户可以使用HiveQL语言编写查询,并进行数据分析和统计。Hive可以对存储在数据仓库中的数据进行复杂的数据分析操作,如聚合、排序、连接等。
数据管理:Hive提供了数据仓库的管理功能,包括数据表的创建、删除、修改以及数据权限管理等功能。
数据导入导出:Hive支持将数据从其他数据源导入到数据仓库中,也可以将数据从数据仓库导出到其他系统中使用。
报表生成和可视化展示:Hive提供了丰富的报表生成功能,可以帮助企业快速生成各种报表以监控业务运行情况。同时,Hive还可以将数据分析结果进行可视化展示,如图表、图像等,以便用户更好地理解和使用数据。
2.3.3 Flask
Flask是一个轻量级的Web开发框架,它使用Python编写,具有简洁、灵活和易于扩展的特点。这使得Flask成为开发小型到中型Web应用程序的理想选择,特别是在大数据环境中,当需要快速构建和部署Web服务以支持数据处理、分析和可视化时。
Flask框架与各种数据可视化库(如Plotly、Pyecharts等)结合使用,可以轻松地创建交互式图表和可视化效果。通过Flask的后端处理,可以将数据转换为可视化图表,并通过Web界面展示给用户。这使得大数据分析师和开发人员能够更直观地理解和分析数据。Flask也常用于开发RESTful API,这些API可以用于在Web应用程序、移动应用程序或其他客户端之间传输数据。在大数据环境中,API可以用于从数据源获取数据、处理数据并将结果返回给客户端。Flask的轻量级和灵活性使其成为开发高效、可扩展的API的理想选择。
在大数据项目中,Flask常用于实现前后端分离的开发模式。后端使用Flask框架处理数据请求和响应,而前端则使用JavaScript、HTML和CSS等技术构建用户界面。这种开发模式可以提高开发效率,降低维护成本,并使得前后端开发人员可以独立工作。Flask具有良好的可扩展性,支持第三方插件和扩展。这些插件和扩展可以扩展Flask的功能,满足大数据项目中的各种需求。例如,可以使用Flask-SQLAlchemy扩展来简化数据库操作,使用Flask-Login扩展来实现用户认证和授权等。
2.3.4 Echarts
ECharts在大数据中的作用主要体现在数据可视化方面。它是一个使用JavaScript编写的开源可视化库,可以在浏览器中生成高质量的图表和图形,帮助用户更直观地理解和分析大数据。
以下是ECharts在大数据中的一些主要作用:
ECharts支持多种图表类型,包括折线图、柱状图、饼图、散点图、地图等,几乎涵盖了所有常见的数据可视化需求。这使得用户可以根据数据的特点和需要选择合适的图表类型,以更直观的方式展示数据。
ECharts支持多维数据的可视化,例如对于传统的散点图等,传入的数据也可以是多个维度的。这使得用户可以在同一图表中展示多个维度的数据,更全面地了解数据的特征和关系。
ECharts提供了丰富的交互功能,用户可以通过鼠标、键盘等设备与图表进行交互,例如缩放、拖拽、选择等。这些交互功能使得用户可以更深入地探索和分析数据,发现其中的规律和趋势。
ECharts允许用户自定义图表的样式和行为,包括颜色、字体、标签、动画等。这使得用户可以根据需要定制出符合自己品牌或主题的图表,提高图表的个性化和专业化程度。
ECharts可以在PC和移动设备上流畅运行,并且对移动端进行了优化,确保在不同设备上都有良好的展示效果。这使得用户可以在各种设备上查看和分析数据,提高数据的可访问性和便利性。
2.3.4 MySQL
MySQL是当下最受欢迎的持久化解决方案。其具有高性能:它的性能非常出色,可以支持高并发的访问请求。可扩展性:它可以通过多种方式进行扩展,包括分库分表、主从复制等方式。安全性:它提供了多种安全性措施,可以保护用户的数据安全。简单易用:经过一到两天的学习基本就能掌握其语法。
第3章 需求建模
3.1 系统可行性分析
3.1.1 技术可行性
技术可行性主要关注项目所需的技术和资源是否具备。对于股票分析和推荐大数据系统,技术可行性包括数据采集、存储、处理和分析的能力,以及系统架构的稳定性和可扩展性。目前,大数据技术和机器学习算法已经相对成熟,为项目的实施提供了坚实的技术基础。同时,云计算和分布式存储技术的发展也为系统提供了强大的计算和存储能力。
3.1.2 经济可行性
经济可行性主要关注项目的投资回报和经济效益。对于股票分析和推荐大数据系统,经济可行性需要考虑项目的开发成本、运营成本以及潜在的市场收益。虽然系统的开发和运营需要一定的投入,但考虑到其能够为投资者提供有价值的投资建议,从而增加其投资收益,因此项目具有良好的经济效益和市场前景。
3.1.3 社会可行性
社会可行性主要关注项目对社会的影响和接受程度。股票分析和推荐大数据系统旨在提高投资者的投资效率和收益,对于推动金融市场的发展和稳定具有积极意义。同时,该系统也有助于提升大数据技术在金融领域的应用水平和普及程度,促进相关产业的发展。因此,项目在社会层面上是可行的。
3.1.4 操作可行性
操作可行性主要关注系统的易用性和可维护性。股票分析和推荐大数据系统需要面向广大投资者,因此系统需要具备良好的用户界面和交互体验,以便用户能够轻松地使用系统并获取所需的投资建议。同时,系统还需要具备可维护性,以便在出现问题时能够迅速修复和升级。
3.2 功能需求分析
3.2.1 功能概述
1、数据采集与整合:系统能够实时从多个数据源(如证券交易所、财经新闻网站、社交媒体等)采集股票相关的数据,包括股票价格、交易量、基本面数据、新闻事件等。能够对采集到的数据进行清洗、去重、标准化等预处理操作,确保数据的质量和准确性。能够将处理后的数据整合到统一的数据库中,方便后续的分析和挖掘。
2、数据分析与挖掘:系统利用先进的数据分析技术和机器学习算法,对股票数据进行深入的分析和挖掘,识别出市场的趋势、规律和异常现象。可以构建各种预测模型,如股票价格预测模型、市场走势预测模型等,为投资者提供科学的投资建议。系统还能够对投资者的投资组合进行风险评估和优化,帮助投资者实现资产的合理配置。
3、用户登录模块:用户身份验证:用户登录模块通过验证用户输入的用户名和密码(或其他身份验证方式,如指纹识别、面部识别等)来确认用户的身份。只有经过验证的用户才能访问系统。权限控制:用户登录模块还可以与系统的权限管理系统集成,以根据用户的角色和权限控制他们对系统功能和数据的访问。这可以确保敏感数据和功能只能被授权用户访问。
4、个性化推荐:系统能够根据投资者的投资偏好、风险承受能力等个性化因素,为投资者提供定制化的投资建议和推荐股票。投资者可以通过系统设定自己的投资目标和约束条件,系统会根据这些条件为投资者生成相应的投资策略和推荐股票列表。
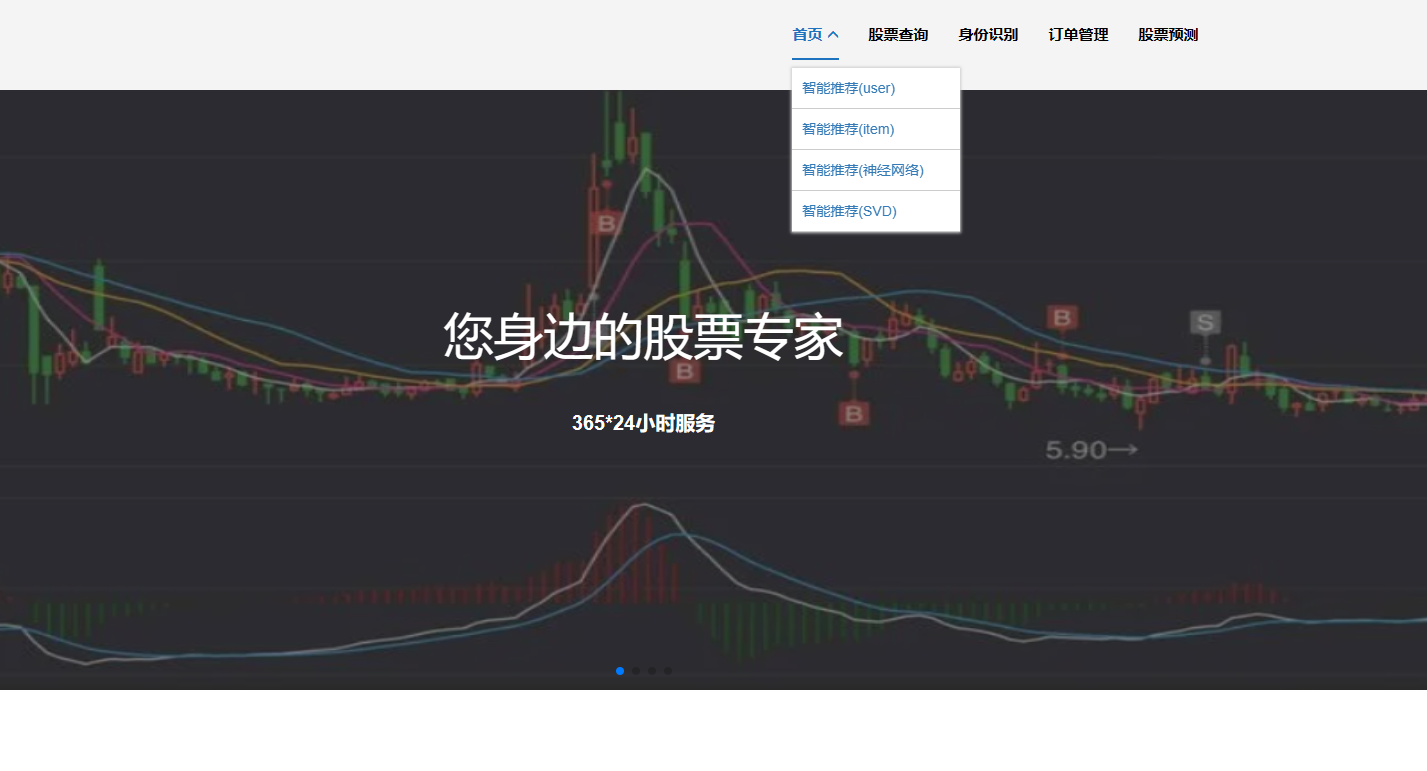
5、基于用户的协同过滤推荐:使用了基于用户的协同过滤算法(User-based Collaborative Filtering,简称UserCF):这种算法的核心思想是给用户推荐和他兴趣相似的其他用户喜欢的产品。它首先找出与目标用户兴趣相似的其他用户,然后根据这些相似用户的喜好来为目标用户推荐产品。
6、基于物品的协同过滤推荐:使用了基于物品的协同过滤算法(Item-based Collaborative Filtering,简称ItemCF):这种算法则是通过分析物品之间的相似性,来预测用户评分行为并进行推荐。它首先找出与目标用户之前喜欢的物品相似的其他物品,然后将这些相似物品推荐给目标用户。
7、SVD混合神经网络推荐模块:SVD混合神经网络推荐是一种结合了奇异值分解(SVD)和神经网络技术的推荐系统方法。这种方法旨在通过SVD来降低数据的维度和复杂度,同时利用神经网络的非线性处理能力来捕捉用户与物品之间的复杂关系,从而提供更准确和个性化的推荐。
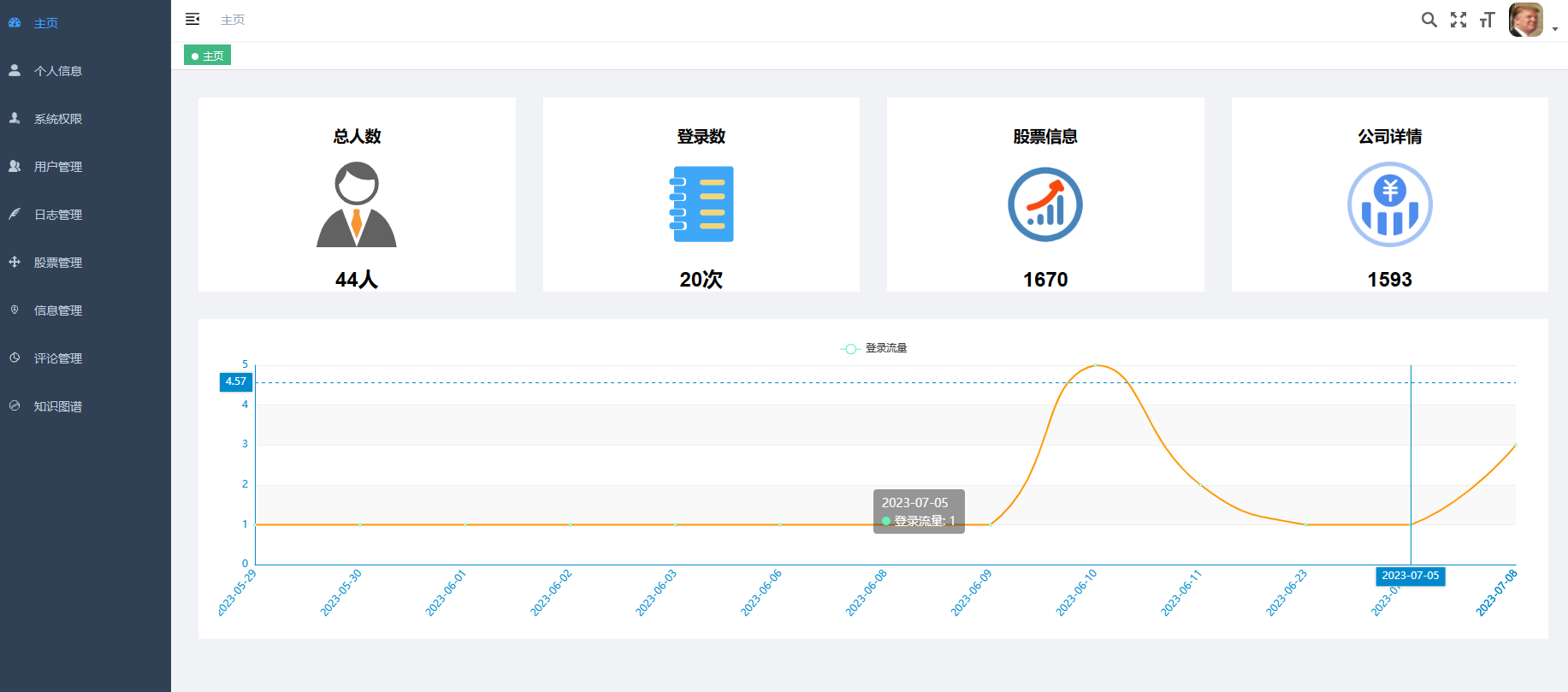
8、大屏数据实时可视化展示模块:系统提供直观、易懂的图表和界面,将分析结果以可视化的形式展示给投资者,方便他们快速理解市场情况和投资建议。投资者可以通过系统查看股票的实时行情、历史走势、基本面数据等详细信息,以便做出更明智的投资决策。
9.虚拟机模块:虚拟机能够在同一物理硬件上运行多个操作系统,实现了硬件资源的复用。每个虚拟机都是独立的,相互之间完全隔离,这使得一个虚拟机的崩溃不会影响其他虚拟机或物理机。虚拟机提供硬件隔离、资源复用、节省成本、简化管理、提高灵活性、增强安全性、支持多种操作系统和应用以及快速恢复和灾难恢复
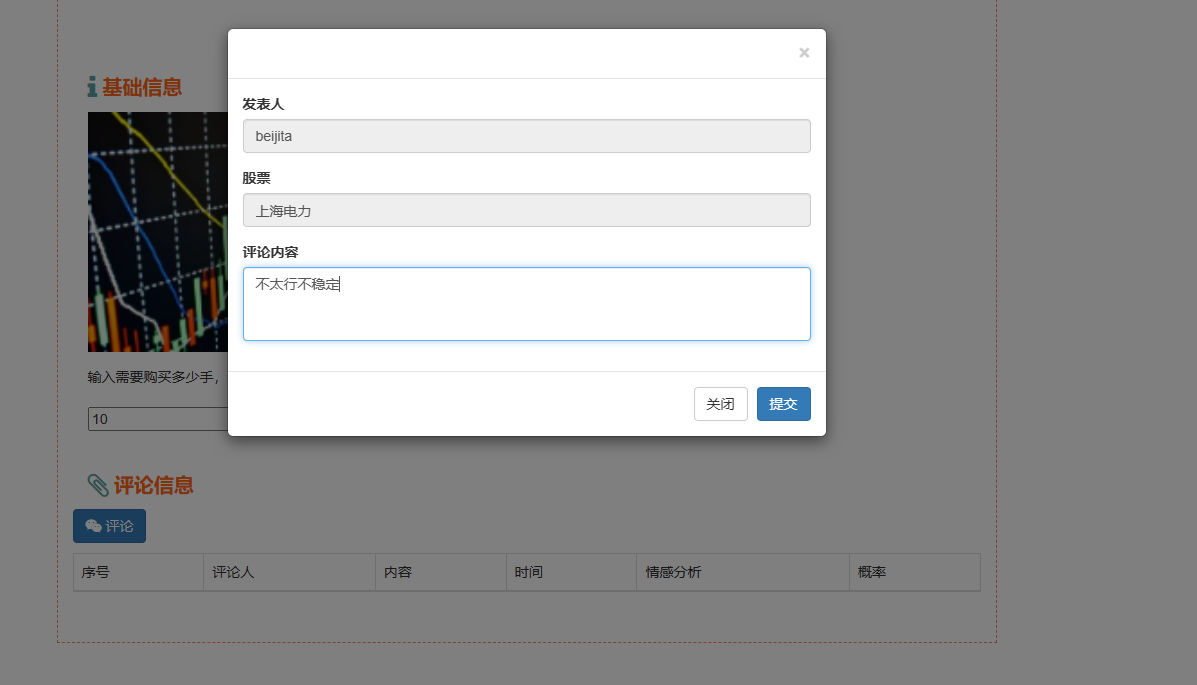


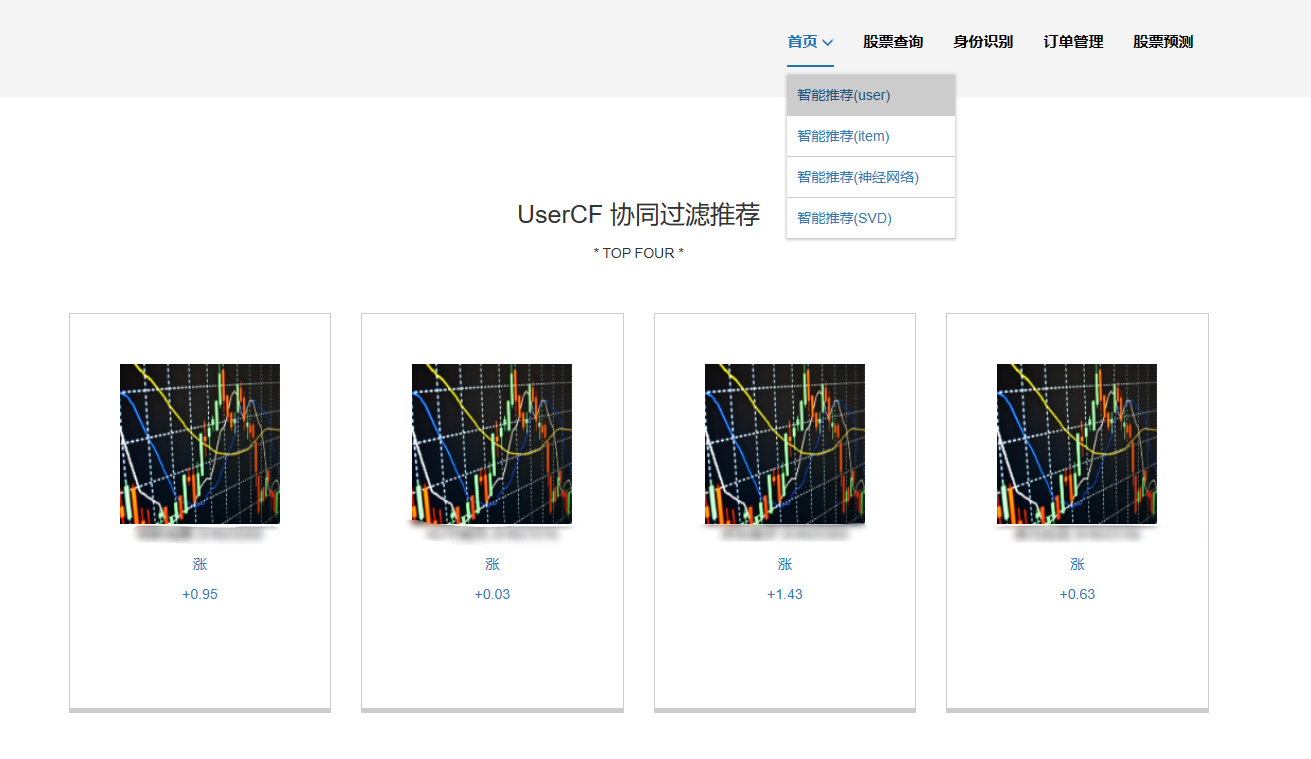
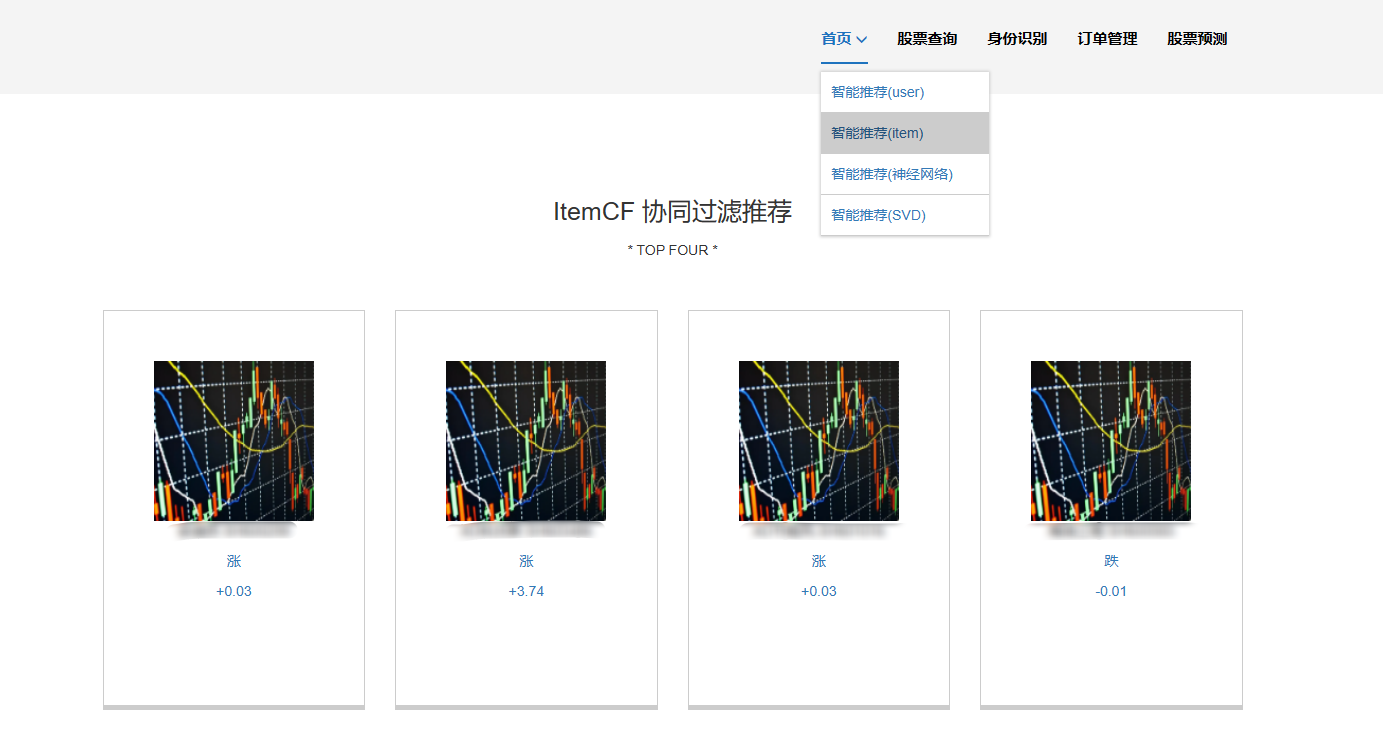
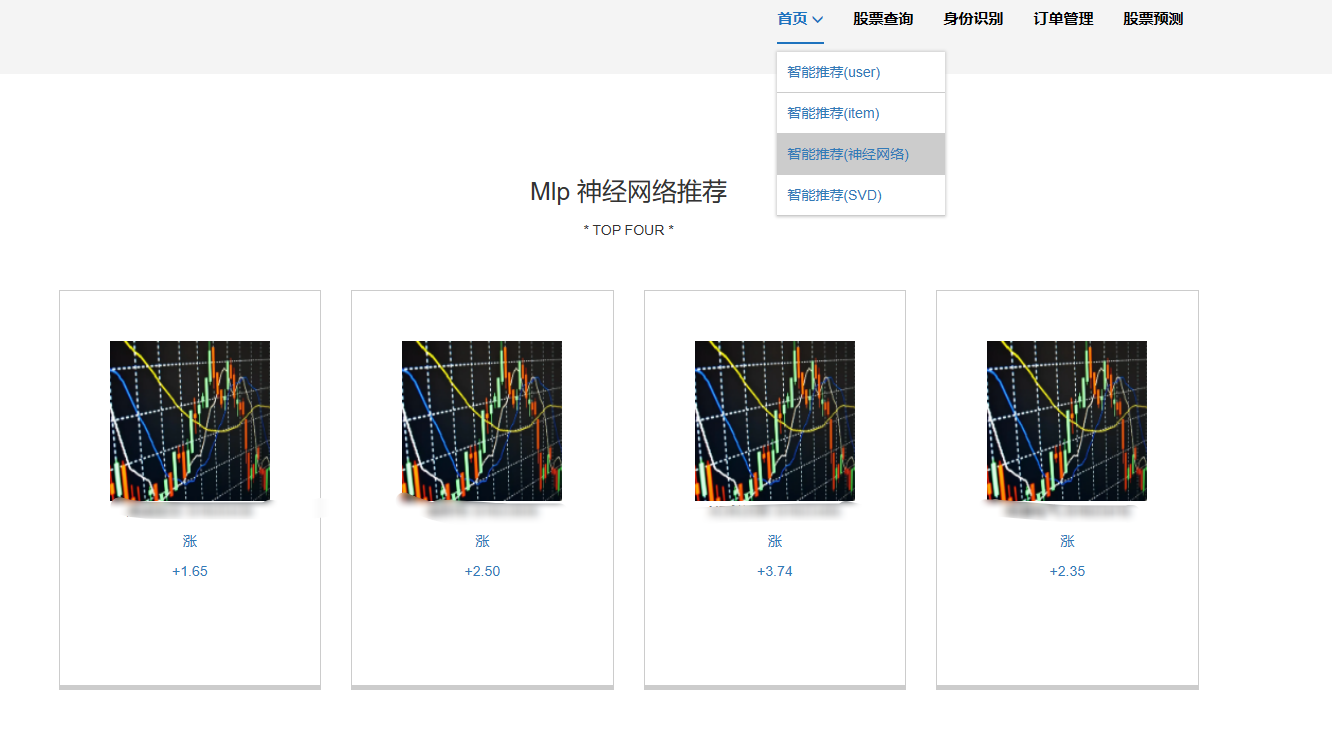
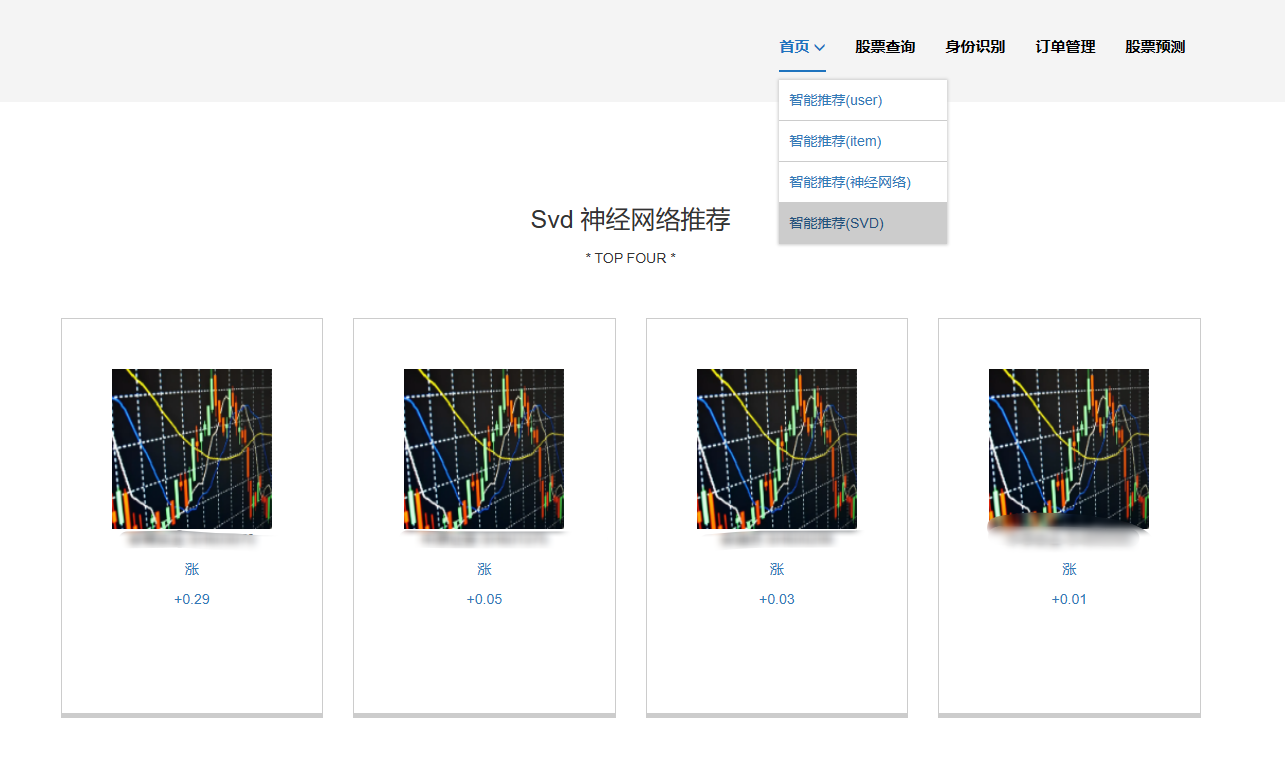


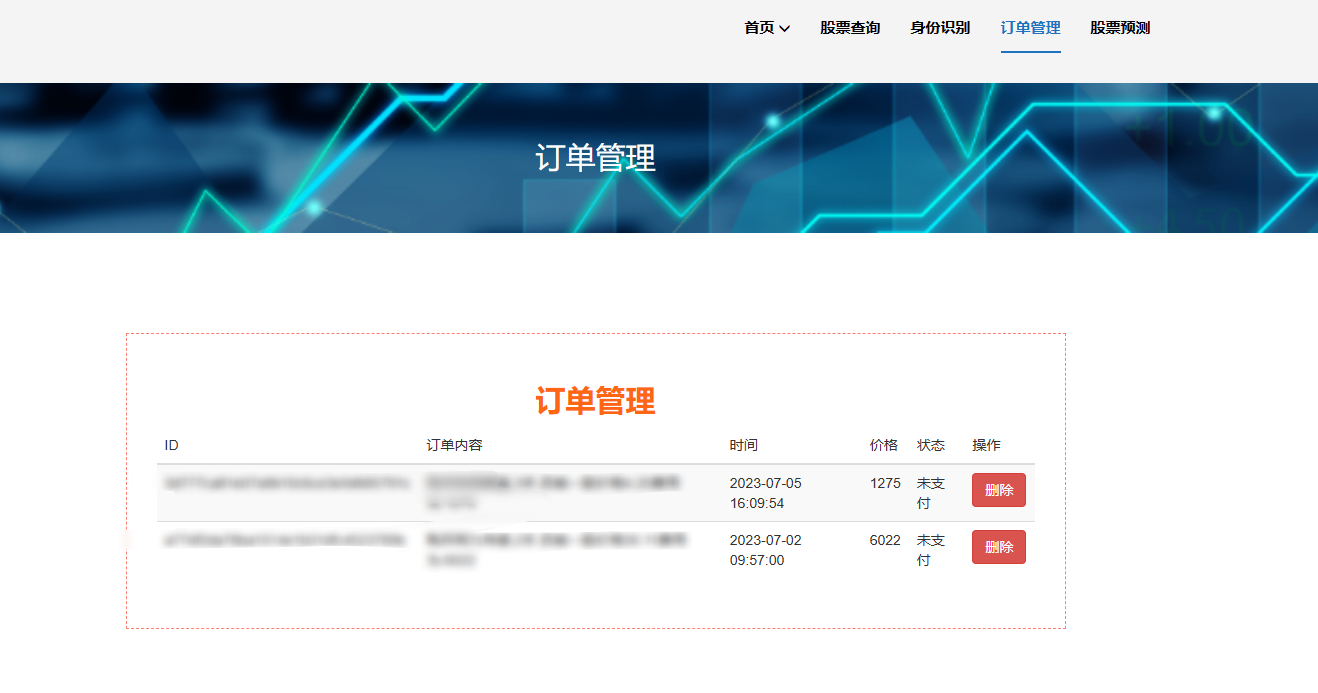
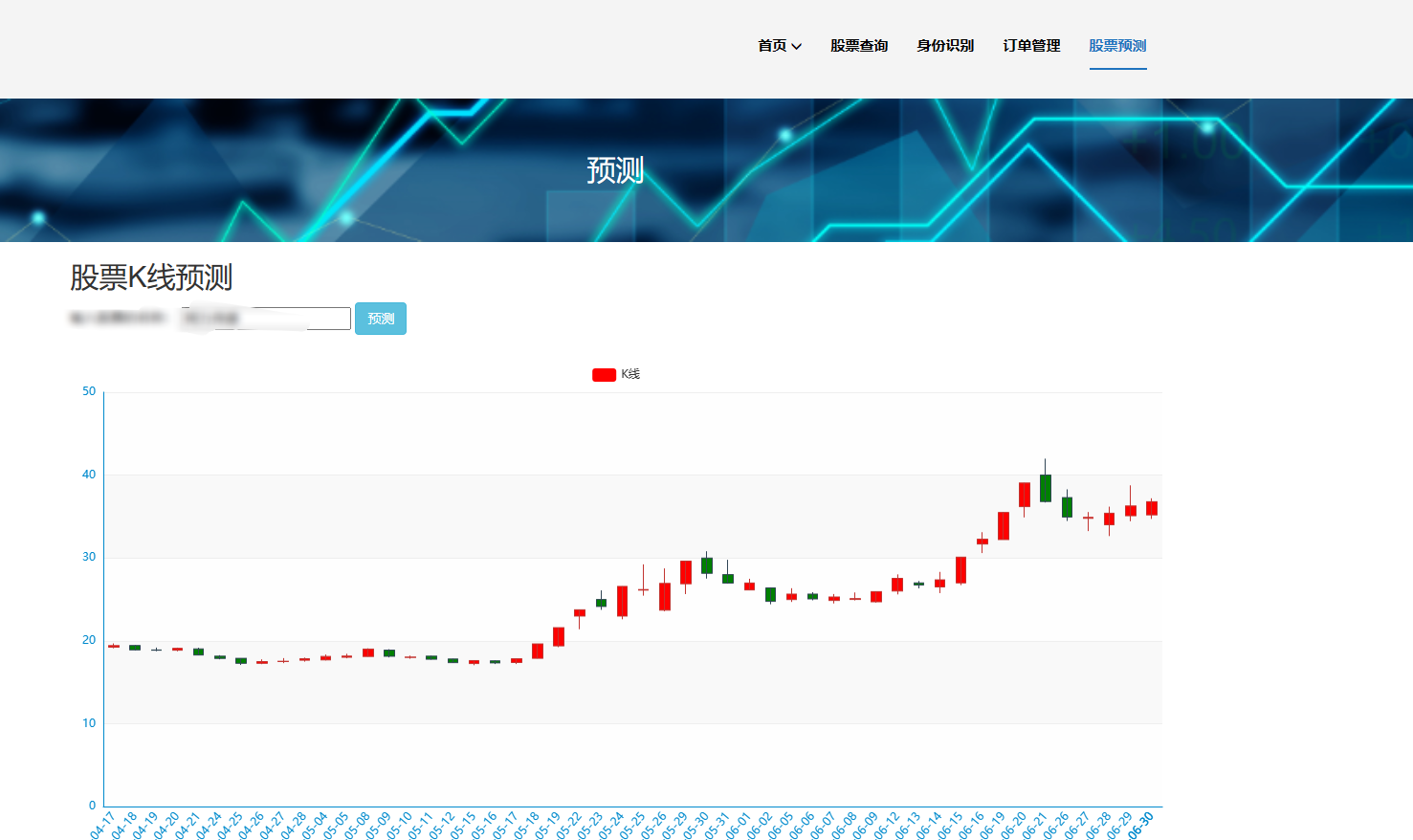
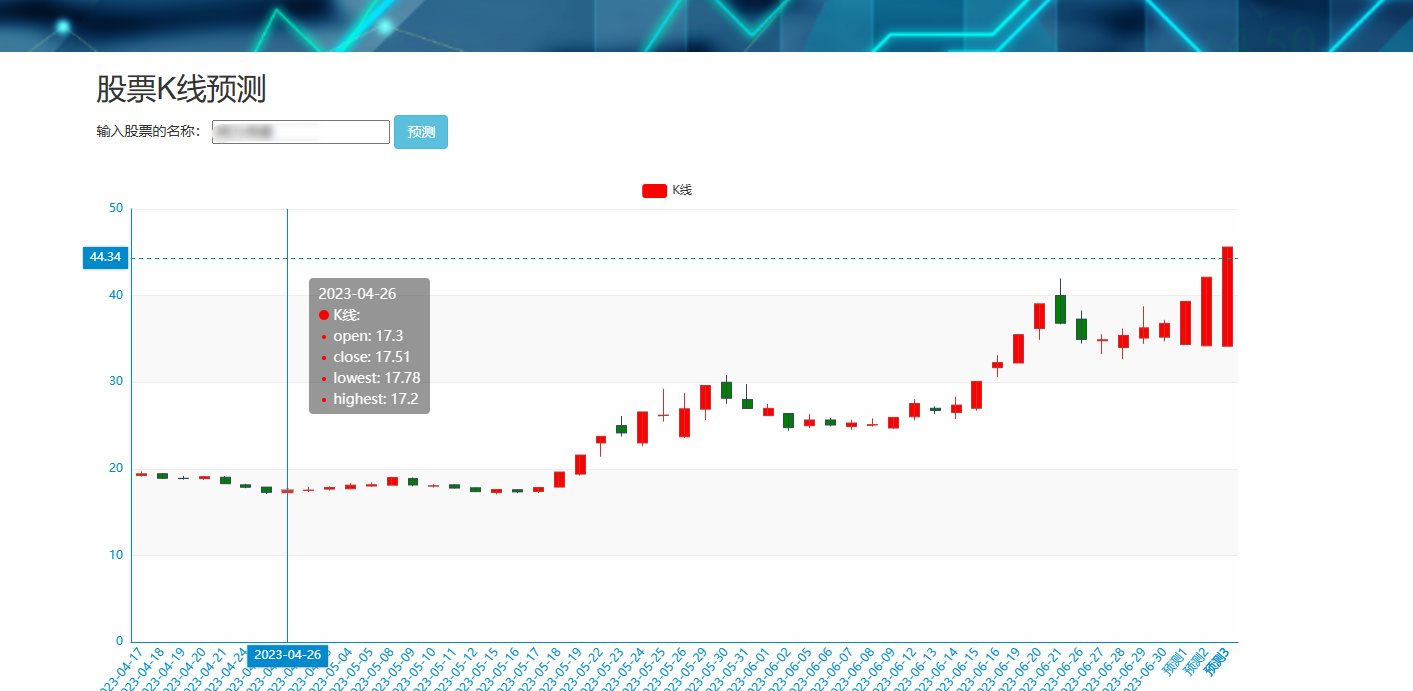
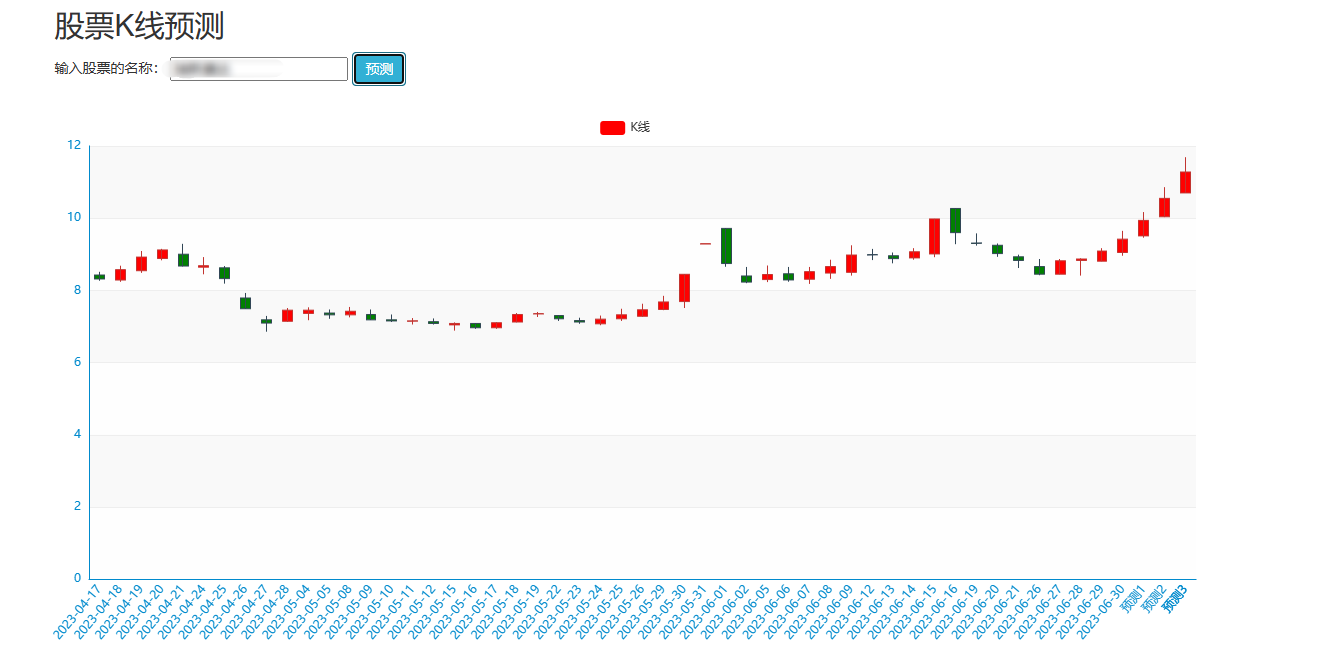
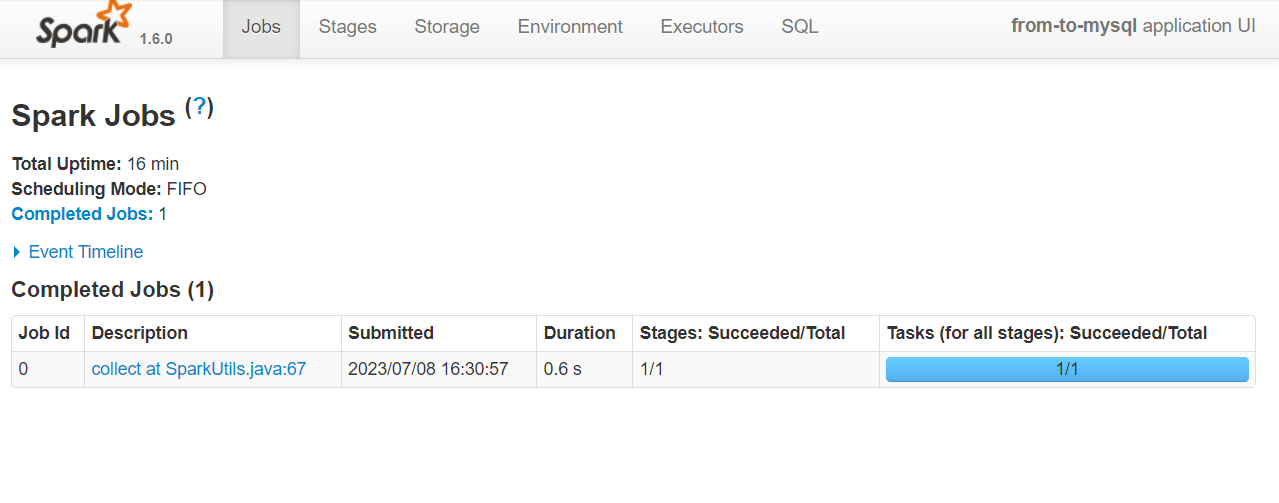
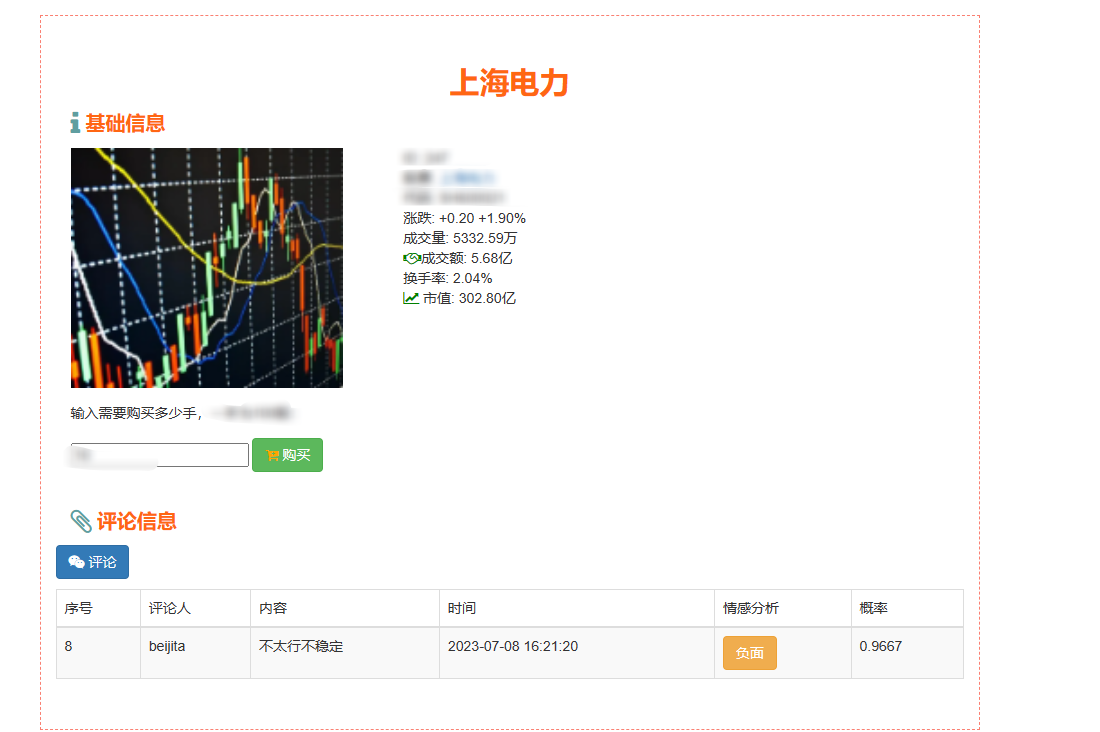
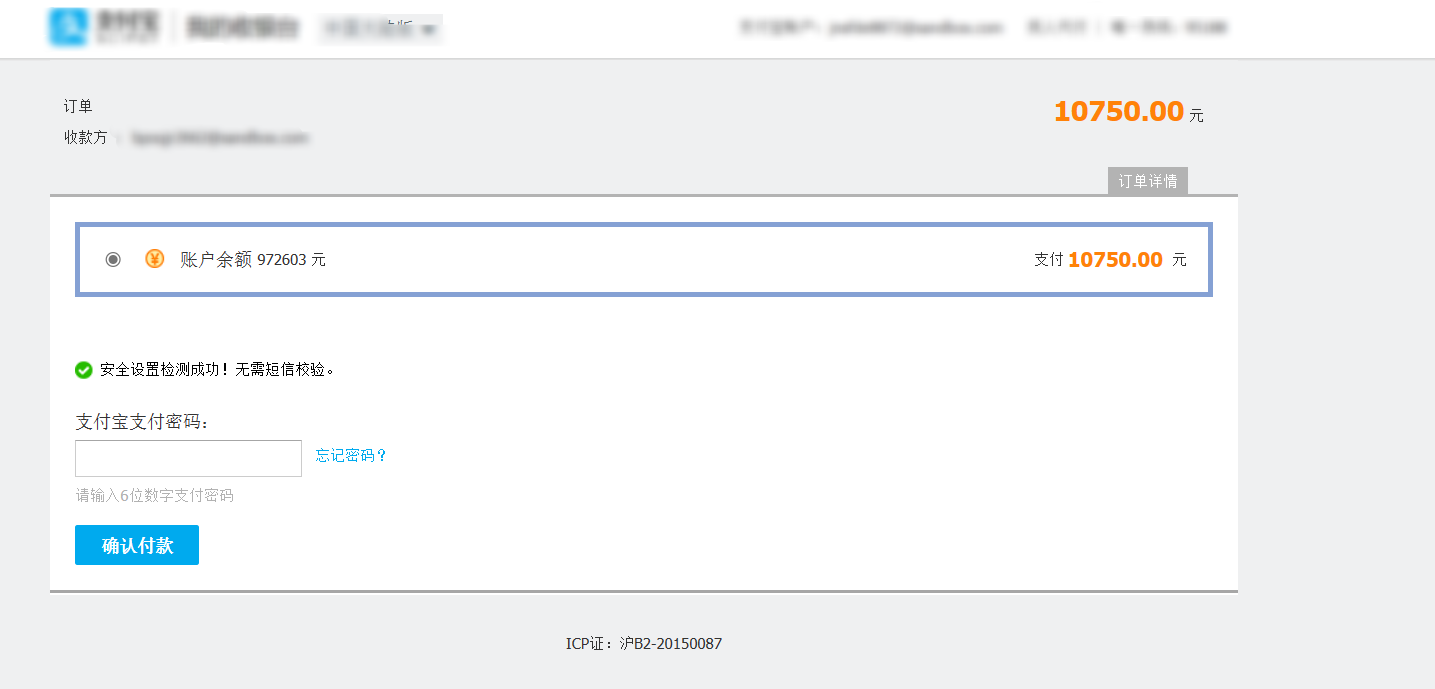
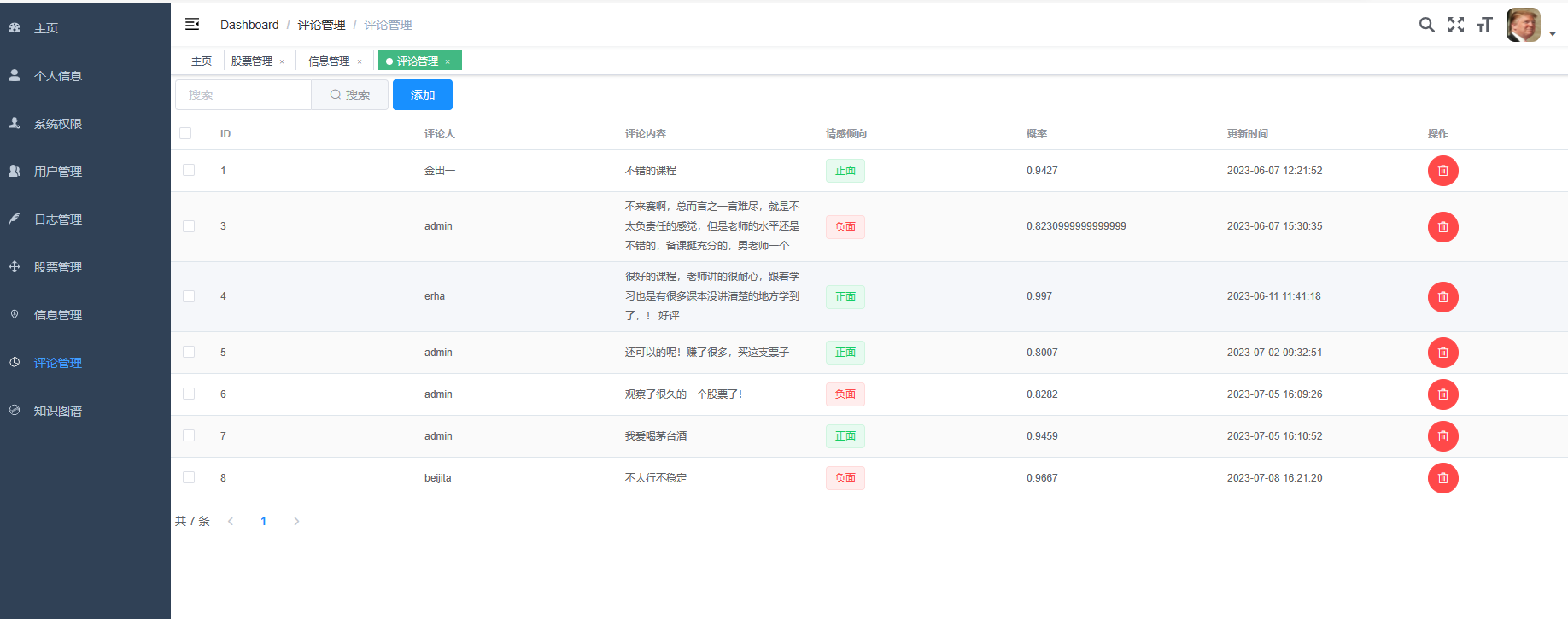
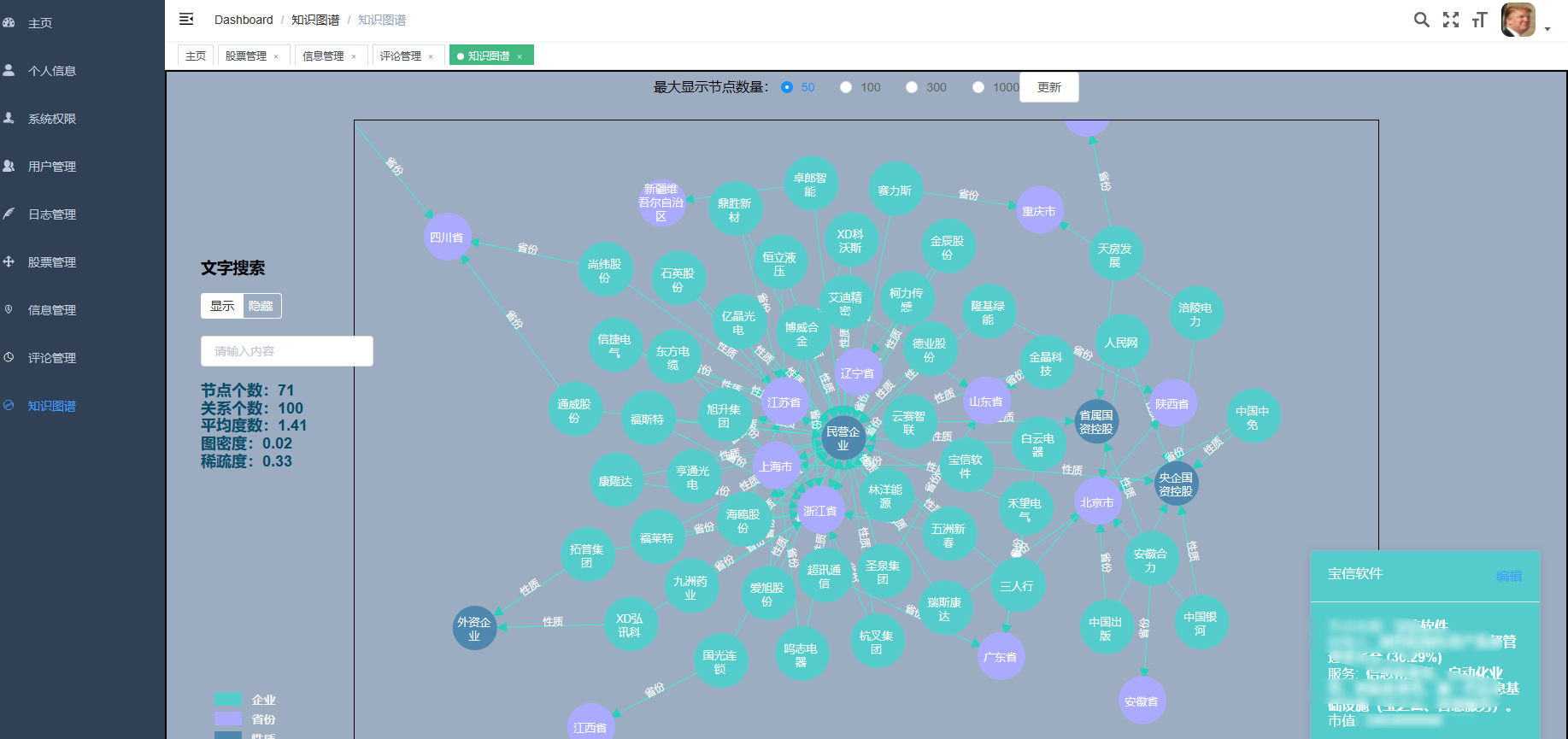


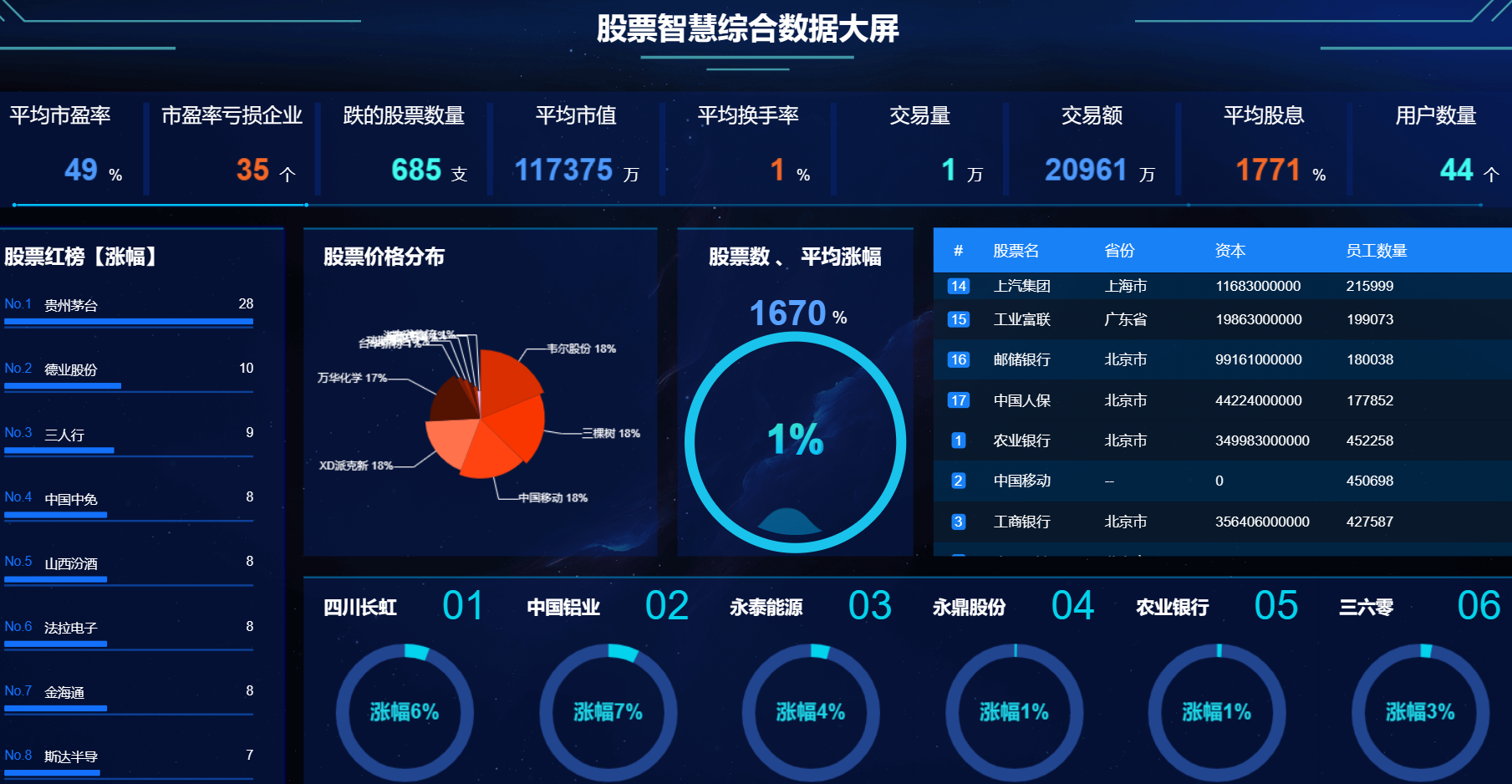
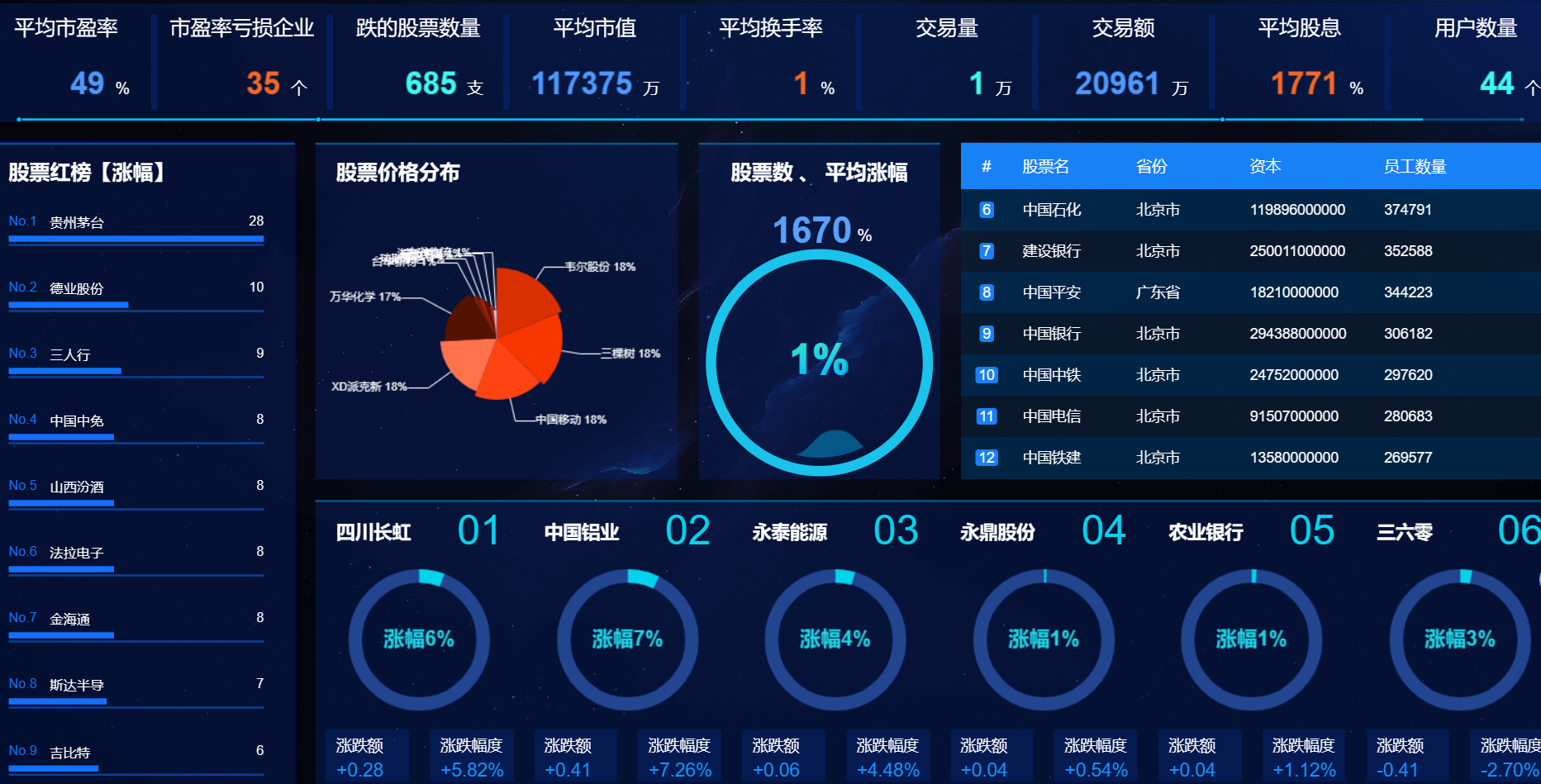
核心算法代码分享如下:
# coding=utf-8
# BILSTM 情感分析接口
import sys
import paddlehub as hub
# BiLstm 情感分析接口
if __name__ == '__main__':
param1 = sys.argv[1]
# param1 = '这个电影不错的哟'
# param1 = "1"
senta = hub.Module(name="senta_bilstm")
test_text= [param1]
input_dict = {"text": test_text}
results = senta.sentiment_classify(data=input_dict)
print(results)


![【大模型】基于ChatGLM进行微调及应用 [更新中......]](https://img-blog.csdnimg.cn/direct/9fefcf2b6f91402cb684275fd7e8fb6c.png)