这是我的第310篇原创文章。
一、引言
前面我们使用的案例的数据无论是特征还是标签都是数值型数据,但是在平时工作中我们的数据往往含有非数值型特征(object,比如文本字符类型的),这时候我们就需要对这类数据进行编码操作,本文通过一个具体的案例教你如何实现。
二、实现过程
2.1 读取数据
df:

2.2 数据划分
train_df = df.sample(frac=0.8, random_state=2)
test_df = df.drop(train_df.index)
train_df = train_df.reset_index(drop=True)
test_df = test_df.reset_index(drop=True)2.3 对训练集进行特征处理
le = LabelEncoder() # 对于标签采用LabelEncoder
ohe = OneHotEncoder(sparse=False) # 对于类别特征采用OneHotEncoder
mm = MinMaxScaler() # 对于数值特征采用MinMaxScaler
train_df_X = pd.DataFrame(ohe.fit_transform(train_df[['color','size']].values), columns=ohe.get_feature_names())
train_df['class label'] = le.fit_transform(train_df['class label'])
train_df[['prize']] = mm.fit_transform(train_df[['prize']])
train_df = pd.concat([train_df_X, train_df['prize'], train_df['class label']], axis=1)
X_train = train_df.iloc[:,:-1]
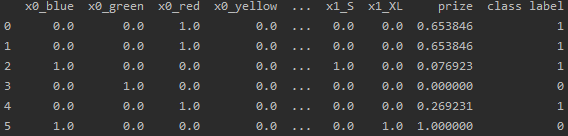
y_train = train_df['class label']对color,size两个特征做独热编码,对class label这个标签做标签编码,对price这个特征做归一化处理,处理完成的train_df如下,处理完的数据就可以输入到模型中了
2.4 模型的构建与训练
model = RandomForestClassifier()
model.fit(X_train, y_train)2.5 对测试集做和训练集同样的处理
test_df_X = pd.DataFrame(ohe.transform(test_df[['color','size']].values), columns=ohe.get_feature_names())
test_df['class label'] = le.transform(test_df['class label'])
test_df[['prize']] = mm.transform(test_df[['prize']])
test_df = pd.concat([test_df_X, test_df['prize'], test_df['class label']], axis=1)
X_test = test_df.iloc[:,:-1]
y_test = test_df['class label']这里一定要同样的处理,注意fit_transform和transform的区别。
2.6 模型的推理
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred) # 准确率acc作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。