一、背景
有时候会看业务执行的情况,如查看多少用户已经领取了礼品等,需要看数据库的计数或统计用户使用情况时,往往会使用聚合函数COUNT(),聚合函数有很多种,列出如官网的截图
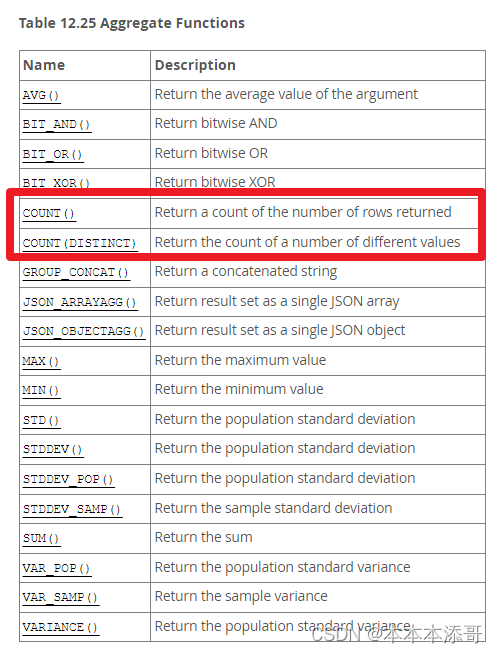
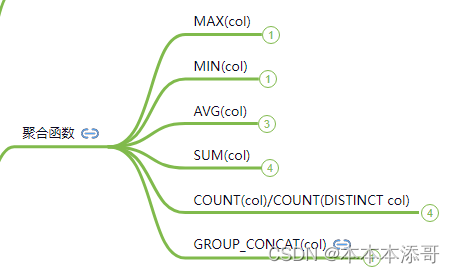
而其中常用的聚合函数主要是包括以下,其中就会涉及到使用Count的聚合函数。
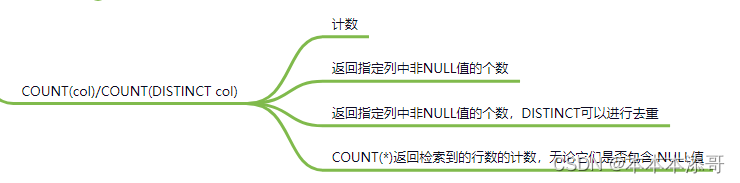
Count常见有三种,具体要使用哪一种呢?
二、实际对比下
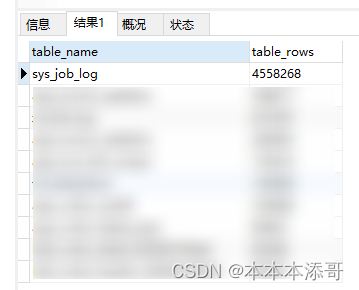
2.1 计算库中最大的表
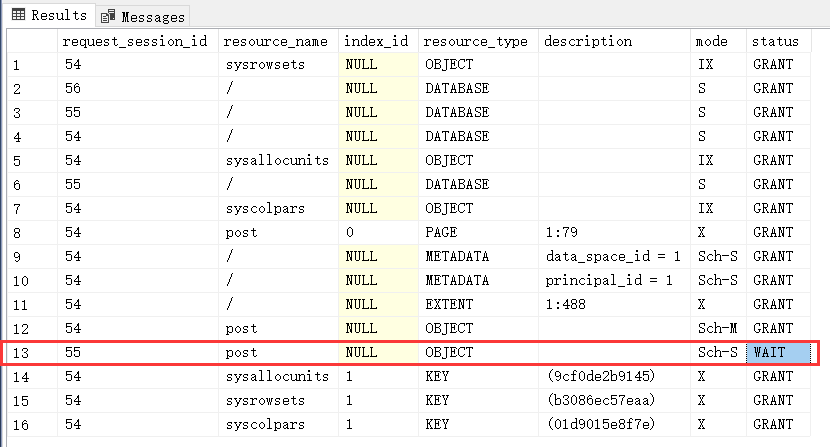
按顺序执行以下SQL脚本,得出sys_job_log为最大的表
show DATABASES;
use information_schema;
show tables;
desc tables;
select table_name,table_rows from tables order by table_rows desc limit 10;
2.2 计算大表的平均查询时间
select count(*) from sys_job_log
select count(1) from sys_job_log
select count(job_log_id) from sys_job_log
发现规律,第三个SQL总是耗去最长时间~平均都需要1S以上才能查询出来结果,其他两个SQL的查询时间看不出时长的差别。

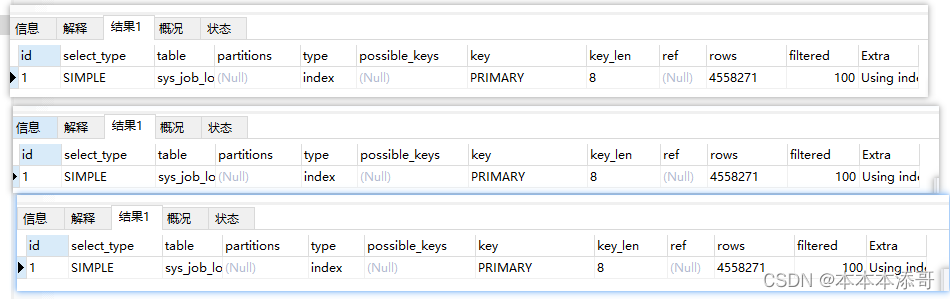
2.3 计算大表的执行计划
EXPLAIN select count(*) from sys_job_log
EXPLAIN select count(1) from sys_job_log
EXPLAIN select count(job_log_id) from sys_job_log
从执行计划来看,三者都一样
三、耗时统计与总结
3.1 count(1)和count(*)的用法相同
- count(1)和count(*)的用法相同,都是统计表中的行数。
- 如果想要统计表中的行数,可以使用count(1)或count(*);
3.2 count(1) 和count(*) 的耗时可能有所不同
- count(1) 会更快一些,因为它只需要统计行数,而不需要计算所有列的值。
- count(*) 会慢一些,因为它需要统计所有列的值,即使它们都为空也需要计算。
3.3 count(id)是统计id列中非空值的个数
- count(column_name)是统计column_name列中非空值的个数。
- 如果想要统计某一列中非空值的个数,可以使用count(column_name)。