一、背景说明
RAG技术为大型语言模型(LLMs)提供了从数据源检索到的信息,以支撑其生成的答案。简而言之,RAG就是搜索加上LLM提示,你让模型在提供的信息上下文中回答问题。查询和检索到的上下文都被注入到发送给LLM的提示中。
传统的建模方式:
典型的RAG向量化应用程序有两个主要组件:
索引:从源中获取数据并对其进行向量化索引。
检索和生成:运行时接受用户查询转化成向量化数据,并从索引中检索相关数据,然后将其传递给LLM,生成内容。
实际使用过程中,上面简单的流程经常效果不能满足业务需求,核心问题在于如何检索并处理好传给LLM的内容,下面介绍几种优化思路以及LangChain的实现。
二、优化方法
2.1 多层索引
多层索引技术主要是针对海量的文档检索的处理策略,对面临需要从海量的文档中搜索、找到相关信息,并将这类信息综合成一个答案,并应用其来源。一般有2种方式建立多层索引来优化这类问题。
一种是为文档建立多级索引,比如建立文档的类别标签,在处理指定业务场景下的问答时,只需要对该类别下的知识库进行检索,如:
处理医疗领域的RAG问答业务时,可能会涉及很多的医学知识库,假设有1000篇文档,包括10个不同的医学研究方向。
当涉及的业务问题范畴只涉及外科相关知识时,可以通过类别标签进行筛选过滤,而无需从1000篇文档中进行全局检索。
第二种是从两个索引——一个是有该文档的摘要组成,一个由文档切片组成。在处理学术论文时,这类方法一般有较好的表现。这类方法的思路是分为两个步骤进行检索,首先通过摘要部分进行召回检索,过滤出可能和当前问题相关的候选文档集,然后再利用切片索引,从候选的文档集中进行检索,召回相关的知识切片。
2.2 假设性问题
首先解释一下什么是假设性问题: 假设性问题是一种提问方式,它基于一个或多个假设的情况或前提来提出问题。在对知识库中文档内容进行切片时,是可以以该切片为假设条件,利用LLM预先设置几个候选的相关性问题的,也就是说,这几个候选的相关性问题是和切片的内容强相关的。
在构建切片索引时,可以将对应的假设性问题进行向量化,并同时存储于向量库中。在RAG中的召回步骤中,对这个问题向量索引进行查询搜索,然后路由到原始文本块,并将它们作为上下文发送给LLM以获取答案。这种方法提高了搜索质量,因为与原始文本块相比,查询和假设问题之间的语义相似性更高。
除此以外,还有一种候选的假设性问题解决方案,和上述策略是对应的,它的核心思想可以表示为:
在要求LLM给定查询信息时,用LLM预先生成一个假设的响应,然后将其向量和查询向量一起使用,进一步提升检索的质量。示例如下:
问题: 感冒了怎么办?
大模型预设响应: 感冒了需要多休息,喝水,必要时就医。
召回时用问题和大模型预设响应进行拼接,形成新的prompt内容进行召回。
2.3 拓展上下文
检索较小的块以获得更好的搜索质量,但将周围的上下文一起拼接起来传给LLM推理。当然在索引的时候就要把数据处理好,搜索的时候才能找到周围的上下文。这么做的好处,就是小的文本块可以提升搜索的准确率,而扩展上下文则可以给LLM更丰富的内容。这里有两种拓展上下文的方式可以作为参考:
一种处理的方案是,通过分割和存储小块数据来实现,在检索过程中,它首先获取小块,然后查找这些块的父ID,并返回那些较大的文档。这种方式在langchain里有进行封装。
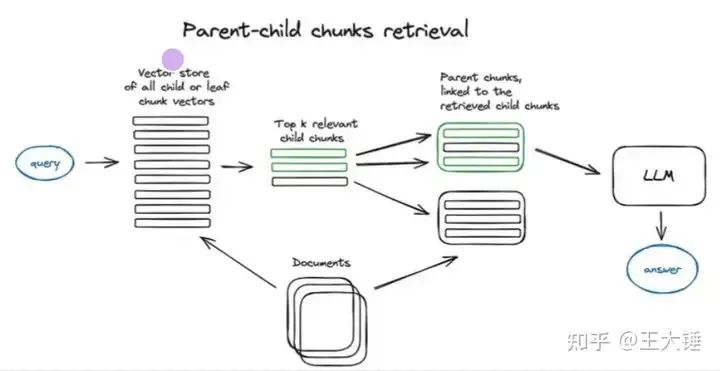

第二种是对更大的块进行检索,有时,完整文档可能太大而无法按原样检索它们。在这种情况下,我们真正想做的是首先将原始文档分割成更大的块,然后将其分割成更小的块。然后我们索引较小的块,但在检索时我们检索较大的块(但仍然不是完整的文档)。

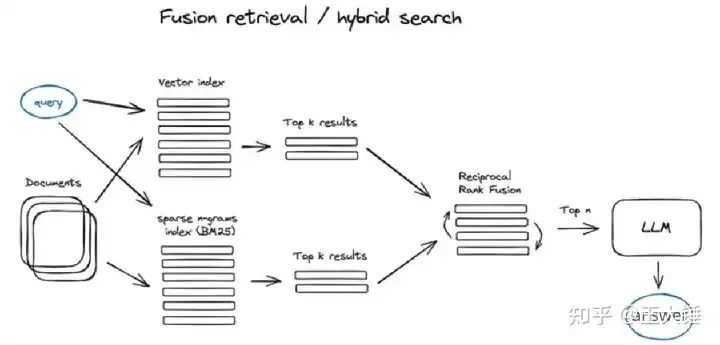
2.4 融合检索
将检索到的结果与不同的相似性分数适当地结合起来——这个问题通常是在倒排融合算法的帮助下解决的,该算法将检索得到的结果重新排序以获得最终输出。在LangChain中,这是在EnsembleRetriever类中实现的,它结合了您定义的检索器列表,例如faiss矢量索引和基于BM25的检索器,并使用RRF进行重新排序。混合或融合搜索通常会提供更好的检索结果,因为两种互补的搜索算法结合在一起,同时考虑了查询和存储文档之间的语义相似性和关键字匹配。

2.5 过滤与压缩
检索容易遇到的一个问题,当把数据向量化索引到数据库时,不太可能预想到对应的用户问题会是什么。这意味着,与查询最相关的信息可能隐藏在一个包含大量不相关文本的文档中,如果都一股脑传给LLM,不仅费用高(肉疼)而且效果可能也会受影响。
LLMChainFilter是一个简单的压缩器,使用LLM链来决定最初检索到的文档中的哪些要过滤掉,哪些要返回,而无需操作文档内容。嗯。。。这个,我就是因为不想调用LLM费钱处理才采用这个方案的吗?EmbeddingsFilter通过嵌入文档和查询并只返回那些与查询具有足够相似嵌入的文档,提供了一个更便宜、更快的选项。
LLMChainFilter的用法:

EmbeddingsFilter的用法:
from langchain.retrievers.document_compressors import EmbeddingsFilter
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
embeddings_filter = EmbeddingsFilter(embeddings=embeddings, similarity_threshold=0.76)
compression_retriever = ContextualCompressionRetriever(
base_compressor=embeddings_filter, base_retriever=retriever
)
compressed_docs = compression_retriever.get_relevant_documents(
"What did the president say about Ketanji Jackson Brown"
)
pretty_print_docs(compressed_docs)
2.6 元数据过滤
我们已经习惯了SQL查询的时候增加Where的限制条件,这个可以精确查询所需的数据。RAG也不是所有的时候都要通过语义或关键词检索。比如检索“所有评分大于8分的电影”,或者我们公司实际的业务场景,检索的时候只需要明确某个品牌的数据。
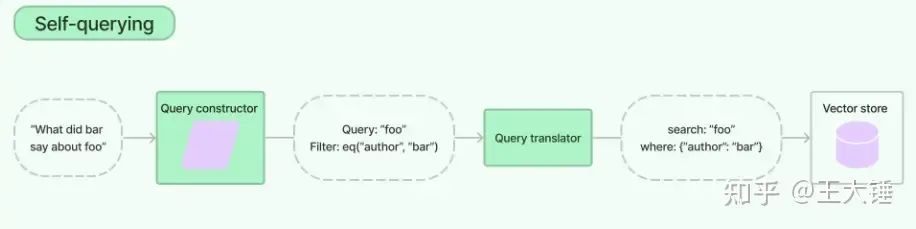
通过元数据过滤实现精确过滤,和语义检索配合。在存储数据块到向量数据块时,需要先处理好元数据,在我们公司的场景中,就是把所属的品牌ID一起存储。检索的时候可以利用大模型的理解能力,把自然语言转成元数据过滤。看看LangChain的实现,metadata_field_info是pydantic的格式。
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
metadata_field_info=[
AttributeInfo(
name="genre",
description="The genre of the movie",
type="string or list[string]",
),
AttributeInfo(
name="year",
description="The year the movie was released",
type="integer",
),
AttributeInfo(
name="director",
description="The name of the movie director",
type="string",
),
AttributeInfo(
name="rating",
description="A 1-10 rating for the movie",
type="float"
),
]
document_content_description = "Brief summary of a movie"
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(llm, vectorstore, document_content_description, metadata_field_info, verbose=True)
2.7 时间加权
对于一些类似客服FAQ的场景,检索命中越频繁,数据的权重就越高,可以使用了语义相似性和时间衰减的组合。LangChain给出的计算公式是这样的。

hours_passed是指自上次访问检索器中的对象以来(而不是自创建对象以来)经过的小时数。这意味着频繁访问的对象保持“新鲜”。
还有另一种时间权重,比如新闻资讯,创建时间越近权重越高,甚至可以为其设置过期时间。
RAG应用系统中,大家比较关心的因素:准确率、速度、成本。上面讨论的方案基本上都是提升准确率的,同时带来的问题就是速度下降,部分方案会成本上升。
另一方面,在实际的业务场景中,准确率可能是现阶段最重要的问题,业务人员对于应用的要求可能是90分,而LLM目前的能力只能达到60分,如果不能通过其它的方式提升效果,那么应用可能无法在实际场景中使用了。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

![[游戏开发][UE5]引擎学习记录](https://img-blog.csdnimg.cn/direct/a0ee1c2ccf7349128c2c6f29f9b601f1.png)