uft-8和Unicode字符表对应,查找可参考:https://www.utf8-chartable.de/unicode-utf8-table.pl
几个好用的字符集转换网址:http://web.chacuo.net/charseturlencode,https://123.w3cschool.cn/webtools,http://mytju.com/classcode/tools/encode_gb2312.asp
导致url复制后,在文本中乱码的根本原因
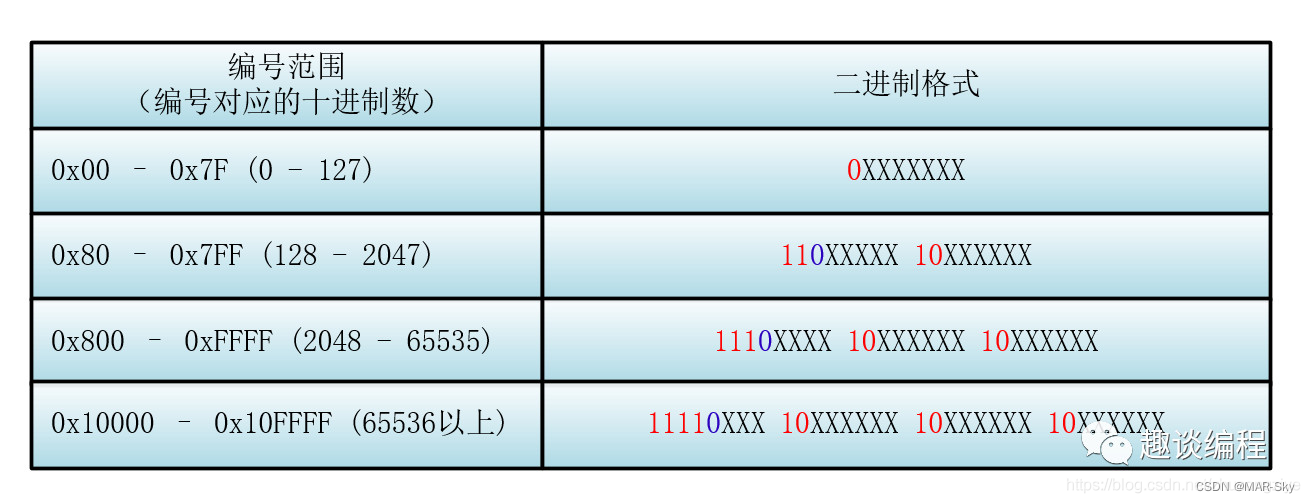
中文字符在请求条件中可能因不同传递编码方式导致最后转换错误,所以先将中文字符转换为utf-8的对应编码值,然后将对应的编码值分成以一个字节为单位分开,也就出现了3个两位16进制的数据。
中文字符集和其他字符集的转换
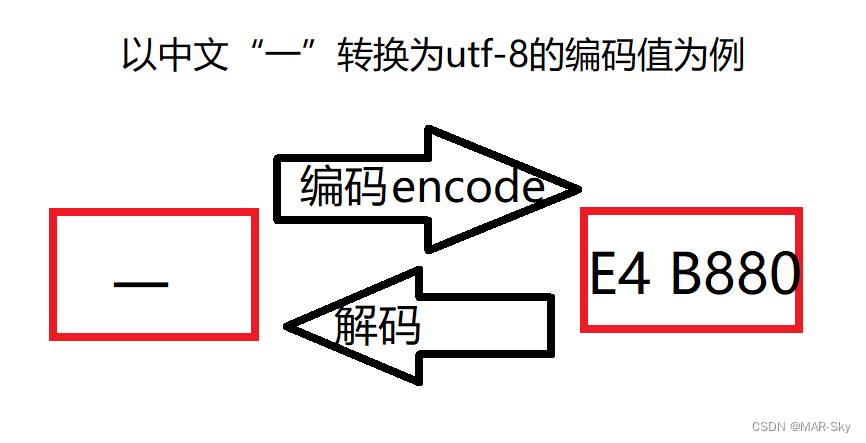
中文编码的实例

下图中,在浏览器中只输入“一”进行搜索,然后把url中从开始到“一”为止的字符复制,贴到记事本上的内容如图,这和UTF-8的号一样,只是每两位有一个%号。
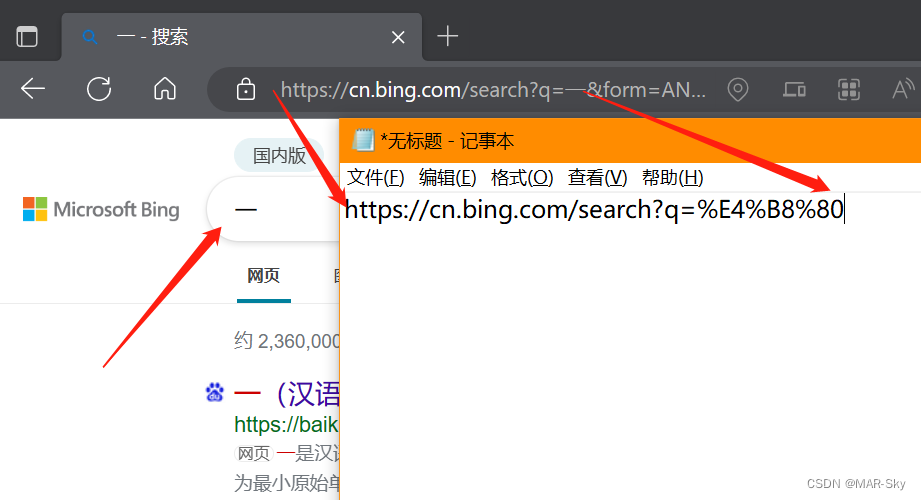
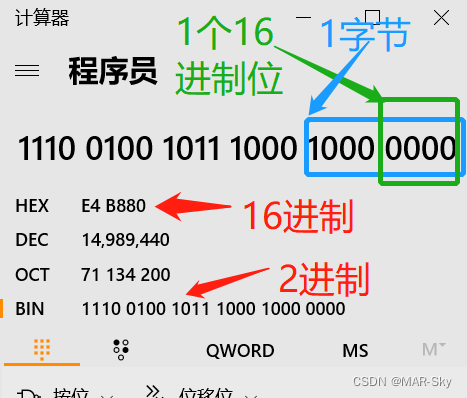
下图中,E4 B880对应的二进制形式如下。表示每个汉字由3个字节表示,其中一个16进制位由是4个二进制位组成,所以UTF-8使用了6个十六进制表示一个汉字编号。
Unicode和utf-8的关系和转换规则
参考:https://blog.csdn.net/zhusongziye/article/details/84261211,其中有utf-16和utf-32为什么不能普遍使用的原因。
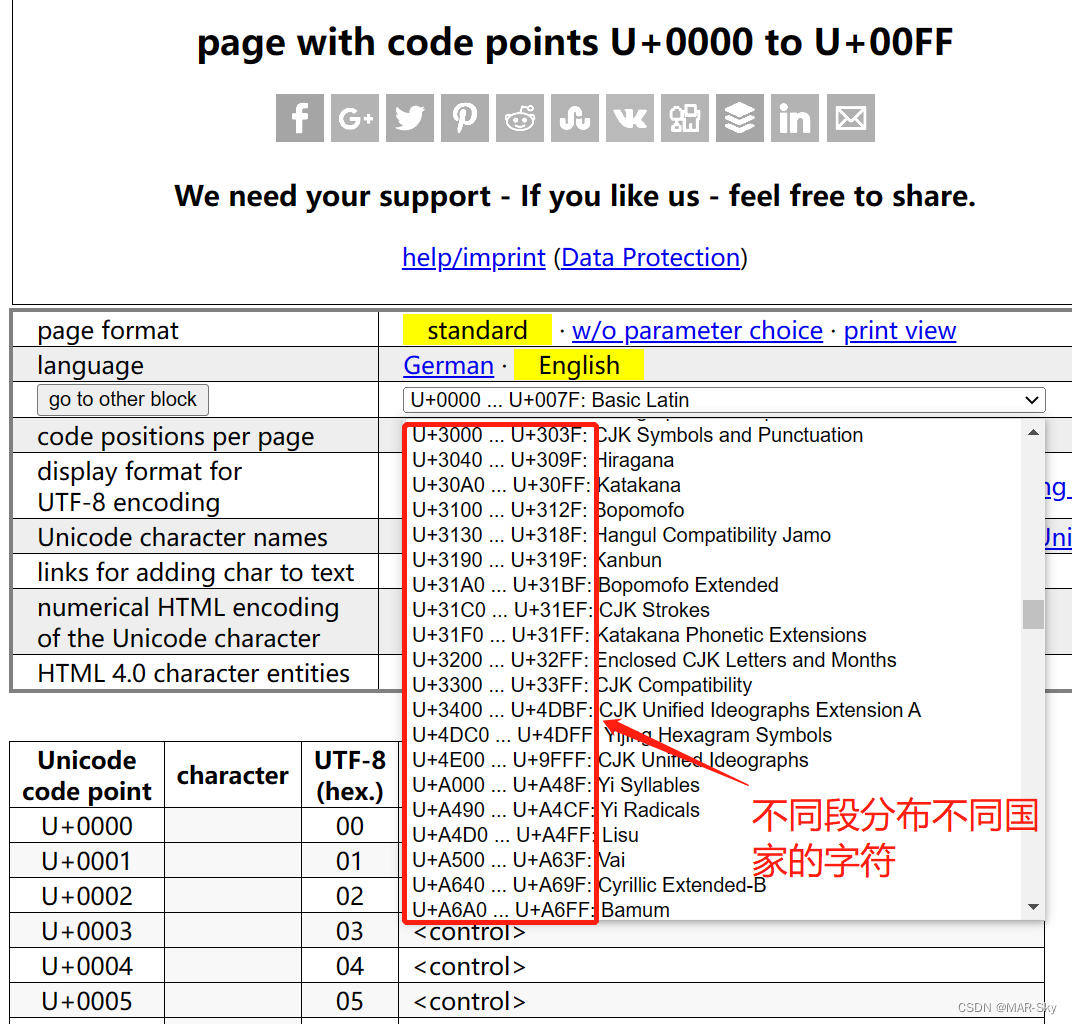
从根本来说utf-8实际上是从Unicode而来的。整体可以理解为所有文字语言都被Unicode逐个编码。但是并未规定每个字符占用空间。UTF-8则定义了不同值段对应的不同国家字符。CJK表示中国日本和韩国的字符。
下图中虽然标记的是URF-8编码转换,但实际是转换为了Unicode编码。
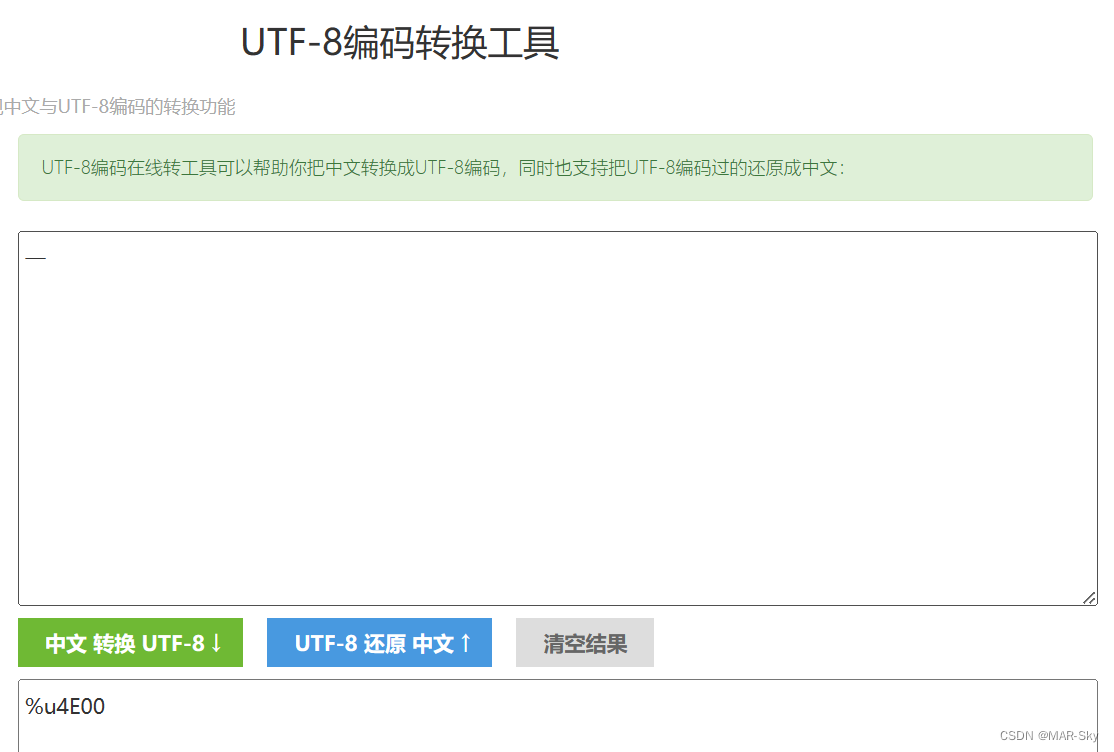
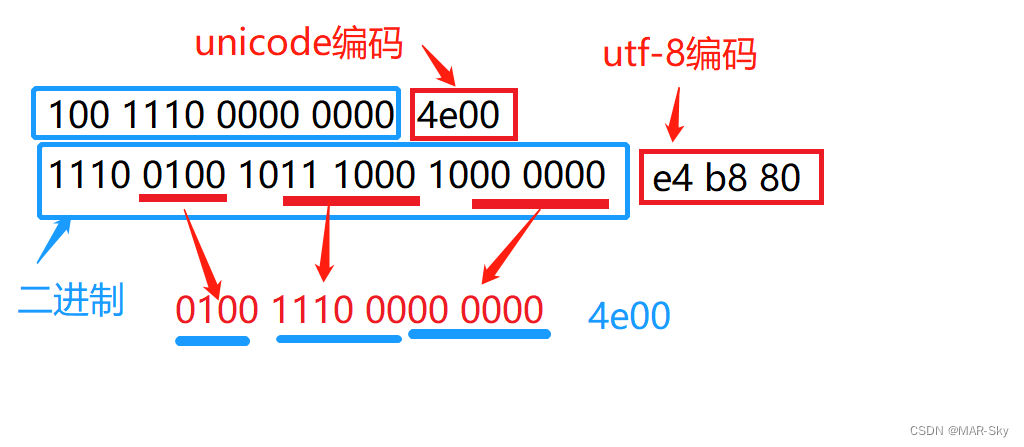
下面是最简单的汉字**“一”对应的编码方式**,也可以看出不同字段的编码值对应的存储空间也不同
**转换方式实例,**下面的字符“一”在utf-8的编码转换范围是在0x800-0xffff,根据规则可完成转换。
简单了解一下utf-32和utf-16
utf-32
直接把每个字符的存储使用4个字节,这样把大小值相同的unicode码直接放置到utf-32,不足的位只需要补零。
**缺点:**频繁使用编码值靠前的字符,会导致很多存储空间的浪费;四个字节的二进制位要定义那些是高位
可以根据他们高低字节的存储位置来判断他们所代表的含义,所以在编码方式中有 UTF-32BE 和 UTF-32LE,分别对应大端和小端
UTF-16 使用变长字节
① 对于编号在 U+0000 到 U+FFFF 的字符(常用字符集),直接用两个字节表示。 前一个字节表示的字符存储也会浪费空间。
② 编号在 U+10000 到 U+10FFFF 之间的字符,需要用四个字节表示。
也需要定义高位。就有 UTF-16BE 表示大端,UTF-16LE 表示小端