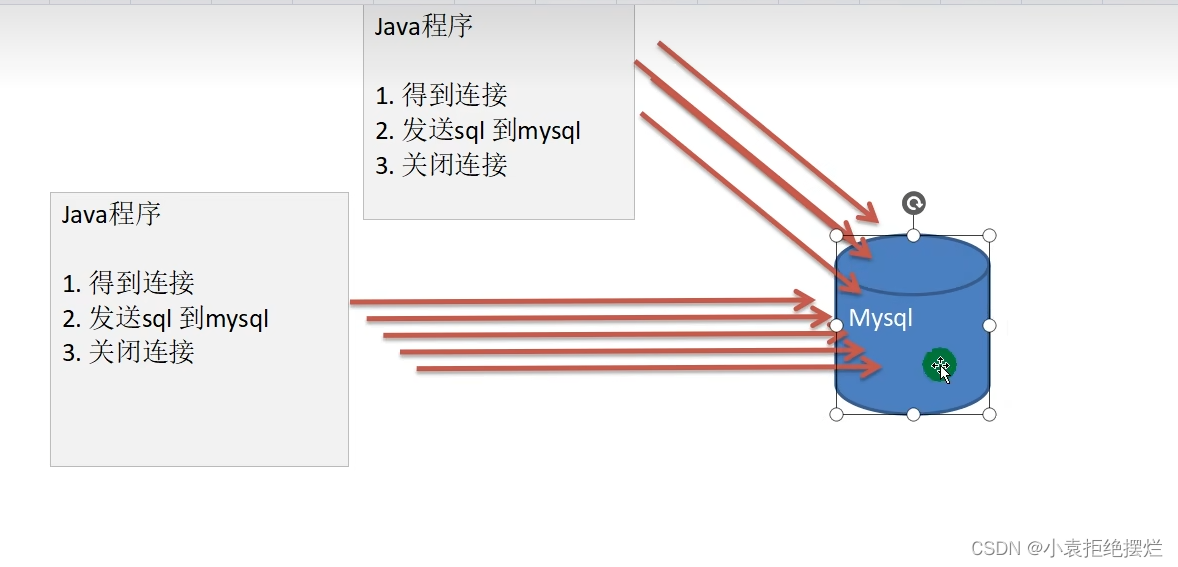
传统数据库连接的弊端

一个java程序多个正常要开启多个mysql连接-正常开发中次数在1w次往上(还可能有多个java程序-并发编程),但是如果很多歌连接的话,数据库可能就瘫痪了
测试一个程序连接5000次
抛出一个,太多连接的异常

我们也开启完执行完就关闭
也有问题-效率太低
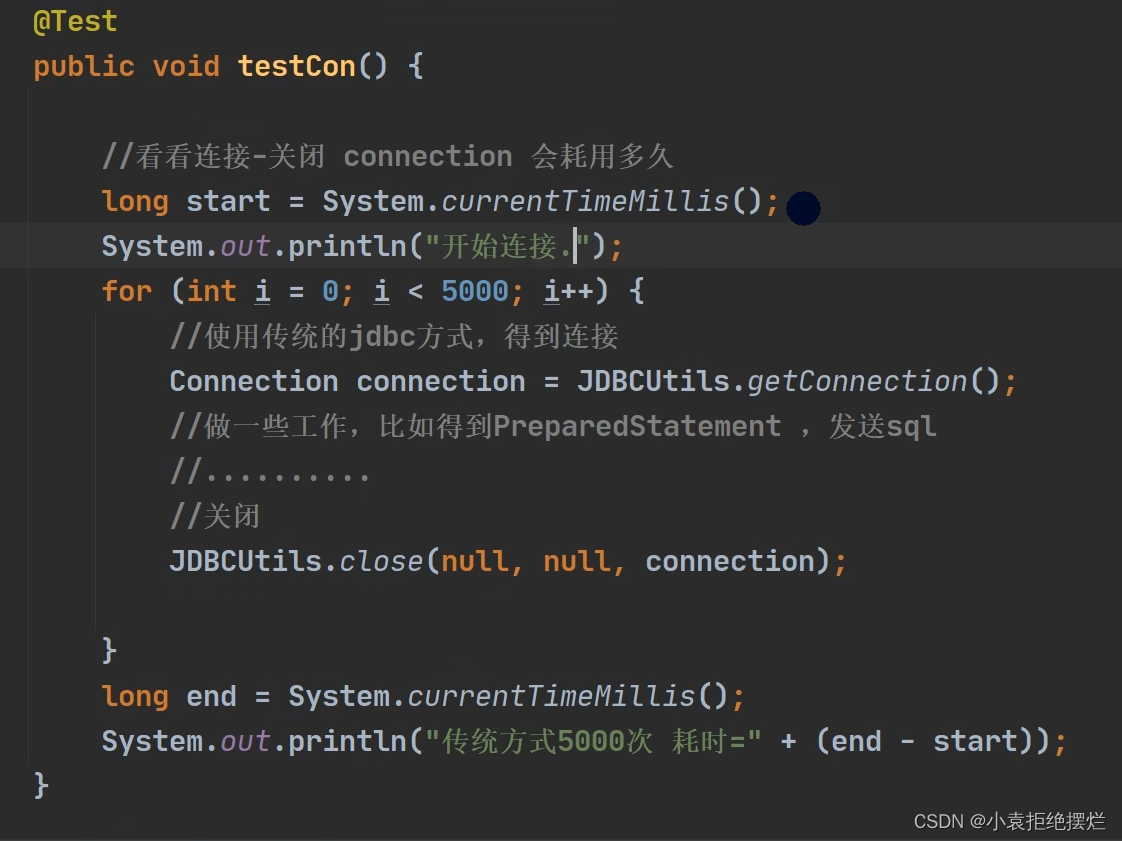

消耗大约7s钟
解决这些问题-数据库连接池技术
数据库连接池

1.介绍先在缓冲池中存一定量的连接,当java程序需要连接时候进行申请,用完后释放连接(不是关闭!),连接可以反复使用
2.数据库连接池进行连接的分配管理,释放
3.连接池连接不够用时,新申请的程序要进入等待队列
示意图
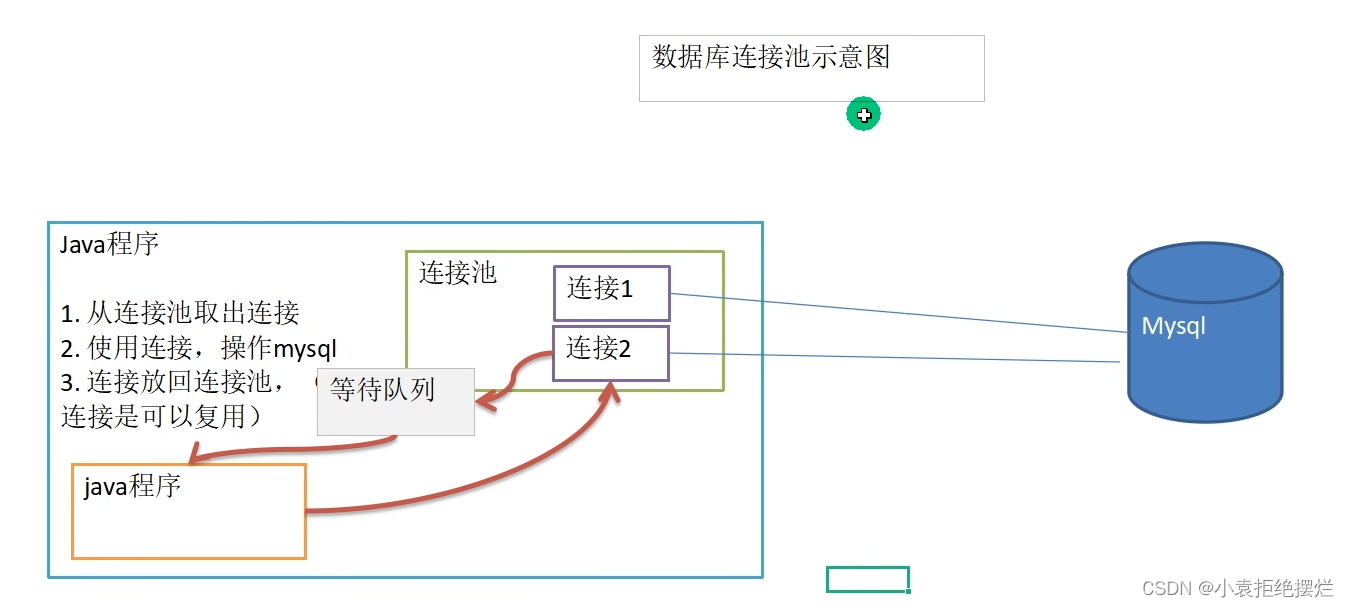
具体方法去调用我们连接池的连接,注意:我们释放连接,不是关闭,而是不用那个对象的引用了
数据库连接池种类
DataSource是所有这些连接池的接口

重点还是我们的C3P0!还有Druid!!!
下面会具体讲解
使用这两种需要导入相应的jar包
C3P0
赋值从网上下的jar包,项目中创建文件夹,复制到文件夹下面
右键jar包点击如下图的第一个有个ADD path什么的就导入成功了
最大连接数:需要在队列等待的临界值
最小连接数:连接池中最小连接(连接一直不用会回收,控制回收)
初始连接数:初始时候连接池的连接数
每次增长连接数:需要增加连接数的增长值,最大为最大连接数
代码
方式1
package yuan.hsp.JDBC.conchi;
import java.io.FileInputStream;
import java.sql.Connection;
import java.util.Properties;
import org.junit.jupiter.api.Test;
import com.mchange.v2.c3p0.ComboPooledDataSource;
//数据库C3P0数据库连接池
public class C3P0 {
@Test
public void testc3p0_01() throws Exception {
//1.创建一个数据源对象(实现DataSource接口)
ComboPooledDataSource comboPooledDataSource = new ComboPooledDataSource();
//2.通过配置文件获取相关信息
Properties properties = new Properties();
properties.load(new FileInputStream("src\\pra.properties"));
String user=properties.getProperty("user");
String password=properties.getProperty("password");
String url=properties.getProperty("url");
String driver=properties.getProperty("driver");
//3.给数据源设置相关参数
//注意我们连接管理由comboPooledDataSource来管理
comboPooledDataSource.setDriverClass(driver);
comboPooledDataSource.setJdbcUrl(url);
comboPooledDataSource.setUser(user);
comboPooledDataSource.setPassword(password);
//4.设置初始连接数
comboPooledDataSource.setInitialPoolSize(10);//设置初始为10个(就是连接池创建里面有多少个连接)
//最大连接数
comboPooledDataSource.setMaxPoolSize(50);//最大连接数为50(就是当你10个用完,还有想要用的,增加连接-最多到50个,第51个去队列等待)
//测试一下效率
long start = System.currentTimeMillis();
//5.获取连接!核心
for(int i=0;i<5000;i++) {
Connection connection = comboPooledDataSource.getConnection();//这个方法是从DataSource接口实现的
connection.close();//释放连接,底层不一样不过还是那个接口
}
long end = System.currentTimeMillis();
System.out.println("耗费时间为"+(end-start));
}
}

365比上面的7099少很多
效率更高
方式2
利用C3P0提供的配置文件进行完成
对应文件名c3p0-config.xml
将该文件复制到src目录
该文件指定了连接数据库和连接池的相关参数
点击这个文件
可以进行相关参数的修改
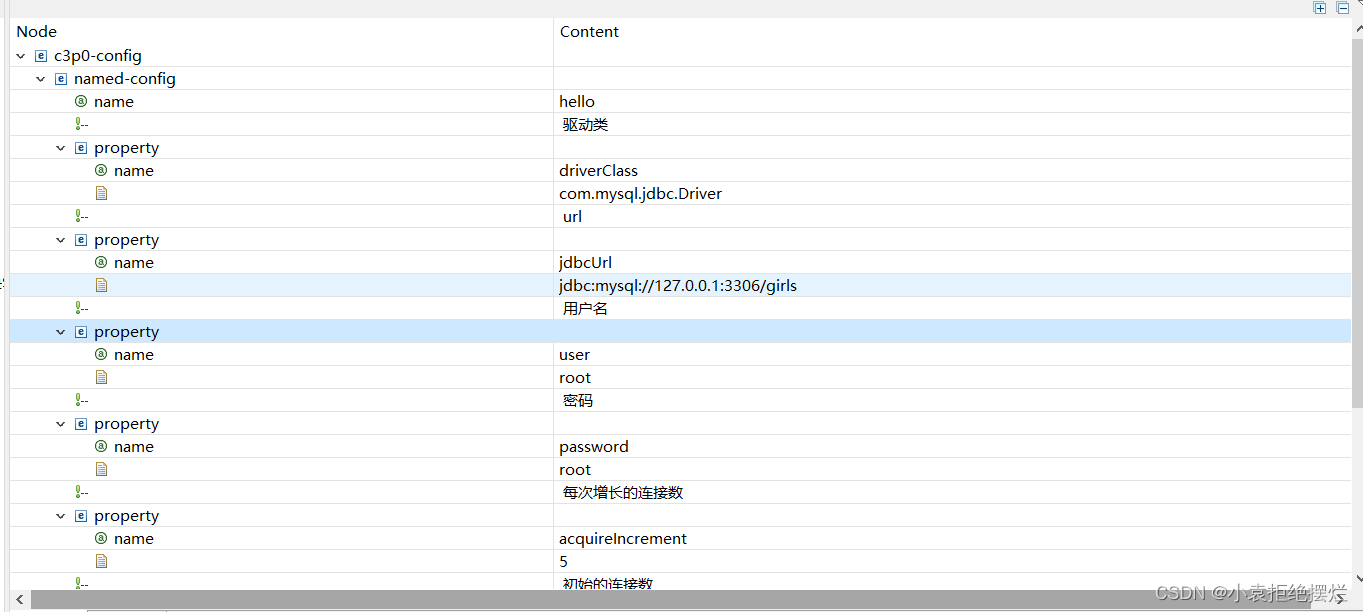
把什么驱动类什么的改成我们的对应路径
还有用户密码什么的
也可以设置连接数什么的

注意这个最开始的这个是数据源名称
就这样几行简单的代码就ok了
因为其他的已经在xml文件了配置了
@Test
public void CP30test02() throws SQLException {
ComboPooledDataSource comboPooledDataSource = new ComboPooledDataSource("hello");
long start = System.currentTimeMillis();
for(int i=0;i<5000;i++) {
Connection connection = comboPooledDataSource.getConnection();
connection.close();//这里是释放连接底层不一样
}
long end = System.currentTimeMillis();
System.out.println("耗费时间为"+(end-start));
}
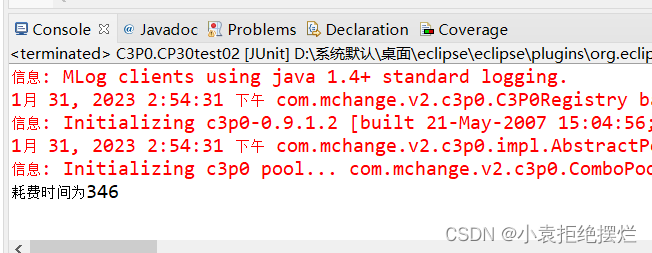
也是可以连接成功且效率高的
德鲁伊连接池
这个效率来说最高
第一步还是加入jar包奥
就之前的步骤
package yuan.hsp.JDBC.conchi;
import java.io.FileInputStream;
import java.sql.Connection;
import java.util.Properties;
import javax.sql.DataSource;
import org.junit.jupiter.api.Test;
import com.alibaba.druid.pool.DruidDataSourceFactory;
//测试德鲁伊使用
public class Druid {
@Test
public void testdruid() throws Exception {
//1.jar包导入和配置文件加入到src目录下面
//这个配置文件(properties)里面有各种数据库连接池的信息
//-#max wait time (5000 mil seconds)特别解释一下这个是最长等待时间,等待超过这个时间,放弃等待下一次申请连接
//2.创建properties读取
Properties properties = new Properties();
properties.load(new FileInputStream("src\\druid.properties"));
//3.创建一个指定的数据库连接池
DataSource createDataSource = DruidDataSourceFactory.createDataSource(properties);
long start = System.currentTimeMillis();
for(int i=0;i<5000;i++) {
Connection connection = createDataSource.getConnection();
connection.close();//这个不是关闭操作时间上是返还操作
}
long end = System.currentTimeMillis();
System.out.println("消耗时间"+(end-start));
}
}
配置文件
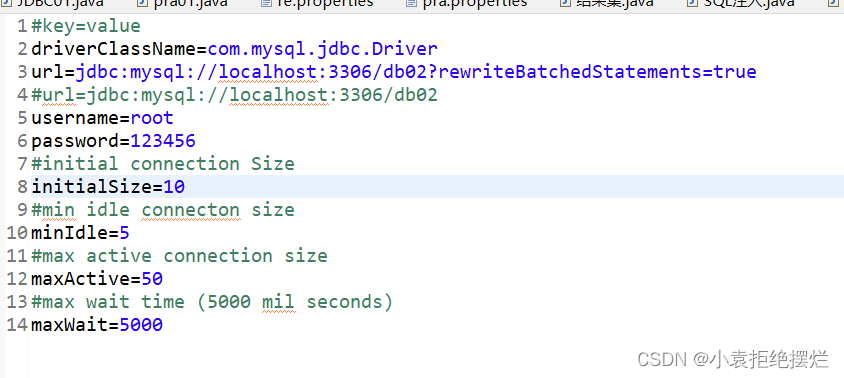
记得不要有空格!

为什么这里393比之前C3P0的346高?
因为连接次数5000次其实是挺小的
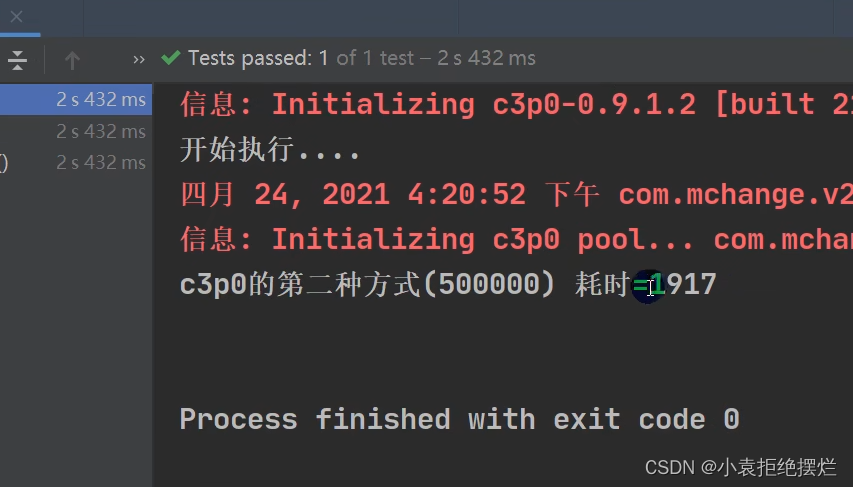
50w次的话这个
德鲁伊比C3P0大
两种高处理量的效率对比
50w次的连接申请
C3P0
Druid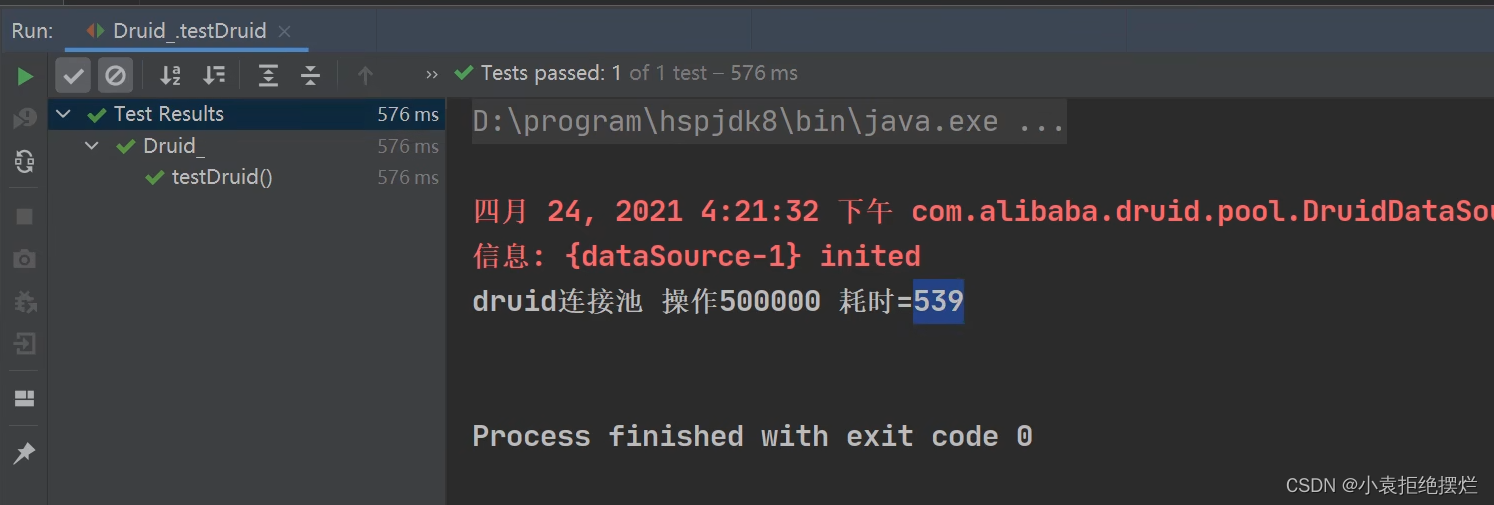
显然Druid效率高一些



![[docker]-docker安装prometheus和grafana](https://img-blog.csdnimg.cn/img_convert/0cf1cf35a93e90b9728425eaf2584f60.png)