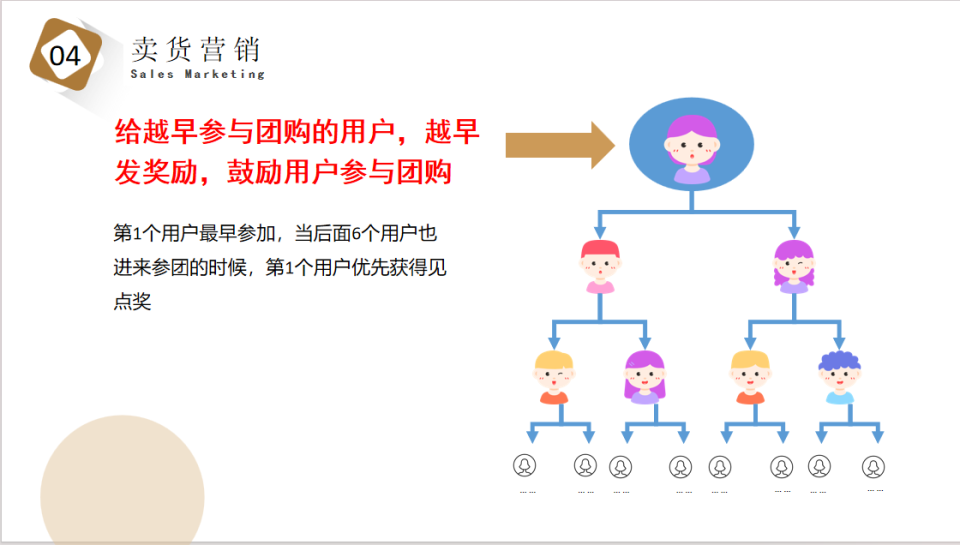
最近完成了一个文旅行业信息聚合的小应用,实现仅从一个入口了解全行业的信息动态,不用一个一个翻看各网站,节省了不少检索时间。
一、基本思路
明确数据来源。基于前述目标,确定数据源为文化和旅游部管理部门官网,比如各省厅网站、各副省级城市网站,文化和旅游管理部门直属单位网站,中国文化报电子版,中国旅游报电子版等,目前大约有60多个网站。
写采集程序。日常使用 Win 系统+ Edge 浏览器,故采集程序使用 Python,配合 Selenium 4 来实现。获取到的数据(标题、链接),存储到 Sqlite3 数据库。
写展示网页。将抓取到的数据进行展示,打开页后,点击某个标题,即可跳转信息源网站,查看对应信息。
二、代码框架
整个项目代码框架如下
├├─anhui_msg.py // 爬虫1├─get_bozhou.py // 爬虫2├─provinces_msg.py // 爬虫3├─province_level_cities.py // 爬虫4├─luyoubao_news.py // 爬虫5├─wenhuabao_news.py // 爬虫6├─newsspider.py // 爬虫共用代码├─txt2db.py // 抓取信息转存数据库├─auto_run.bat // 自动抓取、转存、更新脚本├─ahwlmsg.db // 保存所有数据的数据库文├─<DIR> html // 展示网页代码├─<DIR> provinces // 保存各省文化和旅游厅网站信息├─<DIR> province_level_cities // 保存副省级城市文化旅部网站信息├─<DIR> txt // 保存安徽省市文化和旅部网站信息
html 目录下的文件如下:
├├─<DIR>static // 内含 CSS、JS、图标├─<DIR>templates // 网页前端模板├─run.bat // 本地自动运行网站脚本├─ahwlmsg.db // 保存所有数据的数据库文件├─generate_html.py // 网页后端
三、技术栈
采集程序: Python + Selenium4 + SQL
网页前端: Html + CSS + JQuery
网页后端 Python + Flask + SQL
四、代码实现
(一)网页信息获取
信息采集代码总体思路大体一致。均使用 Selenium 模拟浏览器打开相应网站,获取链接后,全部保存为本地文件;然后进一步梳理存入数据库。
以获取副省级城市文化旅游网站信息为例。基本代码如下:
def grasp_all_a(url, driver):
assert(driver)
driver.get(url)
print("\033[1;31;40m looking {}... \033[0m".format(url))
try:
# 等待网页打开15秒,直至可以定位到<a>标签。
WebDriverWait(driver, 15).until(EC.visibility_of_element_located((By.TAG_NAME,'a')))
except:
print("timeout")
# 获取网页上所有的<a>标签。
a_tags = driver.find_elements(By.TAG_NAME, "a")
#逐个分析<a>标签,并分别处理。
filename = get_filename(url).rstrip('/')
with open("./province_level_cities/" + filename+".txt", 'w', encoding='utf-8') as f:
for tag in a_tags:
title = tag.get_attribute('title').replace('\n','').strip(' ')
href = tag.get_attribute('href')
if title and href:
if filename not in href:
continue
elif 'javascript' not in href:
f.write(title + "\t" + href + "\n" )
elif href:
if 'javascript' in href:
continue
else:
f.write(tag.text.replace('\n','').strip(" ") + "\t" + href + "\n" )
driver.quit()
实现逻辑分三步:
1. 准备工作。
2. 打开网页后,获取该网页上所\<A>标签。
3. 对每一个\<A>标签的title和href属性进行分析:没有title和href则跳出;同时存在时,一看href是不是指向本网站,二看href中是不是包括JavaScript,如果链接指向本网站且链接中不包括JavaScript,就把A标签的title、href属性保存到文件里;只有href属性且链接中不包括JavaScript时,做一点清理后,将href保存到文件中。
(二)网页避坑设置
由于各种原因,并非所有网页数据都能成功获取,所以在打开网页前需要做一些设置。通过反复调试,以下代码可满足多数情况下的需要。
def ready_to_grasp():
path = r"d:\\webdriver\\msedgedriver.exe"
if os.path.exists(path):
sys.path.append(path)
else:
print("Please install webdriver first.\n")
exit(-1)
options = Options()
options.add_argument('headless')
options.add_argument('disable-gpu')
options.add_argument('no-sandbox')
options.add_argument('incognito')
options.add_argument("disable-blink-features=AutomationControlled")
options.binary_location = r"C:\\Program Files (x86)\\Microsoft\\Edge\\Application\\msedge.exe"
driver = webdriver.Edge(options=options)
driver.execute_cdp_cmd('Network.setUserAgentOverride', \
{"userAgent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 \
Safari/537.36 Edg/119.0.0.0'
})
return driver以上代码为三部分:一是准备工作;二是设置选项;三是调用执行。代码本身可以说明。
(三)网页展示
找个看着比较顺眼的网站,保存到本地,去掉不需要的功能,确定前端样式,形成网页模板。
后端主要是响应网页上的操作,查询数据库,并将查询结果从后端向前端传送等。

(最终网页效果)
五、结语
这个周末项目式的“小雪球”,断断续续重写了三遍。目前,程序每天在跑,每天在用,可浏览最近一周之内各省、副省级城市和安徽省各市文旅网站发布的信息资讯。
期间,也尝试接入目前流行的大模型。比如,在鼠标移到网页上某个标题时,自动连接大模型,在不跳转页面的情况下,对其内容进行摘要。