数据分析与挖掘案例-电子商务网站用户行为分析及服务推荐

文章目录
- 数据分析与挖掘案例-电子商务网站用户行为分析及服务推荐
- 1. 背景与挖掘目标
- 2. 分析方法与过程
- 2.1 分析步骤与流程
- 2.2 数据抽取
- 2.3 数据探索分析
- 1. 分析网页类型
- 2. 分析网页点击次数
- 2.4 数据预处理
- 1. 删除不符合规则的网页
- 2. 还原翻页网址
- 3. 筛去浏览次数不满2次的用户
- 4.划分数据集
- 2.5 构建智能推荐模型
- 1. 基于物品的协同过滤算法的基本概念
- 2. 优缺点分析
- 3. 模型构建
- 4. 模型评价
1. 背景与挖掘目标
某法律网站是北京一家电子商务类的大型法律资讯网站,致力于为用户提供丰富的法律信息与专业咨询服务,本案例主要是为律师与律师事务所提供互联网整合营销解决方案。
随着企业经营水平的提高,其网站访问量逐步增加,随之而来的数据信息量也在大幅增长。带来的问题是用户在面对大量信息时无法快速获取需要的信息,使得信息使用效率降低。用户在浏览搜寻想要的信息过程中,需要花费大量的时间,这种情况的出现造成了用户的不断流失,对企业造成巨大的损失。
为了节省用户时间并帮助用户快速找到感兴趣的信息,利用网站海量的用户访问数据,研究用户的兴趣偏好,分析用户的需求和行为,引导用户发现需求信息,将长尾网页准确的推荐给所需用户,帮助用户发现他们感兴趣但很难发现的网页信息。总而言之,智能推荐服务可以为用户提供个性化的服务,改善用户浏览体验,增加用户黏度,从而使用户与企业之间建立稳定交互关系,实现客户链式反应增值。
2. 分析方法与过程
随着互联网领域的电子商务、线上服务、线上交易等网络业务的普及,大量的信息聚集起来形成海量信息。用户想要从海量信息中快速准确的寻找到感兴趣的信息变得越来越困难,尤其在电子商务领域问题更加突出。搜索引擎的诞生在一定程度上缓解了信息过载问题,用户通过输入关键词,搜索引擎就会返回给用户与输入的关键词相关的信息。但是在用户无法准确描述需求时,搜索引擎就无能为力了。
与搜索引擎不同,推荐系统并不需要用户提供明确的需求,它是通过分析用户的历史行为从而主动推荐给用户能够满足他们兴趣和需求的信息。因此,对于用户而言推荐系统和搜索引擎是两个互补的工具。同时,在电子商务领域中推荐技术可以起到以下作用。
1.帮助用户发现其感兴趣的物品,节省用户时间、提升用户体验。
2.提高用户对电子商务网站的忠诚度。推荐系统能够准确地发现用户的兴趣点,将合适的资源推荐给用户,用户容易对该电子商务网站产生依赖,从而提升用户与网站之间的黏度。
为了解决上述问题,结合本案例提供的原始数据情况,可以分析如下目标。
1.按地域分析用户访问网站的时间、访问内容、访问次数等主题,了解用户的浏览行为,和感兴趣的网页内容。
2.根据用户的访问记录对用户进行个性化推荐服务。
2.1 分析步骤与流程
为了帮助用户从海量的信息中快速发现感兴趣的网页,采用协同过滤算法进行推荐,推荐系统原理如下图所示。
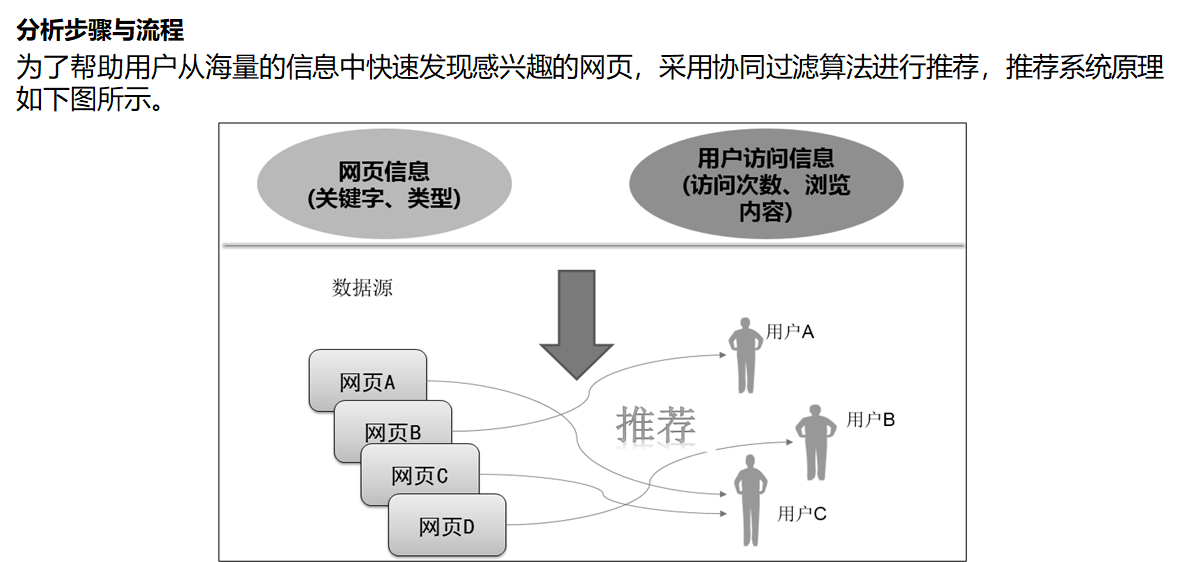
由于用户访问网站的数据记录较大,若不进行分类处理直接采用协同过滤算法进行推荐,会存在以下问题。
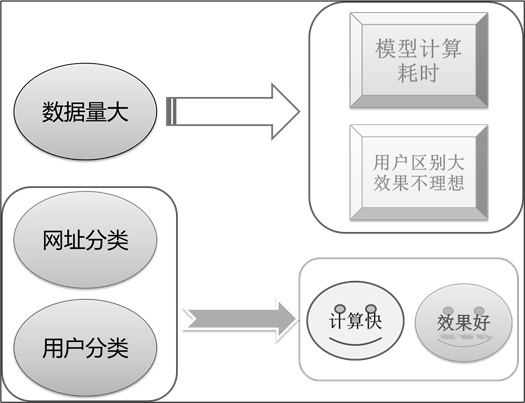
•数据量大说明物品数与用户数很多,在模型构建用户与物品的稀疏矩阵时,模型计算需要消耗大量的时间,并且会造成设备内存空间不足的问题。
•不同的用户关注信息不同,其推荐结果不能满足用户个性化需求。
为了避免上述问题,需要对用户访问记录进行分类处理与分析,如下图所示。在用户访问记录日志中,没有用户访问网页时间的长短的记录,不能根据用户在网页的停留时间的方法判断用户是否对浏览网页感兴趣。采用基于用户浏览网页的类型的方法进行分类,然后对每个类型中的内容进行智能推荐。
采用上述的分析方法与思路,结合原始数据及分析目标,整理的网站智能推荐流程如下图所示。
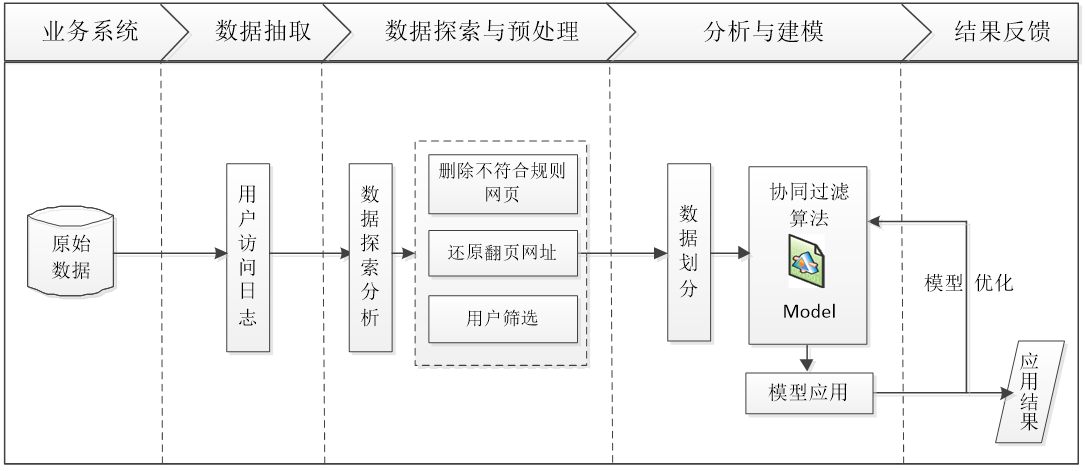
1.从系统中获取用户访问网站的原始记录。
2.分析用户访问内容,用户流失及用户分类等。
3.对数据进行预处理,包含数据去重,数据变换,数据分类等过程。
4.以用户访问html后缀的网页为关键条件,对数据进行处理。
5.对比多种推荐算法的效果,选择效果较好的模型。通过模型预测,获得推荐结果。
2.2 数据抽取
以用户的访问时间为条件,选取三个月内(2015-02-01~2015-04-29)用户的访问数据作为原始数据集。由于每个地区的用户访问习惯以及兴趣爱好存在差异性,因此,抽取广州地区的用户访问数据进行分析,其数据量总共有837450条记录,其中包括用户号、访问时间、来源网站、访问页面、页面标题、来源网页、标签、网页类别、关键词等。
在数据抽取过程中,由于数据量较大且存储在数据库中,为了提高数据处理的效率,采取使用Python读取数据库的操作方式。本案例用到的数据库为开源数据库MySQL-community-5.6.39.0)。安装数据库后导入本案例的数据原始文件7law.sql,然后可以利用Python对数据库进行相关的操作,其中Python连接MySQL数据库及对数据库进行操作。
import os
import pandas as pd
# 修改工作路径到指定文件夹
os.chdir("D:/chapter11/demo")
# 第一种连接方式
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:123@192.168.31.140:3306/test?charset=utf8')
sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)
# 第二种连接方式
import pymysql as pm
con = pm.connect('localhost','root','123456','test',charset='utf8')
data = pd.read_sql('select * from all_gzdata',con=con)
con.close() #关闭连接
# 保存读取的数据
data.to_csv('./tmp/all_gzdata.csv', index=False, encoding='utf-8')
2.3 数据探索分析
原始数据集中包括用户号、访问时间、来源网站、访问页面、页面标题、来源网页、标签、网页类别和关键词等信息,需要对原始数据进行网页类型、点击次数、网页排名等各个维度的分布分析,了解用户浏览网页行为及关注内容,获得数据内在的规律。
1. 分析网页类型
1.对原始数据中用户点击的网页类型进行统计分析,结果如下图。
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:root123@127.0.0.1:3306/test?charset=utf8')
sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)
# 分析网页类型
counts = [i['fullURLId'].value_counts() for i in sql] #逐块统计
counts = counts.copy()
counts = pd.concat(counts).groupby(level=0).sum() # 合并统计结果,把相同的统计项合并(即按index分组并求和)
counts = counts.reset_index() # 重新设置index,将原来的index作为counts的一列。
counts.columns = ['index', 'num'] # 重新设置列名,主要是第二列,默认为0
counts['type'] = counts['index'].str.extract('(\d{3})') # 提取前三个数字作为类别id
counts_ = counts[['type', 'num']].groupby('type').sum() # 按类别合并
counts_.sort_values(by='num', ascending=False, inplace=True) # 降序排列
counts_['ratio'] = counts_.iloc[:,0] / counts_.iloc[:,0].sum()
print(counts_)
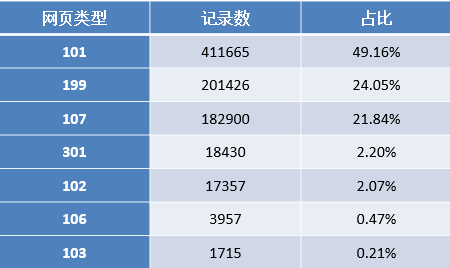
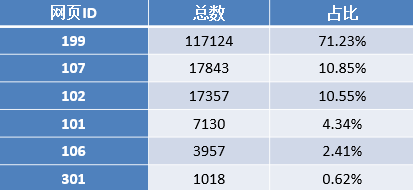
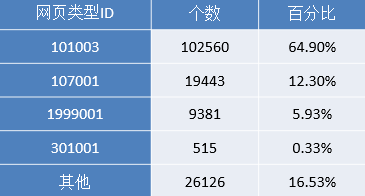
通过上表可以发现,点击与咨询相关(网页类型为101,http://www..com/ask/)的记录占了49.16%,其他的类型(网页类型为199)占比24%左右,知识相关(网页类型为107,http://www..com/info/)占比22%左右。
2.根据统计结果对用户点击的页面类型进行排名,依次为咨询相关、知识相关、其他方面的网页、法规(类型为301)、律师相关(类型为102)。进一步对咨询类别内部进行统计分析,其结果如下表所示。
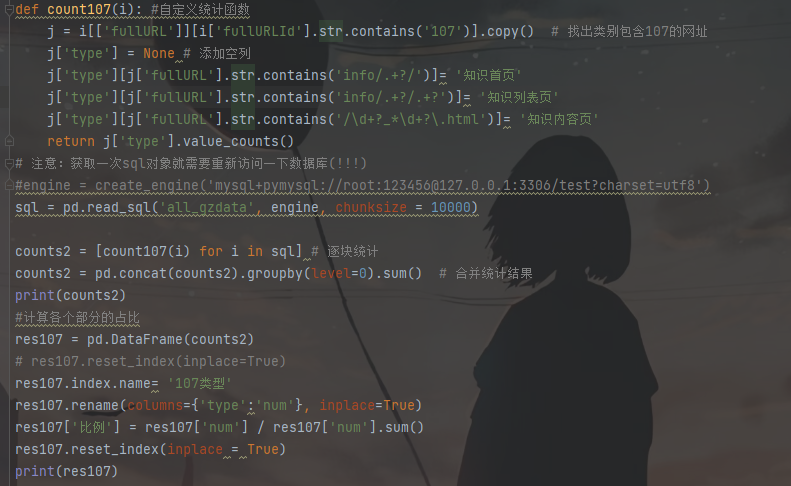
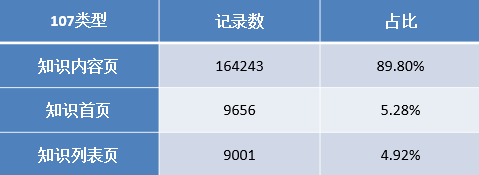
浏览咨询内容页(101003)记录是最多,其次是咨询列表页(101002)和咨询首页(101001)。初步分析可以得知用户都喜欢通过浏览问题的方式找到自己需要的信息,而不是以提问的方式或者查看长篇知识的方式。
3.对原始数据的网址中存在带“?”的数据进行统计,结果如下图所示。
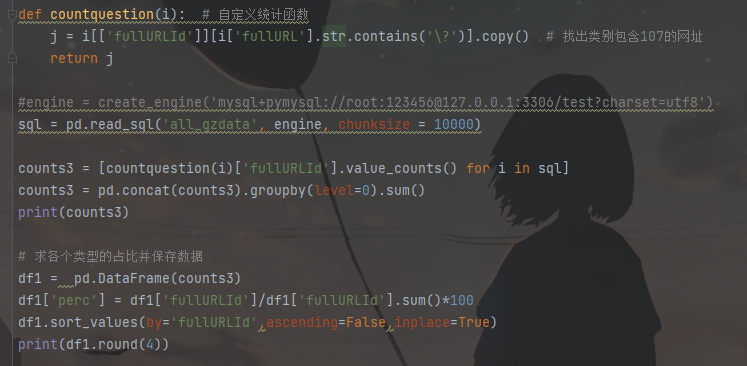
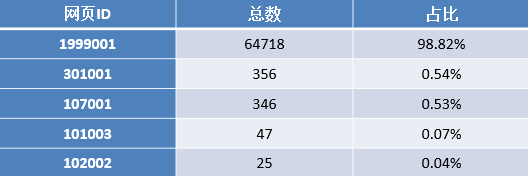
网址中带有“?”的一共有65492条记录,且不仅仅出现在其他类别中,同时也会出现在咨询内容页和知识内容页中,但在其他类型(1999001)中占比最高,达到98.82%。因此需要进一步分析其类型内部的规律。
4.其他类型的统计结果如表所示
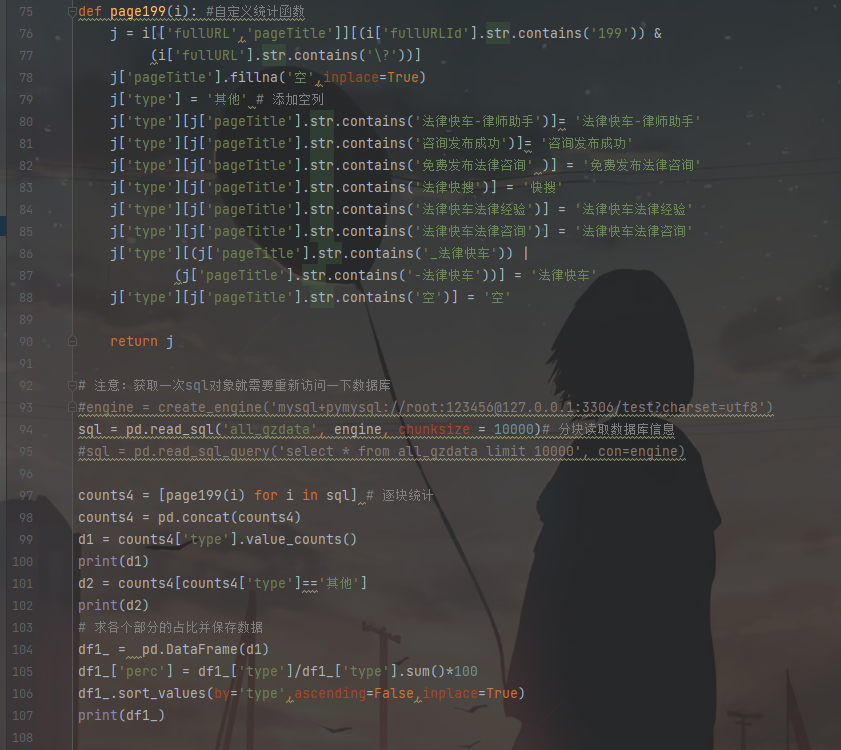
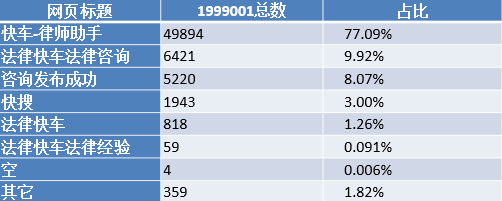
在1999001类型中,标题为“快车-律师助手”的类信息占比77.09%,这类页面是律师的登录页面。标题为“发布成功”类信息占比8.07%,这类页面是自动跳转页面。其他类型页面大部分为http://www.****.com/ask/question_9152354.html?&from=androidqq的类型网页,根据业务了解该类网页为被分享过的网页,这类网页需要对其进行处理,处理方式为截取网址中“?”前面的网址并还原网址类型。
5.访问记录中有一部分用户并没有点击具体的网页,这类网页以.html后缀结尾,且大部分是目录网页,这样的用户可以称为“瞎逛”,总共有165654条记录,统计结果如表所示。
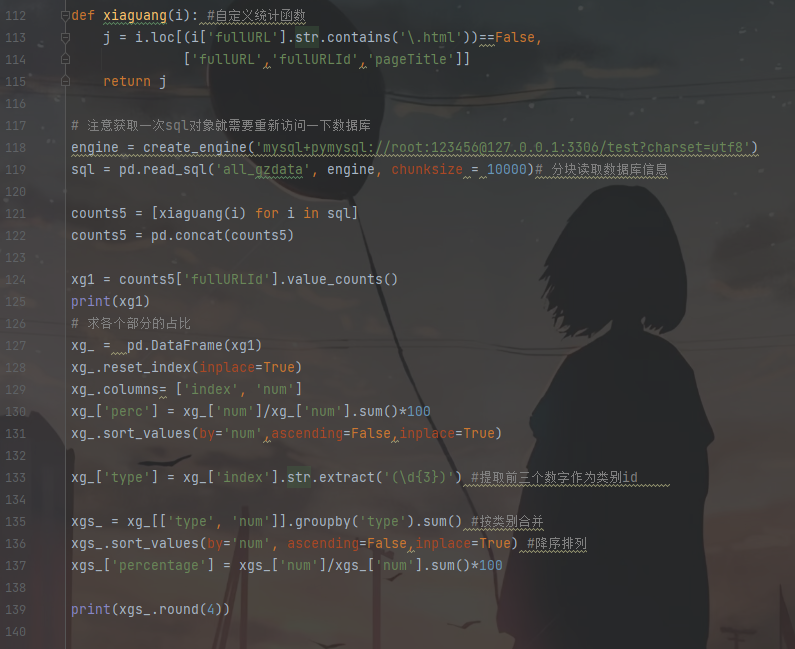
通过表可以看出,小部分网页类型是与知识、咨询相关的,大部分网页类型是地区、律师和事物所相关的,这类用户可能是找律师服务的,或是“瞎逛”的。
综合以上分析,得到一些与分析目标无关数据的规则,记录这些规则,有利于在数据清洗阶段对数据进行清洗操作。
1.咨询发布成功页面。
2.中间类型网页(带有midques_关键字)。
3.网址中带有“?”类型,无法还原其本身类型的快搜网页。
4.重复数据(同一时间同一用户,访问相同网页)。
5.其他类别的数据(主网址不包含关键字)。
6.无点击“.html”行为的用户记录。
7.律师的行为记录(通过快车-律师助手判断)。
2. 分析网页点击次数
1.统计原始数据用户浏览网页次数的情况,结果如表所示
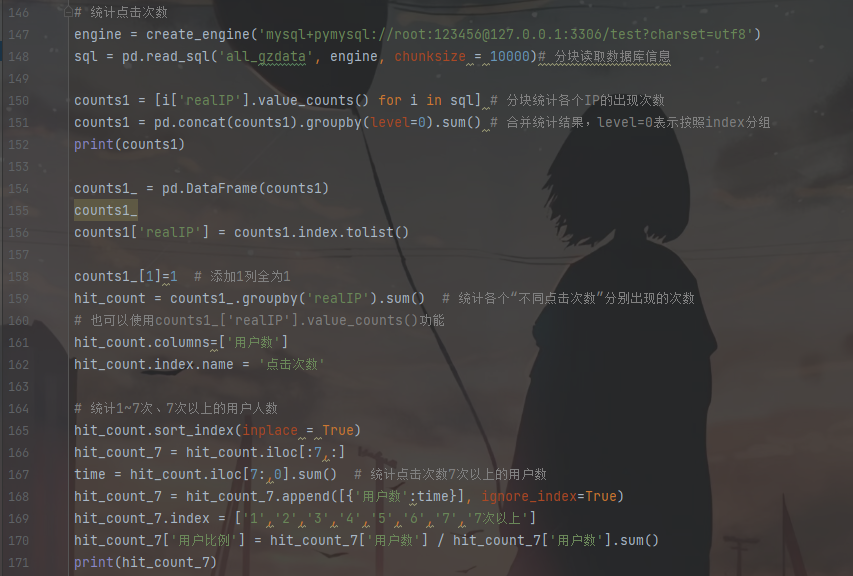
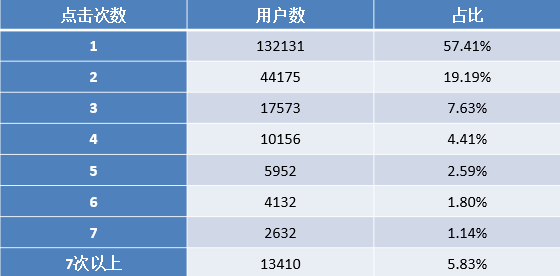
浏览1次的用户最多,占所有用户58%左右。
2.分析浏览次数为1次的用户,结果如表所示。
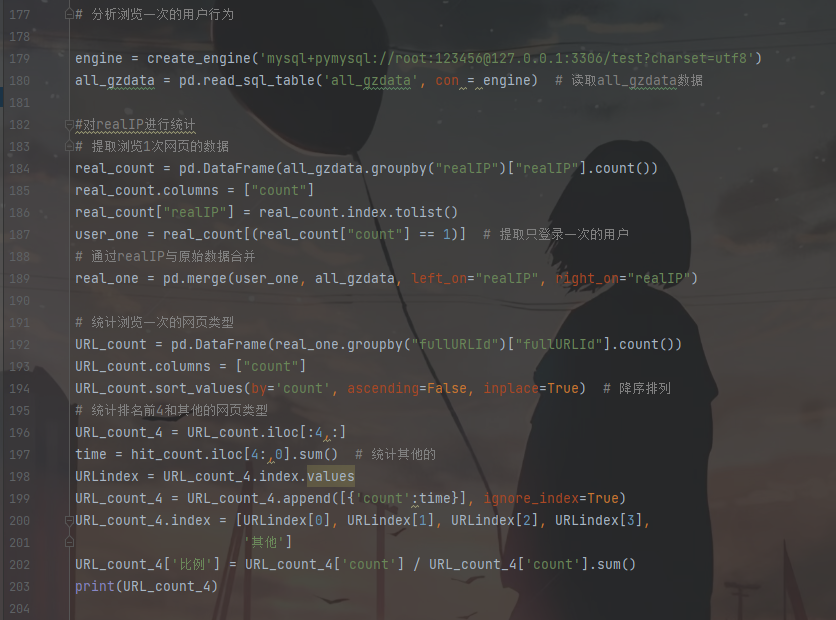
分析浏览次数为1次的用户可知,问题咨询页占比75%,知识页占比16%,这些记录均是通过搜索引擎进入。由此分析得出两种可能。
-
用户为流失用户,在问题咨询与知识页面上没有找到相关的需要。
-
用户找到其需要的信息,因此直接退出。
综合这些情况,将点击1次的用户行为定义为网页的跳出率。为了降低网页的跳出率,就需要对这些网页进行针对用户的个性化推荐,帮助用户发现其感兴趣或者需要的网页。
3.统计浏览次数为1次的用户浏览的网页的总浏览次数


2.4 数据预处理
通过数据探索发现知识类网页的浏览次数在全部类型的网页中占比较高,仅次于咨询类和其他类。知识类网页中的婚姻类网页是较为热门的网页,故选取婚姻类的网页进入模型进行推荐。
对原始数据进行探索分析时,发现与分析目标无关的数据和不符合建模输入要求的数据,即构建模型需要预处理的数据。针对此类数据进行数据清洗、数据去重、数据变换以及特征选取等操作,使数据满足构建推荐系统模型的输入要求。
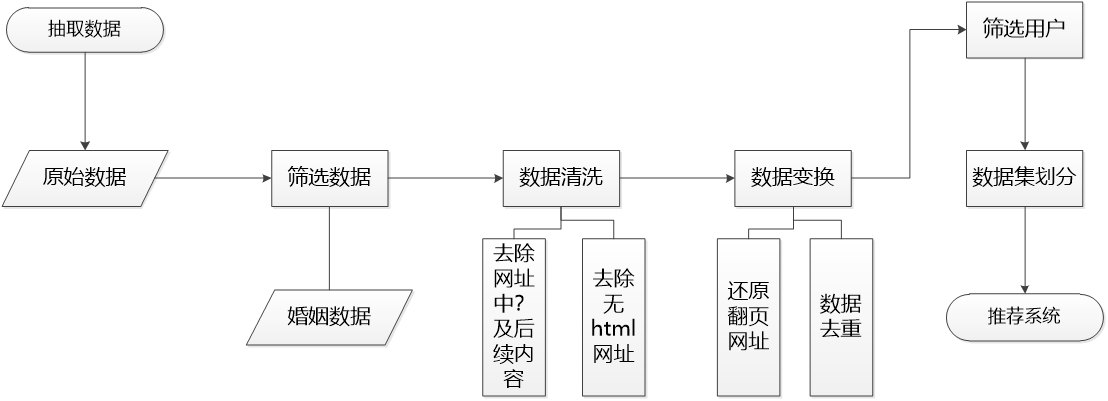
(1) 清除通过数据清洗将数据探索分析过程中发现与目标无关的数据。
(2) 识别翻页的网址,并对其进行还原,然后对用户访问的页面进行去重操作。
(3) 筛选掉浏览网页次数不满2次的用户。
(4) 将数据集划分为训练集与测试集。
1. 删除不符合规则的网页
分析原始数据发现不符合规则的网页包括中间页面的网址、咨询发布成功页面、律师登录助手的页面等,需要对其进行删除处理。
清洗后数据仍然存在大量的目录网页(可理解为用户浏览信息的路径),这类网页不但对构建推荐系统没有作用,反而会影响推荐的结果准确性,同样需要处理。
# 读取数据
con = pm.connect('localhost','root','123456','test',charset='utf8')
data = pd.read_sql('select * from all_gzdata',con=con)
con.close() # 关闭连接
# 取出107类型数据
index107 = [re.search('107',str(i))!=None for i in data.loc[:,'fullURLId']]
data_107 = data.loc[index107,:]
# 在107类型中筛选出婚姻类数据
index = [re.search('hunyin',str(i))!=None for i in data_107.loc[:,'fullURL']]
data_hunyin = data_107.loc[index,:]
# 提取所需字段(realIP、fullURL)
info = data_hunyin.loc[:,['realIP','fullURL']]
# 去除网址中“?”及其后面内容
da = [re.sub('\?.*','',str(i)) for i in info.loc[:,'fullURL']]
info.loc[:,'fullURL'] = da # 将info中‘fullURL’那列换成da
# 去除无html网址
index = [re.search('\.html',str(i))!=None for i in info.loc[:,'fullURL']]
index.count(True) # True 或者 1 , False 或者 0
info1 = info.loc[index,:]
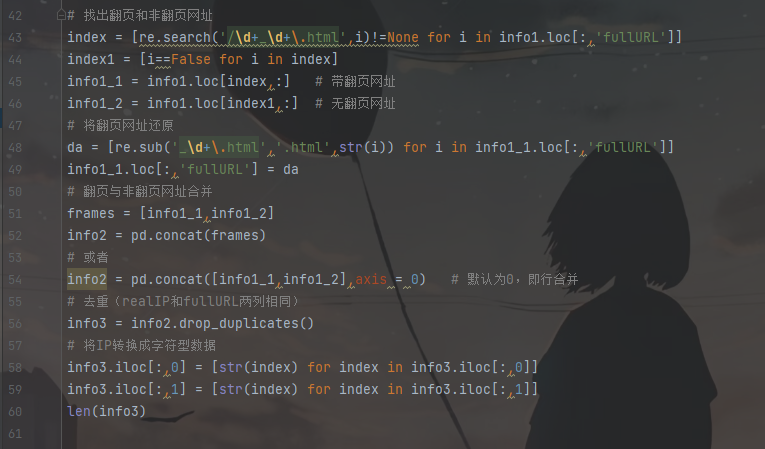
2. 还原翻页网址
主要对知识相关的网页类型数据进行分析,处理翻页情况最直接的方法是将翻页的网址删掉,但是用户是通过搜索引擎进入网站,访问入口不一定是原始页面,采取删除方法会损失大量有效数据,影响推荐结果。因此对该类网页的处理方式首先识别翻页的网址,然后对翻页的网址进行还原,最后针对每个用户访问的页面进行去重的操作。
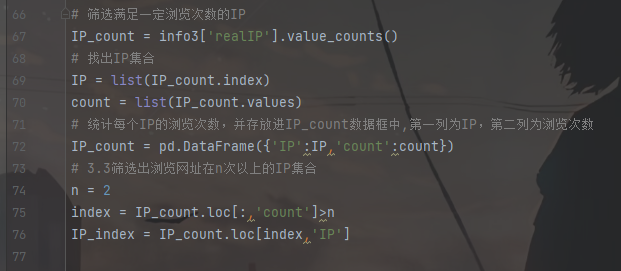
3. 筛去浏览次数不满2次的用户
由数据探索的结果可知存在大量仅浏览一次就跳出的用户,浏览次数在2次及以上的用户的浏览记录更适合用于推荐,而浏览次数仅1次的用户的浏览记录进入推荐模型会影响推荐模型的效果,因此需要筛去浏览次数不满2次的用户。
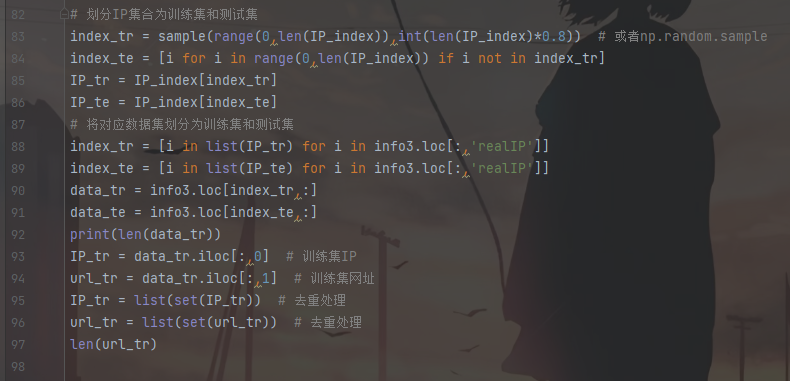
4.划分数据集
将数据集按8:2的比例划分为训练集和测试集。
2.5 构建智能推荐模型
推荐系统(Recommender System)是解决信息过载的有效手段,也是电子商务服务提供商提供个性化服务重要的信息工具。在实际构造推荐系统时,并不是采用单一的某种推荐方法进行推荐。大部分推荐系统都结合多种推荐方法将推荐结果进行组合,最后得出最优的推荐结果。在组合推荐结果时,可以采用串行或者并行的方法。
1. 基于物品的协同过滤算法的基本概念
基于物品的协同过滤系统的一般处理过程,分析用户与物品的数据集,通过用户对案例的浏览与否(喜好)找到相似的物品,然后根据用户的历史喜好,推荐相似的案例给目标用户。基于物品的协同过滤推荐系统图如图所示。
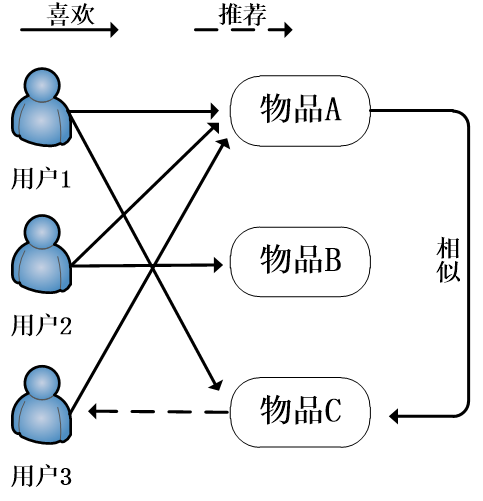
根据协同过滤的处理过程可知,基于物品的协同过滤算法(简称ItemCF算法)主要分为2个步骤。
1.计算物品之间的相似度。
2.根据物品的相似度和用户的历史行为给用户生成推荐列表。
其中关于物品相似度计算的方法有夹角余弦、杰卡德(Jaccard)相似系数和相关系数等
在协同过滤系统中发现用户存在多种行为方式,如是否浏览网页、是否购买、评论、评分、点赞等行为,若采用统一的方式表示所有行为是困难的,因此只对具体的分析目标进行具体的表示。本案例原始数据只记录了用户访问网站浏览行为,所以用户的行为是浏览网页与否,不存在购买、评分和评论等用户行为。
计算各个物品之间的相似度之后,即可构成一个物品之间的相似度矩阵,如下表所示,通过相似度矩阵,推荐算法会给用户推荐与其物品最相似的K个的物品。
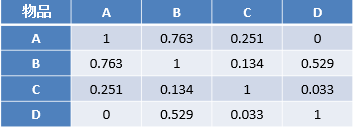
推荐系统是根据物品的相似度以及用户的历史行为对用户的兴趣度进行预测并推荐,在评价模型的时候一般是将数据集划分成训练集和测试集两部分。模型通过在训练集的数据上进行训练学习得到推荐模型,然后在测试集数据上进行模型预测,最终统计出相应的评测指标评价模型预测效果的好与坏。
模型的评测采用的方法是交叉验证法。交叉验证法即将用户行为数据集按照均匀分布随机分成M份(本案例M取10),挑选一份作为测试集,将剩下的M-1份作为训练集。然后在训练集上建立模型,并在测试集上对用户行为进行预测,统计出相应的评测指标。为了保证评测指标并不是过拟合的结果,需要进行M次实验,并且每次都使用不同的测试集。最后将M次实验测出的评测指标的平均值作为最终的评测指标。
2. 优缺点分析
-
优点:可以离线完成相似性步骤,降低了在线计算量,提高了推荐效率;并利用用户的历史行为给用户做推荐解释,结果容易让客户信服。
-
缺点:现有的协同过滤算法没有充分利用到用户间的差别,使计算得到的相似度不够准确,导致影响了推荐精度;此外,用户的兴趣是随着时间不断变化的,算法可能对用户新点击兴趣的敏感性较低,缺少一定的实时推荐,从而影响了推荐质量。
基于物品的协同过滤适用于物品数明显小于用户数的情形,如果物品数很多,会导致计算物品相似度矩阵代价很大。
3. 模型构建
将训练集中的数据转换成0-1二元型数据,使用ItemCF算法对数据进行建模,并对预测推荐结果。
import pandas as pd
# 利用训练集数据构建模型
UI_matrix_tr = pd.DataFrame(0,index=IP_tr,columns=url_tr)
# 求用户-物品矩阵
for i in data_tr.index:
UI_matrix_tr.loc[data_tr.loc[i,'realIP'],data_tr.loc[i,'fullURL']] = 1
sum(UI_matrix_tr.sum(axis=1))
# 求物品相似度矩阵(因计算量较大,需要耗费的时间较久)
Item_matrix_tr = pd.DataFrame(0,index=url_tr,columns=url_tr)
for i in Item_matrix_tr.index:
for j in Item_matrix_tr.index:
a = sum(UI_matrix_tr.loc[:,[i,j]].sum(axis=1)==2)
b = sum(UI_matrix_tr.loc[:,[i,j]].sum(axis=1)!=0)
Item_matrix_tr.loc[i,j] = a/b
# 将物品相似度矩阵对角线处理为零
for i in Item_matrix_tr.index:
Item_matrix_tr.loc[i,i]=0
# 利用测试集数据对模型评价
IP_te = data_te.iloc[:,0]
url_te = data_te.iloc[:,1]
IP_te = list(set(IP_te))
url_te = list(set(url_te))
# 测试集数据用户物品矩阵
UI_matrix_te = pd.DataFrame(0,index=IP_te,columns=url_te)
for i in data_te.index:
UI_matrix_te.loc[data_te.loc[i,'realIP'],data_te.loc[i,'fullURL']] = 1
# 对测试集IP进行推荐
Res = pd.DataFrame('NaN',index=data_te.index,
columns=['IP','已浏览网址','推荐网址','T/F'])
Res.loc[:,'IP']=list(data_te.iloc[:,0])
Res.loc[:,'已浏览网址']=list(data_te.iloc[:,1])
# 开始推荐
for i in Res.index:
if Res.loc[i,'已浏览网址'] in list(Item_matrix_tr.index):
Res.loc[i,'推荐网址'] = Item_matrix_tr.loc[Res.loc[i,'已浏览网址'],
:].argmax()
if Res.loc[i,'推荐网址'] in url_te:
Res.loc[i,'T/F']=UI_matrix_te.loc[Res.loc[i,'IP'],
Res.loc[i,'推荐网址']]==1
else:
Res.loc[i,'T/F'] = False
# 保存推荐结果
Res.to_csv('./tmp/Res.csv',index=False,encoding='utf8')
通过基于协同过滤算法构建的推荐系统,婚姻知识类得到了针对每个用户的推荐,部分结果如表所示。

由上表可知,根据用户访问的相关网址,对用户进行推荐。但是其推荐结果存在NaN的情况。这种情况是由于在目前的数据集中,访问该网址的只有单独一个用户,因此在协同过滤算法中计算它与其他物品的相似度为0,所以就出现无法推荐的情况。一般出现这样的情况,在实际中可以考虑其他的非个性化的推荐方法进行推荐,例如基于关键字、基于相似行为的用户进行推荐等。
4. 模型评价
推荐系统的评价一般可以从如下几个方面整体进行考虑:
1.用户、物品提供者、提供推荐系统网站。
2.好的推荐系统能够满足用户的需求,推荐其感兴趣的物品。同时推荐的物品中,不能全部是热门的物品,同时也需要用户反馈意见帮助完善其推荐系统。
因此,好的推荐系统不仅能预测用户的行为,而且能帮助用户发现可能会感兴趣,但却不易被发现的物品。同时,推荐系统还应该帮助商家将长尾中的好商品发掘出来,推荐给可能会对它们感兴趣的用户。
在实际应用中,评测推荐系统对三方的影响是必不可少的。评测指标主要来源于如下3种评测推荐效果的实验方法,即离线测试、用户调查和在线实验。
1.离线测试是通过从实际系统中提取数据集,然后采用各种推荐算法对其进行测试,获各个算法的评测指标。这种实验方法的好处是不需要真实用户参与。
注意:离线测试的指标和实际商业指标存在差距,比如预测准确率和用户满意度之间就存在很大差别,高预测准确率不等于高用户满意度。所以当推荐系统投入实际应用之前,需要利用测试的推荐系统进行用户调查。
2.用户调查利用测试的推荐系统调查真实用户,观察并记录他们的行为,并让他们回答一些相关的问题。通过分析用户的行为和他们反馈的已经,判断测试推荐系统的好坏。
3.在线测试顾名思义就是直接将系统投入实际应用中,通过不同的评测指标比较与不同的推荐算法的结果,比如点击率,跳出率等。
本次模型是采用离线的数据集构建的,因此在模型评价阶段采用离线测试的方法获取评价指标。在电子商务网站中,用户只有二元选择,比如:喜欢与不喜欢,浏览与否等。针对这类型的数据预测,就要用分类准确度,其中的评测指标有准确率(P、precesion),它表示用户对一个被推荐产品感兴趣的可能性。召回率(R、recall)表示一个用户喜欢的产品被推荐的概率。F1指标表示综合考虑准确率与召回率因素,更好的评价算法的优劣。准确率、召回率和F1指标的计算公式,如下表所示。

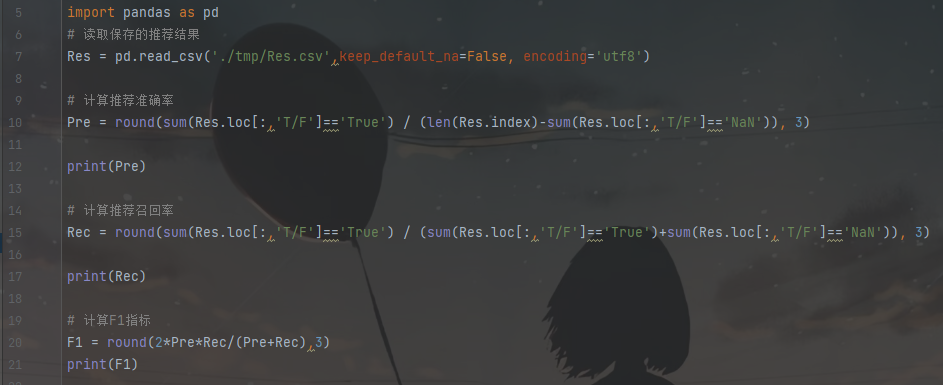

采用的是最基本的协同过滤算法进行建模,因此得出的模型结果也是一个初步的效果,实际应用的过程中要结合业务进行分析,对模型进一步改造。首先需要改造的是一般情况下,最热门物品往往具有较高的“相似性”。比如热门的网址,访问各类网页的大部分人都会进行访问,在计算物品相似度的过程中,就可以知道各类的网页都和某些热门的网址有关。
处理热门网址的方法如下
(1)在计算相似度的过程中,可以加强对热门网址的惩罚,降低其权重,比如对相似度平均化,或者对数化等方法。
(2)将推荐结果中的热门网址进行过滤掉,推荐其他的网址,将热门网址以热门排行榜的形式进行推荐,如下表所示。
在协同过滤推荐过程中,两个物品相似是因为它们共同出现在很多用户的兴趣列表中,也可以说是每个用户的兴趣列表都对物品的相似度产生贡献。但是并不是每个用的贡献度都相同。通常不活跃的用户要么是新用户,要么是只来过网站一两次的老用户。
在实际分析中,一般认为新用户倾向于浏览热门物品,首先他们对网站还不熟悉,只能点击首页的热门物品,而老用户会逐渐开始浏览冷门的物品。因此可以说,活跃用户对物品相似度的贡献应该小于不活跃的用户。
然而在实际应用中,为了尽量的提高推荐的准确率,还会将基于物品的相似度矩阵按最大值归一化,其好处不仅仅在于增加推荐的准确度,它还可以提高推荐的覆盖率和多样性。推荐是针对某一类数据进行推荐,因此不存在类间的多样性。
当然,除了个性化推荐列表,还有另一个重要的推荐应用就是相关推荐列表。有过网购的经历的用户都知道,当你在电子商务平台上购买一个商品时,它会在商品信息下面展示相关的商品。一种是包含购买了这个商品的用户也经常购买的其他商品,另一种是包含浏览过这个商品的用户经常购买的其他商品。这两种相关推荐列表的区别:使用了不同用户行为计算物品的相似性。
跃的用户要么是新用户,要么是只来过网站一两次的老用户。
在实际分析中,一般认为新用户倾向于浏览热门物品,首先他们对网站还不熟悉,只能点击首页的热门物品,而老用户会逐渐开始浏览冷门的物品。因此可以说,活跃用户对物品相似度的贡献应该小于不活跃的用户。
然而在实际应用中,为了尽量的提高推荐的准确率,还会将基于物品的相似度矩阵按最大值归一化,其好处不仅仅在于增加推荐的准确度,它还可以提高推荐的覆盖率和多样性。推荐是针对某一类数据进行推荐,因此不存在类间的多样性。
当然,除了个性化推荐列表,还有另一个重要的推荐应用就是相关推荐列表。有过网购的经历的用户都知道,当你在电子商务平台上购买一个商品时,它会在商品信息下面展示相关的商品。一种是包含购买了这个商品的用户也经常购买的其他商品,另一种是包含浏览过这个商品的用户经常购买的其他商品。这两种相关推荐列表的区别:使用了不同用户行为计算物品的相似性。