杂
在0.9.0.0之前,Kafka提供了replica lag.max.messages 来控制follower副本最多落后leader副本的消息数量,follower 相对于leader 落后当超过这个数量的时候就判定该follower是失效的,就会踢出ISR,这里的指的是具体的LEO值。
对应的Kafka 也针对这些场景提供了一些控制的参数:前面提到的replica.lag.max.message(以数量为标准衡量是否落后),还有以时间为衡量标准的replica.lag.time.max(多久没有向leader 请求数据)
这些是0.9.0.0之前的版本,这个实现是可以适应大多数环境的,但是存在一个严重的缺陷,当qps持续上升,请求打满之后,很容易造成同步速率下降或者长时间无响应,进而导致很多follower被踢出ISR(在流量高峰时期会挺常见),这就导致使用者需要在不同的场景定制不同的参数配置,但是什么时候有突发流量什么时候去配置并且令其生效,这个事儿不现实,所以说Kafka这一点算是一个缺陷吧。
0.9.0.0 之后提供了一个更加适合的方式来解决这个问题,采用Kafka 落后于消费进度的时间长度来判断是否踢出ISR,这样有效的避免了在突发流量偶然落后于leader 被不合理的踢出ISR的情况,如果长时间落后于leader 这种情况实际故障是需要去踢的也没问题,也就有效的避免了ISR的反复移进移出所带来的代价。
Replica
leader分区会维护自身(本地副本)以及所有follower副本(远程副本)的相关状态,而follower分区只维护自己的状态(本地副本)。
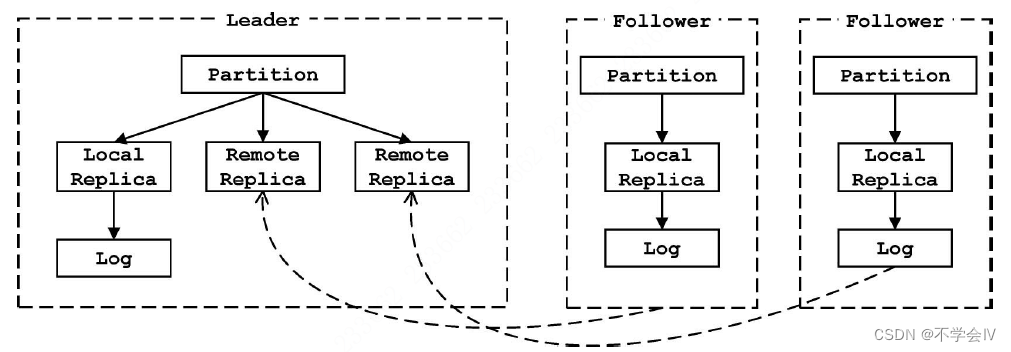
本地副本的LEO和HW都会更新;远程副本的LEO会更新,HW不会被更新。Leader分区之所以要维护远程副本是为了帮助确定HW。LEO和HW的更新时机:
| 更新对象 | 更新时机 |
|---|---|
| leader分区本地副本LEO | 接收到生产者发送的消息,写入本地磁盘后,会更新LEO |
| leader分区远程副本LEO | follower从leader拉取消息时,会告诉leader从哪个位移开始拉,这个位置就会更新到远程副本的LEO |
| follower分区本地副本LEO | 从leader分区拉取消息,写入本地磁盘后,会更新LEO |
| leader分区本地副本HW | 1. 更新本地副本LEO后;2. 更新远程副本LEO后。取本地副本和远程副本LEO中的最小值 |
| leader分区远程副本HW | 不会更新 |
| 从leader分区拉取消息,写入本地磁盘后,会更新LEO,比较LEO和leader发来的HW,取两者最小值更新为HW |
字段:
brokerId:brokerId
topicPartition:类型为TopicPartition,副本对应的分区
log:副本对应的Log对象,远程副本的此字段为空,通过此字段区分是本地副本还是远程副本
highWatermarkMetadata:记录HW的值
logEndOffsetMetadata:本地副本对应LEO值(log's end offset),远程副本该值只在follower fetch的时候更新
logStartOffset:本地副本对应LSO(log's start offset),远程副本该值只在follower fetch的时候更新
lastFetchLeaderLogEndOffset:leader收到follower的FetchRequest时候的LEO值,用来确定follower的lastCaughtUpTimeMs
lastFetchTimeMs:leader收到follower的FetchRequest时候的时间,用来确定follower的lastCaughtUpTimeMs
lastCaughtUpTimeMs:该follower的LEO大于等于此时刻leader的LEO,用来确定该follower相对于该分区ISR的lag
方法:
// 通过有无log判断是本地副本还是远程副本
def isLocal: Boolean = log.isDefined
// 获取lastCaughtUpTimeMs
def lastCaughtUpTimeMs = _lastCaughtUpTimeMs
//
def updateLogReadResult(logReadResult: LogReadResult) {
...
}
// 对于本地副本,不能直接更新LEO,其LEO由Log.logEndOffsetMetadata字段决定
private def logEndOffset_=(newLogEndOffset: LogOffsetMetadata) {
if (isLocal) {
throw new KafkaException(s"xxx")
} else {
logEndOffsetMetadata = newLogEndOffset
trace(s"xxx")
}
}
// 本地副本和远程副本的LEO获取方式也不同
def logEndOffset: LogOffsetMetadata =
if (isLocal)
log.get.logEndOffsetMetadata
else
logEndOffsetMetadata
// LSO的set和get方法与LEO相同,此处省略
// 只有本地副本可以更新HW
def highWatermark_=(newHighWatermark: LogOffsetMetadata) {
if (isLocal) {
if (newHighWatermark.messageOffset < 0)
throw new IllegalArgumentException("High watermark offset should be non-negative")
highWatermarkMetadata = newHighWatermark
log.foreach(_.onHighWatermarkIncremented(newHighWatermark.messageOffset))
} else {
throw new KafkaException(s"Should not set high watermark on partition $topicPartition's non-local replica $brokerId")
}
}
Partition
Partition负责Replica对象的管理和维护,包括副本角色切换、ISR集合管理等。
字段:
topic和partitionId:此Partition对象代表的Topic名称和分区编号。
localBrokerId:当前Broker的id,可以与replicaId比较,从而判断指定的Replica是否表示本地副
本。
logManager:当前Broker上的LogManager对象。
zkClient:操作ZooKeeper的辅助类。
leaderEpoch:该分区Leader副本的年代信息。
leaderReplicaIdOpt:该分区的Leader副本所在broker的id。
inSyncReplicas:Set[Replica]类型,该集合维护了该分区的ISR集合,ISR集合是AR集合的子集。
allReplicasMap:Pool[Int, Replica]类型,维护了该分区的全部副本的集合(AR集合)的信
息。
Partition中的方法按照功能可以划分为下列5类:
- 获取(或创建)Replica:getOrCreateReplica()方法
- 副本的Leader/Follower角色切换:makeLeader()方法和makeFollower()方法
- ISR集合管理:maybeExpandIsr()方法和maybeShrinkIsr()方法
- 调用日志存储子系统完成消息写入:appendRecordsToLeader()方法
- 检测HW的位置:checkEnoughReplicasReachOffset()方法
上述五类方法为ReplicaManager的实现提供了基础支持。其他较为简单的辅助方法不再做详细介绍,请
读者参考源码学习。
获取或创建Replica(done)
getOrCreateReplica()方法主要负责在AR集合(assignedReplicaMap) 中查找指定副本的Replica对象, 如
果查找不到则创建Replica对象并添加到AR集合中管理。 如果创建的是Local Replica, 还会创建(或恢复)
对应的Log并初始化(或恢复) HW。 HW与Log. recoveryPoint类似, 也会需要记录到文件中保存, 在每个log
目录下都有一个replication-offset-checkpoint文件记录了此目录下每个分区的HW。 在ReplicaManager启动时
会读取此文件到highWatermarkCheckpoints这个Map中, 之后会定时更新replication-offset-checkpoint文件。
副本角色切换
Broker会根据KafkaController发送的LeaderAndISRRequest请求控制副本的Leader/Follower角色切换。
Partition.makeLeader()方法是处理LeaderAndISRRequest中比较重要的环节之一, 它会将Local Replica设置成
Leader副本。Partition.makeFollower()方法与Partition.makeLeader()方法类似, 也是处理LeaderAndISRRequest的环节之一。 它的功能是按照PartitionState指定的信息, 将Local Replica设置为Follower副本。
ISR集合管理(done)
Partition除了对副本的Leader/Follower角色进行管理, 还需要管理ISR集合。 随着Follower副本不断与Leader副本进行消息同步, Follower副本的LEO会逐渐后移, 并最终追赶上Leader副本的LEO, 此时该Follower副本就有资格进入ISR集合。 Partition.maybeExpandIsr()方法实现了扩张ISR集合的功能,KafkaApis.handleFetchRequest()处理fetch请求的时候会判断该fetch是否来自follower,如果来自follower则会调用Partition.updateFollowerLogReadResults() -> Partition.maybeExpandIsr()。
在ReplicaManager中使用定时任务周期性地调用maybeShrinkIsr ()方法检查ISR集合中Follower副本与Leader副本之间的同步差距, 并对ISR集合进行缩减。 有一点需要读者注意, 在ISR集合发生增减的时候, 都会将最新的ISR集合保存在ZooKeeper中, 具体的保存路是:/brokers/topics/[topic_name]/partitions/[partitionId]/state。 后面介绍的KafkaController会监听此路径中数据的变化
追加消息(done)
调用日志存储子系统完成消息写入比较简单,后续补充。
内部会调用Log.appendAsLeader()执行真正的写入操作。
然后调用ReplicaManager.tryCompleteDelayedFetch()尝试完成DelayedFetch。
然后调用maybeIncrementLeaderHW()尝试更新高水位HW(ISR可能缩容为1,这时HW就会更新)。
如果高水位HW有变动,则尝试完成所有的Delay操作(DelayedFetch、DelayedProduce、DelayedDeleteRecords)。
检测HW的位置(done)
在检测DelayedProduce的执行条件时, 简单提到了Partition.checkEnoughReplicasReachOffset()方法, 此方法会检测其参数指定的消息是否已经被ISR集合中所有Follower副本同步。
该方法会判断当前leader副本的HW是否已经大于等于传入的偏移量,如果是则说明已经同步,返回true和0错误码,否则还没有同步,返回false和0错误码。注意当某个topic设置了min.insync.replicas参数,如果insync个数不满足,但是HW已经满足,则会返回true和一个20错误码。
ReplicaManager
ReplicaManager的功能是管理一个Broker范围内的Partition信息。ReplicaManager的实现依赖于日志存储子系统、DelayedOperationPurgatory、KafkaScheduler等组件,底层依赖于Partition和Replica。
字段:
logManager:LogManager对象,对分区的读写操作都委托给底层的日志存储子系统。
scheduler:KafkaScheduler对象,用于执行ReplicaManager中的周期性定时任务。在ReplicaManager
中总共有4个周期性任务,它们分别是highwatermark-checkpoint任务、isr-expiration任务、isrchange-
propagation、shutdown-idle-replica-alter-log-dirs-thread任务。
controllerEpoch:记录KafkaController的年代信息,当重新选举Controller Leader时该字段值会递
增。之后,在ReplicaManager处理来自KafkaController的请求时,会先检测请求中携带的年代信息
是否等于controllerEpoch字段的值,这就避免接收旧Controller Leader发送的请求。这种设计方式在
分布式系统中比较常见。
localBrokerId:当前Broker的id,主要用于查找Local Replica。
allPartitions:Pool[(String, Int), Partition]类型,其中保存了当前Broker上分配的所有Partition信息。
replicaFetcherManager:在ReplicaFetcherManager中管理了多个ReplicaFetcherThread线程,
ReplicaFetcherThread线程会向Leader副本发送FetchRequest请求来获取消息,实现Follower副本与
Leader副本同步。ReplicaFetcherManager对象在ReplicaManager初始化时被创建,后面会详细介绍
ReplicaFetcherManager与ReplicaFetcherThread的功能。
highWatermarkCheckpoints:Map[String, OffsetCheckpoint]类型,用于缓存每个log目录与
OffsetCheckpoint之间的对应关系,OffsetCheckpoint记录了对应log目录下的replication-offset-checkpoint文件,该文件中记录了data目录下每个Partition的HW。ReplicaManager中的
highwatermark-checkpoint任务会定时更新replication-offset-checkpoint文件的内容。
isrChangeSet:Set[TopicAndPartition]类型,用于记录ISR集合发生变化的分区信息。
delayedProducePurgatory、 delayedFetchPurgatory:用于管理DelayedProduce和DelayedFetch的
DelayedOperationPurgatory对象。
zkClient:操作ZooKeeper的辅助类。
角色切换
在Kafka集群中会选举一个Broker成为KafkaController的Leader, 它负责管理整个Kafka集群。 Controller Leader根据Partition的Leader副本和Follower副本的状态向对应的Broker节点发送LeaderAndIsrRequest, 这个
请求主要用于副本的角色切换, 即指导Broker将其上的哪些分区的副本切换成Leader角色, 哪些分区的副本切换成Follower角色。
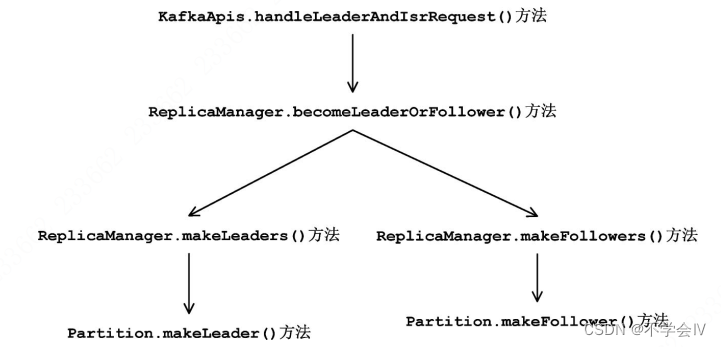
LeaderAndIsrRequest首先由KafkaAPis.handleLeaderAndIsrRequest()方法进行处理, 其核心逻辑是通过
ReplicaManager提供的becomeLeaderOrFollower()方法实现的, 而becomeLeaderOrFollower()又依赖于上一小节介绍的Partition.makeLeader()方法和makeFollower()方法 调用链路:
追加/读取消息(done)
当Local Replica切换为Leader副本之后, 就可以处理生产者发送的ProducerRequest, 将消息写入到Log中。
调用链路:KafkaApis.handleProduceRequest() -> ReplicaManager.appendRecords() -> ReplicaManager.appendToLocalLog() -> Partition.appendRecordsToLeader() -> Log.appendAsLeader()
主要逻辑在 Partition.appendRecordsToLeader()中,之前已经分析,不再展开。
Leader副本的另一个重要功能是处理FetchRequest进行消息读取。
调用链路:KafkaApis.handleFetchRequest() -> ReplicaManager.fetchMessages() -> ReplicaManager.readFromLocalLog() -> Log.read()
这里主要分析readFromLocalLog()方法,在该方法中会循环遍历拉取所有指定分区中的数据。fetch请求中会指定两个参数,一个是单次最多拉取多少数据,一个是单次单分区最多拉取多少数据(对于follower的fetch这两个默认值分别为10MB和1MB,配置项为replica.fetch.response.max.bytes和replica.fetch.max.bytes,对于消费者客户端还未确认todo)。因此,每个分区最多拉取1MB,当从多个分区中累计拉取到10MB后就会返回。另外需要注意当要读取的分区中的单条消息大于1MB时,如果已经从其他分区读到了数据则不会再读取,否则会读取一条大消息。
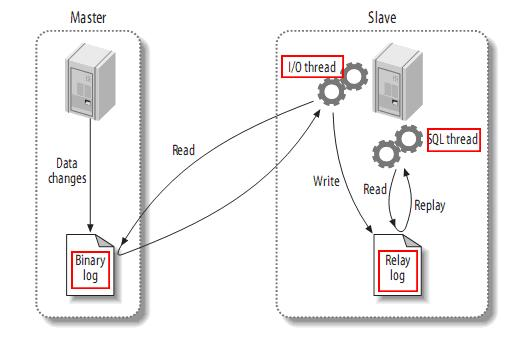
副本同步(done)
Follower副本与Leader副本同步的功能由ReplicaFetcherManager组件实现。具体的同步逻辑交由ReplicaFetcherThread线程处理。
AbstractFetcherManager是ReplicaFetcherManager的抽象类,它的addFetcherForPartitions()方法中,会为分区添加fetch线程,每个broker的fetch线程个数由num.replica.fetchers确定,默认为1。注意这里的fetch线程个数是向单个broker同步数据的线程数,实际环境中都是向n个broker拉取数据的,则真实fetch线程个数是num.replica.fetchers乘以n。比如,3个节点的kafka,kafka0会起1个fetch1线程从kafka1中拉取消息,起1个fetch2线程从kafka2中拉取消息。
还要注意,num.replica.fetchers的值并不是真正的fetch线程个数,下面的方法是将某个分区分配给某个fetcher线程的代码。可以看到是根据topic的hash值和partitionId确定一个key,然后根据该key查找map中对应的fetcher线程(没有则新建)进行关联。首先,fetcher线程个数最多为分区个数,即使我们设置了num.replica.fetchers为10000,也不会有10000个fetch线程,其次,即使num.replica.fetchers远小于分区数,实际fetcher线程数可能比num.replica.fetchers更少。试想这样一种场景,num.replica.fetchers为12,Utils.abs(31 * topic.hashCode() + partitionId) % numFetchersPerBroker中的取值没有3和4,则只会有10个fetcher线程。
private[server] def getFetcherId(topic: String, partitionId: Int) : Int = {
lock synchronized {
Utils.abs(31 * topic.hashCode() + partitionId) % numFetchersPerBroker
}
}
分区和fetch线程对应后,就会启动该fetch线程。
核心业务代码在AbstractFetcherThread的doWork()方法中:
override def doWork() {
maybeTruncate()
val fetchRequest = inLock(partitionMapLock) {
val ResultWithPartitions(fetchRequest, partitionsWithError) = buildFetchRequest(states)
if (fetchRequest.isEmpty) {
trace(s"There are no active partitions. Back off for $fetchBackOffMs ms before sending a fetch request")
partitionMapCond.await(fetchBackOffMs, TimeUnit.MILLISECONDS)
}
handlePartitionsWithErrors(partitionsWithError)
fetchRequest
}
if (!fetchRequest.isEmpty)
processFetchRequest(fetchRequest)
}
主要是两个方法:buildFetchRequest()和processFetchRequest()。
buildFetchRequest()是构造拉取请求,有两个参数值得注意,一个是replica.fetch.response.max.bytes,指定了单次最多拉取多少数据,默认是10MB,一个是replica.fetch.max.bytes,指定了单次单分区最多拉取多少数据,默认1MB。
processFetchRequest()是发送请求并对响应进行处理,主要是两个抽象方法fetch()和processPartitionData()。均在ReplicaFetcherThread中实现。fetch()中通过ReplicaFetcherBlockingSend.sendRequest()实现请求的发送并拿到响应,在具体实现中,发送完响应后会一直在while循环中执行client.poll()方法等待,直到拿到响应。processPartitionData()是将拿到的响应数据追加到本地Log,并更新follower副本的HW字段。
在正常逻辑下fetch()会调用processPartitionData()方法追加数据,如果在fetch()过程中遇到了一些异常情况,leader分区会返回错误码Errors.OFFSET_OUT_OF_RANGE,fetch()会调用handleOffsetOutOfRange()方法进行处理。
Errors.OFFSET_OUT_OF_RANGE对应两种情况:
- 一种是follower的LEO小于leader的logStartOffset。出现的场景:follower下线很久后上线,此时leader的老数据日志已经删了很多,当前的logStartOffset大于follower的LEO。(A)
- 一种是follower的LEO大于leader的LEO。出现的场景:follower下线,leader继续写入消息;follower上线开始同步消息,但还没同步到能进入ISR集合,此时ISR集合中的副本全部下线,follower变成了leader;旧leader重新上线后变成follower,此时follower的LEO大于新leader的LEO**(B)**
handleOffsetOutOfRange()在实际处理时,会重新发送一个请求获取leader分区的LEO,在此时间段内leader分区可能不断有消息写入,因此第2种情况在当下处理的时候又会变为两种情况:
- 和之前一致,follower的LEO大于leader的LEO**(B1)**
- 因为leader分区不断写入消息,此时follower的LEO已经小于leader的LEO**(B2)**
对于情形B1,数据会截断到leader的LEO,并重新发送fetch请求,offset以leader的LEO为准。对于情形B2,会重新发送fetch请求,offset以follower的LEO为准。对于情形A,会删除所有的数据日志,并重新发送fetch请求,以leader的logStartOffset为准。
注意,对于情形B1和B2,都是由于unclean leader election的场景引起的,都有可能出现副本中某一段数据不一致的情况。(在2.0.1版本中没做处理)
副本同步全流程
对于服务端来说,如果follower的拉取请求过来时,没有数据可以返回,则会构造DelayedFetch请求。一方面会放入SystemTimer中,超时后会返回。另一方面会放入Watchers中,等待触发完成时机。
触发时机:主分区中有数据写入时。
对于服务端来说,客户端的生产请求过来,当ack=-1时,会生成DelayedProduce,需要等待follower同步成功后,才能返回响应。DelayedProduce也会放入SystemTimer和Watchers中。
触发时机:接收到follower的fetch请求,或者分区的HW发生了变化
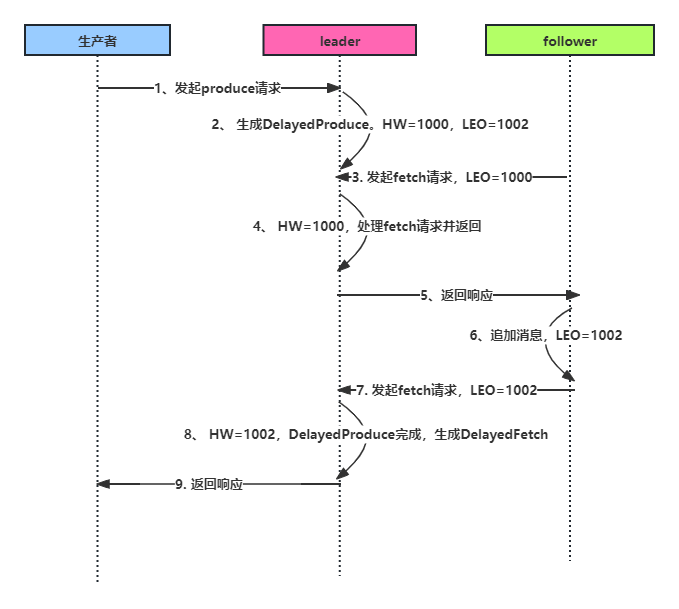
时序如下:
- 服务端处理客户端发送的生产请求
- 服务端生成DelayedProduce,等待follower同步数据
- follower发送fetch请求,请求消息数据
- 服务端接收fetch请求,获得follower当前的LEO,更新HW,判断DelayedProduce当前还未同步成功
- follower拿到消息数据返回,追加到自己的Log中,然后继续发送下一个fetch请求
- 服务端接收fetch请求,获得follower当前的LEO,更新HW,判断DelayedProduce已经同步成功,完成DelayedProduce,放入responseQueue中。
假设某个时刻,leader的HW和LEO都为1000,follower的LEO也为1000。生产者单次请求写入了2条消息。
关闭副本(done)
当Broker接收到来自KafkaController的StopReplicaRequest请求时, 会关闭其指定的副本, 并根据
StopReplicaRequest中的字段决定是否删除副本对应的Log。 在分区的副本进行重新分配、 关闭Broker等过程中都会使用到此请求, 但是需要注意的是, StopReplicaRequest并不代表一定会删除副本对应的Log, 例如shutdown的场景下就没有必要删除Log。 而在重新分配Partition副本的场景下, 就需要将旧副本及其Log删除。
定时任务(done)
highwatermark-checkpoint任务会周期性地记录每个Replica的HW并保存到其log目录中的replicationoffset-checkpoint文件中。 isr-expiration任务会周期性地调用maybeShrinkIsr()方法检测每个分区是否需要缩减其ISR集合。 isr-change-propagation任务会周期性地将ISR集合发生变化的分区记录到ZooKeeper中。
highwatermark-checkpoint
这个定时任务是在ReplicaManager.becomeLeaderOrFollower()中启动的。目的是确保所有的分区都已经完全populated来避免奇怪的race conditions。
运行间隔由配置项replica.high.watermark.checkpoint.interval.ms指定,默认为5000ms。
主体逻辑在ReplicaManager.checkpointHighWatermarks()方法中实现。
// Flushes the highwatermark value for all partitions to the highwatermark file
def checkpointHighWatermarks() {
val replicas = nonOfflinePartitionsIterator.flatMap { partition =>
val replicasList: mutable.Set[Replica] = mutable.Set()
partition.getReplica(localBrokerId).foreach(replicasList.add)
partition.getReplica(Request.FutureLocalReplicaId).foreach(replicasList.add)
replicasList
}.filter(_.log.isDefined).toBuffer
// 获取全部的Replica对象,按照副本所在的log目录进行分组
val replicasByDir = replicas.groupBy(_.log.get.dir.getParent)
for ((dir, reps) <- replicasByDir) {
// 获取当前log目录下的全部副本的HW
val hwms = reps.map(r => r.topicPartition -> r.highWatermark.messageOffset).toMap
try {
// 将HW更新到log目录下的replication-offset-checkpoint文件中
highWatermarkCheckpoints.get(dir).foreach(_.write(hwms))
} catch {
case e: KafkaStorageException =>
error(s"Error while writing to highwatermark file in directory $dir", e)
}
}
}
isr-change-propagation、isr-expiration和shutdown-idle-replica-alter-log-dirs-thread
这3个定时任务是kafka启动的时候就开始的。具体的调用栈为:
KafkaServer.startup() -> ReplicaManager.startup()。
isr-change-propagation运行间隔为2500ms。
isr-expiration运行间隔由replica.lag.time.max.ms/2指定,默认为10000/2 ms。也即一个follower分区在已经落后之后最多可以在isr中存在1.5倍的replica.lag.time.max.ms时间。内部调用Partition.maybeShrinkIsr()方法。
shutdown-idle-replica-alter-log-dirs-thread运行间隔为10000ms。
MetadataCache(done)
MetadataCache是Broker用来缓存整个集群中全部分区状态的组件。 KafkaController通过向集群中的Broker发送UpdateMetadataRequest来更新其MetadataCache中缓存的数据, 每个Broker在收到该请求后会异步更新MetadataCache中的数据。
字段:
cache: Map[String,Map[Int, UpdateMetadataRequest.PartitionState]]类型, 记录了每个分区的状态, 其中使用PartitionState记录Partition的状态。外层map的key为topic,内层map的key为分区号。
aliveBrokers: Map[Int, Broker]类型, 记录了当前可用的Broker信息, 其中使用Broker类记录每个存活Broker的网络位置信息(host、 ip、 port等) 。
aliveNodes: Map[Int,Map[ListenerName, Node]]类型, 记录了可用节点的信息
UpdateMetadataRequest由KafkaApis.handleUpdateMetadataRequest()方法处理, 它直接将请求交给ReplicaManager.maybeUpdateMetadataCache()方法处理。
MetadataCache.updateCache()方法中完成了对aliveBrokers、aliveNodes、 cache字段的更新。
生产者和消费者中使用Metadata对象缓存Kafka集群的元信息, 在 Metadata更新时会向服务端发送MetadataRequest。 MetadataRequest首先由KafkaApis. handleTopicMetadataRequest()方法进行处理。
在KafkaApis.getTopicMetadata()方法中完成对MetadataCache的查询, 同时还会根据配置以及Topic的名称决定是否自动创建未知(MetadataCache查找不到) 的Topic。
总结
num.replica.fetchers 单个broker的拉取线程,默认1
replica.fetch.response.max.bytes 单次最多拉取多少数据,默认10MB
replica.fetch.max.bytes 单次单分区最多拉取多少数据,默认1MB


![【大模型】基于ChatGLM进行微调及应用 [更新中......]](https://img-blog.csdnimg.cn/direct/9fefcf2b6f91402cb684275fd7e8fb6c.png)