一、ClickHouse基础
1.1 ClickHouse介绍
ClickHouse是一个用于联机分析(OLAP)的列式DBMS。
简单来说,相比MySQL等行式数据库,数据存储方式是:
| Row | id | is_del | title | sex | createAt |
|---|---|---|---|---|---|
| #0 | 2 | 1 | a | 1 | 2024/2/18 5:19 |
| #1 | 3 | 0 | b | 1 | 2024/2/18 8:10 |
| #2 | 4 | 1 | c | 1 | 2024/2/18 7:38 |
| #N | … | … | … | … | … |
即是:处于同一行中的数据总是被物理的存储在一起。
在列式数据库系统中,数据按如下的顺序存储:
| Row: | #0 | #1 | #2 | #N |
|---|---|---|---|---|
| id | 2 | 3 | 4 | … |
| is_del | 1 | 0 | 1 | … |
| title | a | b | c | … |
| sex | 1 | 1 | 1 | … |
| createAt | 2024/2/18 5:19 | 2024/2/18 8:10 | 2024/2/18 7:38 | … |
即是:来自不同列的值被单独存储,来自同一列的数据被存储在一起。
这种数据存储方式适用不同的业务场景,数据访问的场景包括:
1.进行了何种查询、多久查询一次以及各类查询的比例;
2.每种类型的查询(行、列和字节)读取多少数据;
3.读取数据和更新之间的关系;
4.使用的数据集大小以及如何使用本地的数据集;
5.是否使用事务,以及它们是如何进行隔离的;
6.数据的复制机制与数据的完整性要求;
7.每种类型的查询要求的延迟与吞吐量
做个例子,以下表数据为例:
| id | name | age |
|---|---|---|
| 1 | 张三 | 12 |
| 2 | 李四 | 13 |
| 3 | 王五 | 14 |
行式存储,数据在磁盘的组织结构:

列式存储,数据在磁盘的组织结构:

行式存储应用场景在查询某个人的所有属性,只需根据索引一次磁盘查找加顺序读取即可。但是当列变多,每次只查询一列或者某几列(统计所有人年龄平均值),如果还是行式存储数据,需要全表扫描,遍历很多数据都是不需要的。而列式存储想查询所有人年龄,只需把年龄一列拿出即可
1.2 OLAP和OLTP
OLTP(On-Line Transaction Processing):联机事务处理,典型代表是关系型数据库(如MySQL),它的数据存储在服务器本地的文件里
OLAP(On-Line Analytical Processing):联机分析处理,OLAP型数据库的典型代表是分布式文件系统(hive),它的数据存储在HDFS集群里
| OLTP | OLAP | |
|---|---|---|
| 业务目的 | 处理业务,如订单,进销存 | 业务支持决策 |
| 面向对象 | 业务处理人 | 分析决策人 |
| 主要工作负载 | 增删改 | 查询 |
| 主要衡量指标 | 事务吞吐量 | 查询响应速度(QPS) |
| 数据库设计 | 3NF/BCNF | 星型/雪花模型 |
1.3 OLAP场景的关键特征
- 绝大多数是读请求
- 数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
- 已添加到数据库的数据不能修改。
- 对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
- 宽表,即每个表包含着大量的列
- 查询相对较少(通常每台服务器每秒查询数百次或更少)
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每个查询有一个大表。除了他以外,其他的都很小。
- 查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
可以看出,OLAP场景与其他通常业务场景(例如,OLTP或K/V)有很大的不同, 因此想要使用OLTP或Key-Value数据库去高效的处理分析查询场景,并不是非常完美的适用方案。
1.4 列式数据库更适合OLAP场景的原因
输入/输出
- 针对分析类查询,通常只需要读取表的一小部分列。在列式数据库中你可以只读取你需要的数据。例如,如果只需要读取100列中的5列,这将帮助你最少减少20倍的I/O消耗。
- 由于数据总是打包成批量读取的,所以压缩是非常容易的。同时数据按列分别存储这也更容易压缩。这进一步降低了I/O的体积。
- 由于I/O的降低,可以让更多的数据被系统缓存。
例如,查询«统计每个广告平台的记录数量»需要读取«广告平台ID»这一列,它在未压缩的情况下需要1个字节进行存储。如果大部分流量不是来自广告平台,那么这一列至少可以以十倍的压缩率被压缩。当采用快速压缩算法,它的解压速度最少在十亿字节(未压缩数据)每秒。换句话说,这个查询可以在单个服务器上以每秒大约几十亿行的速度进行处理。这实际上是当前实现的速度。
CPU
由于执行一个查询需要处理大量的行,因此在整个向量上执行所有操作将比在每一行上执行所有操作更加高效,减少调用成本的查询引擎。
数据压缩
能存储大量数据的数据库都是采用列式存储的,它压缩比极高,如果压缩比低,是无法存储海量数据的,数据库的存储格式决定了存储的体积。
行式存储每一行的数据格式不同,有数字,文本,日期型等,很大的问题就是,不同的格式无法采用统一的压缩格式,而列式存储一列是一个数据块,是同一个数据格式,很好的弥补了压缩比低的缺点。
压缩比高好处是同样规模的数据,占用的空间小,可以节省磁盘,更重要的是可以节省内存,对于内存小的可以将更多的数据放到其中,如对于128G内存能够管理的列式存储的数据远远大于行式存储的数据,这样管理行式存储的数据需要分布式,代理中间件等,十分复杂,列式存储可能一台机器就足够了,节省资源。
列式储存的好处:
1.对于列的聚合,计数,求和等统计操作原因优于行式存储,只需要遍历一个数据块,而行式存储则需要遍历所有的数据块。
由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列选择更优的数据压缩算法,大大提高了数据的压缩比重。
2.由于数据压缩比更好,一方面节省了磁盘空间,另一方面对于cache也有了更大的发挥空间。
列式存储的劣势:
1.不支持事务。
2.对行级别的查询不方便,列式存储一般负责范围的查询。
1.5 读与写
写(MergeTree)
ClickHouse采用类LSM Tree的结构(HBase也使用的这种结构),数据写入后定期在后台合并。通过类LSM tree的结构,但没有内存表,没有预写日志,ClickHouse在数据导入时全部是顺序append写入磁盘,在后台周期性合并数据到主数据段。顺序写的特性,充分利用了磁盘的吞吐能力,即便在HDD上也有着优异的写入性能。
尤其是当在批量插入的场景下,MySQL是真正的将数据一条一条的写入到数据库中,磁盘一致地在移动,而ClickHouse会将大量的数据直接放到临时分区中,然后ClickHouse会自动调用进程去后台处理,compaction 时也是多个段 merge sort 后顺序写回磁盘。
读(MergeTree)
(1)稀疏索引
索引:用于查询,通过索引可以查找到数据的具体位置,关系型数据库中默认没有索引,但一般来说每张表都需要加一个主键,主键就是索引,在hive中,分区也相当于一个索引,这两种索引的不同在于粒度。
MySQL一般使用稠密索引,即尽可能的让每一条数据都有一个索引,对应公交车的站牌,可以精确定位到一个地点。
clickhouse使用稀疏索引,索引之间的颗粒度(默认8192行),对应火车站的车站,可以定位到一个范围,想找到具体的数据,还需要在这个范围内进行逐表扫描。
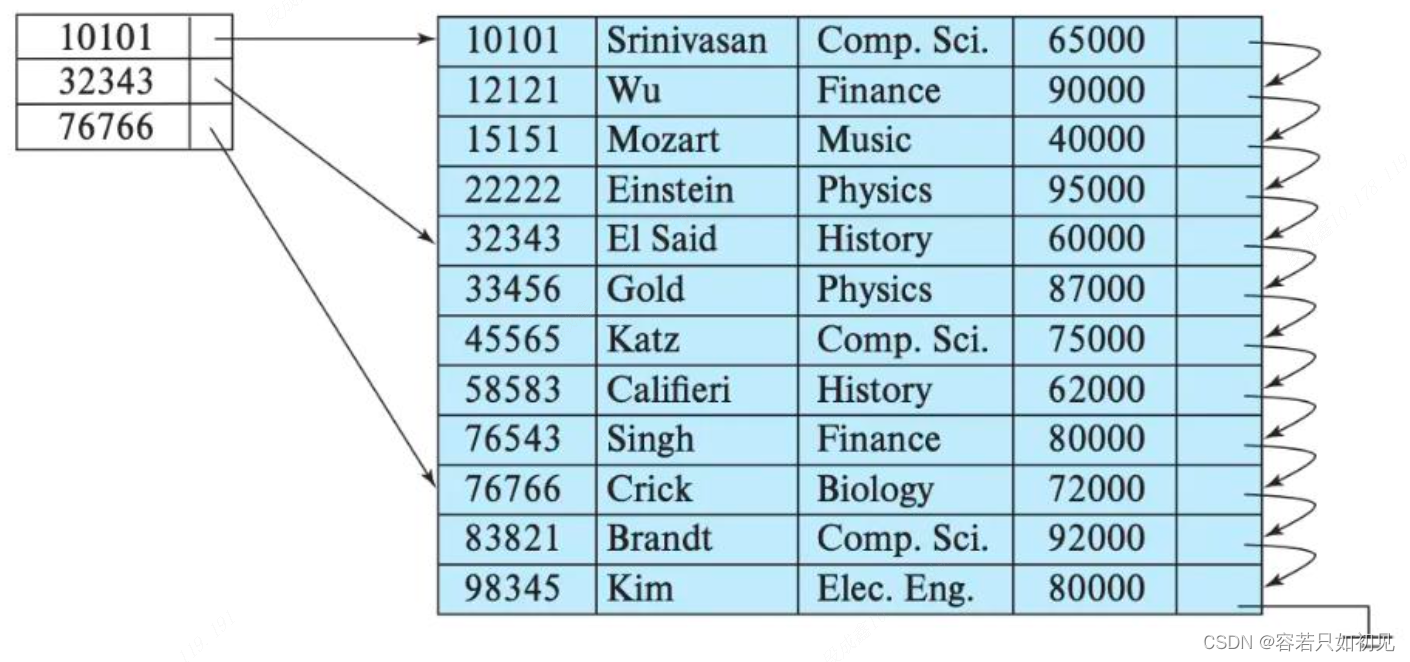
稀疏索引的好处是可以用很少的索引数据,定位更多的数据,范围查询过滤比较快,代价是只能定位到索引粒度第一行,然后再逐个扫描数据,不适合做点对点查询。对于稠密和稀疏两种设计思路没有好坏,只有取舍,而语句级多线程就是针对稀疏索引的缺点做的一些优化。
(2)语句级多线程
MySQL是多线程,但不是语句级的,其处理任意一条SQL,只使用一个线程,MySQL可以执行多条SQL,所以多线程这个功能也不会浪费,对多条SQL开多个线程,不同SQL之间互相独立。
ClickHouse不同,它会针对一条SQL启动多个线程共同完成,如上图中,会在10101 - 22222,32343 - 76543,76766 - 98345会启动三个线程同时进行查询,在ClickHouse中每一个间隔都称为颗粒,默认为8192行,即一个线程最多扫描8192行。
ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity(索引颗粒),然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。
在这种设计下,单条Query就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时。
MySQL一般接受简单、数据量小的查询(业务系统),导致QPS相对较高,每个查询的资源较少,只有一个线程对一个查询,但是可以支持更多查询。
ClickHouse适合复杂数据量大的查询(分析系统),QPS不高,每个查询投入的资源更多,多个线程对一个查询,但是支持的查询更少。
弊端:clickhouse即使对于大量数据的查询也能够化整为零平行处理。但是有一个弊端就是对于单条查询使用多cpu,就不利于同时并发多条查询。所以对于高qps的查询业务,clickhouse并不是强项。
1.6多样化引擎
ClickHouse 和 MySQL 类似,把表级的存储引擎插件化,根据表的不同需求可以设定不同
的存储引擎。目前包括合并树、日志、接口和其他类这四大类 20 多种引擎。
Clickhouse 中最强大的表引擎是 MergeTree (合并树)引擎及该系列(MergeTree)中的其他引擎。 MergeTree 系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。
合并树系列:MergeTree、ReplacingMergeTree(分区内主键去重)、CollapsingMergeTree(标记列 Sign)、VersionedCollapsingMergeTree(快速写入不断变化的对象状态)、SummingMergeTree(对主键列进行预先聚合)、AggregatingMergeTree(高级预先聚合)
对于MergeTree的一些理解:
1.存储的数据按主键排序。 这使得能够创建一个小型的稀疏索引来加快数据检索。
2.如果指定分区键的话,可以使用分区。在相同数据集和相同结果集的情况下ClickHouse中某些带分区的操作会比普通操 作更快。查询中指定分区键时ClickHouse会自动截取分区数据,有效增加查询性能。
3.支持数据副本。 ReplicatedMergeTree系列的表提供了数据副本功能
4.支持数据采样。需要时可以给表设置一个采样方法。
–MergeTree建表语句
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name (
name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
name2 [type] [DEFAUErEMAMLERLALLIZED|ALIAS expr],
省略...
) ENGINE = MergeTree()
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name=value, 省略...]
order by 设定分区内的数据按照哪些字段顺序进行有序保存。 order by 是 MergeTree 中唯一一个必填项,甚至比 primary key 还重要,因为当不设置主键的情况,很多处理会依照 order by 的字段进行处理(比如去重和汇总)。 要求:主键必须是 order by 字段的前缀字段。 比如: order by 字段是 (id, u_id) ,那主键必须是 id 或者(id, u_id)
1.7 基于ClickHouse构建标签画像示例
1.标签表结构演进
表结构:
| tag_id | user_id |
|---|---|
| tagnum1 | 101 |
| tagnum1 | 102 |
| tagnum2 | 101 |
| tagnum3 | 101 |
#####DDL
CREATE TABLE ......ORDER BY (tag_id,user_id)
engine=MergeTree()
###用户圈选,交集
SELECT user_id FROM xxx WHERE tag_id=1 AND
user_id IN (select user_id from xxx
where tag_id =2
)
where tagID= 1
###用户画像,基于人群进行画像分析
SELECT tag_id ,count(1) FROM xxx AND
uid IN (select user_id from xxx
where tag_id =2
)and tag_id in (4,5,6,7)
GROUP BY tag_id
优势:
-
表结构简单,标签扩展简单
-
同一个uid 数据只在shard,增加并行查询效率
劣势:
-
标签和用户量增加,数据行数膨胀迅速,查询效率衰减明显
-
多条件嵌套查询SQL 复杂
2.标签表结构演进
| user_id | tag1 | tag2 | tagN |
|---|---|---|---|
| 101 | F | 10 | 20 |
| 101 | M | 20 | 30 |
| 102 | M | 10 | 30 |
| … | … | … | … |
#####DDL:
CREATE TABLE( ......
user_id UInt64,
tag1 SimpleAggregateFunction(anyLast, Nullable(Enum(‘女’ = F, '男’ = M)
.........
)
ORDER BY uid ENGINE= AggregatingMergeTree()
###用户圈选,交集
SELECT uid FROM table_users WHERE anyLastMerge(tag1)=‘F ’ AND
anyLast(tag2)= 10
### 用户标签详情
SELECT uid FROM table_users WHERE anyLastMerge(tagID)=‘F ’
AND anylastMerge(tag2)= 10
###用户画像,基于已有人群进行用户画像分析
SELECT tag1 ,count(1) FROM table_users AND
user_id IN (select user from xxx
where tag2 =10
)GROUP BY tag
优缺点:
- 数据行数减少,SQL 语句简单
- SimpleAggregateFunction (anylast,…)支持标签值更新
- 交,并,差,SQL表达复杂(在线分析效率低)
3.标签表结构演进
| tag | tag_value | user_ids(bitmap) |
|---|---|---|
| tag1 | F | (101,102,103,) |
| tag1 | M | (104,105,) |
| tag3 | 20 | (101,) |
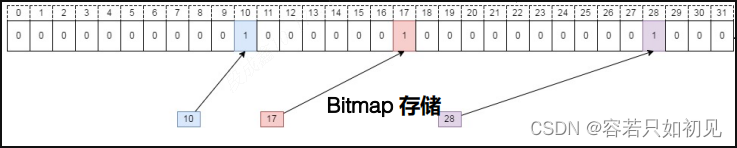
数据存储与同步
###离线任务计算标签结果:
create table label_local(
tag String ,
tag_value String ,
user_id UInt64
)
ENGINE = MerTree()
partition by tag
order by tag,tag_value
### bitmap标签表
create table label_bitmap_local
(
tag String comment '标签名称',
tag_value String comment '标签值',
user_ids AggregatingMergeTree()
)
partition by tag
order by (tag,tag_value)
settings index_granularity = 128;
###数据导入
insert into table label_bitmap_local
select
tag,
tag_value,
groupBitmapState(user_id)
from label_local
group by tag,tag_value
使用bitmap做人群(群体)圈选
with
(
select groupbitmapMergeState(user_ids) //获取满足条件数据包
from label_bitmap_local
where tag='性别' and tag_value = '女'
)as user_group_1,
(
select groupbitmapMergeState(user_ids)
from label_bitmap_local
where tag='年龄段' and tag_value = '18-30'
) as user_group_2
select bitmapToArray(bitmapAnd(user_group_1,user_group_2)) //求交集,转数组
### Result = (性别=女生) ∩(年龄段=18-30)= 年轻女性
群体分析
###人群预估,群体基数
select bitmapCardinality(bitmapAnd(user_group_1,user_group_2))
###查询个人是否存在群体中
select bitmapContains(bitmapAnd(user_group_1,user_group_2),user_id)
### 查询群体是否存在公共元素
select bitmapHasAny(user_group_1,user_group_2)
### 群体是否包含另一群体所有
select bitmapHasAll(user_group_1,user_group_2)
###圈定群体(年轻女性)其他情况分布(消费水平)
with
(
select bitmapAnd(user_group_1,user_group_2)
) as filter_users
select bitmapCardinality(bitmapAnd(filter_users, group_by_users)) AS count,
tag,
tag_value
from (
SELECT groupBitmapMergeState(user_ids) AS group_by_users, tag, tag_value
FROM lable_bitmap_local
WHERE tag = "消费水平"
GROUP BY (tag, tag_value)
);
//年轻女性群体消费能力分布
1.8 缺点、局限
不支持事务,不支持真正的删除/更新;
数据一致性差,或者只能保证最终数据一致性
适用宽边多维度分析查询,多表join性能差 可以使用物化视图进行优化
不支持高并发,官方建议qps为100 Clickhouse快是由于采用了并行处理机制,即便一个查询,也会用服务器一半的CPU去执行,因此ClickHouse不能支持高并发的使用场景,默认单查询使用CPU核数为服务器核数的一半
1.9优化
1.建议每次写入多于1000行的批量写入,或每秒不超过一个写入请求
2.同一个分区的 两个part的数据量都很大,然后后台自动的merge合并成一个的时候,会消耗大量的cpu 控制merge的线程,后台默认的线程数是16 降低线程数的配置; 实时的数据尽量在ssd上.
3.选择更加合适的引擎
4.建表优化:尽量不使用 Nullable 类型,避免数据出现大量空值字段,空值会被单独存储,字段可以设置默认值;
5.分区粒度:分区粒度根据业务场景特性来设置,不宜过粗也不宜过细。我们的数据一般都是按照时间来严格划分,所以都是按天、按月来划分分区。如果索引粒度过细按分钟、按小时等划分会产生大量的分区目录,更不能直接 PARTITION BY create_time ,会导致分区数量惊人的多,几乎每条数据都有一个分区会严重的影响性能。
1.9.1慢查询优化
ClickHouse 在 20.6 版本后已经提供查看查询计划的原生 EXPLAIN,但是提供的信息对慢 SQL 优化提供的帮助不是很大,推荐使用查看服务日志这种方式进行分析,这种方式需要使用 clickhouse-client 进行执行 SQL 语句。
举个栗子,通过query_log_all 定位到一个慢 SQL:
select ifNull(sum(price), 0) as total_price
from wms.wms_order_sku_local final
prewhere tranTime = '2024-02-27 08:00:00' and orderType = '10'
where is_del = '0' and is_valid = '0'
使用 clickhouse-client,send_logs_level 参数指定日志级别为 trace。
clickhouse-client -h 地址 --port 端口 --user 用户名 --password 密码 --send_logs_level=trace
在 client 中执行上述慢 SQL,服务端打印核心日志如下:
1.(SelectExecutor): Key condition: unknown 没有使用主键索引:导致全表扫描
2.(SelectExecutor): MinMax index condition: unknown 没有使用分区索引:导致全表扫描
3.MemoryTracker: Peak memory usage (for query): 60.37 MiB. 查询语句消耗的内存最大为 60.37MB
4.(SelectExecutor): Selected 36 parts by date, 9390 marks by primary key 共扫描 36 个 parts,9390 个 MarkRange,查询system.parts系统分区信息表发现当前表共拥有36个活跃分区,相当于全表扫描。
所以需要再查询条件上添加主键字段或者分区索引来进行优化。比如将tranTime为分区键,在添加这个条件后可以看到没有使用主键索引,但使用分区索引,扫描分片数为 6,MarkRange 186,共扫描 1409001 行数据,使用内存 40.76MB,扫描数据大小等大幅度降低节省大量服务器资源,并且提升了查询速度,0.267s 降低到 0.18s。
1.9.2条件聚合函数降低扫描数据行数
假设要统计某天的” 入库件量”,” 有效出库单量”,” 复核件量”三个指标。
-- 入库件量:select sum(qty) from table_1 final prewhere type = 'inbound' and dt = '2024-01-01';
-- 有效出库单量:select count(distinct orderNo) final from table_1 prewhere type = 'outbound' and dt = '2024-01-01' where and status = '1' ;
-- 复核件量:select sum(qty) from table_1 final prewhere type = 'check' and dt = '2024-01-01';
查询三个指标需要上述三个 SQL 语句查询 table_1 来完成,但dt 是一致的,区别在于 type 和 status 两个条件。假设 dt = ‘2024-01-1’ 每次查询需要扫描 100W 行数据,那么一次接口请求将会扫描 300W 行数据。通过条件聚合函数优化后将三次查询改成一次,那扫描行数将降低为 100W 行,可极大的节省集群计算资源。
select sumIf(qty, type = 'inbound'),
-- 入库件量countIf(distinct orderNo, type = 'outbound' and status = '1'),
-- 有效出库单量sumIf(qty, type = 'check')
-- 复核件量prewhere dt = '2024-01-01';
条件聚合函数比较灵活,可根据业务情况自由发挥,核心是减少整体的扫描量,来提升查询性能。
1.9.3二级索引
MergeTree 系列的表引擎可以指定跳数索引。
跳数索引是指数据片段按照粒度 (建表时指定的 index_granularity) 分割成小块后,将 granularity_value 数量的小块组合成一个大的块,对这些大块写入索引信息,这样有助于使用 where 筛选时跳过大量不必要的数据,减少 SELECT 需要读取的数据量。
CREATE TABLE table_name(u64 UInt64,
i32 Int32,
s String, ...
INDEX a (u64 * i32, s)
TYPE minmax GRANULARITY 3,
INDEX b (u64 * length(s))
TYPE set(1000) GRANULARITY 4) ENGINE = MergeTree()...
上例中的索引能让 ClickHouse 执行下面这些查询时减少读取数据量。
SELECT count() FROM table WHERE s < 'z' SELECT count() FROM table WHERE u64 * i32 == 10 AND u64 * length(s) >= 1234
支持的索引类型:
1.minmax:以 index granularity 为单位,存储指定表达式计算后的 min、max 值;在等值和范围查询中能够帮助快速跳过不满足要求的块,减少 IO。
2.set (max_rows):以 index granularity 为单位,存储指定表达式的 distinct value 集合,用于快速判断等值查询是否命中该块,减少 IO。
3.ngrambf_v1 (n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed):将 string 进行 ngram 分词后,构建 bloom filter,能够优化等值、like、in 等查询条件。
4.tokenbf_v1 (size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed): 与 ngrambf_v1 类似,区别是不使用 ngram 进行分词,而是通过标点符号进行词语分割。
5.bloom_filter ([false_positive]):对指定列构建 bloom filter,用于加速等值、like、in 等查询条件的执行。
创建二级索引:
Alter table wms.wms_order_sku_local
ON cluster default
ADD INDEX belongProvinceCode_idx belongProvinceCode
TYPE set(0) GRANULARITY 5;
Alter table wms.wms_order_sku_local
ON cluster default
ADD INDEX productionEndTime_idx productionEndTime
TYPE minmax GRANULARITY 5;
重建分区索引数据:在创建二级索引前插入的数据,不能走二级索引,需要重建每个分区的索引数据后才能生效
-- 拼接出所有数据分区的MATERIALIZE语句
select concat('alter table wms.wms_order_sku_local on cluster default ', 'MATERIALIZE INDEX productionEndTime_idx in PARTITION '||partition_id||',')from system.partswhere database = 'wms' and table = 'wms_order_sku_local'group by partition_id
-- 执行上述SQL查询出的所有MATERIALIZE语句进行重建分区索引数据
1.9.4final 替换 argMax 进行去重
对比下 final 和 argMax 两种方式的性能差距,如下 SQL
-- final方式:
select count(distinct groupOrderCode), sum(arriveNum), count(distinct sku) from tms.group_order final prewhere siteCode = 'WG0001544' and createTime >= '2024-02-24 22:00:00' and createTime <= '2024-02-27 22:00:00' where arriveNum > 0 and test <> '1'
-- argMax方式:
select count(distinct groupOrderCode), sum(arriveNumTemp), count(distinct sku) from (select argMax(groupOrderCode,version) as groupOrderCode, argMax(arriveNum,version) as arriveNumTemp, argMax(sku,version) as sku from tms.group_order prewhere siteCode = 'WG0001544' and createTime >= '2024-02-24 22:00:00' and createTime <= '2024-02-27 22:00:00' where arriveNum > 0 and test <> '1' group by docId)
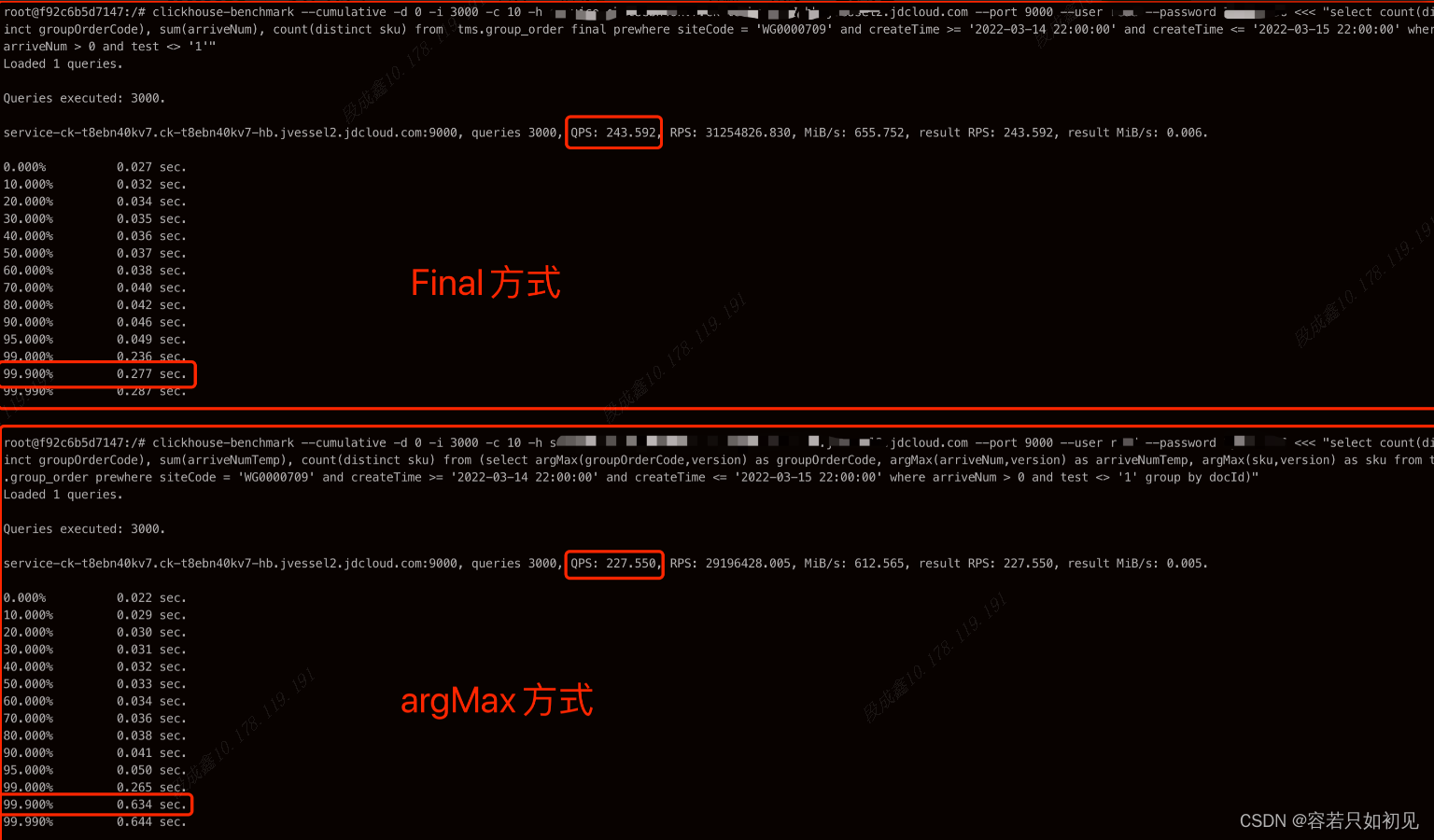
final 方式的 TP99 明显要比 argMax 方式优秀很多
1.9.5prewhere 替代 where
ClickHouse 的语法支持额外的 prewhere 过滤条件,它会先于 where 条件进行判断,可以看做是更高效率的 where,作用都是过滤数据。当在 sql 的 filter 条件中加上 prewhere 过滤条件时,存储扫描会分两阶段进行,先读取 prewhere 表达式中依赖的列值存储块,检查是否有记录满足条件,再把满足条件的其他列读出来。以下述的 SQL 为例,其中 prewhere 方式会优先扫描 type,dt 字段,将符合条件的列取出来,当没有任何记录满足条件时,其他列的数据就可以跳过不读了。相当于在 Mark Range的基础上进一步缩小扫描范围。prewhere 相比 where 而言,处理的数据量会更少,性能会更高。
-- 常规方式:
select count(distinct orderNo) final from table_1 where type = 'outbound' and status = '1' and dt = '2024-01-01';
-- prewhere方式:
select count(distinct orderNo) final from table_1 prewhere type = 'outbound' and dt = '2024-01-01' where and status = '1' ;
PS小坑:prewhere 会优先于 final 进行执行,所以对于 status 这种值可变的字段处理过程中,能够查询到中间状态的数据行,导致最终数据不一致。
| id | version | status | orderNo | type | dt |
|---|---|---|---|---|---|
| 1 | 11 | 0 | 1311 | outbound | 2024-01-01 |
| 1 | 12 | 1 | 1311 | outbound | 2024-01-01 |
| 1 | 13 | 2 | 1311 | outbound | 2024-01-01 |
如表所示,id:1 的业务数据,进行三次写入,到 version=13 的数据是最新版本数据,当我们使用 where 过滤 status 这个可变值字段时,语句 1,语句 2 结果如下。
--语句1:使用where + status=1 查询,无法命中id:1这行数据,select count(distinct orderNo) final from table_1 where type = 'outbound' and dt = '2024-01-01' and status = '1';
--语句2:使用where + status=2 查询,可以查询到id:1这行数据,select count(distinct orderNo) final from table_1 where type = 'outbound' and dt = '2024-01-01' and status = '2';
当我们prewhere 后,语句 3 写法:prewhere 过滤 status 字段时将 status=1,version=12 的数据会过滤出来,导致我们查询结果不正确。正确的写法是将不可变字段使用 prewhere 进行优化。
-- 语句3:错误方式,将status放到prewhere
select count(distinct orderNo) final from table_1 prewhere type = 'outbound' and dt = '2024-01-01' and status = '1';
-- 语句4:正确prewhere方式,status可变字段放到where上
select count(distinct orderNo) final from table_1 prewhere type = 'outbound' and dt = '2024-01-01' where and status = '1' ;
其他限制:prewhere 目前只能用于 MergeTree 系列的表引擎
1.9.6 where、group by 顺序
where 和 group by 中的列顺序,要和建表语句中 order by 的列顺序统一,并且放在最前面使得它们有连续不间断的公共前缀,否则会影响查询性能。
-- 建表语句create table group_order_local( docId String, version UInt64, siteCode String, groupOrderCode String, sku String, ... 省略非关键字段 ... createTime DateTime) engine = ReplicatedReplacingMergeTree('/clickhouse/tms/group_order/{shard}', '{replica}', version)PARTITION BY toYYYYMM(createTime)ORDER BY (siteCode, groupOrderCode, sku);
--查询语句1:
select count(distinct groupOrderCode) groupOrderQty, ifNull(sum(arriveNum),0) arriveNumSum,count(distinct sku) skuQty from tms.group_order final prewhere createTime >= '2024-01-01 22:00:00' and createTime <= '2024-02-01 22:00:00'and siteCode = 'WG0000709'where arriveNum > 0 and test <> '1'
--查询语句2 (where/prewhere中字段):
select count(distinct groupOrderCode) groupOrderQty, ifNull(sum(arriveNum),0) arriveNumSum,count(distinct sku) skuQty from tms.group_order final prewhere siteCode = 'WG0000709' and createTime >= '2024-01-01 22:00:00' and createTime <= '2024-02-01 22:00:00'where arriveNum > 0 and test <> '1'
建表语句 ORDER BY (siteCode, groupOrderCode, sku),语句 1 没有符合要求经过压测 QPS6.4,TP99 0.56s,语句 2 符合要求经过压测 QPS 14.9,TP99 0.12s
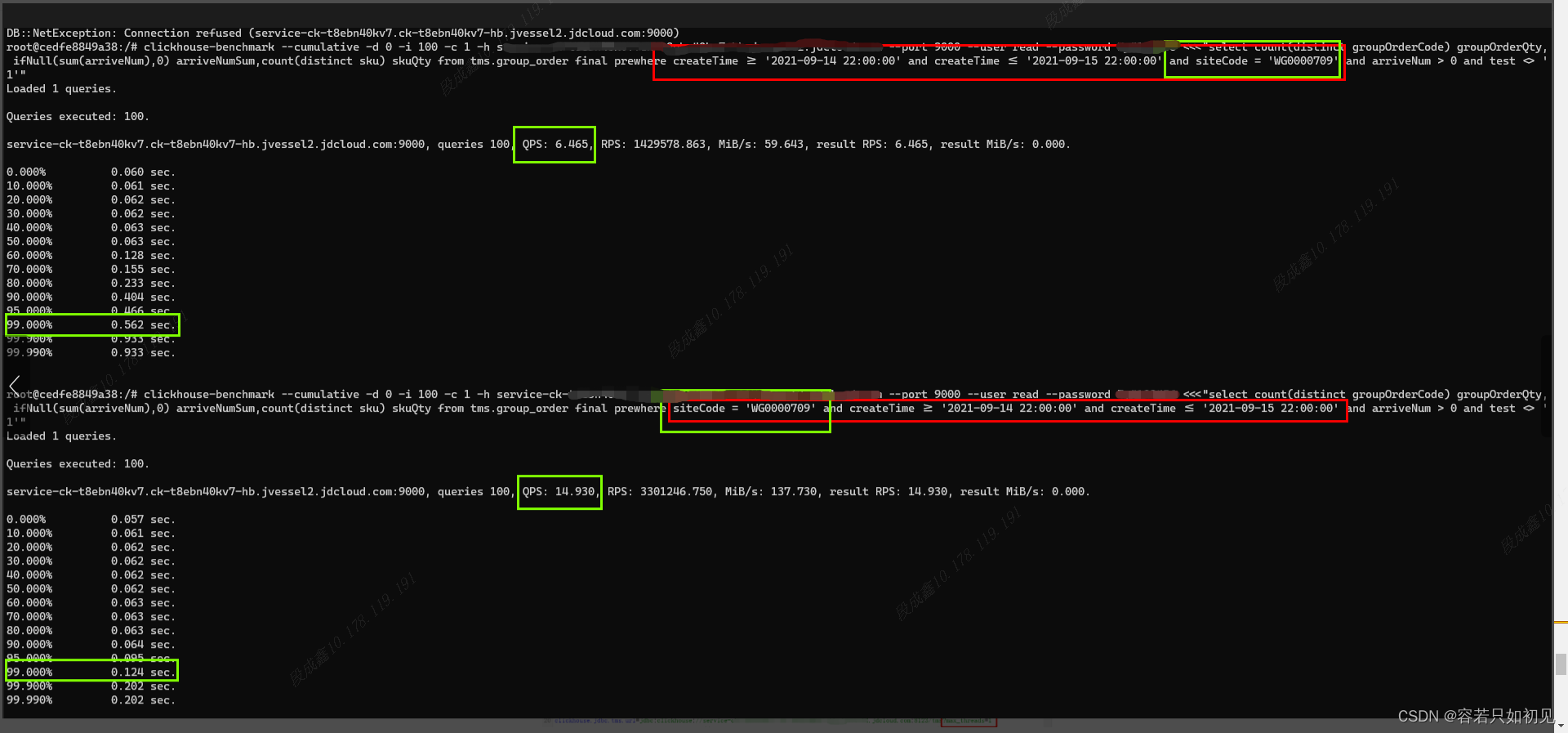
1.9.7性能测试
clickhouse 提供的一个 clickhouse-benchmark 性能测试工具,可通过 docker 搭建 CK 环境。
clickhouse-benchmark -c 1 -h 链接地址 --port 端口号 --user 账号 --password 密码 <<< "具体SQL"
通过这种方式可以了解 SQL 级别的 QPS 和 TP99等信息,这样就可以测试语句优化前后的性能差异。
1.10 保证高并发 ClickHouse 可用性
1)降低查询速度,提高吞吐量
max_threads:位于 users.xml 中,表示单个查询所能使用的最大 CPU 个数,默认是 CPU 核数,假如机器是 32C,则会起 32 个线程来处理当前请求。可以把 max_threads 调低,牺牲单次查询速度来保证 ClickHouse 的可用性,提升并发能力。可通过 jdbc 的 url 来配置

max_threads 做的一个压测,接口级别压测,一次请求执行 5 次 SQL,处理数据量 508W 行。可以看出 max_threads 越小,QPS 越优秀 TP99 越差。可根据自身业务情况来进行调整一个合适的配置值。

2)接口增加一定时间的缓存
3)异步任务执行查询语句,将聚合指标结果落到 ES 中,应用查询 ES 中的聚合结果
4)物化视图,通过预聚合方式解决这种问题,但是我们这种业务场景不适用