转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn]
如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~
GitHub - NVIDIA/nccl-tests: NCCL TestsNCCL Tests. Contribute to NVIDIA/nccl-tests development by creating an account on GitHub.![]() https://github.com/NVIDIA/nccl-tests
https://github.com/NVIDIA/nccl-tests

工具安装
1、对于cuda、cudnn、nccl的环境安装可以看:
【教程】保姆级安装NVIDIA CUDA、CUDNN、NCCL环境教程文章浏览阅读1.2w次,点赞2次,收藏8次。非常全面且详细!_nvidia-driver-550 : 依赖: nvidia-dkms-550 (<= 550.54.14-1) 但是它将不会被安https://blog.csdn.net/sxf1061700625/article/details/127705588
2、然后编译工具,编译的结果在build文件夹里:
cd nccl-test
make![]()
工具介绍
NCCL 测试性能指标解释
NCCL(NVIDIA 集体通信库)测试提供了集体操作的重要性能指标,对于优化和理解多 GPU 通信非常重要。以下是这些指标的详细解释及其含义。
1. 时间 (Time)
- 定义:完成集体操作所需的时间。
- 重要性:
- 小规模:用于测量与操作相关的常量开销(或延迟)。
- 大规模:时间与大小成线性关系,因为时间大约等于开销 + (大小 / 带宽)。对于大规模操作,带宽指标更有意义。
2. 带宽 (Bandwidth)
带宽表示操作期间的数据传输速率,分为两种类型:
a. 算法带宽 (Algorithm Bandwidth)
- 公式:algbw=S/t
- 其中 S 是数据大小,ttt 是时间。
- 用途:
- 用于计算任何大规模操作所需的时间,通过将操作大小除以算法带宽。
- 反映操作本身的效率。
- 算法带宽使用最常用的带宽公式:size (S) / time (t)。只需用操作的大小除以算法带宽,就能计算出任何大型操作需要多少时间。
b. 总线带宽 (Bus Bandwidth)
- 定义:反映 GPU 间通信速度,与硬件的峰值带宽相比,不受节点数量影响。
- 重要性:
- 提供一个反映硬件使用效率的度量。
- 对于集体操作,算法带宽会随节点数量变化,而总线带宽则提供一个更一致的硬件能力对比。
-
虽然算法带宽对发送/接收等点对点操作很有意义,但它并不总是有助于测量集体操作的速度,因为理论峰值算法带宽并不等同于硬件峰值带宽,通常取决于ranks。大多数基准仅提供时间测量,这对于大型系统来说很难解释。其他一些基准也提供了算法带宽,但根据ranks的不同,带宽也不同(随着ranks的增加而降低)。为了提供一个能反映硬件最佳使用情况的数字,NCCL 测试引入了 "总线带宽 "的概念(测试输出中的 "busbw "列)。这个数字是通过对算法带宽应用一个公式得出的,以反映 GPU 之间的通信速度。使用该总线带宽,我们可以将其与硬件峰值带宽进行比较,与使用的ranks无关。该公式取决于集体操作。
集合操作详解
全规约 (AllReduce)
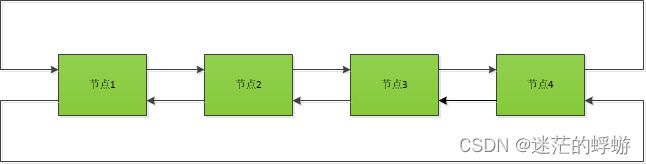
操作:对所有节点上的输入求和并将结果分发到所有节点。注意:这与所使用的算法(环形、树形或其他)无关,只要它们使用点对点操作(发送/接收)即可。
示例:o_0 = o_1 = o_2 = ... = o_{n-1} = i_0 + i_1 + i_2 + ... + i_{n-1}
环将按照环的顺序进行操作:i_0 + i_1 + ...+ i_{n-1} -> o_{n-1} -> o_0 -> o_1 -> ... -> o_{n-2}
树状结构可以分层处理 :(((((i_{n-1} + i_{n-2}) + (i_{n-3} + i_{n-4}))+ ...+ (i_1 + i_0)))))-> o_0 -> (o_{n/2} -> (o_{3n/4} ...))
在所有情况下,我们需要对每个元素进行 n-1 次添加和 n 次赋值。由于每一步都在不同的秩上,只有潜在的一步除外(最后一个输入和第一个输出),因此我们需要 2(n-1) 次数据传输(x 个元素)才能执行一次 allReduce 操作。
考虑到每个秩都有通向 B 外部世界的带宽,执行 S 个元素的 allReduce 操作的时间充其量为 :t = (S*2*(n-1)) / (n*B)
事实上,我们有 S 个元素,每个元素有 2*(n-1) 个操作,有 n 个带宽为 B 的链路来执行这些操作。对等式重新排序后,我们发现 t = (S/B) * (2*(n-1)/n)
因此,要获得可以与硬件峰值带宽进行比较的 AllReduce 带宽测量值,我们需要计算 :B = S/t * (2*(n-1)/n) = algbw * (2*(n-1)/n)
./all_reduce_perfUSAGE: all_reduce_perf
[-t,--nthreads <num threads>]
[-g,--ngpus <gpus per thread>]
[-b,--minbytes <min size in bytes>]
[-e,--maxbytes <max size in bytes>]
[-i,--stepbytes <increment size>]
[-f,--stepfactor <increment factor>]
[-n,--iters <iteration count>]
[-m,--agg_iters <aggregated iteration count>]
[-w,--warmup_iters <warmup iteration count>]
[-p,--parallel_init <0/1>]
[-c,--check <check iteration count>]
[-o,--op <sum/prod/min/max/avg/mulsum/all>]
[-d,--datatype <nccltype/all>]
[-r,--root <root>]
[-z,--blocking <0/1>]
[-y,--stream_null <0/1>]
[-T,--timeout <time in seconds>]
[-G,--cudagraph <num graph launches>]
[-C,--report_cputime <0/1>]
[-a,--average <0/1/2/3> report average iteration time <0=RANK0/1=AVG/2=MIN/3=MAX>]
[-R,--local_register <1/0> enable local buffer registration on send/recv buffers (default: disable)]
[-h,--help]

规约散播 (ReduceScatter)
- 操作:对所有节点上的输入求和并将部分结果分发到每个节点。
- 示例:oK=i0+i1+i2+...+in−1o_K = i_0 + i_1 + i_2 + ... + i_{n-1}oK=i0+i1+i2+...+in−1
- 总线带宽计算:
- 时间公式:t = S*(n-1) / (B*n)
- 带宽公式:B = S/t * (n-1)/n = algbw * (n-1)/n
./reduce_scatter_perf
USAGE: reduce_scatter_perf
[-t,--nthreads <num threads>]
[-g,--ngpus <gpus per thread>]
[-b,--minbytes <min size in bytes>]
[-e,--maxbytes <max size in bytes>]
[-i,--stepbytes <increment size>]
[-f,--stepfactor <increment factor>]
[-n,--iters <iteration count>]
[-m,--agg_iters <aggregated iteration count>]
[-w,--warmup_iters <warmup iteration count>]
[-p,--parallel_init <0/1>]
[-c,--check <check iteration count>]
[-o,--op <sum/prod/min/max/avg/mulsum/all>]
[-d,--datatype <nccltype/all>]
[-r,--root <root>]
[-z,--blocking <0/1>]
[-y,--stream_null <0/1>]
[-T,--timeout <time in seconds>]
[-G,--cudagraph <num graph launches>]
[-C,--report_cputime <0/1>]
[-a,--average <0/1/2/3> report average iteration time <0=RANK0/1=AVG/2=MIN/3=MAX>]
[-R,--local_register <1/0> enable local buffer registration on send/recv buffers (default: disable)]
[-h,--help]

全收集 (AllGather)
- 操作:从所有节点收集输入并将收集结果分发到所有节点。
- 示例:o0=o1=o2=...=on−1=iKo_0 = o_1 = o_2 = ... = o_{n-1} = i_Ko0=o1=o2=...=on−1=iK
- 总线带宽计算:
- 时间公式:t = S*(n-1) / (B*n)
- 带宽公式:B = S/t * (n-1)/n = algbw * (n-1)/n
./all_gather_perfUSAGE: all_gather_perf
[-t,--nthreads <num threads>]
[-g,--ngpus <gpus per thread>]
[-b,--minbytes <min size in bytes>]
[-e,--maxbytes <max size in bytes>]
[-i,--stepbytes <increment size>]
[-f,--stepfactor <increment factor>]
[-n,--iters <iteration count>]
[-m,--agg_iters <aggregated iteration count>]
[-w,--warmup_iters <warmup iteration count>]
[-p,--parallel_init <0/1>]
[-c,--check <check iteration count>]
[-o,--op <sum/prod/min/max/avg/mulsum/all>]
[-d,--datatype <nccltype/all>]
[-r,--root <root>]
[-z,--blocking <0/1>]
[-y,--stream_null <0/1>]
[-T,--timeout <time in seconds>]
[-G,--cudagraph <num graph launches>]
[-C,--report_cputime <0/1>]
[-a,--average <0/1/2/3> report average iteration time <0=RANK0/1=AVG/2=MIN/3=MAX>]
[-R,--local_register <1/0> enable local buffer registration on send/recv buffers (default: disable)]
[-h,--help]

广播 (Broadcast)
- 操作:从一个根节点向所有其他节点发送数据。
- 示例:o0=o1=o2=...=on−1=iRo_0 = o_1 = o_2 = ... = o_{n-1} = i_Ro0=o1=o2=...=on−1=iR
- 总线带宽计算:
- 时间公式:t = S/B
- 带宽公式:B = S/t
./broadcast_perfUSAGE: broadcast_perf
[-t,--nthreads <num threads>]
[-g,--ngpus <gpus per thread>]
[-b,--minbytes <min size in bytes>]
[-e,--maxbytes <max size in bytes>]
[-i,--stepbytes <increment size>]
[-f,--stepfactor <increment factor>]
[-n,--iters <iteration count>]
[-m,--agg_iters <aggregated iteration count>]
[-w,--warmup_iters <warmup iteration count>]
[-p,--parallel_init <0/1>]
[-c,--check <check iteration count>]
[-o,--op <sum/prod/min/max/avg/mulsum/all>]
[-d,--datatype <nccltype/all>]
[-r,--root <root>]
[-z,--blocking <0/1>]
[-y,--stream_null <0/1>]
[-T,--timeout <time in seconds>]
[-G,--cudagraph <num graph launches>]
[-C,--report_cputime <0/1>]
[-a,--average <0/1/2/3> report average iteration time <0=RANK0/1=AVG/2=MIN/3=MAX>]
[-R,--local_register <1/0> enable local buffer registration on send/recv buffers (default: disable)]
[-h,--help]

规约 (Reduce)
- 操作:对所有节点上的输入求和并将结果发送到一个根节点。
- 示例:oR=i0+i1+i2+...+in−1o_R = i_0 + i_1 + i_2 + ... + i_{n-1}oR=i0+i1+i2+...+in−1
- 总线带宽计算:
- 时间公式:t = S/B
- 带宽公式:B = S/t
./reduce_perf USAGE: reduce_perf
[-t,--nthreads <num threads>]
[-g,--ngpus <gpus per thread>]
[-b,--minbytes <min size in bytes>]
[-e,--maxbytes <max size in bytes>]
[-i,--stepbytes <increment size>]
[-f,--stepfactor <increment factor>]
[-n,--iters <iteration count>]
[-m,--agg_iters <aggregated iteration count>]
[-w,--warmup_iters <warmup iteration count>]
[-p,--parallel_init <0/1>]
[-c,--check <check iteration count>]
[-o,--op <sum/prod/min/max/avg/mulsum/all>]
[-d,--datatype <nccltype/all>]
[-r,--root <root>]
[-z,--blocking <0/1>]
[-y,--stream_null <0/1>]
[-T,--timeout <time in seconds>]
[-G,--cudagraph <num graph launches>]
[-C,--report_cputime <0/1>]
[-a,--average <0/1/2/3> report average iteration time <0=RANK0/1=AVG/2=MIN/3=MAX>]
[-R,--local_register <1/0> enable local buffer registration on send/recv buffers (default: disable)]
[-h,--help]

总结
为了在不同节点数量 nnn 上归一化总线带宽,我们对算法带宽应用一个修正因子:
- 全规约:2×(n−1)n2 \times \frac{(n-1)}{n}2×n(n−1)
- 规约散播:(n−1)n\frac{(n-1)}{n}n(n−1)
- 全收集:(n−1)n\frac{(n-1)}{n}n(n−1)
- 广播:1
- 规约:1
总线带宽反映了硬件瓶颈的速度:NVLink、PCIe、QPI 或网络。