火灾是人类面临的重大威胁,检测火灾至关重要。目前的火焰传感器在距离检测方面存在局限性。为了克服这个问题,我的目标是使用机器学习方法创建一个轻量级且高度准确的火灾检测系统。当需要实时数据处理或机器学习模型可用的数据集很少时,这个问题变得非常具有挑战性。因此,这里合成数据集就派上用场了。该项目为在火灾检测系统中使用合成数据集的优势提供了概念验证。
合成数据集是一种数据类型,使我们能够模拟在现实生活中可能很少遇到但需要解决的情况。它提供了一种使用真实数据的高度经济高效的替代方案。用于训练深度神经网络的合成数据集在计算机视觉中的应用越来越多。存在不同的策略,例如域随机化,以弥合合成训练数据和实际应用之间的差距。
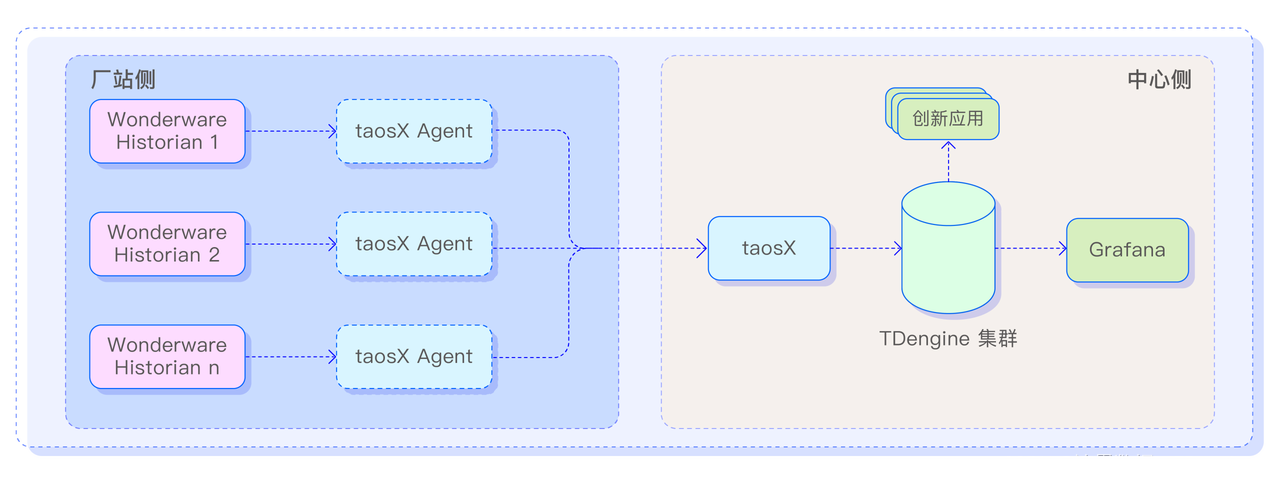
本指南将引导你完成为火灾检测系统训练对象检测模型的过程。下图可以更好地解释项目的整体架构。

如上图所示,Nvidia Omniverse 工具可用于创建合成数据集。该平台提供逼真的渲染和动态场景创建,能够生成具有不同环境因素(如光线、颜色、背景等)的高度逼真的场景。
然后使用 Edge Impulse Web 平台,我们可以快速在云中的数据上训练 ML 模型。
完成训练过程后,优化的火灾检测模型将部署到 Arduino Nicla Vision 上。Nicla Vision 体积小巧、功耗低,是边缘计算应用的理想选择。该模型在此平台上的部署可实现实时火灾检测,因为它可以在本地处理数据,而无需依赖云连接。
机器学习模型的输出可能用于触发操作,例如打开灯或向智能手机发送通知。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、使用Omniverse Replicator 生成合成数据
与任何机器学习任务一样,最重要的任务是准备数据集。Omniverse Replicator 是 Nvidia Omniverse 生态系统的一部分,这是一个可在 Omniverse Code 应用程序中使用的虚拟世界模拟。
通过访问此链接从 NVIDIA 官方网站下载 Omniverse。你可以选择从此链接下载适用于 Windows 或 Linux 操作系统的应用程序。下载 Omniverse 后,导航到 Exchange 选项卡并继续安装 Omniverse Code。

然后,创建本地 Nucleus 服务,转到 Nucleus 选项卡并按照那里提供的说明进行操作。
设置 Nucleus 服务后,导航到 Library 选项卡。从那里,打开 Omniverse Code 开始使用它。

你可能会遇到以下消息:
2023-05-13 10:20:29 [Warning] [rtx.flow.plugin] rtx.flow.plugin failed to load Flow dynamic libraries (error: libnvflow.so: cannot open shared object file: No such file or directory)! Flow rendering will not be available. Try enabling the omni.flowusd extension.要解决此问题,你应该启用 omni.flowusd 扩展以自动加载。这可以在 Omniverse 应用程序设置中完成。找到 omni.flowusd 扩展并确保已启用或选中“自动加载”选项。
保存设置并重新启动 Omniverse 应用程序。
为了进行测试,您可以从下面的“示例”选项卡中找到一个火焰示例,然后执行拖放操作将其添加到场景中。然后,单击“播放”按钮以启动火焰动画。

现在,我们将使用 Python 代码生成合成数据集。我们将有机会使用两个从不同角度观察每一帧的摄像头来生成不同的数据。
请导航到脚本编辑器并粘贴以下代码片段。
import omni.replicator.core as rep
import datetime
now = datetime.datetime.now()
# Camera1
focal_length1 = 25
focus_distance1 = 1200
f_stop1 = 0.4
pixel_resolution1 = (512, 512)
horizontal_aperture1 = 8.5
camera1_pos = [(0, 270, 500), (500, 270, 500), (-500, 270, 500)]
# Camera2 (Top view)
focal_length2 = 50
focus_distance2 = 5000
f_stop2 = 2.8
pixel_resolution2 = (512, 512)
horizontal_aperture2 = 8.5
camera2_pos = [(0, 1800, 0)]
with rep.new_layer():
# Camera1
camera1 = rep.create.camera(
position=(0, 0, 1200),
rotation=(0, -90, 0),
focal_length=focal_length1,
focus_distance=focus_distance1,
f_stop=f_stop1,
horizontal_aperture=horizontal_aperture1,
name='Camera1'
)
# Camera2
camera2 = rep.create.camera(
position=(0, 1500, 0),
rotation=(-90, 0, 0),
focal_length=focal_length2,
focus_distance=focus_distance2,
f_stop=f_stop2,
horizontal_aperture=horizontal_aperture2,
name='Camera2'
)
# Create a new render_product (1 for each camera)
render_product1 = rep.create.render_product(camera1, pixel_resolution1)
render_product2 = rep.create.render_product(camera2, pixel_resolution2)
# Create the floor plane
floor = rep.create.plane(
position=(0, 0, 0),
rotation=(0, 0, 0),
scale=(50, 50, 50),
semantics=[('class', 'floor')],
name='floor',
)
# Randomize the floor material
def random_Floor_Material():
floor_material = rep.randomizer.materials(
materials=rep.get.material(path_pattern="/Fire/Looks/*"),
input_prims=floor
)
return floor_material.node
rep.randomizer.register(random_Floor_Material)
with rep.trigger.on_frame(num_frames=300):
rep.randomizer.random_Floor_Material()
with camera1:
rep.modify.pose(look_at=(0, 0, 0), position=rep.distribution.sequence(camera1_pos))
with camera2:
rep.modify.pose(look_at=(0, 0, 0), position=rep.distribution.sequence(camera2_pos))
writer = rep.WriterRegistry.get("BasicWriter")
now = now.strftime("%Y-%m-%d")
output_dir = "fire_data_" + now
writer.initialize(output_dir=output_dir, rgb=True)
writer.attach([render_product1, render_product2])将火焰元素从流程选项卡拖放到场景中。
单击脚本编辑器选项卡中的运行按钮。然后,将不同的材料从材料选项卡拖放到场景中。
在上面的代码中,编写器已初始化并附加到渲染器以生成没有注释的图像输出。

现在,让我们通过单击开始按钮来开始合成数据生成。

我们不断改变地板的材料,这将增加数据的多样性。这会导致数据集的多样性增加。它将创建两个文件夹,名称如下:RenderProduct_Replicator、RenderProduct_Replicator_01。图像将填充到这些相应文件夹内的 img 文件夹中。
生成完成后,您可以查看这些文件夹中的合成图像,如下所示。

文件夹“RenderProduct_Replicator”包含火灾的正面图像

文件夹“RenderProduct_Replicator_01”包含火灾的顶视图

至此,合成数据集生成过程结束。
由于我们没有带边界框的火灾标注,因此我们需要找到一种方法来自动化此过程。此步骤将在下一节中介绍。
2、使用 Grounding DINO 自动标记图像
众所周知,数据标记已成为一项极其昂贵且耗时的任务。根据 NVIDIA 论坛,使用 NVIDIA Omniverse Code 中的内部工具对流对象进行输出标注是不可行的。因此,我发现了一个解决方案,利用突破性的零样本对象检测器(例如 Grounding DINO),它彻底改变了图像标记过程。
首先,使用下面的 Python 代码将这些文件夹中的图像复制到一个文件夹中。
import os
import shutil
def copy_images(source_folders, destination_folder):
# Create the destination folder if it doesn't exist
if not os.path.exists(destination_folder):
os.makedirs(destination_folder)
for folder in source_folders:
# List all files in the source folder
files = os.listdir(folder)
for file in files:
# Check if the file is an image (you can add more image extensions if needed)
if file.endswith('.png'):
source_file_path = os.path.join(folder, file)
destination_file_path = os.path.join(destination_folder, file)
# If the destination file already exists, rename the file
counter = 0
while os.path.exists(destination_file_path):
counter += 1
new_filename = f"{os.path.splitext(file)[0]}_{counter}.png"
destination_file_path = os.path.join(destination_folder, new_filename)
# Copy the file to the destination folder
shutil.copy(source_file_path, destination_file_path)
if __name__ == "__main__":
source_folders = ["./RenderProduct_Replicator/rgb/", "./RenderProduct_Replicator_01/rgb/"]
destination_folder = "./output_folder"
copy_images(source_folders, destination_folder)完成上一个任务后,请按照 Parthiban Marimuthu 在“如何使用 Grounding DINO 自动标记图像”中描述的步骤进行操作。
打开“generate_annotation”Jupyter 笔记本并执行以下代码片段。确保您已在 Jupyter 环境中安装了所有必要的依赖项和库,以成功执行代码。

它将在导出文件夹中生成 Pascal VOC 格式的注释,如下所示。Pascal VOC(视觉对象类)格式是对象检测数据集中广泛采用的标准。它存储图像及其相应的注释,包括边界框标签。
你可以利用 OpenCV 库使用下面的 Python 代码来检查边界框的正确性。
import cv2
import xml.etree.ElementTree as ET
def draw_bounding_box(image_path, annotation_path, output_path):
# Load the image
img = cv2.imread(image_path)
# Parse the annotation file
tree = ET.parse(annotation_path)
root = tree.getroot()
for obj in root.findall('object'):
# Retrieve bounding box coordinates
xmin = int(obj.find('bndbox/xmin').text)
ymin = int(obj.find('bndbox/ymin').text)
xmax = int(obj.find('bndbox/xmax').text)
ymax = int(obj.find('bndbox/ymax').text)
# Draw the bounding box on the image
cv2.rectangle(img, (xmin, ymin), (xmax, ymax), (0, 255, 0), 2)
# Save the image with bounding box
cv2.imwrite(output_path, img)
if __name__ == "__main__":
image_path = "path/to/your/image.jpg"
annotation_path = "path/to/your/annotation.xml"
output_path = "path/to/save/output_image.jpg"
draw_bounding_box(image_path, annotation_path, output_path)下面你可以看到图像:

图像标记现已完成。如你所见,通过使用 Grounding DINO 零样本方法,初始图像标记过程可以在几分钟内完成。
下一步是使用 Edge Impulse 训练火灾探测系统的模型,并最终将其部署到 Arduino Nicla Vision。
3、使用 Edge Impulse 平台进行训练
Edge Impulse 为在 TinyML 设备上部署模型提供了端到端解决方案。该过程从使用 IoT 设备收集数据开始,然后是特征提取、模型训练,最后是 TinyML 设备的部署和优化。
创建如下所示的目录结构。
.
├── annotations
│ ├── rgb_0000.xml
│ ├── rgb_0001.xml
│ ├── rgb_0002.xml
│ ├── rgb_0003.xml
│ ...
└── images
├── rgb_0000.png
├── rgb_0001.xml
├── rgb_0002.png
├── rgb_0003.png
├── rgb_0004.png
├── rgb_0005.png
...Edge Impulse 最近发布了以 Pascal VOC 格式上传数据集的功能。就我而言,我上传了大约 600 张图像和标注文件。

你应该确保每个图像都正确标记并分组到各自的火灾类别中,以避免在训练期间出现任何混淆。

设置好所有类别并对数据集感到满意后,就可以开始训练模型了。在左侧导航菜单中导航至“create impulse”。

最后,单击“save impulse”。
然后导航到“图像”。在此步骤中,你将从输入数据中生成特征。特征是分类算法将用来对图像进行分类的独特属性。

使用完功能探索器后,点击左侧导航菜单中的对象检测项。
对于此项目,训练周期数设置为 100,学习率设置为 0.005。

Edge Impulse 开发了 FOMO,这是一种用于边缘设备的实时物体检测的 TinyML 深度学习架构,它使得在计算和内存容量非常小的设备上运行实时物体检测成为可能。FOMO 不是检测边界框,而是预测物体的中心。这些模型的大小设计为 <100KB,可以部署到 Arduino Nicla Vision。
神经网络架构具有以下结构。它将使用基于 FOMO 的迁移学习来训练我们的模型。

按下“开始训练”按钮来训练模型。此过程可能需要大约 5-10 分钟,具体取决于你的数据集大小。如果一切顺利,你应该在 Edge Impulse 中看到以下内容。
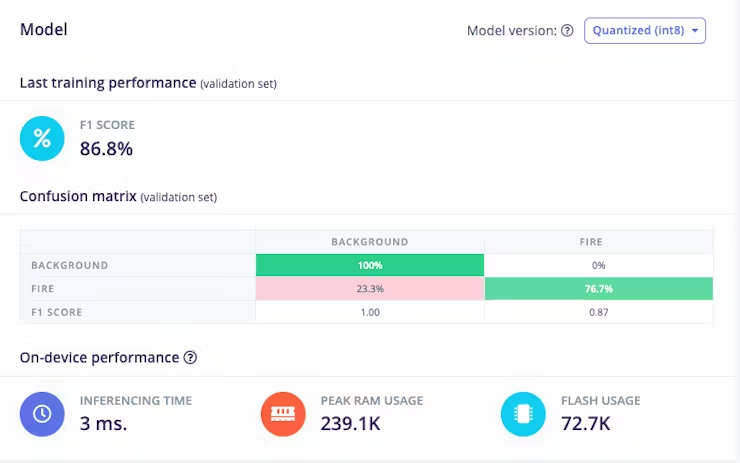
F1 得分为 86.8%,这意味着该模型在准确率和召回率之间取得了良好的平衡,并且在该对象检测任务上表现良好。一旦你对模型的性能感到满意,就可以将其部署到你的 Arduino Nicla Vision 上。

我们的量化模型的大小为 56KB。Arduino Nicla Vision 的可用内存限制为 400 千字节 (KB),因为处理器已经为操作系统和图像缓冲区使用了 1 兆字节 (MB) 的随机存取存储器 (RAM)。它还具有 2MB 的闪存和 16MB 的 QSPI 闪存,可为您提供额外的存储空间。
4、将训练模型部署到 Arduino Nicla Vision
Arduino Nicla Vision 可以在 MicroPython 环境中使用 OpenMV IDE 进行编程。下载它。

然后,转到 Edge Impulse 的部署选项卡。单击部署选项。在我的情况下,它是 OpenMV 库。
在该部分的底部,按下构建按钮。一个 zip 文件将自动下载到您的计算机。解压它。
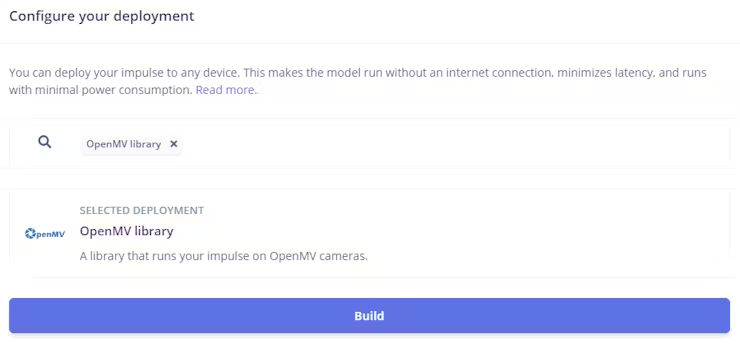
使用 USB 线将 Arduino Nicla Vision 设备连接到你的计算机。
将“labels.txt”和“trained.tflite”文件复制到 Arduino Nicla Vision 设备的根目录。确保将文件直接粘贴到主文件夹中。
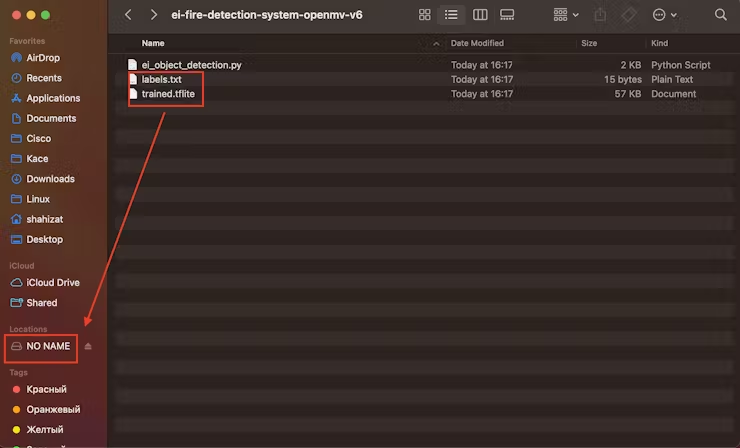
在 OpenMV IDE 中,找到 ei_object_detection.py python 脚本,该脚本处理对象检测过程。最后,运行它。这里是演示视频。
原文链接:火灾检测边缘设备开发 - BimAnt