前言
本文的素材来源与某次和朋友技术交流,当时朋友就跟我吐槽说apollo不如nacos好用,而且他们还因为apollo发生过一次线上事故。
故事的背景大概是如下
前阵子朋友部门的数据库发生宕机,导致业务无法正常操作,当时朋友他们数据库信息是配置在apollo上,朋友的想法是当数据库宕机时,可以通过切换配置在apollo上的数据库信息,实现数据源热变更。但当他们数据库发生宕机时,朋友按他的想法操作,发现事情并不像他想象的那样,他们更换数据源后,发现业务服务连接仍然是旧的数据库服务,后面没办法他们只能联系dba处理。
后边我听了朋友的描述后,我就问他说,你们当时数据库热切是怎么做的,他的回答是:很简单啊,就把数据源信息配置在apollo上,如果要变更数据源,就直接在apollo的portal上变更一下啊。听了朋友话,我就问然后呢?朋友的回答是:什么然后?就没然后了啊。
通过那次交流,就有了今天的文章,今天我们就来聊聊apollo与druid整合实现数据源动态热切
实现核心思路
apollo的配置变更动态监听 + spring AbstractRoutingDataSource预留方法determineCurrentLookupKey来做数据源切换
在介绍实现核心逻辑之前,我们来聊一下配置中心
何为配置中心?
配置中心是一种统一管理各种应用配置的基础服务组件。他的核心是对配置的统一管理。他管理的范畴是配置,至于对配置有依赖的对象,比如数据源,他是不归配置中心来管理。为什么我会单独提这个?是因为朋友似乎陷入了一个误区,以为在apollo上变更了配置,这个配置依赖的数据源也会一起跟着变更
核心代码
1、创建动态数据源,代理原来的datasource
public class DynamicDataSource extends AbstractRoutingDataSource {
public static final String DATASOURCE_KEY = "db";
@Override
protected Object determineCurrentLookupKey() {
return DATASOURCE_KEY;
}
public DataSource getOriginalDetermineTargetDataSource(){
return this.determineTargetDataSource();
}
}
@Configuration
@EnableConfigurationProperties(BackupDataSourceProperties.class)
@ComponentScan(basePackages = "com.github.lybgeek.ds.switchover")
public class DynamicDataSourceAutoConfiguration {
@Bean
@ConditionalOnMissingBean
@Primary
@ConditionalOnClass(DruidDataSource.class)
public AbstractDataSourceManger abstractDataSourceManger(DataSourceProperties dataSourceProperties, BackupDataSourceProperties backupDataSourceProperties){
return new DruidDataSourceManger(backupDataSourceProperties,dataSourceProperties);
}
@Bean("dataSource")
@Primary
@ConditionalOnBean(AbstractDataSourceManger.class)
public DynamicDataSource dynamicDataSource(AbstractDataSourceManger abstractDataSourceManger) {
DynamicDataSource source = new DynamicDataSource();
DataSource dataSource = abstractDataSourceManger.createDataSource(false);
source.setTargetDataSources(Collections.singletonMap(DATASOURCE_KEY, dataSource));
return source;
}
}
这边有个需要注意的点就是DynamicDataSource的bean名称一定是需要为dataSource,目的是为了让spring默认的datasource取到的bean是DynamicDataSource
2、监听配置变更,并进行数据源切换
切换数据源
@ApolloConfigChangeListener(interestedKeyPrefixes = PREFIX)
public void onChange(ConfigChangeEvent changeEvent) {
refresh(changeEvent.changedKeys());
}
/**
*
* @param changedKeys
*/
private synchronized void refresh(Set<String> changedKeys) {
/**
* rebind configuration beans, e.g. DataSourceProperties
* @see org.springframework.cloud.context.properties.ConfigurationPropertiesRebinder#onApplicationEvent
*/
this.applicationContext.publishEvent(new EnvironmentChangeEvent(changedKeys));
/**
* BackupDataSourceProperties rebind ,you can also do it in PropertiesRebinderEventListener
* @see PropertiesRebinderEventListener
*/
backupDataSourcePropertiesHolder.rebinder();
abstractDataSourceManger.switchBackupDataSource();
}
@SneakyThrows
@Override
public void switchBackupDataSource() {
if(backupDataSourceProperties.isForceswitch()){
if(backupDataSourceProperties.isForceswitch()){
log.info("Start to switch backup datasource : 【{}】",backupDataSourceProperties.getBackup().getUrl());
DataSource dataSource = this.createDataSource(true);
DynamicDataSource source = applicationContext.getBean(DynamicDataSource.class);
DataSource originalDetermineTargetDataSource = source.getOriginalDetermineTargetDataSource();
if(originalDetermineTargetDataSource instanceof DruidDataSource){
DruidDataSource druidDataSource = (DruidDataSource)originalDetermineTargetDataSource;
ScheduledExecutorService createScheduler = druidDataSource.getCreateScheduler();
createScheduler.shutdown();
if(!createScheduler.awaitTermination(backupDataSourceProperties.getAwaittermination(), TimeUnit.SECONDS)){
log.warn("Druid dataSource 【{}】 create connection thread force to closed",druidDataSource.getUrl());
createScheduler.shutdownNow();
}
}
//当检测到数据库地址改变时,重新设置数据源
source.setTargetDataSources(Collections.singletonMap(DATASOURCE_KEY, dataSource));
//调用该方法刷新resolvedDataSources,下次获取数据源时将获取到新设置的数据源
source.afterPropertiesSet();
log.info("Switch backup datasource : 【{}】 finished",backupDataSourceProperties.getBackup().getUrl());
}
}
}
3、测试
@Override
public void run(ApplicationArguments args) throws Exception {
while(true){
User user = userService.getById(1L);
System.err.println(user.getPassword());
TimeUnit.SECONDS.sleep(1);
}
}
未切换前,控制台打印
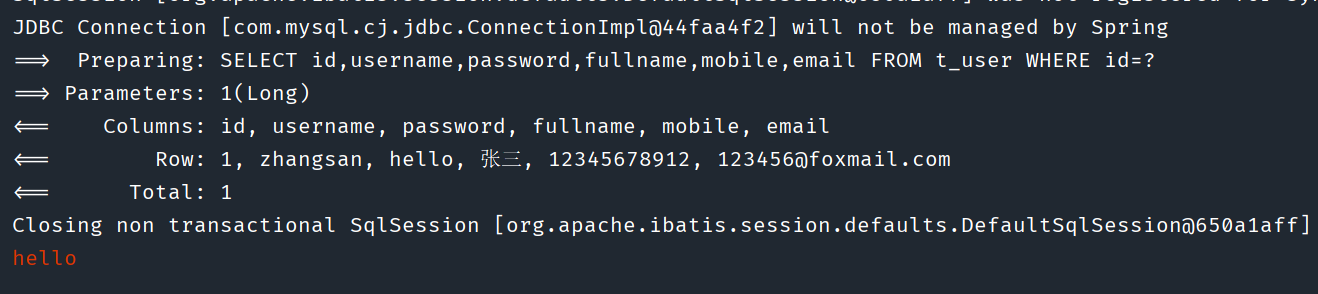
切换后,控制台打印

总结
以上就是实现apollo与druid整合实现数据源动态热切的整体思路,但是实现中还存在有一点问题,就是存在老连接没做处理。虽然我在示例代码中没做处理,但代码里面预留了getOriginalDetermineTargetDataSource,可以通过getOriginalDetermineTargetDataSource来做额外一些操作。
本文的实现方式还可以使用apollo在github提供的case来实现,链接如下
https://github.com/apolloconfig/apollo-use-cases/tree/master/dynamic-datasource
他这个case在进行连接切换后,会对老的数据源进行连接清理。他里面的用数据源是HikariDataSource,如果你用apollo提供的case,当你是使用druid数据源时,我贴下druid的关闭部分源码
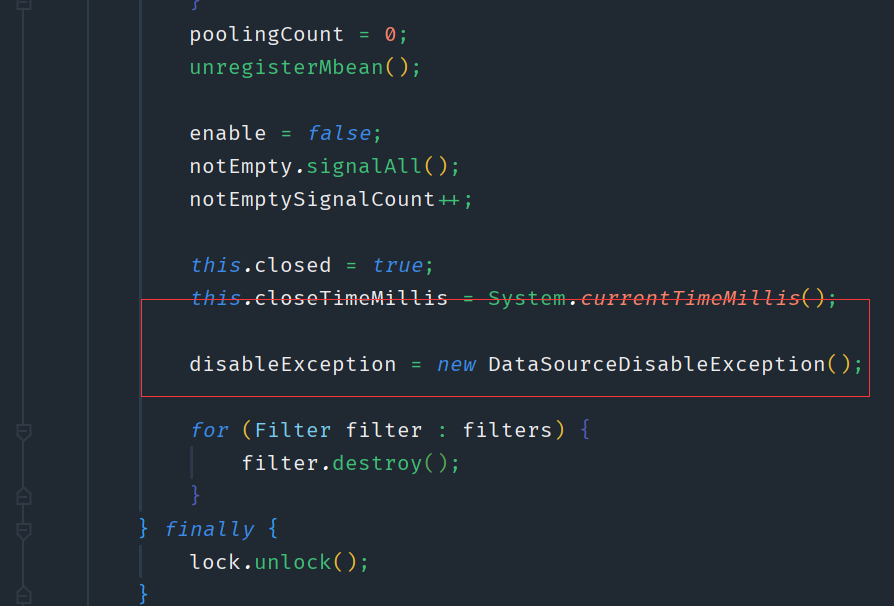
以及获取connection源码
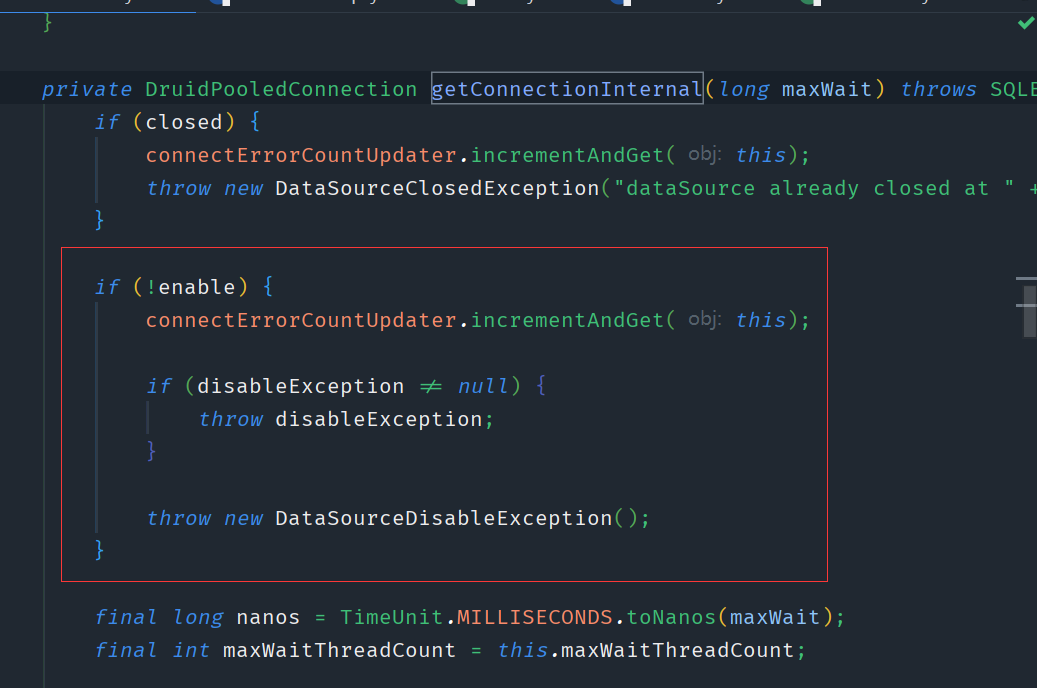
这边有个注意点就是,当druid数据源进行关闭时,如果此时恰好有连接进来,此时就会报DataSourceDisableException,然后导致项目异常退出
最后说点额外的,之前朋友说apollo比nacos不好用啥的,我是持保留意见的,其实衡量一个技术的好坏,是要带上场景的,在某些场景,技术的具备的优势可能反而成了劣势
demo链接
https://github.com/lyb-geek/springboot-learning/tree/master/springboot-datasource-hot-switchover