那年夏天我和你躲在 这一大片宁静的海
直到后来我们都还在 对这个世界充满期待
今年冬天你已经不在 我的心空出了一块
很高兴遇见你 让我终究明白
回忆比真实精彩
🎵 王心凌《那年夏天宁静的海》
在机器学习和深度学习中,数据归一化(Normalization)是一种常用的预处理技术,旨在将数据特征缩放到某一特定范围。归一化的主要目的是加速训练过程,提高模型的性能和稳定性。本文将详细介绍数据归一化的原理、方法及其在模型训练中的重要性。
一、数据归一化的原理
数据归一化的基本原理是将不同特征的数据按比例缩放到同一尺度范围,以消除各特征之间的量纲差异。不同特征的数值范围可能相差甚远,例如一个特征的取值范围是0到1,而另一个特征的取值范围可能是0到10000,这样的差异会影响模型的训练效果。归一化可以解决这一问题,使得每个特征对模型的贡献更为均衡。
归一化的常见方法包括最小-最大归一化(Min-Max Normalization)、标准化(Standardization)和小数定标法(Decimal Scaling)。
二、常见归一化方法

三、数据归一化在模型训练中的重要性
加速收敛速度
归一化后的数据具有更稳定的梯度,避免了梯度消失或梯度爆炸的问题,有助于优化算法更快收敛。
提高模型的准确性
归一化可以平衡各特征对模型的影响,避免某些特征由于数值范围较大而主导模型的训练,提高模型的整体性能。
减少特征间的量纲差异
不同量纲的特征经过归一化后,单位和量纲被消除,便于不同特征间的比较和计算。
提高数值计算的稳定性
归一化后的数据在数值计算时更加稳定,避免了数值溢出或精度丢失的问题。
四、总结
数据归一化是机器学习和深度学习模型训练中不可或缺的一步。通过将数据特征缩放到同一尺度范围,归一化不仅加速了模型的训练过程,还提高了模型的性能和稳定性。不同的归一化方法适用于不同的数据场景,选择合适的方法对模型训练的效果至关重要。在实际应用中,应根据数据的特点和模型的需求,灵活应用各种归一化技术,以达到最佳的训练效果。



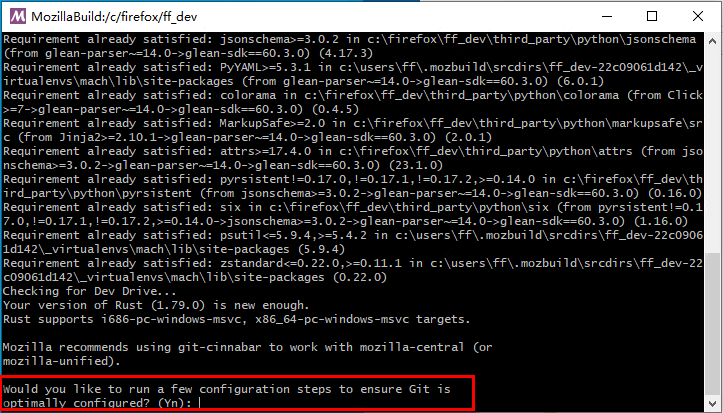








![【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 灰度图像恢复(100分) - 三语言AC题解(Python/Java/Cpp)](https://i-blog.csdnimg.cn/direct/d16c3fc15aec4ea487ad2a13774cfb0b.png)