-
识别内存问题
当怀疑应用存在内存问题的时候,首先使用DevEco Profiler的Allocation Insight来度量内存在问题场景下的大小变化以及整体趋势,初步定界问题出现的位置(Native Heap/ArkTS Heap/dev等)。
在初步识别内存问题出现的位置时,录制时需要将Allocation Insight中的后两条泳道取消勾选,只录制Memory这一条泳道。
(注:因为另外两条泳道会开启对内存分配、内存对象的抓取,这些功能会带来额外的开销,可能会对我们初步定界问题产生噪音,阻碍分析,故先排除)
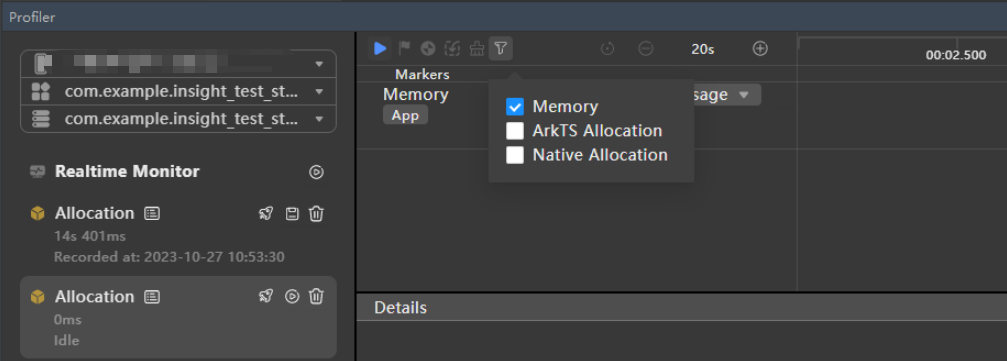
录制过程中,尽可能多的触发会导致内存问题的操作,将问题放大,便于快速定界问题点。复现完成后,结束录制,选中Memory泳道(直接选中泳道详情区域会展示完整的泳道数据),查看详情区域的数据 (注:详情区域数据采用PSS的维度衡量,数据近似于使用`hidumper --mem $pid`的第一列PSS值)。
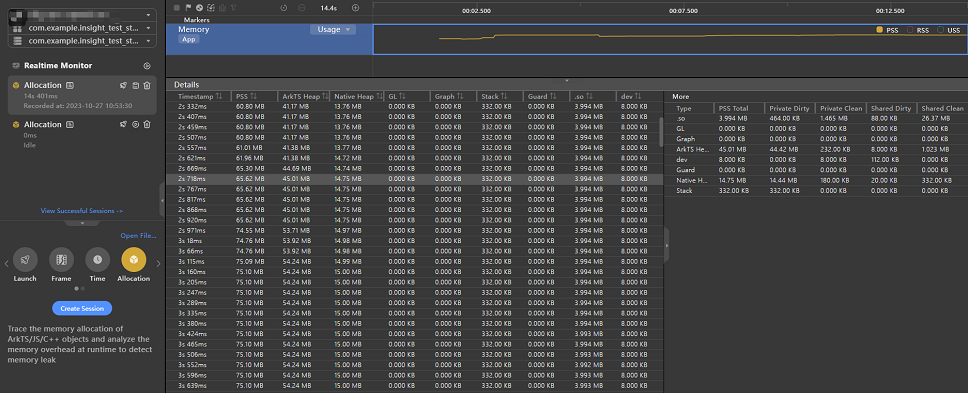
通过详情区域的详细内存占用数值,我们能够大致定界出有哪些位置的内存可能存在问题。
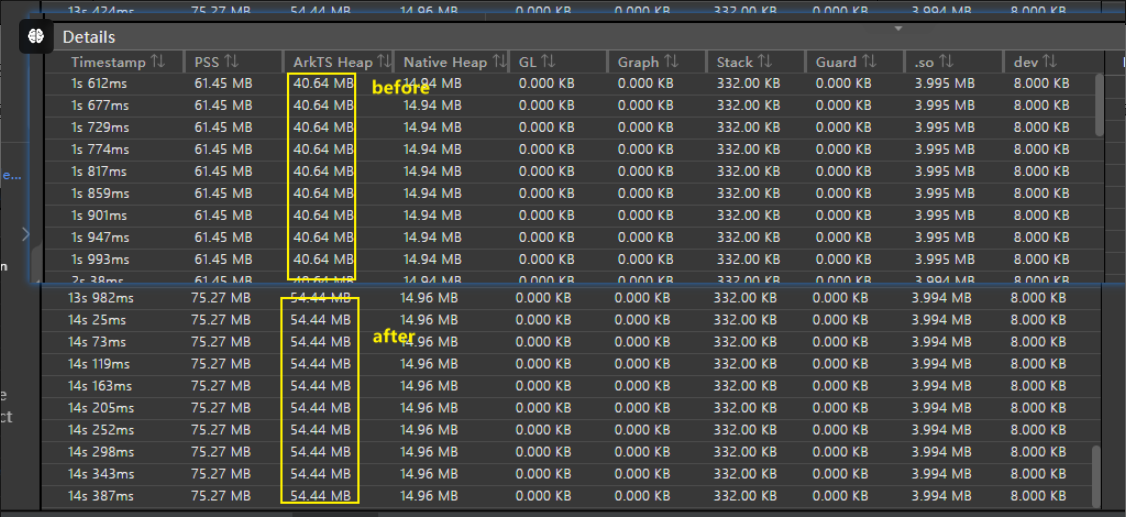
因为本文主要介绍如何定位ArkTS的内存问题,故只关心ArkTS Heap相关的部分。从表格的数据中发现,ArkTS Heap有不少的上涨,这说明在方舟虚拟机内的堆内存上可能存在内存泄漏问题,需要进一步分析。
-
分析ArkTS Heap
ArkTS在编译后会生成JS代码,运行在方舟虚拟机中。分析虚拟机的堆内存问题时会用到内存快照(Heap Snapshot/Heap Dump)技术,DevEco Profiler提供了分析内存快照的Snapshot Insight。
点击领取→纯血鸿蒙Next全套最新学习资料(安全链接,放心点击)希望这一份鸿蒙学习资料能够给大家带来帮助,有需要的小伙伴自行领取,
在使用Snapshot分析时,通常会使用三快照技术(Three Snapshot Technique),通过内存快照的对比视图将某两次快照之间分配且仍然驻留的内存筛选出来,这些对象中的一部分就可能是导致内存泄漏的对象。通用的流程为:
打开应用,初始化场景 (触发GC)-> 拍摄第一次Snapshot作为基准 -> 多(N)次触发内存泄漏操作 -> 拍摄第二次堆快照 -> 触发主动GC -> 拍摄第三次堆快照。由于方舟虚拟机提供了在获取堆快照之前自动GC的功能,因此我们可以将上述流程简化为两步,同时加上Profiler的录制功能,整体流程为:
打开应用,初始化场景 -> 开启录制Snapshot Insight-> 拍摄第一次Snapshot作为基准 -> 多(N)次触发内存泄漏操作 -> 拍摄第二次堆快照 -> 结束录制。
录制完成后,会得到如下图所示的数据:
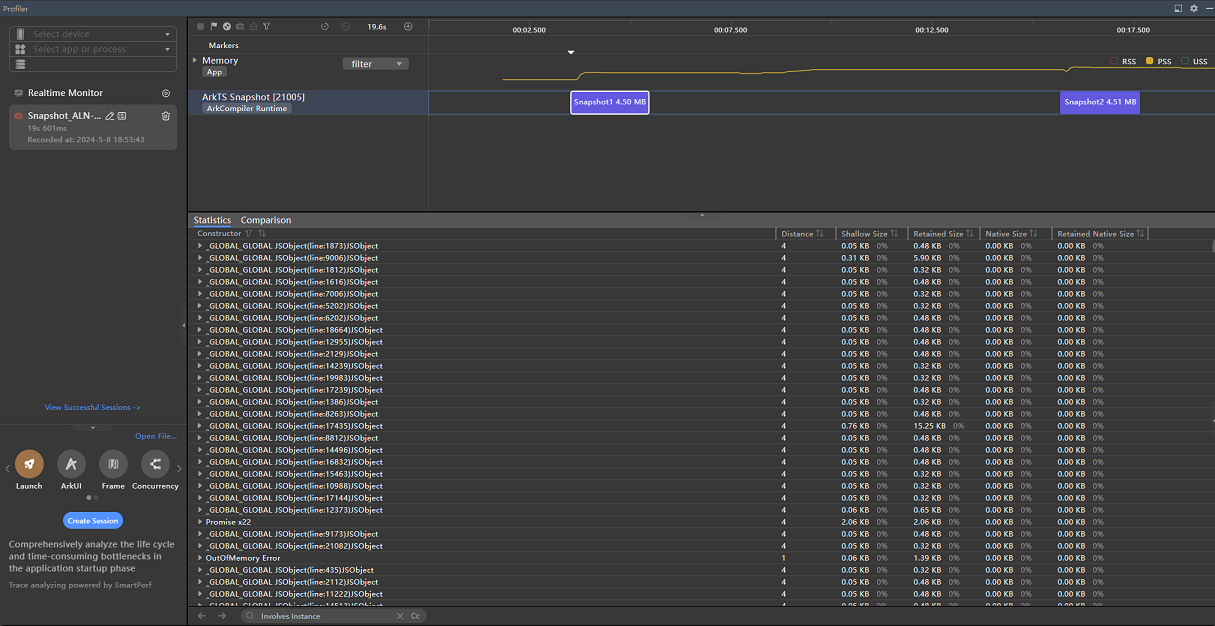
录制过程中,我们采集了两次堆快照,对应在Profiler的界面上就是两个紫色的条块,每一个条块内的数据都是当前的虚拟机堆快照。条块上的数字大小代表的是虚拟机堆内存的实际占用。
由于在每次拍摄堆快照之前,虚拟机都会触发GC,所以理论上堆快照内存在的对象都是当前虚拟机已经无法GC掉的对象,所以我们可以将两个堆快照进行比较,来查看哪些对象是我们在触发问题场景时新增了且不能释放的。
点击Snapshot Insight面板的Comparison页签,将两次Snapshot进行比较,如下图。图中数据的含义为以Snapshot1作为基准,Snapshot2对比Snapshot1的数据变化量。
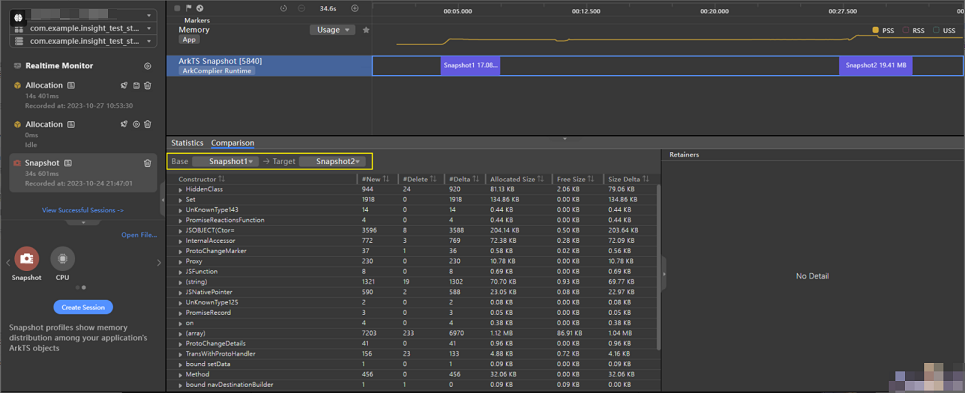
在触发内存问题场景时将问题触发N次,在比较视图中首先就去找与N强相关、与业务代码强相关的constructor,首先来分析这些对象是否正常。
首先介绍一下Snapshot比较视图中各项数据的含义,如下图:
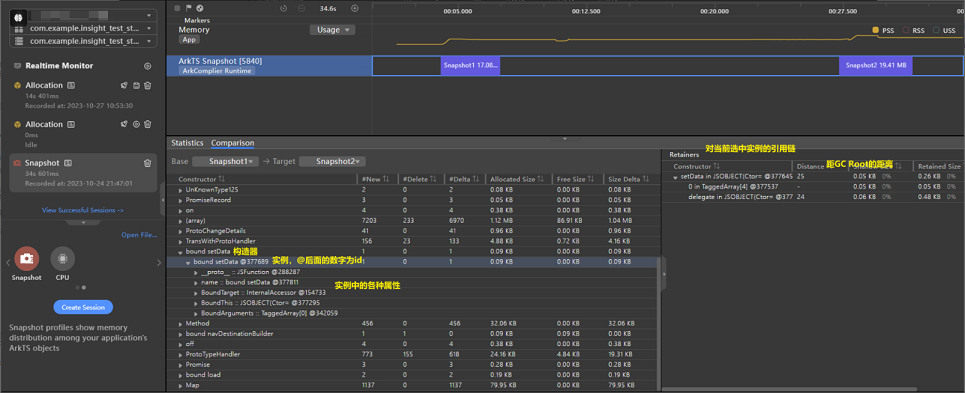
在找到相关的业务关联的对象后,可以从右侧More区域的Retainers里面一层层去寻找、排查在引用链上的可疑对象(一般指与业务代码关联的对象,例如上图中的setData)。
当发现了引用链上的业务对象时,就可以通过对象索引功能(IDE正在实现)可以一环一环找到各个对象的引用关系,通过排查在引用链上的对象传递关系,在代码中分析相关的逻辑来找到内存泄漏的位置。
-
应用代码排查
具备了通用的分析能力,就需要根据业务场景来排查代码,分析代码中出现问题的位置。
第一步,就是先缩小问题场景,让场景尽可能的单一,最好是单一操作单一组件出现问题。涉及的代码越少,定位效率越高。
第二步,开始排查代码,首先需要排查的模块就是在上面提到的Snapshot分析中所找出到的问题场景中两个Snapshot对比里增加的与业务代码相关的对象以及其引用链(这里在排查引用链时,可以参考:ArkTS内存泄露分析,在引用链中有一些对象是虚拟机内部的,基本不需要开发者关心)。
这一步在代码场景比较单一的时候,可以结合引用逻辑与代码来一起分析是什么原因造成的,例如闭包被全局对象持有无法释放。结合目前的经验来看,从引用链上虽然无法直接定位到代码具体位置和原因,但是可以分析到一些代码关联性的。
但是在引用链上也很可能会挂载一些ArkUI相关的对象,如果定位到大量的应用对象最终的引用关系都是引用到了ArkUI对象上,可能需要找到相关的框架同事来协助定位。
这一步中可能有两个问题:
1. 对象实例以及引用链上有很多对象都和业务代码相关联,应该从哪一个下手。
2. 对象引用链实在太过复杂,具体要看哪里,怎么一步步往下看。
针对这两个问题:
1. 关联对象多,这时候不要发散,力出一孔,优先解决一个问题,顺带着可能就解决掉了一串问题,然后再根据可能涉及到的多个模块逐个攻破
2. 参考上面的Ark调优工具指南,使用“深度优先遍历”的方法先分析一条引用链,找到其中的可疑点,再慢慢地发散到其他的引用链上,找出一些共性的对象,最终汇总起来再集中审视所有的可疑对象
第三步,通过在上面步骤中分析的代码,最好相关模块的开发人员来走读一遍代码,通过白盒来分析可能存在的问题点。如果实在模块逻辑太过复杂,那就只有请出注释大法,二分的来定位问题位置。
-
实践
这里使用一个某视频应用内存泄漏的问题来简单介绍具体的问题定位方法。
问题出在视频应用的搜索页上,在点击进入搜索页搜索内容后退出搜索页,发现内存增长不会回退,且不断操作进入/退出时内存数据会一直增加,因此怀疑这步操作存在内存泄漏。
采用章节2中提到的两步Snapshot法:
1. 打开应用,在初始化的页面上拍摄一次ArkTS堆内存快照。
2. 反复进入搜索页搜索内容,一共触发6次,并在搜索完之后推出搜索页回到主页(步骤1)的状态。
3. 拍摄第二次ArkTS堆内存快照,拍摄完成后停止录制等待解析完毕。
快照解析完成后,即可使用对比视图查看在两次相同状态下的应用内存区别,下面是对比视图:
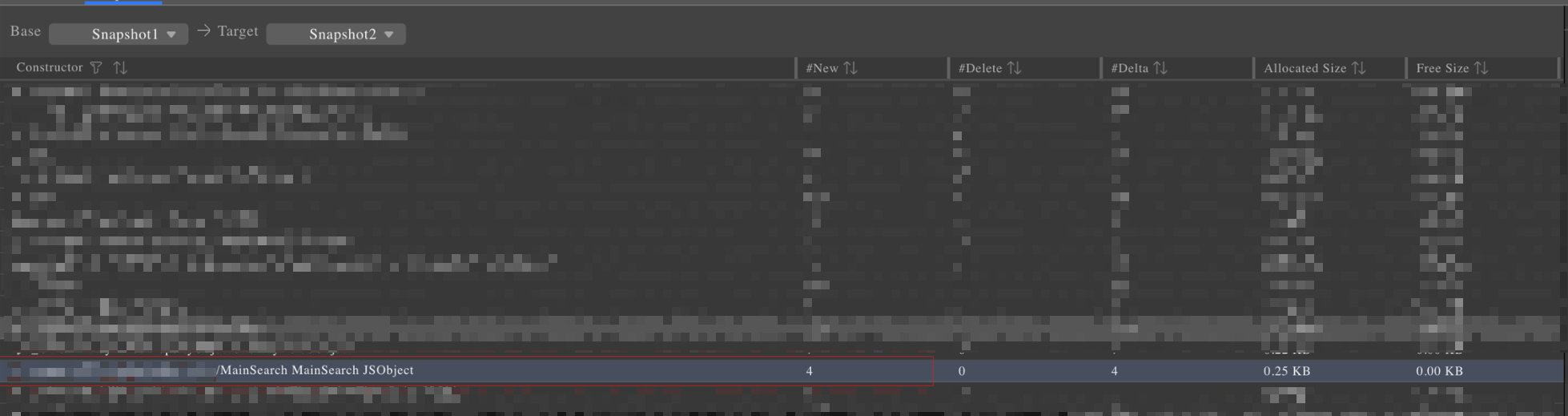
结合业务逻辑,从对比视图中发现,MainSearch这个搜索逻辑所对应的业务对象在两次Snapshot之间增加了4个,并且是虚拟机无法GC回收掉的对象(因为虚拟机在做dump之前自动触发一次Full GC),而从B站的业务逻辑中确认,该对象在退出搜索页面时就应该被销毁,因此基本可以确定该对象产生了泄漏。
接下来就要分析为什么会这个对象不会被GC回收掉,在方舟虚拟机中,对象不会被GC回收的根本原因是从GC Root到该对象有至少一条引用链,导致该对象间接甚至直接被GC Root引用,虚拟机在做可达性分析时,发现该对象被GC Root引用,因此不会回收该对象。接下来就需要借助工具中的引用链来分析为什么对象会被GC Root引用,找出其中的引用关系并解决掉错误的引用关系,以释放相应的内存。虚拟机GC详细介绍可参考:解密方舟的高性能内存回收技术——HPP GC。
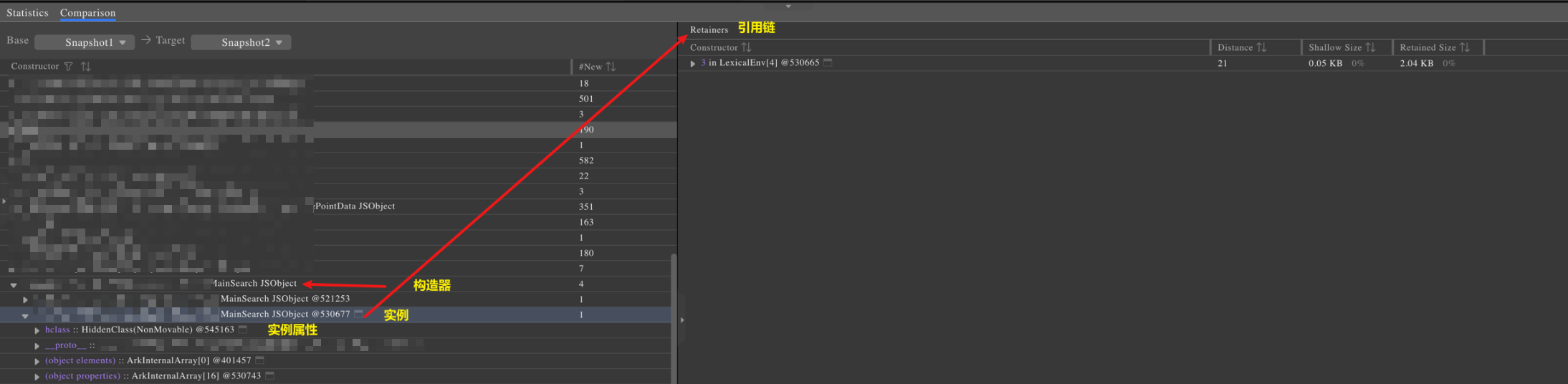
打开该构造器所对应的树状结构,其子节点均为该构造器对应的实例对象,也即在这次快照中仍然存活的对象,再将该对象节点展开,其下方节点为对象的属性(Fields)以及引用链(Retainers),点击该对象即可在Reatiners中分析其引用链。
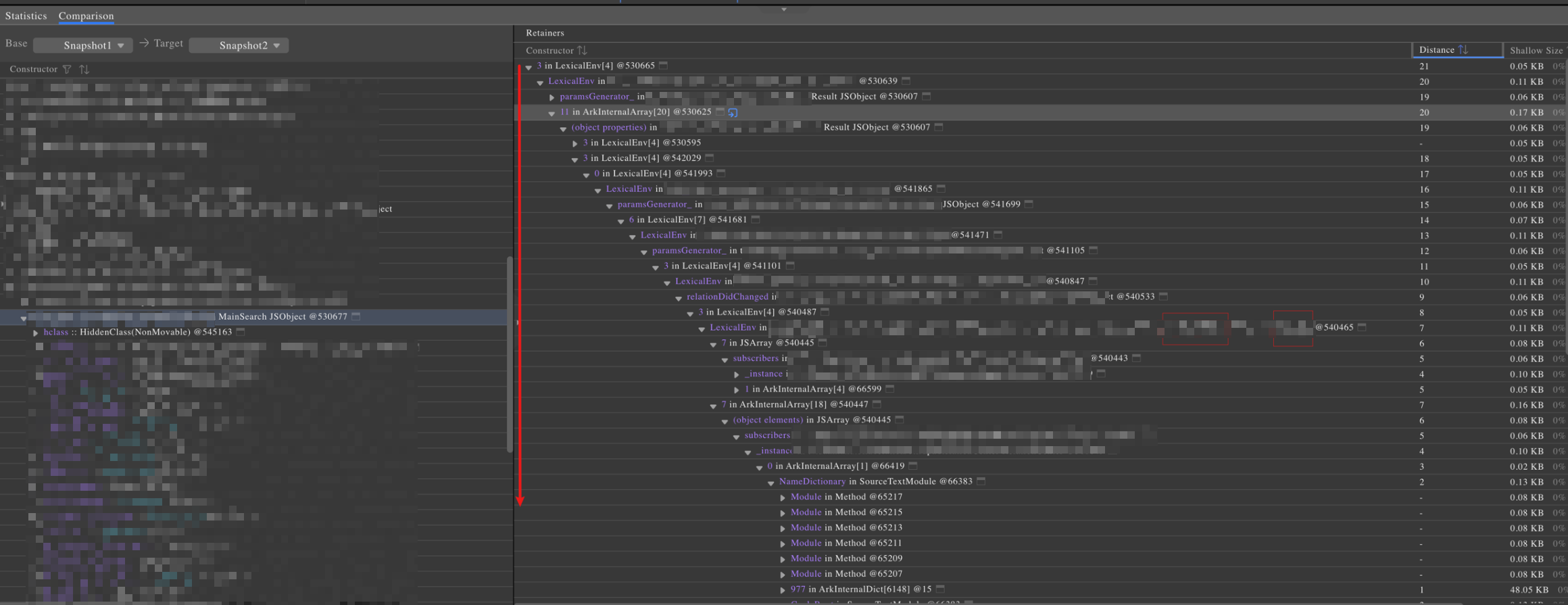
引用链中有个重要信息是Distance,即该节点距离GC Root的距离(所需要经过的节点个数),我们在分析引用链上的对象问题时,通常会逐步找Distance越来越小的对象,以对该对象到GC Root上对象的进行分析,如上图所示,就是一条从泄漏对象(Main Search)到GC Root的引用链。下面挑选其中一小部分来介绍如何分析引用链。

图中是一个顺序展开的树形引用链结构,其中每一行标注了字母,后面用字母代替该行的数据。
引用链在树形结构的展示中是一个反向的逻辑,即下面一行的属性引用了上面一行的对象,拿A和B举例,上图中的关系就代表着A中RelationCenter这个对象的_instance属性引用了B中的RelationCenter JSObject,而B中RelationCenter这个对象的subscribers属性又引用了JSArray对象,再往上分析以此类推。
反过来也可以这么理解:B中RelationCenter JSObject就是A中RelationCenter对象的_instance属性。
用伪代码可以描述为:
A:RelationCenter._instance = B:RelateionCenter JSObject B:RelateionCenter JSObject.subscribers = C:JSArray C:JSArray[7] = D:RelationButton.anonymous(line:84)通过这个引用关系,可以大体上确定出代码的变量引用逻辑,接下来就要去白盒分析代码的问题所在,即这些引用是否合理,若不合理,需要解决这些引用关系。
在此视频应用的这个问题中,分析发现这里在 GC Root距离为 7 的节点上(上图中D), 看到 RelationButton anonymous(line:84)以及RelationCenter相关信息(如果需要查看该对象的详细信息,可以点击这一行字符后面的蓝色按钮,跳转到对象详情面板),
我们打开项目在编译后的文件中(build目录下的ts文件)找到 RelationButton的84行,分析逻辑发现是一个 subscriber,首先考虑是否是因为忘记解绑这个定位导致问题,然后去自己的 ets 代码找问题。
最终定位到相关的源码文件发现是因为没有解除相关代码的订阅导致内存泄漏,添加解绑逻辑后再次抓取快照测试,该引用链消失,这个问题点解除,接下来以相同的方式分析其余类似问题。
上面的例子只是简单介绍如何通过引用链来分析可疑的内存泄漏对象的方法,并未过多描述其中的分析排查思路和逻辑,总的来说,在应用侧排查内存问题时,主要有以下几个关注点:
1. Snapshot的对比视图中,优先观察与当前问题场景强相关的业务对象,虚拟机内部对象以及一些基础对象(例如ArkInternelXXX/(array)/GLOBAL等等)可以先不关心,可以使用过滤功能过滤出业务代码相关的对象(例如使用com.huawei进行过滤)。
2. 在分析引用链的过程中,引用链上可能掺杂了一些虚拟机内部的对象(因为虚拟机需要使用一些内部对象或类型来管理/表达业务对象),所以引用链的分析过程中也可以优先关注业务侧的对象,先忽略掉其中的虚拟机内部对象(虚拟机内部对象的描述,可以参考:ArkTS内存泄露分析)。
3. Snapshot中展示的对象可能非常多,这可能是由于某一条引用链上引用了很多的对象所导致的,不要怕,逐个解决其中的与当前业务逻辑最相关的对象,其他的对象可能随之就一起解决掉了,所以优先解决业务对象以及与问题复现场景下最强相关的对象的引用逻辑,其余对象逐步再进行优化。
-
结语
问题通常会在开发的过程中逐渐积累,到最终暴露出来时可能已经涉及了多个模块、多种逻辑,各种逻辑互相耦合,导致分析的难度大大增加。
这种情况下,我们建议把性能相关的工作也能做到平时,在开发态也去关心程序的性能问题。例如,刚写了一个很长的引用关系、增加了一些注册实例的逻辑或者做了一些父子组件的变量传递,这种时候就可以去结合逻辑自己设想一下,会不会引发一定的性能问题,甚至可以在平时就用调优工具来自测试。这样做到每个开发阶段都保证了性能的可靠,那么在项目日益增大的同时,性能问题也不会严重到离谱、无法分析。
HarmonyOS开发探索:使用Snapshot Insight分析ArkTS内存问题
news2026/2/13 8:47:05
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1884295.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
阿里云物联网应用层开发:第二部分,云产品流转
文章目录 哔哩哔哩视频教程1、云产品流转概述2、我们需要创建多少个云产品流转?3、阿里云物联网平台产品云流转实现3-1 创建数据源3-2 创建数据目的3-2 创建解析器,并关联数据、编写脚本 哔哩哔哩视频教程
【阿里云物联网综合开发,STM32ESP8266微信小程…
2024年道路运输安全员(企业管理人员)备考题库资料。
46.危险货物道路运输随车携带的单据,下列选项不属于的是()。
A.道路运输危险货物安全卡
B.运单或者电子运单
C.道路危险货物运输从业资格证
D.车辆检测报告
答案:D
47.危险货物运输驾驶人员在24小时内实际驾驶车辆时间累计不…
opengl箱子的显示
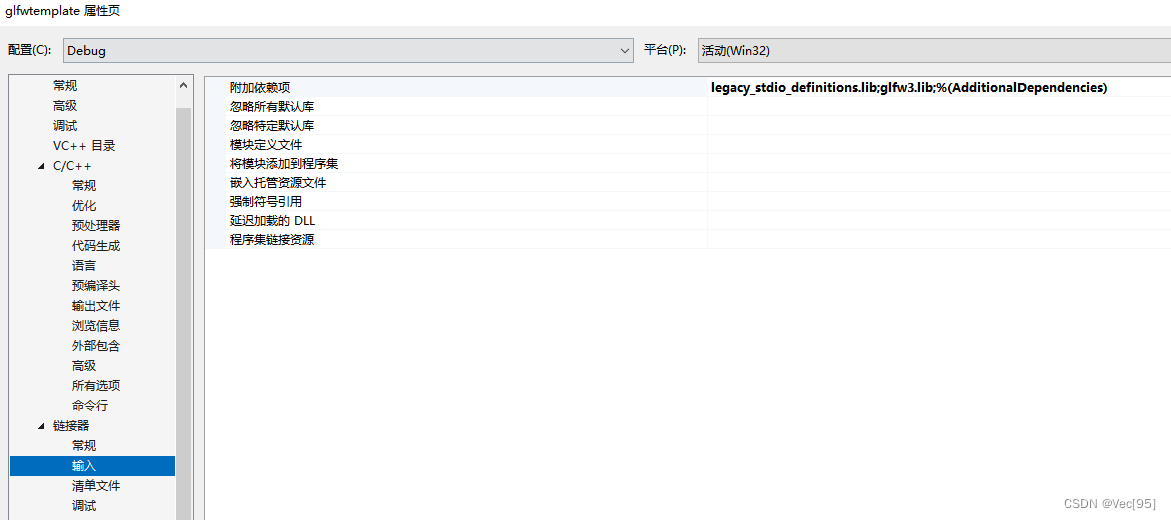
VS环境配置: /JMC /ifcOutput "Debug\" /GS /analyze- /W3 /Zc:wchar_t /I"D:\Template\glfwtemplate\glfwtemplate\assimp" /I"D:\Template\glfwtemplate\glfwtemplate\glm" /I"D:\Template\glfwtemplate\glfwtemplate\LearnOp…

接口测试流程及测试点!
一、什么时候开展接口测试
1.项目处于开发阶段,前后端联调接口是否请求的通?(对应数据库增删改查)--开发自测
2.有接口需求文档,开发已完成联调(可以转测),功能测试展开之前
3.专…
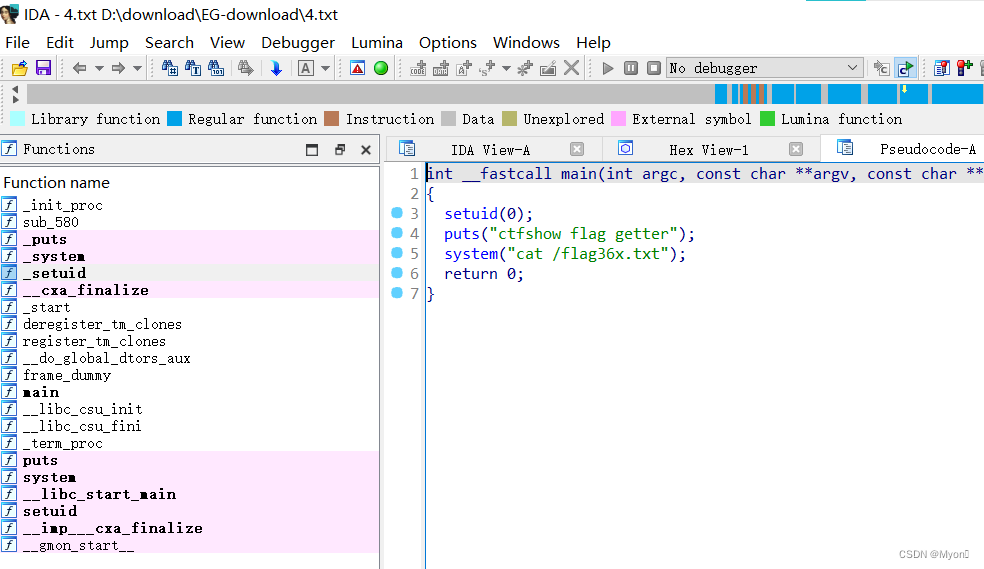
ctfshow-web入门-命令执行(web75-web77)
目录
1、web75
2、web76
3、web77 1、web75
使用 glob 协议绕过 open_basedir,读取根目录下的文件,payload:
c?><?php $anew DirectoryIterator("glob:///*");
foreach($a as $f)
{echo($f->__toString(). );
}
ex…
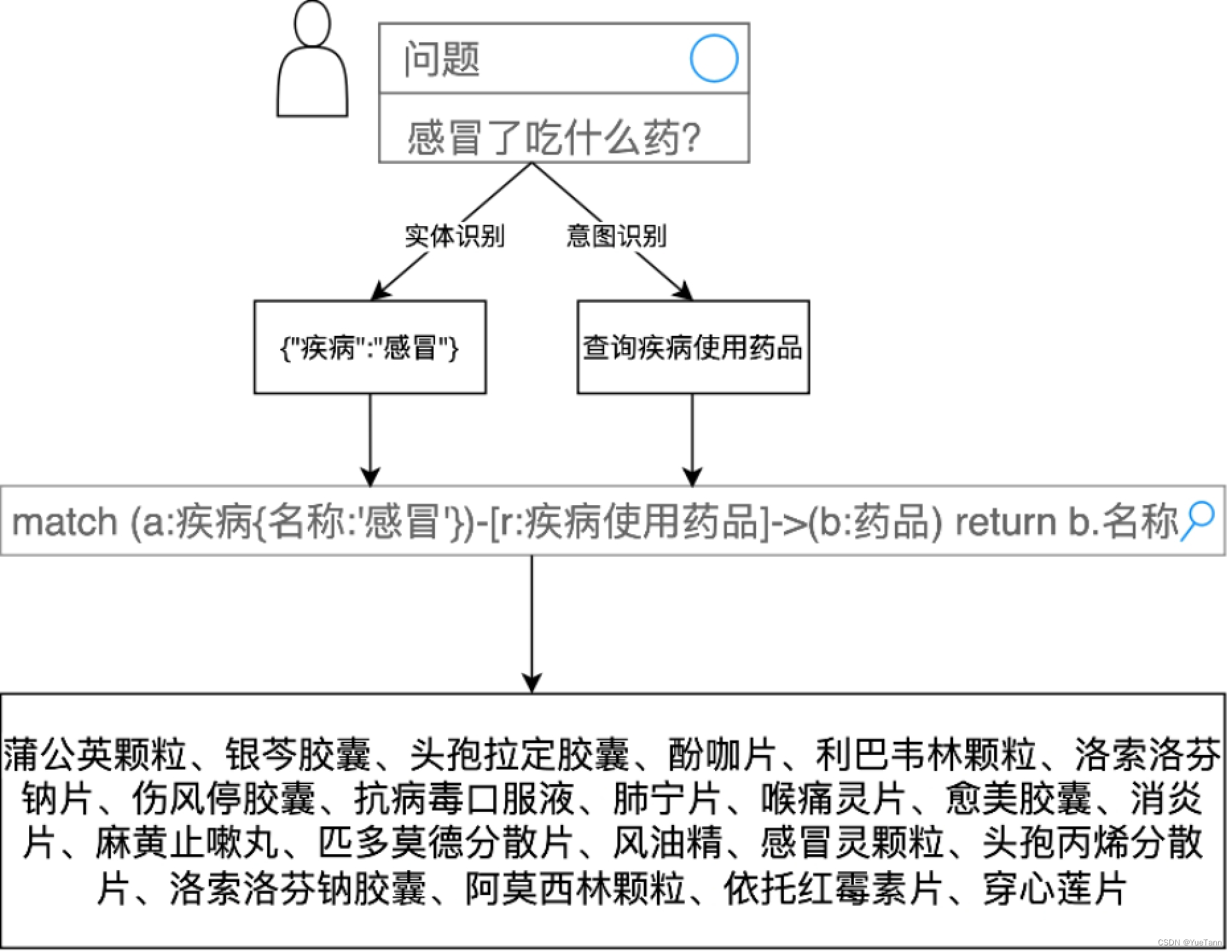
如何用大模型RAG做医疗问答系统
代码参考
https://github.com/honeyandme/RAGQnASystemhttps://github.com/LongxingTan/open-retrievals
TLDR
if 疾病症状 in entities and 疾病 not in entities:sql_q "match (a:疾病)-[r:疾病的症状]->(b:疾病症状 {名称:%s}) return a.名称" % (entitie…
Cosine 余弦相似度并行计算的数学原理与Python实现
背景
Cosine 我在LLM与RAG系列课程已经讲了很多次了,这里不在熬述,它在LLM分析中,尤其是在语义相似度的计算中至关重要,在dot attention机制中,也会看到他的身影。这里讲的是纯数学上的运算与python是如何运用相关库进…

鸿蒙开发Ability Kit(程序访问控制):【向用户申请单次授权】
申请使用受限权限
受限开放的权限通常是不允许三方应用申请的。当应用在申请权限来访问必要的资源时,发现部分权限的等级比应用APL等级高,开发者可以选择通过ACL方式来解决等级不匹配的问题,从而使用受限权限。
举例说明,如果应…
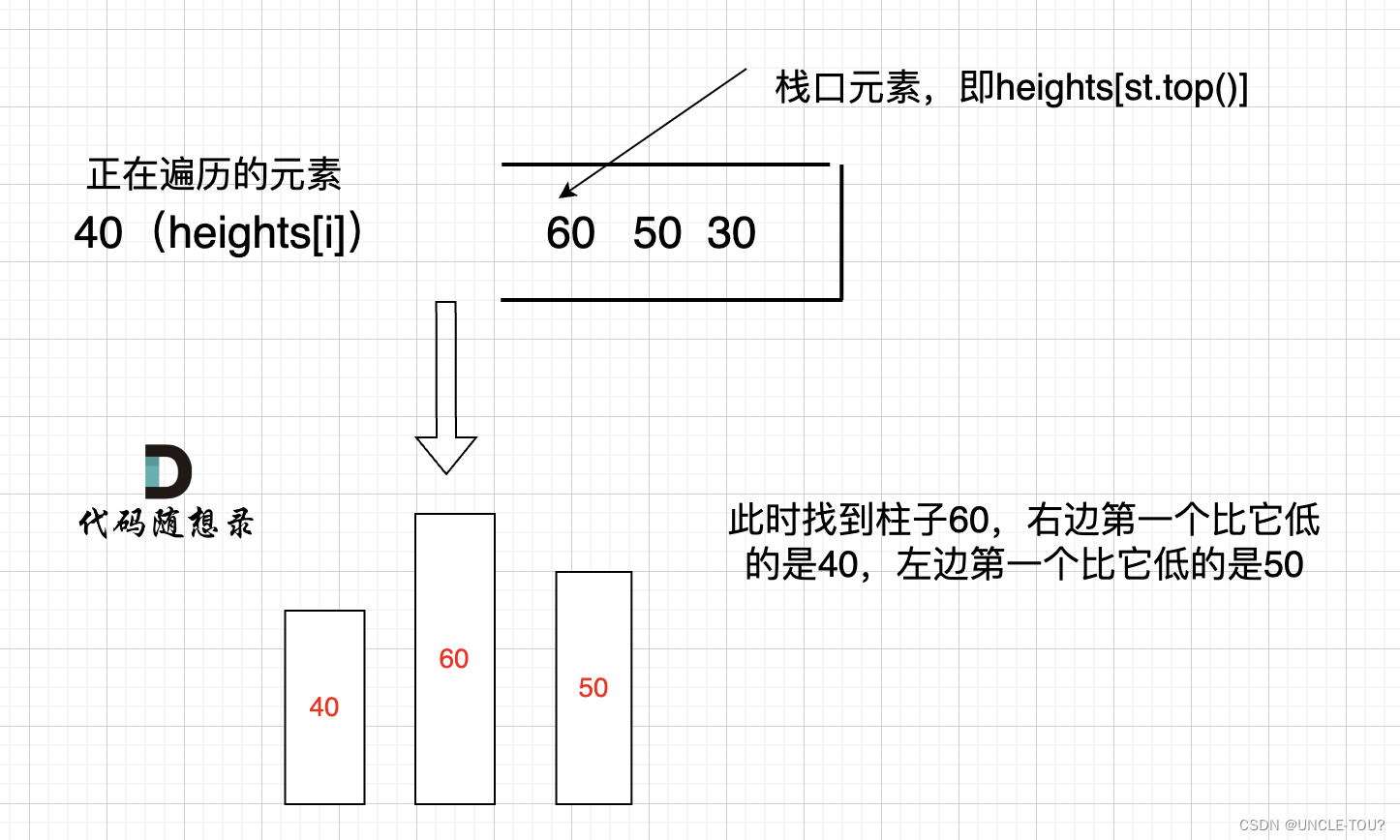
代码随想录算法训练营第55天(py)| 单调栈 | 42. 接雨水*、84.柱状图中最大的矩形
42. 接雨水*
力扣链接 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
思路1 暴力
按列来计算。每一列雨水的高度,取决于,该列 左侧最高的柱子和右侧最高的柱子中,…

【记录】IDEA2023的激活与安装
前言:
记录IDEA2023的激活与安装
第一步:官网下载安装包:
下载地址:https://www.jetbrains.com/idea/download/other.html
这个最好选择2023版本,用着很nice。
安装步骤就不详解了,无脑下一步就可以了…

09 - matlab m_map地学绘图工具基础函数 - 绘制区域填充、伪彩色、加载图像和绘制浮雕效果的有关函数
09 - matlab m_map地学绘图工具基础函数 - 绘制区域填充、伪彩色、加载图像和绘制浮雕效果的有关函数 0. 引言1. 关于m_pcolor2. 关于m_image3. 关于m_shadedrelief4. 关于m_hatch5. 结语 0. 引言 本篇介绍下m_map中区域填充函数(m_hatch)、绘制伪彩色图…
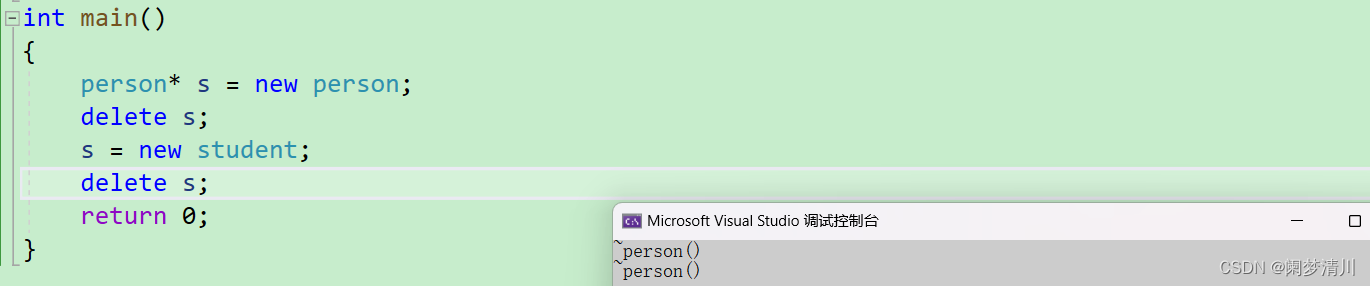
C++多态~~的两个特殊情况
目录 1.多态的概念
2.简单认识
(1)一个案例
(2)多态的两个满足条件
(3)虚函数的重写
(4)两个特殊情况 1.多态的概念
(1)多态就是多种形态; …


AI绘画工具Midjourney:和Discord互相成就
前言 提到文生图,很多人都会想到植根于根植于Discord社区的Midjourney,本篇文章就基于作者的使用体验思考,并结合了Discord来对Midjourney进行探讨,感兴趣的朋友一起来看看吧。 如果要说现在最火的文生图,不得不说到Mi…
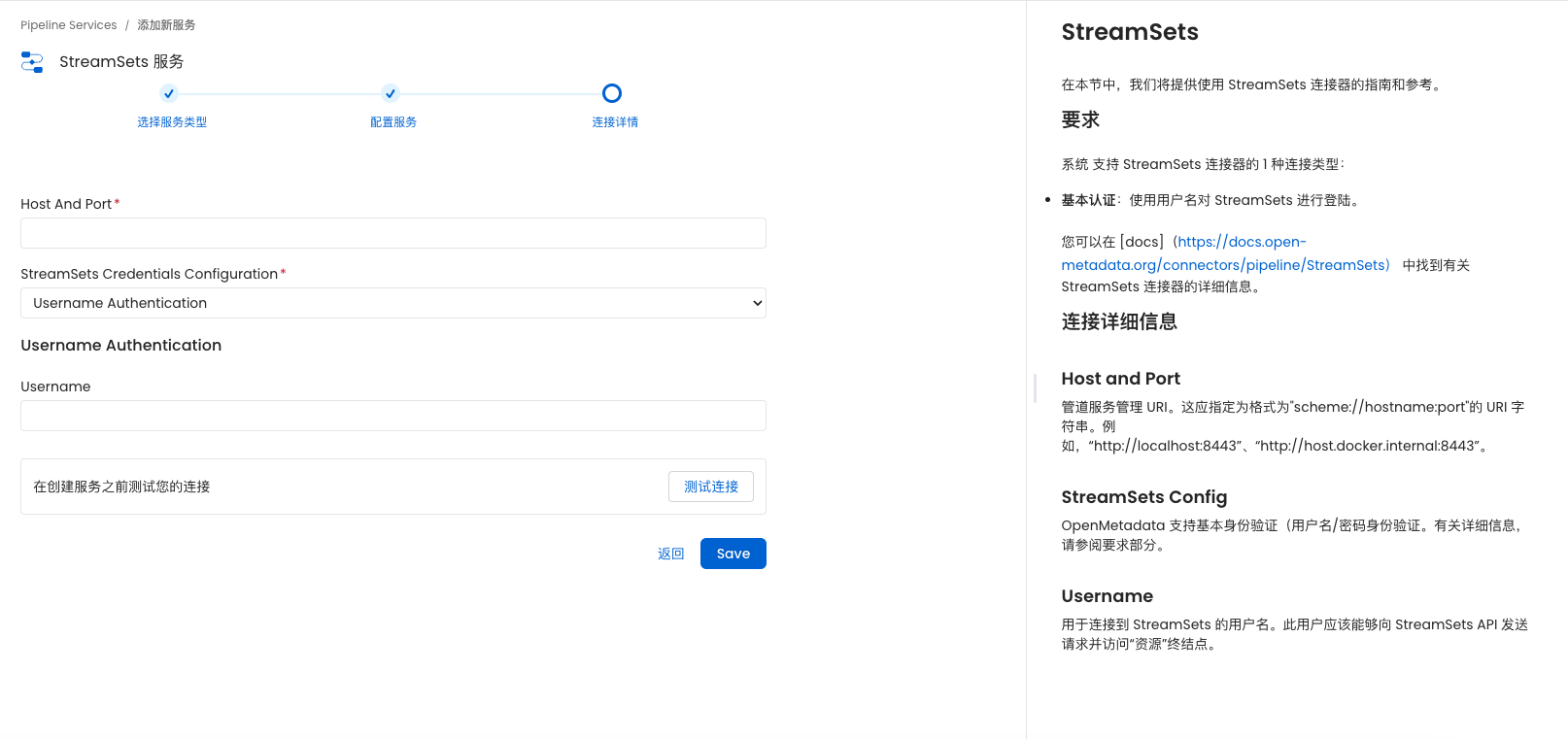
openmetadata1.3.1 自定义连接器 开发教程
openmetadata自定义连接器开发教程
一、开发通用自定义连接器教程
官网教程链接:
1.https://docs.open-metadata.org/v1.3.x/connectors/custom-connectors
2.https://github.com/open-metadata/openmetadata-demo/tree/main/custom-connector
(一&…

本周波动预警!7月将一路上涨,牛市“复苏“?低于6万美元的比特币,是熊市陷阱吗?
比特币在第三季度伊始发出了一些积极信号。随着上周末的涨势,BTC/USD最高一度达到63818美元,这让人对比特币能否重拾牛市信心满怀希望。不过,在冲破关键阻力位64000美元之前,市场参与者仍保持谨慎态度。比特币要想维系开头的牛市态…
掌握React与TypeScript:从零开始绘制中国地图
最近我需要使用reactts绘制一个界面,里面需要以中国地图的形式展示区块链从2019-2024年这五年的备案以及注销情况,所以研究了一下这方面的工作,初步有了一些成果,所以现在做一些分享,希望对大家有帮助! 在这…
使用Qt制作一个简单的界面
1、创建工程
步骤一: 步骤二: 步骤三: 选择 build system,有qmake、CMake 和 Qbs 三个选项。 CMake 很常用,功能也很强大,许多知名的项目都是用它,比如 OpenCV 和 VTK,但它的语法繁…
heic格式转化jpg如何操作?heic转jpg,分享6款图片转化器!
随着苹果iOS 11系统的推出,HEIC格式作为一种新的图片格式逐渐走进大众视野,heic格式在保证照片质量的同时,能显著减少系统存储空间的占用。然而,这也给非苹果用户带来了一些困扰,因为HEIC格式的图片在Windows系统上并不…

深入理解C# log4Net日志框架:功能、使用方法与性能优势
文章目录 1、log4Net的主要特性2、log4Net框架详解配置日志级别 3、log4Net的使用示例4、性能优化与对比5、总结与展望 在软件开发过程中,日志记录是一个不可或缺的功能。它可以帮助开发者追踪错误、监控应用程序性能,以及进行调试。在C#生态系统中&…