解释基于XGBoost对泰坦尼克号数据集的预测过程和结果
- 1. 训练数据
- 2. 简单的 XGBoost 分类器
- 3. 解释重量
- 4. 解释预测
- 5. 添加文本特性
- 参考资料
本文介绍如何分析XGBoost分类器的预测(
eli5也支持
XGBoost和大多数
scikit-learn树集成的回归)。 我们将使用
Titanic数据集,它很小且没有太多特征,但仍然足够有趣。
使用XGBoost 0.81和从https://www.kaggle.com/c/titanic/data下载的数据(它也存储在eli5源码库中:https://github.com/TeamHG-Memex/eli5/blob/master/notebooks/titanic-train.csv)。
1. 训练数据
首先,加载数据:
import pandas as pd
# 直接从github代码仓库位置加载
url = "https://github.com/TeamHG-Memex/eli5/blob/017c738f8dcf3e31346de49a390835ffafad3f1b/notebooks/titanic-train.csv?raw=true"
data = pd.read_csv(url)
data.head()

变量说明:
- Age: 年龄
- Cabin: 船舱
- Embarked: 出发港 (C = 瑟堡港; Q = 皇后镇; S = 南安普敦)
- Fare: 乘客票价
- Name: 姓名
- Parch: 船上父母/子女人数
- Pclass: 乘客类别 (1 = 1st; 2 = 2nd; 3 = 3rd)
- Sex: 性别
- Sibsp: 船上兄弟姐妹/配偶人数
- Survived: 幸存(0 = No; 1 = Yes)
- Ticket: 船票号码
接下来,把数据和我们试图预测的特征(是否生存)分开:
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
data = data.to_dict('records') # 首先将data的每一行都转换为字典,其中键是列明,值是单元格中的数据
_all_xs = [{k: v for k, v in row.items() if k != 'Survived'} for row in data]
_all_ys = np.array([int(row['Survived']) for row in data]) # 标签数据
all_xs, all_ys = shuffle(_all_xs, _all_ys, random_state=0) # 打乱顺序
train_xs, valid_xs, train_ys, valid_ys = train_test_split(all_xs, all_ys, test_size=0.25, random_state=0)
print('{} items total, {:.1%} true'.format(len(all_xs), np.mean(all_ys)))
'''
891 items total, 38.4% true
'''
我们只做最少的预处理:将明显连续的Age和Fare变量转换为 float,将SibSp和Parch转换为整数。删除缺少的年龄值。
for x in all_xs:
if x['Age']:
x['Age'] = float(x['Age'])
else:
x.pop('Age')
x['Fare'] = float(x['Fare'])
x['SibSp'] = int(x['SibSp'])
x['Parch'] = int(x['Parch'])
2. 简单的 XGBoost 分类器
首先使用 xbgoost.XGBClassifier 和 sklearn.feature_extraction.DictVectorizer 构建一个非常简单的分类器,并使用 10 折交叉验证检查其准确性:
from xgboost import XGBClassifier
from sklearn.feature_extraction import DictVectorizer
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import cross_val_score
clf = XGBClassifier()
vec = DictVectorizer()
pipeline = make_pipeline(vec, clf)
def evaluate(_clf):
scores = cross_val_score(_clf, all_xs, all_ys, scoring='accuracy', cv=10)
print('Accuracy: {:.3f} ± {:.3f}'.format(np.mean(scores), 2 * np.std(scores)))
_clf.fit(train_xs, train_ys) # so that parts of the original pipeline are fitted
evaluate(pipeline)
'''
Accuracy: 0.828 ± 0.061
'''
上面的代码有一个棘手的地方:可能只是将 dense=True 传递给 DictVectorizer:毕竟,在这种情况下矩阵很小。 但这不是一个很好的解决方案,因为我们将失去区分缺失特征和零值特征的能力。
3. 解释重量
为了计算预测,XGBoost 对所有树的预测求和。 树的数量由 n_estimators 参数控制,默认为 100。 每棵树本身并不是一个很好的预测器,但通过对所有树求和,XGBoost 能够在许多情况下提供可靠的估计。 这是其中一棵树:
booster = clf.get_booster()
original_feature_names = booster.feature_names
booster.feature_names = vec.get_feature_names()
print(booster.get_dump()[0])
# recover original feature names
booster.feature_names = original_feature_names
'''
0:[Sex=female<-9.53674316e-07] yes=1,no=2,missing=1
1:[Age<13] yes=3,no=4,missing=4
3:[SibSp<2] yes=7,no=8,missing=7
7:leaf=0.145454556
8:leaf=-0.125
4:[Fare<26.2687492] yes=9,no=10,missing=9
9:leaf=-0.151515156
10:leaf=-0.0727272779
2:[Pclass<2.5] yes=5,no=6,missing=5
5:[Fare<12.1750002] yes=11,no=12,missing=11
11:leaf=0.0500000007
12:leaf=0.175193802
6:[Fare<24.8083496] yes=13,no=14,missing=13
13:leaf=0.0365591422
14:leaf=-0.151999995
'''
可以看到这棵树检查了 Sex、Age、Pclass、Fare 和 SibSp 特征。 leaf 给出了单个树的决定,并且它们对ensemble中的所有树求和。
用eli5.show_weights()检查特征重要性:
from eli5 import show_weights
show_weights(clf, vec=vec)

有几种不同的方法可以计算特征重要性。 默认情况下,使用“gain”,即特征在树中使用时的平均增益。 其他类型是“weight”——一个特征被用来分割数据的次数,以及“cover”——特征的平均覆盖率。 您可以使用 importance_type 参数传递它。
现在知道两个最重要的特征是 Sex=female 和 Pclass=3,但仍然不知道 XGBoost 如何根据它们的值来决定做出什么样的预测。
4. 解释预测
为了更好地了解我们的分类器是如何工作的,使用 eli5.show_prediction() 检查单个预测:
from eli5 import show_prediction
show_prediction(clf, valid_xs[1], vec=vec, show_feature_values=True)
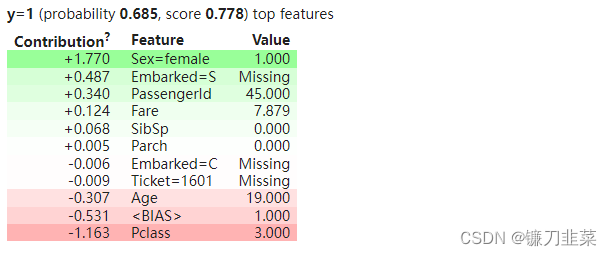
Weight表示每个特征对所有树的最终预测的贡献程度。 权重计算的思路在http://blog.datadive.net/interpreting-random-forests/中有描述;eli5为 XGBoost和大多数scikit-learn树集成提供了该算法的独立实现。
在这里,可以看到分类器认为成为女性是件好事,但乘坐三等车厢是不好的。 一些特征的值是“Missing”(我们通过 show_feature_values=True 来查看值):这意味着该特征缺失,所以在这种情况下最好不要在南安普顿上船。 这是我们决定使用稀疏矩阵的地方——我们仍然看到 Parch 为零,而不是缺失。
可以使用 feature_filter 参数仅显示存在的特征:它是一个接受特征名称和值的函数,并为应该显示的特征返回 True 值:
no_missing = lambda feature_name, feature_value: not np.isnan(feature_value)
show_prediction(clf, valid_xs[1], vec=vec, show_feature_values=True, feature_filter=no_missing)
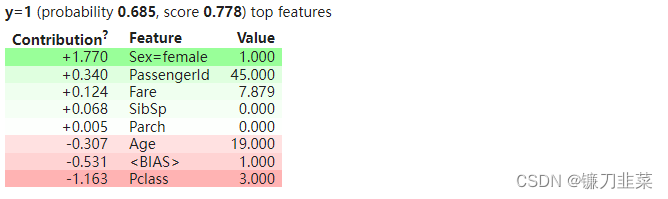
5. 添加文本特性
现在将 Name 字段视为分类的,就像其他文本特征一样。 但是在这个数据集中,每个名字都是唯一的,所以 XGBoost 根本不使用这个特性,因为它是一个很差的鉴别器:它在第 3 部分的权重表中不存在。
但是 Name 仍然可能包含一些有用的信息。 我们不猜测如何最好地对其进行预处理以及提取哪些特征,所以使用最通用的char ngram 向量化器:
from sklearn.pipeline import FeatureUnion
from sklearn.feature_extraction.text import CountVectorizer
vec2 = FeatureUnion([
('Name', CountVectorizer(
analyzer='char_wb',
ngram_range=(3, 4),
preprocessor=lambda x: x['Name'],
max_features=100,
)),
('All', DictVectorizer()),
])
clf2 = XGBClassifier()
pipeline2 = make_pipeline(vec2, clf2)
evaluate(pipeline2)
'''
Accuracy: 0.824 ± 0.076
'''
在这种情况下,管道更加复杂,稍微改进了结果,但改进并不显着。 继续查看特征重要性:
show_weights(clf2, vec=vec2)

看到现在有很多特征来自 Name 字段(事实上,仅基于 Name 的分类器给出了大约 0.79 的准确度)。 以这种方式列出的名称特征不是很有用,当我们检查预测时它们更有意义。 这里隐藏了缺失的特征,因为文本中有很多缺失的特征,但它们并不是很有趣:
from IPython.display import display
for idx in [4, 5, 7]:
display(show_prediction(clf2, valid_xs[idx], vec=vec2, show_feature_values=True, feature_filter=no_missing))
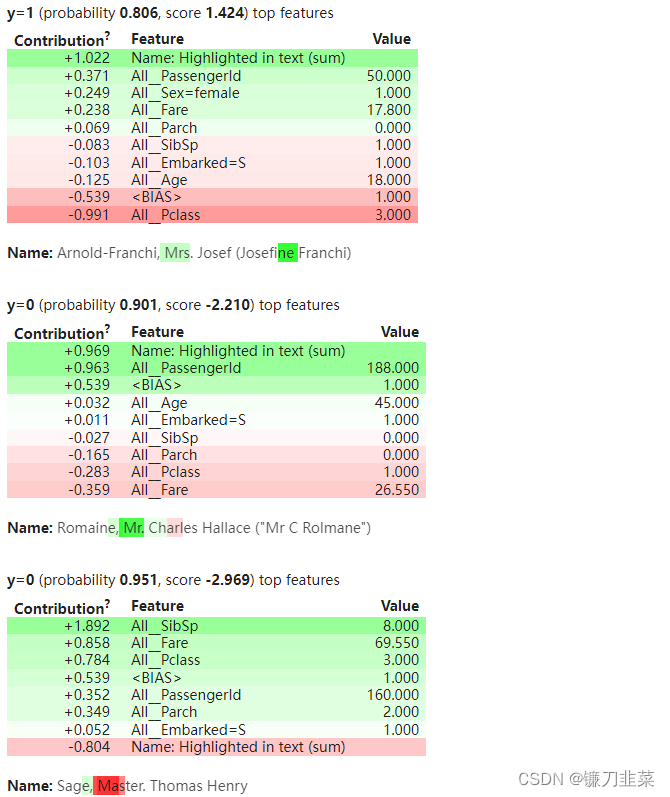
Name 字段中的文本特征直接在文本中突出显示,权重之和在权重表中显示为“Name: Highlighted in text (sum)”。
看起来姓名分类器试图从标题“先生”中推断出性别和地位。 “Mr.”不好是因为女人先得救,做“Mrs.(结婚)”比“Miss.”好。姓名分类器也在尝试挑选姓名的某些部分,尤其是结尾,或许作为社会地位的代表。 如果来自三等舱,那么成为“Mary”尤其糟糕。
参考资料
[1] Explaining XGBoost predictions on the Titanic dataset