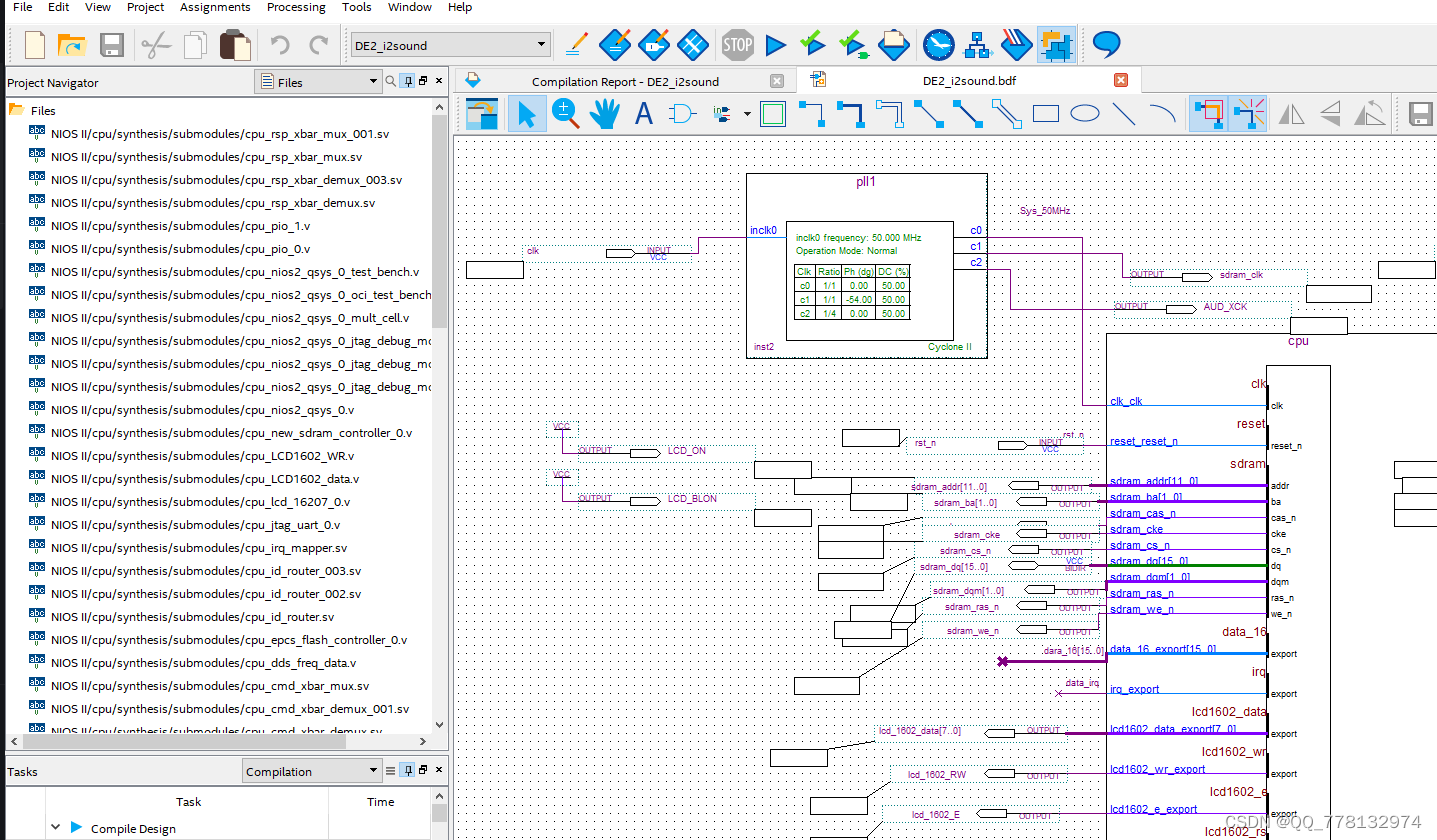
reset三种模式区别和使用场景
区别:
--hard:重置位置的同时,直接将 working Tree工作目录、 index 暂存区及 repository 都重置成目标Reset节点的內容,所以效果看起来等同于清空暂存区和工作区。
--soft:重置位置的同时,保留working Tree工作目录和index暂存区的内容,只让repository中的内容和 reset 目标节点保持一致,因此原节点和reset节点之间的【差异变更集】会放入index暂存区中(Staged files)。所以效果看起来就是工作目录的内容不变,暂存区原有的内容也不变,只是原节点和Reset节点之间的所有差异都会放到暂存区中。
--mixed(默认):重置位置的同时,只保留Working Tree工作目录的內容,但会将 Index暂存区 和 Repository 中的內容更改和reset目标节点一致,因此原节点和Reset节点之间的【差异变更集】会放入Working Tree工作目录中。所以效果看起来就是原节点和Reset节点之间的所有差异都会放到工作目录中。
使用场景:
--hard:(1) 要放弃目前本地的所有改变時,即去掉所有add到暂存区的文件和工作区的文件,可以执行 git reset -hard HEAD 来强制恢复git管理的文件夹的內容及状态;(2) 真的想抛弃目标节点后的所有commit(可能觉得目标节点到原节点之间的commit提交都是错了,之前所有的commit有问题)。
--soft:原节点和reset节点之间的【差异变更集】会放入index暂存区中(Staged files),所以假如我们之前工作目录没有改过任何文件,也没add到暂存区,那么使用reset --soft后,我们可以直接执行 git commit 將 index暂存区中的內容提交至 repository 中。为什么要这样呢?这样做的使用场景是:假如我们想合并「当前节点」与「reset目标节点」之间不具太大意义的 commit 记录(可能是阶段性地频繁提交,就是开发一个功能的时候,改或者增加一个文件的时候就commit,这样做导致一个完整的功能可能会好多个commit点,这时假如你需要把这些commit整合成一个commit的时候)時,可以考虑使用reset --soft来让 commit 演进线图较为清晰。总而言之,可以使用--soft合并commit节点。
--mixed(默认):(1)使用完reset --mixed后,我們可以直接执行 git add 将這些改变果的文件內容加入 index 暂存区中,再执行 git commit 将 Index暂存区 中的內容提交至Repository中,这样一样可以达到合并commit节点的效果(与上面--soft合并commit节点差不多,只是多了git add添加到暂存区的操作);(2)移除所有Index暂存区中准备要提交的文件(Staged files),我们可以执行 git reset HEAD 来 Unstage 所有已列入 Index暂存区 的待提交的文件。(有时候发现add错文件到暂存区,就可以使用命令)。(3)commit提交某些错误代码,或者没有必要的文件也被commit上去,不想再修改错误再commit(因为会留下一个错误commit点),可以回退到正确的commit点上,然后所有原节点和reset节点之间差异会返回工作目录,假如有个没必要的文件的话就可以直接删除了,再commit上去就OK了。

文章不错
spark 3.0特性 aqe https://cloud.tencent.com/developer/article/1791911
堆内内存 JVM on-heap 内存
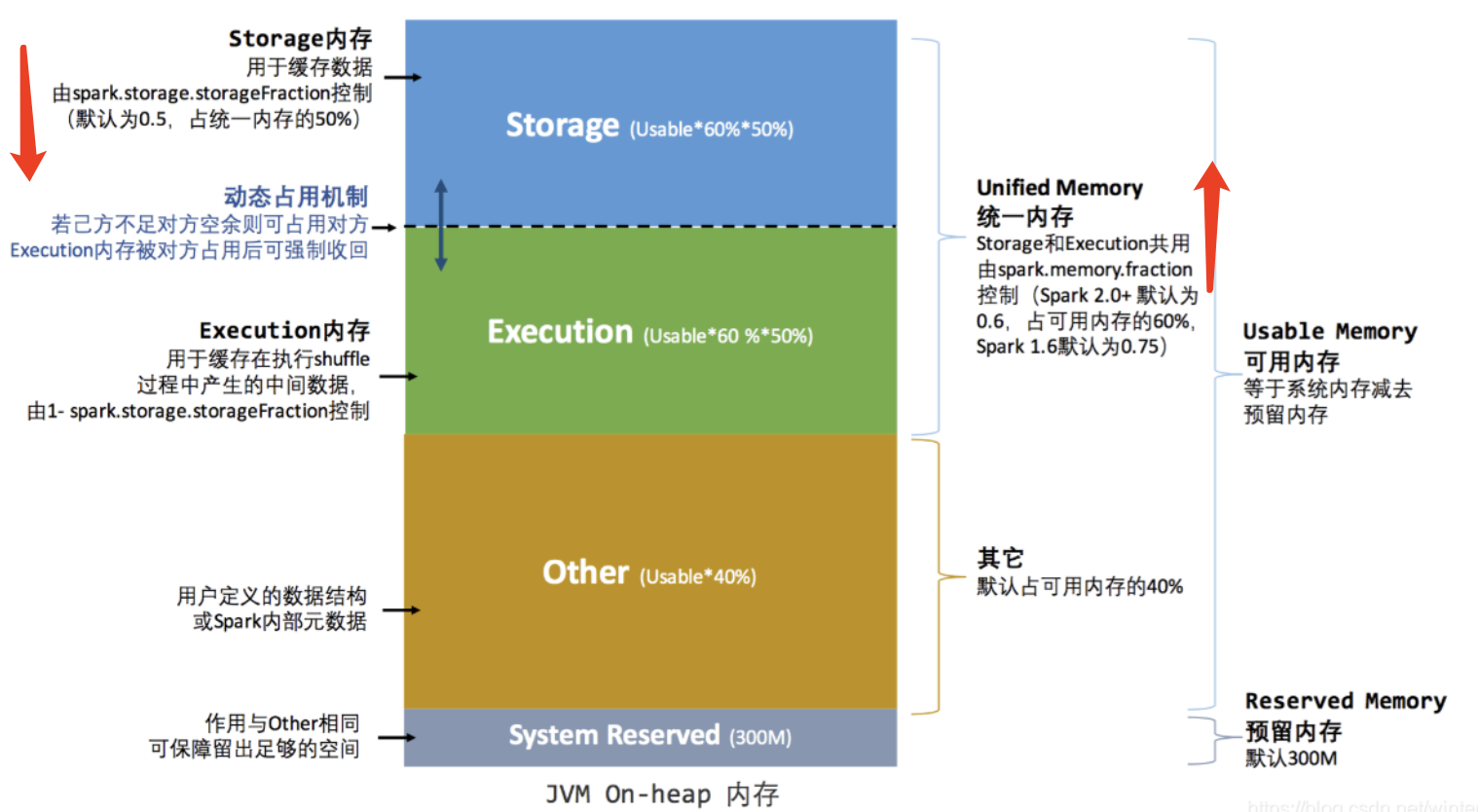
1、Storage 内存:Executor 内运行的并发任务共享JVM堆内内存,这些任务在缓存RRD数据集和广播(Broadcast)数据 时占用的内存被规划为存储(Storage)内存。60%
2、Execution 内存:这些任务在执行Shuffle时占用的内存被规划为执行(Execution)内存。 20%
堆内内存 JVM on-heap 内存
1、Storage 内存:Executor 内运行的并发任务共享JVM堆内内存,这些任务在缓存RRD数据集和广播(Broadcast)数据 时占用的内存被规划为存储(Storage)内存。60%
Execution 内存:这些任务在执行Shuffle时占用的内存被规划为执行(Execution)内存。 20%
1、Execution 内存:主要用于存放 Shuffle、Join、Sort、Aggregation 等计算过程中的临时数据
2、Storage 内存:主要用于存储 spark 的 cache 数据,例如RDD的缓存、unroll数据;
3、用户内存(User Memory):主要用于存储 RDD 转换操作所需要的数据,例如 RDD 依赖等信息。
4、预留内存(System Reserved Memory):系统预留内存,会用来存储Spark内部对象。
storage 60%*50% 存储内存 cache、 persist、 广播变量
execution 60%*50% 执行内存 shuffle
other 40% 其他内存 用户自定义数据结构(定义一个mapper)、 spark内部元数据
reserved 预留内存 300m
3.使用map-side预聚合的shuffle操作
如果因为业务需要,一定要使用shuffle操作,无法用map类的算子来替代,那么尽量使用可以map-side预聚合的算子。
所谓的map-side预聚合,说的是在每个节点本地对相同的key进行一次聚合操作,类似于MapReduce中的本地combiner。
map-side预聚合之后,每个节点本地就只会有一条相同的key,因为多条相同的key都被聚合起来了。
其他节点在拉取所有节点上的相同key时,就会大大减少需要拉取的数据数量,从而也就减少了磁盘IO以及网络传输开销。

JVM on-heap
静态内存模型 : 6:2:2
统一内存模型 : 3:3:4
storage : execution : reserved
JVM on-heap
均为1:1
堆内内存(On-Heap) 线程共享
堆外内存(Off-Heap)进程共享
注意几对概念:
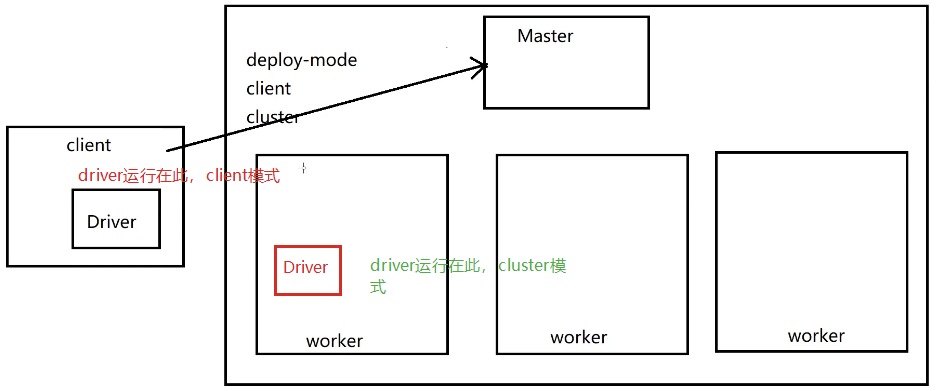
1、master worker
2、driver executor 是进程,driver其实也是在一个独立的JVM中。executor会启动一个线程池,每个线程运行的就是一个task
3、application job stage task
同一个executor里面的task是相同的,不同executor里的task可能不相同
spark on yarn
两种不同的模式:
1、client模式
2、cluster模式
模式上的区别:client模式,driver程序运行在client节点
cluster模式,driver程序运行在spark集群中的某一个wokrer中
使用上的区别:
client模式,通过spark-submit 提交任务成功了之后,不能干掉 client
cluster模式,通过spark-submit 提交任务成功了之后,是可以干掉client的
在mapredudceshuffle当中: 边shuffle边排序,就是为了排序
1、如果有reducer阶段就一定会进行shuffle
2、如果有shuffle,那么就一定会按照key排序
原因:
1、如果一个reduceTask执行计算的输入数据是无序的,则每个reduceTask进行分组聚合的时候,需要对这个输入文件尽心多次扫描。
2、reduceTask期望它的输入数据是有序的。按照顺序来扫描这个文件一次,就能做完所有分组操作
spark做了优化:
1、不用排序的shuffle
2、需要排序的shuffle
使用repartitionAndSortWithinPartitions替代repartition与sort类操作
原来的分区不吻合我的需求:先reparation, 然后每个分区sort排序!
rdd.repartition().sort(); < rdd.repartitionAndSortWithinPartitions