论文地址:https://arxiv.org/pdf/2204.02311.pdf
相关博客
【自然语言处理】【大模型】PaLM:基于Pathways的大语言模型
【自然语言处理】【chatGPT系列】大语言模型可以自我改进
【自然语言处理】【ChatGPT系列】WebGPT:基于人类反馈的浏览器辅助问答
【自然语言处理】【ChatGPT系列】FLAN:微调语言模型是Zero-Shot学习器
【自然语言处理】【ChatGPT系列】ChatGPT的智能来自哪里?
【自然语言处理】【ChatGPT系列】Chain of Thought:从大模型中引导出推理能力
【自然语言处理】【ChatGPT系列】InstructGPT:遵循人类反馈指令来训练语言模型
【自然语言处理】【ChatGPT系列】大模型的涌现能力
一、简介
近些年,超大型神经网络在语言理解和生成的广泛任务上实现了令人惊讶的效果。这些模型通常是在大规模文本语料上,使用填充式的预训练目标和encoder-only或者encoder-decoder架构进行训练,然后通过微调来适应下游的具体任务。虽然这些模型在数千个自然语言任务上实现了state of the art,但缺点是其需要大量任务相关的训练样本来微调模型。此外,至少有一部分参数需要更新来拟合任务,这增加了模型训练和部署的复杂性。
GPT-3表明了超大的自回归语言模型可以用来进行few-shot预测,即仅给模型一些关于任务的自然语言描述,和一些少量的示例来表明任务该如何完成。这种类型的模型使用decoder-only和标准的left-to-right语言建模目标函数进行训练。few-shot的结果表明不需要大规模任务相关的数据收集或者模型参数的更新都能够实现非常好的效果。
自GPT-3出现以来,出现了大量的自回归语言模型来实现更高的性能。例如GPT-3之后的模型GLaM、Gopher、Chinchilla、Megatron-Turing NLG和LaMDA都在其推出时,在大量任务上实现了few-shot的state-of-the-art。类似于GPT-3,这些模型都是Transformer架构的变体。这些模型的改进主要来自于如下方面:(1) 在深度和宽度上扩大模型的尺寸;(2) 增加模型训练时的token数量;(3) 在更多样且更干净的数据上训练;(4) 通过稀疏激活模型在不增加计算量的情况下增加模型的容量。
本文会在7800亿token的高质量文本上训练一个5400亿参数的稠密自回归Transformer。该模型使用新的机器学习系统Pathways进行训练的,因此称新模型为Pathways Language Model(PaLM)。其在数百个自然语言、代码和数学推理任务上实现了state-of-the-art的few-shot结果。
本文的主要贡献有:
-
高效的扩展
首次展示了Pathways的大规模使用,其是一个能够跨数千上万加速芯片训练单个模型的新机器学习系统。本文使用Pathways在6144个TPU v4芯片上高效的训练了一个540B参数的语言模型,先前的模型无法达到这个规模。
-
随着规模持续改善
在数百个自然语言、代码和数学推理任务上评估了PaLM,其在绝大多数基准上都实现了state-of-the-art的结果。这充分证明了大语言模型随着规模的改进还没有趋于稳定或者达到饱和点。
-
突破能力
在许多困难任务上展示了语言理解和生成的突破性能力。在推理任务上,先前的最优结果是将任务相关的微调、领域相关的架构以及任务相关的验证相结合才实现好的结果。本文表明了当大模型与 chain-of-thought prompting \text{chain-of-thought prompting} chain-of-thought prompting相结合就能够在广泛的推理任务上匹敌或者超过先前的微调模型。
-
不连续改进
为了更好的理解规模的行为,本文呈现了不同参数规模的结果:8B、62B和540B。通常,从62B至540B带来的效果类似于从8B至62B,其与神经网络中经常观察到的"power law"一致。然而,对于某些任务,观察到了不连续的改善,相比于8B至62B的规模变化,从62B至540B在准确率上将带来戏剧性的跳跃。这表明当模型达到足够规模时,语言模型会涌现新的能力。
-
多语言理解
现有的大语言模型通常会在多语言领域进行有限的评估。本文在机器翻译、摘要和问答上进行了更彻底的评估。即使在非英文数据占训练数据相对小比例( ≈ 22 % \approx 22\% ≈22%)的情况下,540B模型的few-shot的评估结果也能在非英文摘要上接近先前最优的微调方法,并在翻译任务上超越先前的最优。未来的工作需要进一步理解英文中的多语言数据比例的影响。
-
偏见和毒性
本文还评估了模型在偏见和毒性上的表现,其带来几个洞见。首先,对于性别和职业的偏见,PaLM 540B在1-shot和few-shot设置下实现了新的state-of-the-art。其次,通过对种族/宗教/性别的prompt延续的共享分析表明,模型可能会错误的肯定刻板印象,例如将穆斯林和恐怖主义、极端主义和暴力联系在一起。最后,对prompt延续的毒性分析表明,相较于8B模型,62B和540B模型的毒性略高。然而,模型生成的毒性与prompt的毒性高度相关。这表明,与人类生成的文本相比,模型严重依赖于prompt的风格。
二、模型结构
PaLM使用了标准Transformer架构的解码器,并作如下修改:
-
SwiGLU激活
对于MLP的中间激活函数使用SwiGLU激活函数 ( Swish ( x W ) ⋅ x V ) (\text{Swish}(xW)\cdot xV) (Swish(xW)⋅xV),因为与标准的ReLU、GeLU和Swish相比,其已经被证明能够显著的提高质量。注意,这需要在 MLP \text{MLP} MLP层中进行三次矩阵乘法运算,而不是两次。
-
并行层
在每个Transformer块中使用"并行"的形式,而不是标准的"序列化"形式。具体来说,标准形式可以写为
y = x + MLP(LayerNorm(x+Attention(LayerNorm(x)))) y = x + \text{MLP(LayerNorm(x+Attention(LayerNorm(x))))} y=x+MLP(LayerNorm(x+Attention(LayerNorm(x))))
而并行形式则写为:
y = x + MLP(LayerNorm(x)) + Attention(LayerNorm(x)) y = x + \text{MLP(LayerNorm(x))} + \text{Attention(LayerNorm(x))} y=x+MLP(LayerNorm(x))+Attention(LayerNorm(x))
并行的方式将会为训练带来大约15%的提速,因为MLP和Attention的输入句子乘法可以被混合。消融实验显示,其在8B模型上效果略有下降,但是在62B模型上没有影响,所以推断并行层在540B规模的模型上没有影响。 -
多Query注意力
标准的Transformer会使用k个注意力头,其每个时间步的输入向量被线性投影为形状 [ k , h ] [k,h] [k,h]的"query"、"key"和"value"张量,其中h是注意力头的尺寸。这里,对于每个头共享key/value投影,即key和value被投影为[1,h],但是"query"仍然被投影为形状[k,h]。我们发现这对模型的训练速度和质量没有影响,但是能够显著的减少自回归解码的时间。这是因为多头注意力在自回归解码时对硬件加速的利用率较低,因为key/value张量在样本间不共享,在一个时刻仅解码单个token。
-
RoPE嵌入层
这里使用RoPE嵌入,而不是绝对或者相对位置嵌入,因为RoPE嵌入向量在长序列上的表现更好。
-
共享输入-输出嵌入层
共享输入和输出嵌入矩阵,其在过去的工作中很常见。
-
没有Biases
在任何稠密核或者layer norms都不使用biases,这可以增加大模型的训练稳定性。
-
词表
使用具有256k token的 SentencePiece \text{SentencePiece} SentencePiece词表,其能够支持训练语料中的大量语言。词表是从训练数据中生成的,其可以提高训练效率。词表是完全无损且可逆的,意味着"空白"也是保留在词表里的,并且袋外词的Unicode字符被划分为UTF-8 bytes,每个byte都是一个词表的token。数字总是被划分为独立的数值tokens(例如: “123.5->1 2 3 . 5”)
模型规模超参数
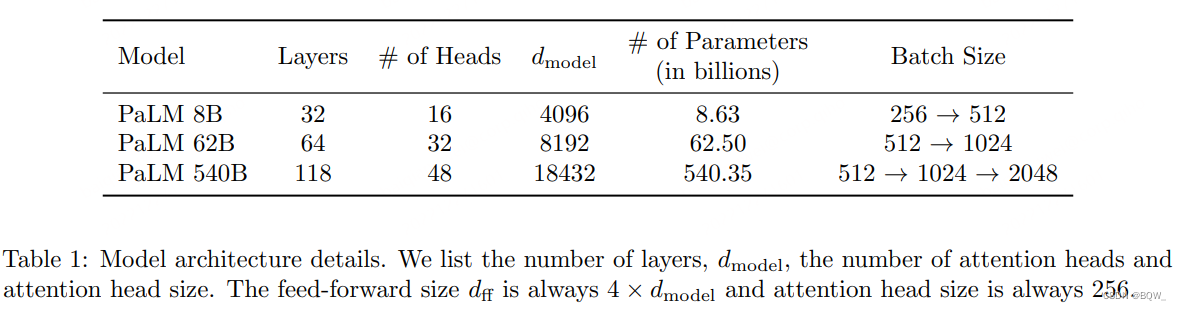
本文中会比较不同的模型规模:540B、62B和8B参数量。每个token的FLOPs数量近似等于参数量,因为这些模型是标准的稠密模型。这些模型使用上表的超参数进行构造。上面三个模型使用相同的数据和词表来独立训练。
三、训练数据集
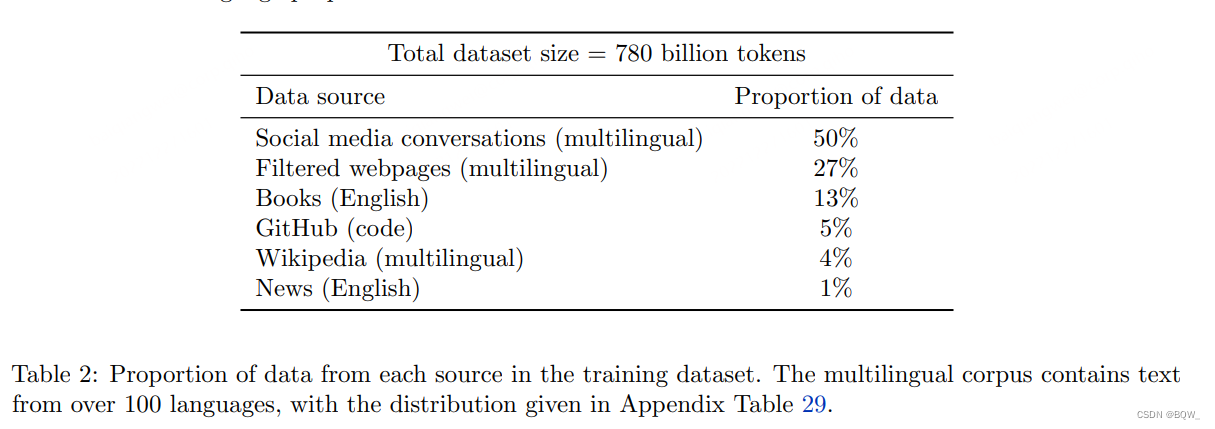
PaLM预训练数据集由7800亿token的高质量语料组成,表示了广泛的自然语言用例。该数据集混合了过滤后的网页、书籍、Wikipedia、新闻、源代码和社交媒体对话数据。该数据集是基于训练LaMDA和GaLM的数据集。所有的模型都仅训练1个epoch,并选择混合百分比来避免重复数据。
除了自然语言数据,预训练数据也包含代码数据。预训练数据集中的源代码来自于GitHub的开源仓库。通过仓库中的license过滤文件。此外,通过文件名的扩展来过滤文件,从而限制为24种常见的编程语言,包括Java、HTML、Javascript、Python、PHP、C#、XML、C++和C,总共有196GB的源代码。此外,基于Levenshtein距离移除了重复的文件,因为重复的文件是常见的源代码库。
上表2列出了用于创建最终 PaLM \text{PaLM} PaLM数据集的各种数据源的百分比。
四、训练基础设施
训练和评估代码库都是基于JAX和T5X,并且所有的模型都是在TPU v4上训练的。PaLM 540B在基于数据中心网络(DCN)连接的两个TPU v4 Pods上训练,并使用模型并行和数据并行。在每个Pod中包含由3072个TPU v4芯片链接的768个主机。该系统是目前为止最大的TPU配置,其允许在不使用任何流水线并行的情况下高效的在6144个芯片上训练。
LaMDA和GLaM在单个TPU系统上训练,并使用流水线并行或者DCN。Megatron-Truing NLG 530B使用模型、数据和流水线并行在2240个A100 GPUs上训练,Gopher则是在4个由DCN连接的TPU v3 Pods上使用流水线并行进行训练的。
流水线通常是和DCN一起使用的,因为其具有较低的带宽要求并且能够提供模型并行和数据并行以外额外的并行。流水线通常划分训练batch为"micro-batches",但是其仍然有缺点。首先,其会带来一个流水线步骤时间开销,在前向或者后向传播的开始和结束时会填充或者清空流水线,这时的设备都是空闲的。第二,其需要更高的内存带宽,其需要为mini-batch中的每个micro-batch重新从内存中加载权重。在某些情况下,其会增加软件的复杂度。这里使用以下策略将PaLM 540B的无流水线训练扩展至6144个芯片。
每个TPU v4 Pod都包含模型参数的完全拷贝,每个权重张量使用12路模型并行和256路全分片数据并行。在前向传播时,数据并行轴上的所有权重被收集,并且来自于每个层的完全激活张量被保存。在反向传播时,余下的激活被重新具体化。因此在大batch size的情况下,相比于重新计算其会带来更高的训练吞吐量。
使用Pathways系统将训练扩展至多个TPU v4 Pod。PaLM 540B利用Pathways的client-server架构实现了pod级别的两路数据并行。这里,单个Python客户端将训练batch的一半分派至每个pod,每个pod使用标准的pod内数据和模型并行来执行前向和后向计算。然而,pod会迁移梯度至远程的pod,最终每个Pod会积累本地和远程梯度,并且应用并行的参数更新来获得下一个时间步的参数。
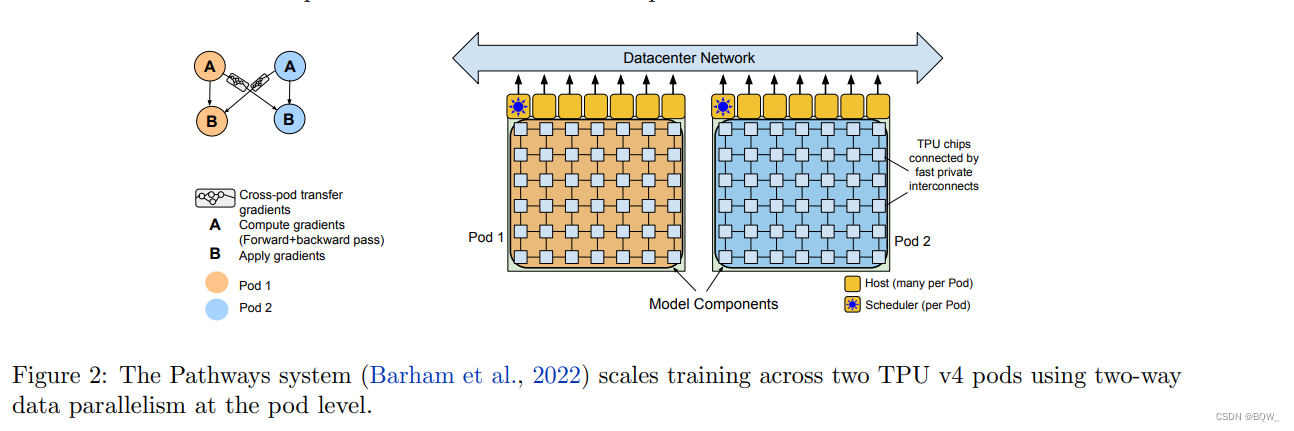
上图2展示了Pathways系统执行两路pod级别的数据并行。单个Python client会构造一个分片数据流程序(上图左),其会在远程服务器上启动一个JAX/XLA work。该程序中包含一个用于计算pod内前向和后向计算、并在跨pod梯度迁移的组件A,和一个用于优化更新的组件B(包括本地和远程梯度的和)。Pathways程序在每个pod上执行组件A,然后将输出的梯度转移至另一个pod,最终在每个pod上执行组件B。Pathways系统设计有几个特点,允许其将程序扩展至上千个加速芯片:首先,其会消除掉从单个python client分发JAX/XLA work至远程服务器上的时间;其次,通过分片数据流执行模型来分摊管理数据迁移的成本。
两路pod-level级数据并行的一个有趣方面是,在两个连接了1536主机且包含6144 TPU v4芯片的pod间跨pod梯度迁移来实现高的训练吞吐量。需要注意,跨pod梯度迁移仅需要在两个pod的对应主机上进行1:1的迁移,因为每个核仅需要模型分片参数的远程梯度。此外,两个pod的主机通过Google datacenter network进行连接。因为梯度迁移会在每个核完成计算梯度后才开始,这将导致非常突发的工作负载,所有主机在同一时间通过data-center-network进行梯度的迁移。特别地,每对主机在每个训练步都需要交互1.3GB的梯度,在所有主机上的总爆发量为81 Tbps。这种工作负载的突发性会带来挑战,我们通过仔细的设计Pathways的网络栈以解决这个挑战,从而实现最优的DCN链路利用率。例如,为了减轻拥堵的影响,梯度迁移数据被划分为更小的块,并通过多个更小的流在不同的DCN链接集上路由。使用这些优化,实现了相对于训练时单个pod吞吐量的1.95倍。
训练效率
先前大多数语言模型加速效率的报告都使用一种称为hardware FLOPs utilization(HFS)的度量。这通常反应了给定设备观察到的FLOPs和理论峰值FLOPs比例的估计值。然而,HFS有几个问题。首先,执行的硬件FLOPs数量是依赖系统和实现的,编译器上的设计选择也会导致不同的操作数量。Rematerialization是一项广泛用来折中内存使用和计算的技术。为了高效的计算反向传播,batch的许多中间激活必须存储在内存中。若它们不能全部匹配,一些前向操作将需要重新计算。这产生了一个折中,使用额外、硬件FLOPs来节省内存,但是训练系统的最终目标是实现高的吞吐量(训练的更快),而不是尽可能的使用多的硬件FLOPs。其次,观察到的硬件FLOPs依赖于使用的计算或者跟踪方法。
基于上面的问题,本文发现HFU对于LLM训练效率来说不是一个一致且有意义的度量。因此提出了一种衡量效率的新度量,其是实现独立的并且允许对系统效率进行清晰的比较,称为model FLOPs utilization(MFU)。这是观察到的吞吐量相对于一个系统在巅峰FLOPs操作的理论最大吞吐量。至关重要的是,"理论最大"吞吐量仅考虑正向和反向传播所需的操作,而不是rematerialization。因此,MFU允许在不同系统上训练运行间的公平比较,因为分子仅是每秒观察到的tokens,而分母仅依赖于模型架构和给定系统的最大FLOPs。
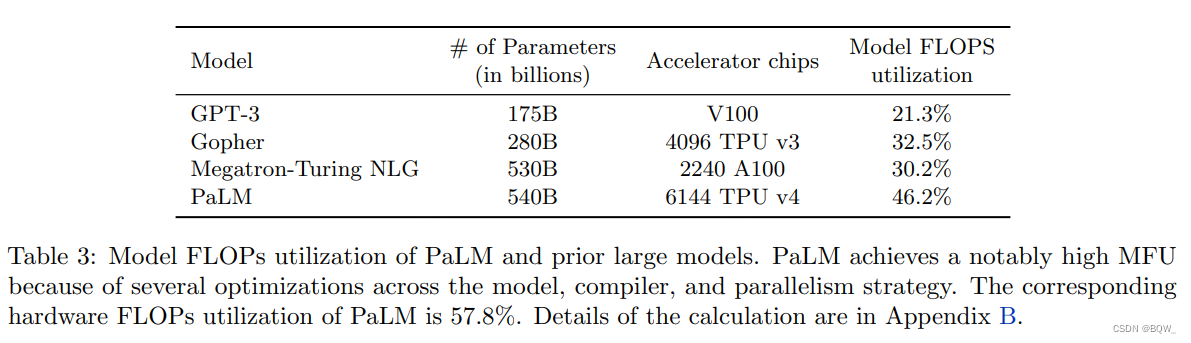
上表3中展示了PaLM 540B以及先前一些模型的MFU。MFU在不同模型参数量、架构和模型质量的上下文中,对于比较模型和系统非常有用。基于每个GPU 24.6个非注意力模型TFLOP/s,GPT-3的MFU数量为21.3%;基于每秒训练步骤为0.0152,Gopher的MFU数量为32.5%。Megatron-Turing NLG 530B的MFU数量为29.7%,或者基于其吞吐量每秒65.43K的MFU值为30.2%。相比,PaLM 540B在batch size为2048的情况下实现了平均训练吞吐量为238.3K tokens每秒。PaLM 540B的训练使用了rematerialization,因为更灵活的batch size可以提高训练的吞吐量。PaLM 540B在没有自注意力下的MFU为45.7%,具有自注意力下为46.2%。本文也计算了HFS,其包含rematerialization FLOPs,为57.8%。PaLM实现了更高的加速利用率,因为其并行策略和几个其他因子,包括XLA TPU编译优化,使用“并行层”。作者相信PaLM代表了LLM训练效率前进的重要一步。
五、训练设置
-
权重初始化
核心权重(除了embedding和layer norm scales)都使用"fan-in variance scaling"初始化,即 W ∼ N ( 0 , 1 / n i n ) W\sim\mathcal{N}(0,1/\sqrt{n_{in}}) W∼N(0,1/nin),其中 n i n n_{in} nin是核的维度。输入embedding使用 E ∼ N ( 0 , 1 ) E\sim\mathcal{N}(0,1) E∼N(0,1)初始化,因为layer normalization不应用在embedding层。因为输入和输出的embedding层共享,将softmax之前的logits使用 1 / n 1/\sqrt{n} 1/n进行缩放,其中n是embedding的尺寸。
-
优化器
使用Adafactor优化器进行训练。这相当于带有"参数缩放"的Adam,其通过参数矩阵的均方根来缩放学习率。因为权重初始化与 1 / n 1/\sqrt{n} 1/n成正比,其类似于手动缩小Adam的学习率。然而,参数缩放的优点是,在不同尺度上操作的参数矩阵的学习率不会以相同的速率缩减。
-
优化超参数
在前10000个step,Adafactor的学习率为 1 0 − 2 10^{-2} 10−2,然后会以 1 / k 1/\sqrt{k} 1/k的比率进行衰减, k k k是step数量。训练的momentum为 β 1 = 0.9 \beta_1=0.9 β1=0.9。二阶距插值的计算为 β 2 = 1.0 − k − 0.8 \beta_2=1.0-k^{-0.8} β2=1.0−k−0.8,其中k是step数量。实验发现相比于标准的 β 2 = 0.99 \beta_2=0.99 β2=0.99,在训练大模型时会更加稳定。对于所有模型使用值为1.0的全局范数梯度裁剪。我们在训练时使用 l r 2.0 lr^{2.0} lr2.0的动态权重衰减,其中 l r lr lr是当前的学习率。
-
损失函数
模型使用标准的语言模型损失函数,其是一个不使用标签平滑的所有token的对数概率平均值。此外,额外使用了辅助损失函数 z l o s s = 1 0 − 4 ⋅ log 2 Z z_{loss}=10^{-4}\cdot\log^2 Z zloss=10−4⋅log2Z来鼓励softmax标准化 log ( Z ) \log(Z) log(Z)接近0,其可以增加训练的稳定性。
-
序列长度
所有模型都使用2048的序列长度。输入样本被拼接在一起,然后被划分为精确的2048个tokens,所以也不需要padding的token,但是样本可能会被从中间分开。输入样本之间使用特殊的token [eod] 来区分开。
-
Batch size
对于所有的模型,在训练时增加batch size。在50k step之前使用的batch size为512,在115k步骤之前则使用的batch size为1024,在训练完成的255k step之前则使用2048的batch size。较小的模型遵循类似的方案。使用这种batch size调度的方法主要原因有2个:(1) 较小的batch size在训练早期样本效率更高;(2) 更大的batch size会带来更大的矩阵乘法维度,其增加TPU效率。
-
Bitwise determinism
模型可以从任意checkpoint按位进行复制。换句话说,在单次训练中模型训练至17000步,我们从15000步重新开始,训练框架可以保证在从checkpoint 15000至17000产生完全一致的结果。这是通过两种方式实现的:(1) 由JAX+XLA+T5X提供的bitwise-deterministic模型框架;(2) 一个确定性的数据集流水线。
-
Dropout
模型在训练时不使用dropout,虽然在大多数微调时使用0.1的dropout。
训练不稳定
对于最大的模型,尽管使用了梯度裁剪,在训练过程中观察到大于20次损失函数锋值。这些峰值的出现非常的不规律,有时出现在训练的后期,且在较小的模型中没有观察到。由于训练最大模型的代价,不能确定缓解这些峰值的主要策略。
相反,本文发现一个简单的策略可以有效的缓解这个问题:从峰值前的100步的checkpoints训练,并且跳过200-500个data batches,其涵盖了爆炸前以及爆炸之间的batches。通过这种缓解策略,损失函数不会在相同的点爆炸。这些峰值不太可能是由"bad data"导致的,因为跑了一些消融实验,将峰值周围的batch数据拿出来,然后从一个较早的不同的checkpoint上训练这些数据。在这些案例中,没有看到峰值。这意味着峰值仅会由特定batch的数据和特定模型参数结合而发生。
六、评估
评估部分内容角度,本博客仅列出一些实验结论。
1. 英文NLP任务
在29个英文基准上评估了PaLM,这些基准大致可以分类为:开放域闭卷问答、填空和补全任务、Winograd风格任务、常数推理任务、阅读理解任务、SuperGLUE、自然语言推理。
PaLM在1-shot设置下,在29个任务中的24取得了SOTA;在few-shot设置下,在29个任务中的28个取得了SOTA。此外,预训练数据、训练策略和token数量对于最终的结果很重要。
1.1 大规模多任务语言理解
这里也在Massive Multitask Language Understanding (MMLU)基准上评估了PaLM,其平均能有2个点的改善。
1.2 微调
在SuperGLUE基准上,针对PaLM进行了微调实验。PaLM仅能接近SOTA表现,而最优的模型都是encoder-decoder结构。结果表明,在分类任务微调上encoder-decoder结构优于纯decoder结构。
2. BIG-bench
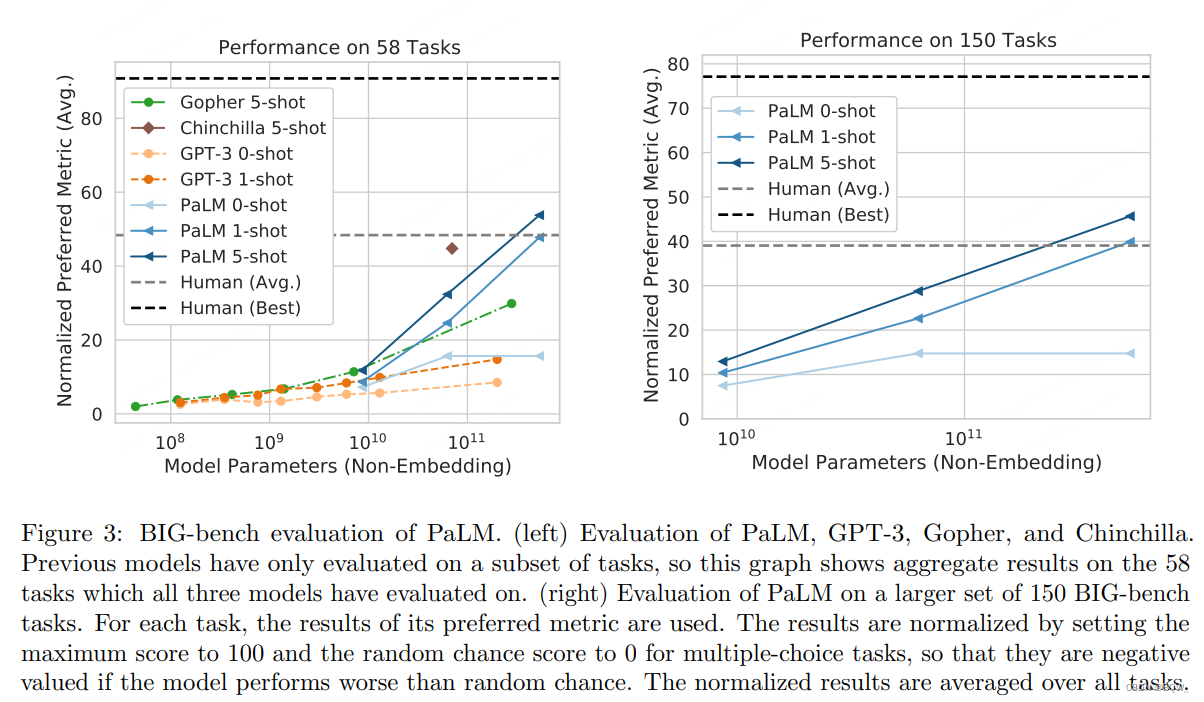
BIG-bench是一个众包基准,旨在为打模型生成有挑选的任务。该基准包含的150个任务覆盖了包含逻辑推理、翻译、问答等各种语言模型任务。本小节分析PaLM模型在BIG-bench的few-shot评估结果。BIG-bench包含了文本任务和编程任务。本文仅考虑纯文本任务。上图3展示了PaLM在BIG-bench上的结果。
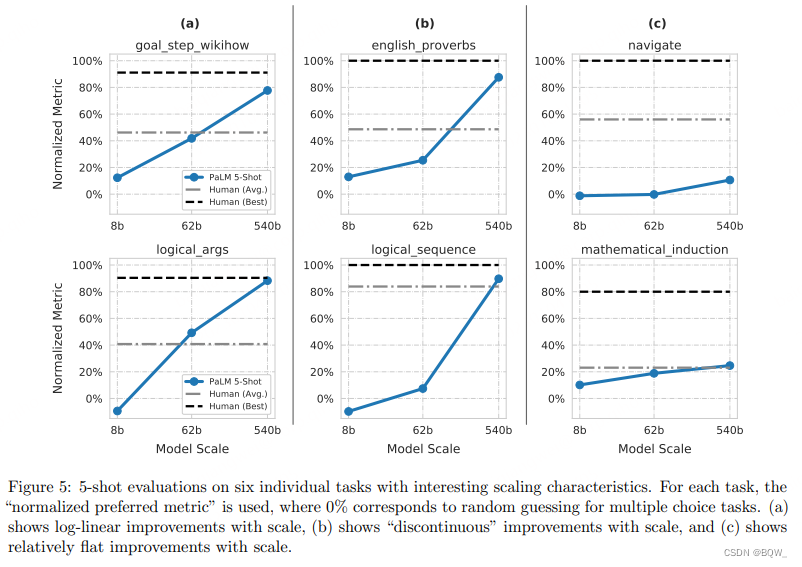
实验还分布分析了BIG-bench中的部分任务。
上图(a)的两个任务随着模型规模的增大而效果持续改善,且基本是线性的。上图(b)的两个任务呈现出“不连续的改善”,意味着模型的能力仅在确定的规模达到。上图©的两个任务并没有从模型规模中受益。
3. 推理
这里评估了推理任务,该任务需要通过算术或者常识的多步推理才能够产生正确的答案。语言模型在广泛的任务上都有很好的表现,但是通常认为其在需要多步推理的任务上仍然很挣扎。这里主要评估两类推理基准:算术推理和常识推理。
模型规模和chain-of-thought(CoT) prompting结合可以在各种算术和常识推理任务上实现SOTA,而不需要特定的架构、任务相关的微调等。
4. 代码任务
近期的一些工作显示,大语言模型在竞争性编程、代码补全和基于自然语言的程序合成上很有用。本小节展示了PaLM在各种代码任务上实现了非常好的结果:
- Text-to-code。 该任务是给定自然语言描述来生成代码;
- Code-to-code。该任务是从一种代码翻译为另一种代码;
这里比较了LaMDA和CodeX两个语言模型。LaMDA虽然没有在Github的代码数据上训练,但是数据集中也有12.5%的代码数据。CodeX则是比较早期12B版本。
-
PaLM 540B
LaMDA在所有任务上都有非0的表现,即使其没有在GitHub代码上训练。这说明LaMDA的代码网络文档对这些任务是有效的。这与GPT-3形成对比,因为其在HumanEval数据集上的表现为0。PaLM在所有的任务上都比LaMDA效果好,在HumanEval上能够与Codex 12B相媲美。这一点还特引入注意的,不同于Codex,PaLM模型并不是针对代码的,同一个模型在代码和自然语言任务上都实现了卓越的效果。**这应该是第一个在单个模型上实现自然语言和代码任务state-of-the-art效果的大语言模型。**PaLM使用了2.7B token的Python代码,而Codex则使用了100B。PaLM能够使用较少的代码实现相当的结果,可能的原因有:(a) 从其他编程语言和自然语言数据中迁移;(b) 大模型可能比小模型样本效率高。
-
PaLM-Coder
相较于PaLM,PaLM-Coder则是在代码上微调。微调能够显著的改善PaLM在代码任务上的效果。
5. 翻译
像GPT-3这样的大语言模型已经证明了具有机器翻译的能力,尽管没有的并行文本语料上进行训练。当翻译至英语时的效果令人印象深刻,而翻译英语至其他语言则效果平平。本小节将评估各种PaLM的翻译能力,其并没有在并行文本语料上进行训练。具体来说,专注在三种类型的语言对上:英语为中心的语言对(即源语言或者目标语言中有一个是英语)、直接语言对(不包含英语的翻译)、极限低资源语言对。
-
英语为中心的语言对评估
在该类任务上考虑0-shot、1-shot和few-shot设置,PaLM显著超越了先前的SOTA。对于德语-英语和罗马尼亚语-英语上甚至超过了有监督的baseline。此外,PaLM从62B扩展至540B,会在BLEU分数上带来大幅度的跳跃。
-
直接语言对和极限低资源语言对评估
在这种有挑战的设定中,PaLM仅在法语-德语上匹配监督表现,但仍然能够在德语-法语和哈萨克语-英语上给出很强的表现。
这里整理了一些观察结果:
- 从其他语言翻译至英语的质量好于将英语翻译为其他语言;
- prompt能够比单独的样本带来更多价值,例如使用语言名称来引导翻译要比直接给输入-输出样例效果更好。
- 通用模型仅依赖自监督能够匹配小规模的专用模型;
6. 多语言生成
自然语言生成任务,需要给定文本或者非语言信息(文档、表格)作为模型输入,并生成可以理解的文本。先前相似规模的模型上并没有探索few-shot条件语言生成。通常生成评估限制为生成问题答案和语言建模任务的多项选择,并不需要生成完整的句子或者段落。
本小节会呈现大语言模型few-shot条件语言生成的第一个基准。先前的SOTA主要来自于微调的T5、mT5或者BART,其都是encoder-decoder的结果。这些模型显著的小于PaLM。在微调的设置上encoder-decoder通常优于大型decoder-only语言模型。因此,本小节比较的重点是模型规模是否能够弥补这个缺点。
评估的数据集主要是三个摘要数据集和三个data-to-text数据集,度量使用ROUGE-2, ROUGE-L和BLEURT-20。
-
微调的有效性
在摘要任务中,微调的PaLM 540B在所有英文生成任务上接近或超过先前的最优结果。这表明PaLM通过增加规模来弥补架构上的缺点。
-
英文与非英文的生成质量
当生成英文时,PaLM在6个摘要任务中的4个上都实现了微调的state-of-the-art,即使输入不是英文。然而,对于非英文摘要,微调没有实现SOTA。这表明PaLM在处理非英文输入要优于生成非英文输出。
-
1-shot和微调的差距
在data-to-text任务上,few-shot的结果与摘要类似,但是与最优微调结果的差距急剧减小。
-
few-shot摘要
当在PaLM上比较few-shot摘要时,8B至62B有一个显著改善,62B至540B也有大幅度改善。然而,few-shot和微调之间仍然存在很大差距。
七、记忆
众所周知,神经网络能够记忆训练数据:事实上,这也是过拟合的定义。通常来说,这种类型的记忆发生在模型对一个小训练集进行多次传播。然而,在本文的场景中,PaLM在780B token的语料上进行单次传播训练。另一方面,本文模型有着极大的容量,因此单次传播也能够记住训练数据中的大部分。此外,由于网络语料中存在着大量的相似文本,一些文本可能在训练中被模型看到多次。
本小节将分析PaLM模型对训练数据的记忆程度。为了评估,随机从训练样本中选择了100个token 序列,并使用前50个token来提示模型。使用贪心解码并衡量模型产生的50个延续token准确匹配训练样本的比例。方法遵循Carlini et al.,实验的prompt长度从50至500。
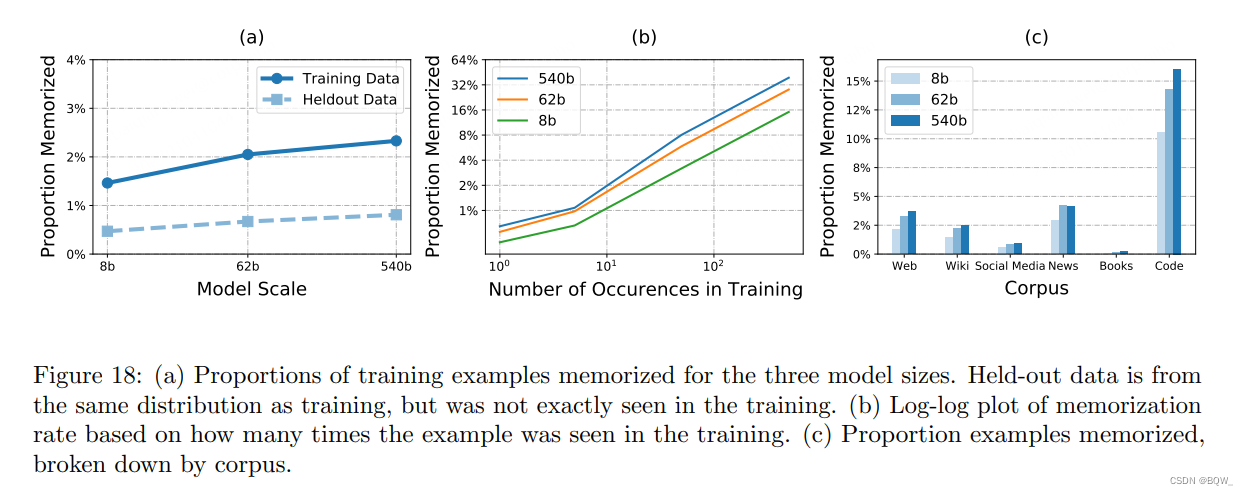
上图18(a)展示了三个规模模型的记忆匹配率。可以看到8B模型能够精准的为1.6%的数据重现50个token,而540B模型则能够精准重现2.4%的数据。此外,还评估了与训练数据相同分布中采样的留出数据的记忆率。留出数据的记忆率大于0%是因为留出的样本与训练样本非常相似,例如:开源代码许可证模板,仅更改了日期。
上图18(b) 展示了记忆率和训练样本在训练中被看到次数的函数。可以看到,训练样本在最大模型上被精确看到一次的记忆率是0.75%,而样本被看到500次的记忆率为40%。
上图18© 展示了三种模型在分解训练数据语料上的记忆率。在分析了记忆例子后得出结论,最大的区别在于训练中样本的精确复制、近似复制或者模板。代码语料中有大量的许可证字符串、从其他地方复制的共享代码片段以及自动生成的代码。书籍语料主要包含了真正独特的文本。
基于这些结果,可以得到如下关于记忆的结论:
- 相比于小模型,更大的模型有更高的记忆率。
- 记忆需要一定的数量,因此模型对常见的模板能够生成精确的匹配。然而,训练数据上的记忆率显著的高于留出数据上的记忆率,这意味着模型确实记忆住了部分数据。
- 一个样本被记住的几率和其在训练中的独特性高度相关。被看见一次的样本不太可能比看见多次的样本更容易被记忆。
实验发现被记忆的例子大多数是公式化的文本。然而也观察到了对故事、新闻文章和事实记忆的情况。事实上,可记忆内容的数量是训练数据集、模型尺寸的函数。例如,Carlini et al.展示了长的prompts能够发现更多的记忆实例。然而,简单的衡量能够被抽取的训练集文本数量并不能告诉我们这种记忆是否有问题。
记忆是否有问题取决于数据集的属性和目标应用。因此,大型语言模型选择下游应用时应该保持谨慎。防止在生成记忆样本一种计算高效的方法是在训练数据上训练一个布隆过滤器,并限制在训练数据集中逐字出现的序列被生成。由于来自某些源的数据可能比其他源更有问题,因此该方法通过在部分数据上构建布隆过滤器来提高内存效率。当然,该方法会移除记忆中的精确内容,但是仍然会产生近似内容。