设计和优化神经网络架构通常需要广泛的专业知识,从手工设计开始,然后进行手动或自动化的精细化改进。这种依赖性成为快速创新的重要障碍。认识到从头开始自动生成神经网络架构的复杂性,本文引入了Younger,这是一个开创性的数据集,旨在推进人工智能生成神经网络架构 (AIGNNA) 的发展。
1 现状
- 早期手动设计: 早期神经网络架构如 AlexNet, ResNet, LSTM, Transformer 等都是手动设计的,需要大量专家知识和经验。这种方法的创新和灵活性有限,难以适应快速发展的数据和应用场景。
- 神经架构搜索 (NAS): NAS 通过自动化搜索和优化神经网络架构,提高了设计效率。然而,现有的 NAS 方法仍然依赖于预先定义的宏架构和有限的算子类型,限制了创新空间。
- 现有基准数据集: 现有的 GNN 基准数据集如 Cora, CiteSeer, PubMed, QM9, ZINC 等,主要包含结构简单、静态的图数据,难以测试 GNN 算法的可扩展性、鲁棒性和泛化能力。
2 数据集介绍
数据集来源: Younger数据集来源于超过174K个真实世界模型,这些模型涵盖了来自不同公共模型中心的30多个任务。包括7,629个独特的架构,每个架构都以有向无环图(DAG)的形式表示,并包含了详细的操作员级别的信息。
Younger 数据集分为三个系列:
- 完整系列: 包含所有从模型中提取的 DAG,记录了原始模型的来源和 ID。
- 过滤系列: 去除了同构 DAG 后的异构架构集合。
- 分割系列: 根据特定实验需求,对过滤系列数据进行分割和处理的版本。
3 数据集构建
Younger 数据集的构建过程主要包括以下四个步骤:
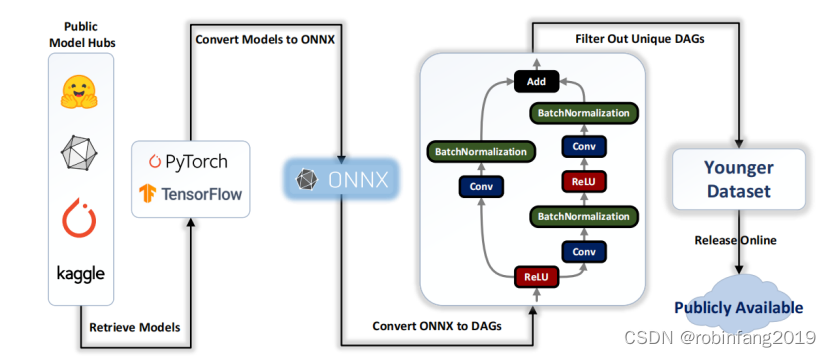
3.1 获取神经网络模型
- 从四个公开的神经网络模型仓库中获取模型:Kaggle Models, PyTorch Hub, ONNX Model Zoo, Hugging Face Hub。这些仓库包含各种深度学习任务和框架的模型,保证了数据的多样性。
- 开发自动化工具,定期更新数据,确保 Younger 数据集的时效性。
3.2 将模型转换为 ONNX 格式
- 使用 ONNX 作为统一表示格式,方便不同深度学习框架之间的模型交换和部署。
- 使用开源工具如 Optimum 和 tf2onnx 进行模型转换,降低转换成本。
3.3 从 ONNX 模型中提取 DAG
- 开发工具,将 ONNX 模型转换为 DAG,并去除参数信息,确保数据安全和隐私。
- 在 DAG 中,节点代表 ONNX 算子,记录详细的配置和超参数;边代表算子之间的数据流。
3.4 过滤数据集
- 使用 Weisfeiler-Lehman (WL) 图哈希算法,识别并过滤掉同构的神经网络架构,保证数据集中每个架构的唯一性。
- 最终,从 174K 个真实世界模型中提取出 7,629 个异构的神经网络架构。
4 实验验证
验证Younger数据集在人工智能生成神经网络架构(AIGNNA)方面的潜力和有效性,并探索其在现实世界场景中的可行性。
4.1 实验设计
- 统计分析: 在不同的粒度级别(操作员级别、组件级别和架构级别)进行了统计分析,以展示数据集包含足够丰富的先验知识。
- 实际应用探索: 探索了局部和全局设计范式的实践应用,证明了数据集在现实场景中的可行性。
4.2 统计分析
从低维度和高维度两个层面分析了 Younger 数据集的统计特性,揭示了数据集的丰富性和挑战性。
4.2.1 低维度统计信息
4.2.1.1 图的节点数和边数分布
- Younger 数据集中包含的 DAG 结构规模差异很大,从仅包含十几个节点的图到包含数十万个节点的图都有。
- 与现有的图数据集相比,Younger 数据集具有更广泛的节点数分布,这为 GNN 研究提供了更大的挑战和机遇。
4.2.1.2 常用 ONNX 算子
- Younger 数据集中包含 184 种 ONNX 算子,涵盖了各种类型的算子,包括张量变形、算术运算、逻辑运算和量化等。
- 其中,最常用的算子包括 ReLU、Conv、Add、MatMul 等,这些算子是构建神经网络架构的基础。
4.2.2 高维度统计信息
4.2.2.1 嵌入学习
使用 GCN 网络对 DAG 进行嵌入,将 DAG 转换为高维向量表示,以便于分析架构的分布特性。
4.2.2.2 不同粒度分析
- 算子嵌入: 将每个 DAG 中的所有算子进行嵌入,分析算子的分布特性。
- 子图嵌入: 将每个 DAG 中的所有子图进行嵌入,分析子图的分布特性。
- 图嵌入: 将每个 DAG 的所有子图嵌入取平均,得到整个 DAG 的嵌入表示。
4.2.2.3 结果分析
- 算子嵌入: 训练后的嵌入结果能够将高频算子和低频算子区分开来,但由于数据集中算子类型的多样性,学习过程仍然存在一定的偏差。
- 子图嵌入: 基线模型能够将不同子图的嵌入表示区分开来,但由于数据集中子图结构的复杂性,子图嵌入的学习效果仍然有待提高。
- 图嵌入: 不同架构的 DAG 嵌入表示在空间中距离较近,表明数据集涵盖了多种主流架构。同时,相同架构的 DAG 嵌入表示也存在多个点,表明数据集中存在该架构的多种变体。
统计分析结果表明,Younger 数据集具有丰富的统计特性,涵盖了各种类型的神经网络架构和算子。同时,数据集的复杂性和多样性也给 GNN 研究带来了新的挑战。
4.3 实际应用探索
4.3.1 局部设计范式
- 数据流设计: 使用图卷积网络(GCN)、图注意力网络(GAT)和GraphSAGE等模型在数据流设计范式下验证了神经架构细化的有效性。所有模型在Younger数据集上都取得了良好的性能,这证明了现有的图神经网络更适合预测神经网络架构中的数据流。
- 操作员设计: 使用五种不同的基线模型进行了十次实验,在操作员设计范式下,尽管所有基线模型都取得了高准确率,但F1分数、精确度和召回率仍然较低。这主要是由于Younger中复杂的图结构,其特征是许多操作员类型的存在。其中,多种类型的操作员出现频率较低,这对实现稳健的多分类性能构成了挑战。
4.3.2 全局设计范式
从头开始设计神经网络架构是一个开放且复杂的挑战。与神经架构搜索不同,后者将搜索空间限制在预定义的宏观架构内,同时优化微观架构元素以获得特定性能,全局范式寻求从基础开始生成包含详细操作员级元素的全面神经网络架构。
4.4 实验结果
- 在局部范式下,所有模型在Younger数据集上都表现出良好的性能,其中GCN在所有指标上的表现优于其他模型,除了F1分数。
- 在全局范式下,采用了使用扩散模型生成图的Digrress图生成模型。由于计算资源的限制和Younger图中节点数量最多可达数十万,我们只选择了节点数量在[1, 300]范围内的架构进行训练。
Younger数据集为AIGNNA提供了一个有前景的基准,通过实验,初步验证了Younger在新领域的神经架构设计方面的潜力和有效性。








![[word] Word如何删除所有的空行? #职场发展#学习方法](https://img-blog.csdnimg.cn/img_convert/794d729053d074244e428cdca4ddbbe2.png)
