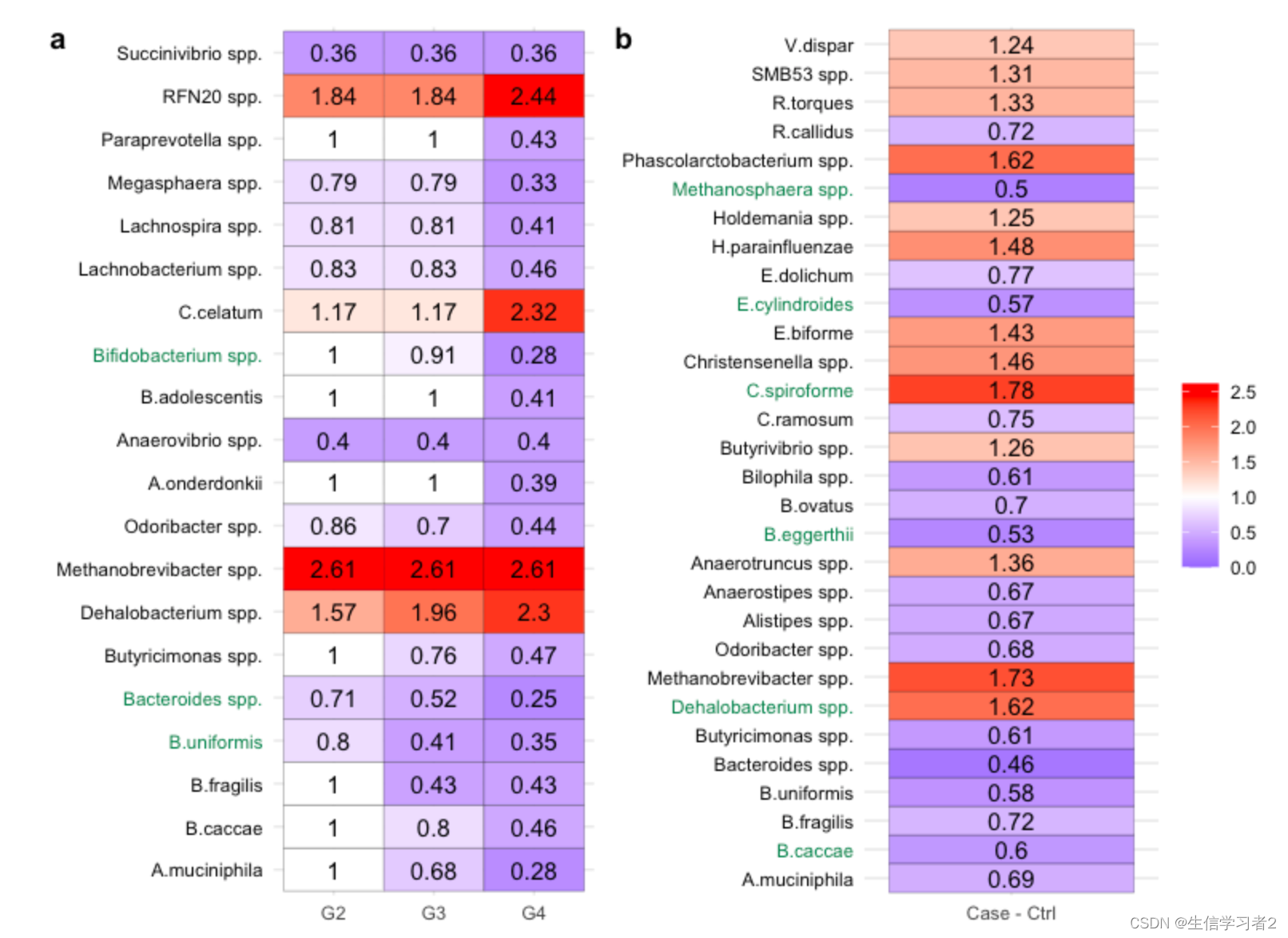
目录
1、数据库自增
2、Redis自增
3、Zookeeper
4、其他
4.1、雪花算法
4.2、Tinyid
4.3、Leaf
4.4、数据库号段
1、数据库自增
利用数据库表的自增特性,或主键唯一性,实现分布式ID
REPLACE INTO id_table (stub) values (’a‘) ;
SELECT LAST_INSERT_ID();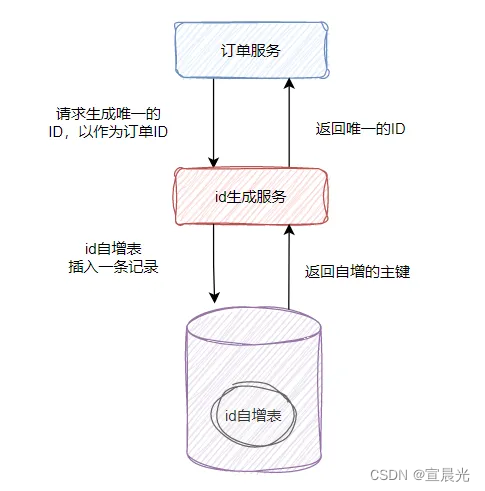
优点:
(1)单调递增,不会影响数据库的数据写入性能。
(2)可读性高。
缺点:
(1)ID生成涉及到数据库操作,性能不高。
(2)需要额外引入中央数据库,链路变长导致出错概率增加。
(3)开发成本相对较高。
(4)数据库压力大。
2、Redis自增
Redis的自增命令incr生成全局唯一ID。具体实现方式是:在Redis中维护一个自增的计数器,每次生成ID时,从Redis中获取计数器的值,然后将其加一并更新回Redis。
通过Redis的INCR自增命令来生成分布式ID。
127.0.0.1:6379> set distributed_id 1 // 将分布式ID初始化为1
OK
127.0.0.1:6379> incr distributed_id // +1,并返回结果
(integer) 2优点:
(1)单调递增,不会影响数据库的数据写入性能。
(2)ID生成性能高。
(3)可读性高。
缺点:
(1)需要额外引入Redis,链路变长导致出错概率增加。
(2)Redis宕机后,RDB + AOF数据恢复较慢,需要Plan B提升恢复速度。
(3)开发成本相对较高。
3、Zookeeper
利用Zookeeper的顺序节点特性来生成全局唯一ID。
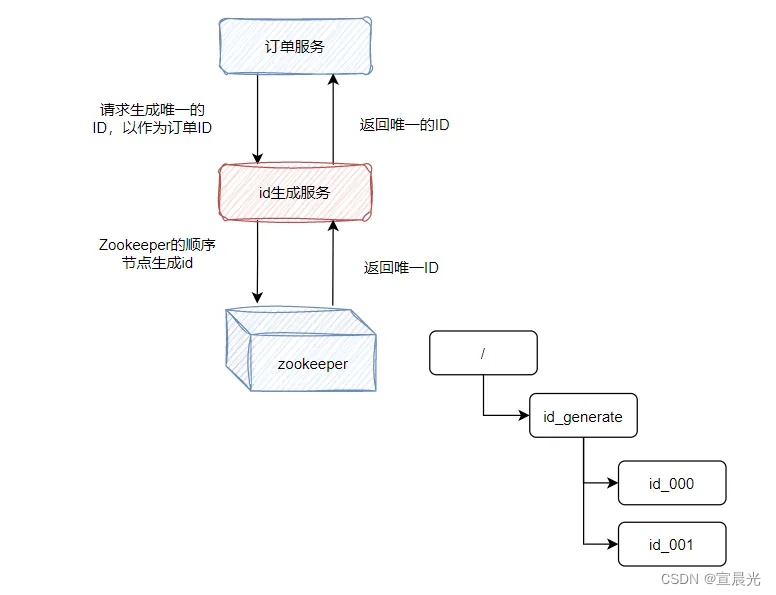
优点:
-
利用Zookeeper的集群特性保证高可用。
-
ID全局唯一。
缺点:
-
需要依赖Zookeeper集群。
-
可能会受到Zookeeper性能的限制。
-
并发竞争较大不适合用Zookeeper
4、其他
4.1、雪花算法
雪花算法是一种生成分布式全局唯一ID的算法,生成的ID称为Snowflake IDs。这种算法由Twitter创建,并用于推文的ID。
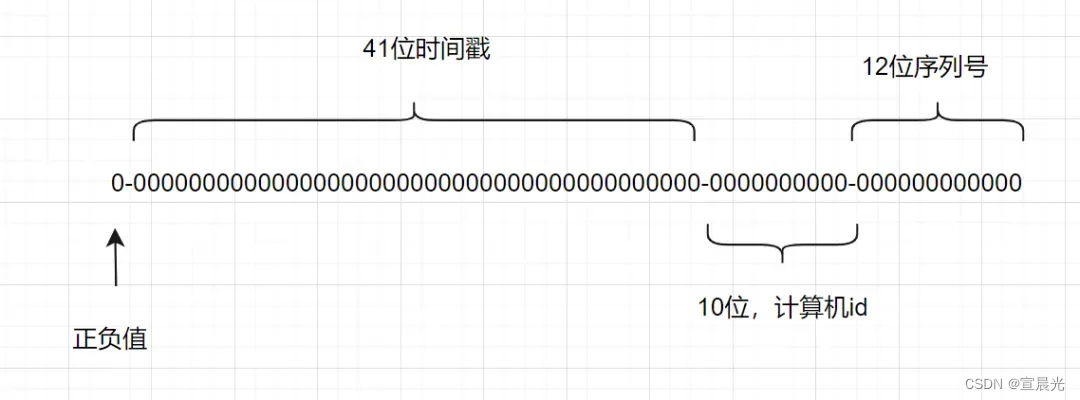
一个Snowflake ID有64位。
-
第1位:Java中long的最高位是符号位代表正负,正数是0,负数是1,一般生成ID都为正数,所以默认为0。
-
接下来前41位是时间戳,表示了自选定的时期以来的毫秒数。
-
接下来的10位代表计算机ID,防止冲突。
-
其余12位代表每台机器上生成ID的序列号,这允许在同一毫秒内创建多个Snowflake ID。
Snowflake雪花算法的优点:
-
生成的ID全局唯一、趋势递增。
-
性能高,可扩展性强。
Snowflake雪花算法的缺点:
-
需要时钟回拨处理机制。
-
依赖机器ID和数据中心ID的分配。
4.2、Tinyid
Tinyid是滴滴开源的轻量级分布式ID生成系统,它是基于号段模式原理实现的与Leaf如出一辙,每个服务获取一个号段(1000,2000]、(2000,3000]、(3000,4000]
4.3、Leaf
Leaf是美团点评开源的分布式ID生成系统,包含基于数据库和基于Zookeeper的两种实现方式。以基于数据库的自增ID生成策略为例(数据库表结构):
CREATE TABLE leaf_alloc (
biz_tag VARCHAR(128) NOT NULL COMMENT '业务key',
max_id BIGINT(20) NOT NULL COMMENT '当前已分配的最大id',
step INT(11) NOT NULL COMMENT '每次id的增长步长',
PRIMARY KEY (biz_tag)
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4;4.4、数据库号段
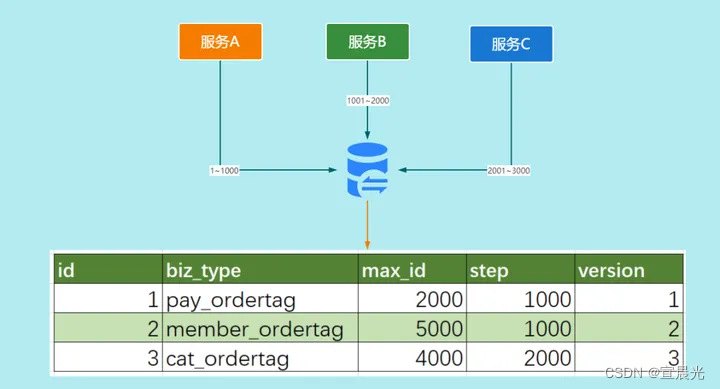
数据库号段,是在“数据库自增ID”方案上做的优化,实现方式如下:
(1)从中央数据库中获取出一批分布式ID,并缓存到分布式ID服务本地,业务系统获取分布式ID的时候,可直接在这个批次内递增取值。
(2)若该批次分布式ID的号段用完,则需要更新数据库中的初始值,再次获取新批次的分布式ID,并重新缓存到分布式ID服务本地,以供使用。
CREATE TABLE id_generator (
id int(10) NOT NULL,
max_id bigint(20) NOT NULL COMMENT '当前最大id',
step int(10) NOT NULL COMMENT '号段的长度',
biz_type int(10) NOT NULL COMMENT '业务类型',
version int(10) NOT NULL COMMENT '版本号,是一个乐观锁,每次都更新version,保证并发时数据的正确性',
PRIMARY KEY (`id`)
)优点:
(1)趋势递增,不会影响数据库的数据写入性能。
(2)ID生成性能高。
(3)数据库压力小。
(4)可读性高。
缺点:
(1)开发成本很高。
(2)需要额外引入分布式ID服务和中央数据库,链路变长导致出错概率增加。