variable templates
变量模板。这个特性允许模板被用于定义变量,就像之前模板可以用于定义函数或类型一样。变量模板为模板编程带来了新的灵活性,特别是在定义泛化的常量和元编程时非常有用。

变量模板的基本语法
变量模板的声明遵循以下基本语法:
template<typename T>
constexpr T someValue = /* some value depending on T */;
这里,T是一个类型参数,someValue是根据T变化的一个变量。
示例:定义一个泛化的π值
考虑一个简单的例子,我们想要定义一个依据类型变化的π值,以便能够获取不同精度的π值(例如,float,double,long double等)。
#include <iostream>
template<typename T>
constexpr T pi = T(3.1415926535897932385);
int main() {
std::cout << "pi<float> = " << pi<float> << std::endl;
std::cout << "pi<double> = " << pi<double> << std::endl;
std::cout << "pi<long double> = " << pi<long double> << std::endl;
return 0;
}
这个例子中,我们定义了一个变量模板pi,其类型是模板参数T。因此,我们可以请求pi的不同类型版本,获取相应精度的π值。
注意事项
- 类型完整性:变量模板在实例化时要求其类型参数必须是完整类型。
- 模板参数限制:和函数或类模板一样,变量模板不能推导其模板参数。
generic lambdas
泛型Lambda表达式,这大大增强了Lambda的灵活性和通用性。泛型Lambda允许Lambda的参数类型自动推导,更重要的是,它允许Lambda使用模板参数。这意味着,你可以写出更为通用的Lambda表达式,它们能够处理多种不同类型的数据,而不需要为每种类型编写特定的代码。
泛型Lambda的基本用法
在C++11中,Lambda参数的类型必须是显式声明的。而在C++14中,你可以使用auto关键字,让编译器自动推导参数的类型。这不仅仅是一个简化的语法糖,它实际上隐式地将Lambda转换成了一个模板。
例如,一个可以比较两个值的Lambda在C++14中可以写成:
auto compare = [](auto a, auto b) {
return a < b;
};
这个Lambda可以用于比较任意两个可以进行<操作的类型的值。
实现原理
当编译器遇到泛型Lambda的时候,它实际上为Lambda自动生成了一个模板类。每次调用泛型Lambda时,编译器根据传递给Lambda的参数类型,实例化出一个特定的模板实例。这就是C++14泛型Lambda如何提供类型通用性的基本原理。
使用场景
泛型Lambda可以在很多场合下简化代码,特别是与STL算法一起使用时。例如,使用泛型Lambda在一个容器中查找一个元素:
std::vector<int> v = {1, 2, 3, 4, 5};
int to_find = 3;
auto found = std::find_if(v.begin(), v.end(), [to_find](auto elem) { return elem == to_find; });
这段代码使用了泛型Lambda来定义查找条件,这使得相同的Lambda可以应用于不同类型的容器和元素。
注意事项
-
捕获表达式的自动类型推导:泛型Lambda可以捕获外部变量,但是这些捕获的变量类型必须在Lambda表达式创建时就已经确定。这意味着不能捕获泛型Lambda自身作为变量,因为在创建时Lambda的类型还未确定。
-
Lambda不能被重载或特化:与函数模板不同,Lambda表达式不能被重载或特化。这意味着同一个Lambda表达式必须能够处理所有它可能被调用的的类型。
-
递归调用:泛型Lambda表达式不能直接递归调用自己,因为
auto类型参数不允许在Lambda内部推导其自身类型
lambda init-capture
C++14引入了一个新的Lambda表达式特性:初始化捕获(init-capture),也被称为广义Lambda捕获或Lambda初始化。这项特性让我们能够在Lambda表达式的捕获列表中,直接定义并初始化新的变量。这提供了更加灵活的变量捕获方式,允许在Lambda表达式创建时构造新的对象或执行复杂的初始化。
基本语法
初始化捕获的基本语法是在Lambda捕获列表中使用[name = expression]形式,其中name是在Lambda体中使用的新变量的名称,而expression是用于初始化该变量的表达式。例如:
int x = 42;
auto lambda = [y = x + 1] { return y; };
std::cout << lambda(); // 输出 43
在这个例子中,通过初始化捕获创建了一个名为y的新变量,并将其初始化为x + 1的值。y在Lambda内部可用,就像任何其他捕获的变量一样。
特点与用途
初始化捕获的引入解决了C++11中存在的一些局限性:
-
移动语义支持:在C++11中,Lambda只能通过值或引用捕获外部变量,不能方便地捕获通过移动语义获得的对象。C++14通过初始化捕获支持移动语义,使得能够移动而非复制对象到Lambda表达式内部。
auto p = std::make_unique<int>(42); auto lambda = [ptr = std::move(p)] { return *ptr; }; -
复杂的初始化:初始化捕获允许在Lambda捕获列表中执行复杂的表达式计算,无需在Lambda外部单独声明和初始化变量。
-
避免不必要的捕获:有时我们希望Lambda表达式依赖于从外部变量派生的值,而不直接依赖这些外部变量本身。通过初始化捕获,可以避免不必要地捕获外部变量,减少资源捕获的开销。
注意事项
- 初始化捕获只能创建拷贝或通过移动语义创建的变量。这意味着,你不能通过初始化捕获来直接声明一个引用类型的变量。例如,以下代码是不合法的:
int x = 42;
auto lambda = [&y = x] { return y; }; // 错误:不能通过初始化捕获来创建引用
relaxed restrictions on constexpr functions
在C++14中,对constexpr函数的限制相较于C++11有了显著放宽。constexpr函数或变量表达的是它们可以在编译时被求值,这对于提高程序的性能和安全性非常重要。在C++11中,标记为constexpr的函数受到了很多限制,使得它们的用途相对有限。然而,C++14放宽了这些限制,使得constexpr函数变得更加灵活和强大。
C++11中的constexpr函数限制包括:
- 函数体内只能包含一个单一的返回语句。
- 不能有任何变量声明。
- 不能有任何循环或分支语句。
C++14放宽的限制:
-
多条语句:C++14允许
constexpr函数包含多条语句,使得你可以在constexpr函数中执行更复杂的计算。 -
局部变量:允许在
constexpr函数内部声明和使用局部变量,只要这些变量的类型也都是字面类型(Literal Type)。 -
循环和分支:在C++14中,
constexpr函数现在可以使用循环和条件分支,这大大增加了它们的灵活性和能力。 -
递归:由于允许使用多条语句和条件分支,
constexpr函数现在也支持递归调用。
示例对比:
C++11中的constexpr函数:
constexpr int factorial(int n) {
return n <= 1 ? 1 : (n * factorial(n - 1));
}
C++14中的constexpr函数:
constexpr int factorial(int n) {
int result = 1;
for(int i = 1; i <= n; ++i) {
result *= i;
}
return result;
}
在C++14的例子中,我们利用了局部变量、循环,以及允许在constexpr函数中包含多条语句的特性。
注意点:
- 即使C++14放宽了对
constexpr函数的限制,但是为了在编译时求值,函数的所有输入和逻辑仍然需要在编译时是已知的。 constexpr函数也可以在运行时被调用,如果其参数在编译时不是已知的。在这种情况下,它们就像普通函数那样工作。
binary literals
二进制字面量,使得开发者可以直接在代码中以二进制形式表示整数。这一特性对于底层编程、位操作或者对内存布局有特定要求的场景尤为有用。在C++14之前,表达二进制数据通常需要使用十六进制或八进制,尽管这些方法也相对直观,但直接使用二进制字面量无疑能让代码的意图更加明显。

使用方法
二进制字面量通过在数字前加0b或0B前缀来表示。后续紧跟二进制数字(0或1)。
// C++14 二进制字面量示例
int a = 0b1010; // 等于十进制的10
int b = 0B0011; // 等于十进制的3
这种表示方法使得表达和理解涉及位操作的代码变得更加直观和简洁。
注意事项
-
前缀规定:二进制字面量必须以
0b或0B前缀开始。没有此前缀,数字会被解释为十进制数。 -
类型默认为
int:就像十进制和十六进制字面量一样,未经明确指定的二进制字面量将被视为int类型。如果字面量超出了int类型的范围,这可能导致未定义行为或编译错误。
digit separators
数字分隔符,允许在数值字面量中使用单引号'作为分隔符,以提高数值的可读性。这对于编写涉及大数值的代码特别有用,使得这些大数值更容易阅读和理解。
使用方法
数字分隔符可以在整数、浮点数以及二进制、八进制、十六进制数字字面量中使用。分隔符可以放置在数字之间的任何位置,但不能放置在数字的开头或结尾。此外,分隔符不能连续使用。
以下是一些使用数字分隔符的示例:
long long earth_population = 7'800'000'000; // 世界人口约78亿
unsigned long distance_to_moon = 384'400; // 月球距离地球大约384,400千米
double avogadro_number = 6.022'140'76e23; // 阿伏伽德罗常数
int binary_data = 0b1010'0110'1101'0011; // 二进制字面量
注意事项
-
位置限制:数字分隔符(单引号
')不能放置在数值字面量的开头或结尾。此外,分隔符之间至少要有一位数字,不允许连续使用分隔符。 -
前缀后立即使用:对于二进制(
0b或0B)、八进制(0)、十六进制(0x或0X)字面量,分隔符不能紧跟数值前缀后立即出现。比如,0x'FF是不合法的,正确的写法应该是0xFF。 -
浮点数及科学记数法:在浮点数和使用科学记数法的字面量中,分隔符同样不能用在小数点或指数标识符(
e或E)之前或之后立即出现。
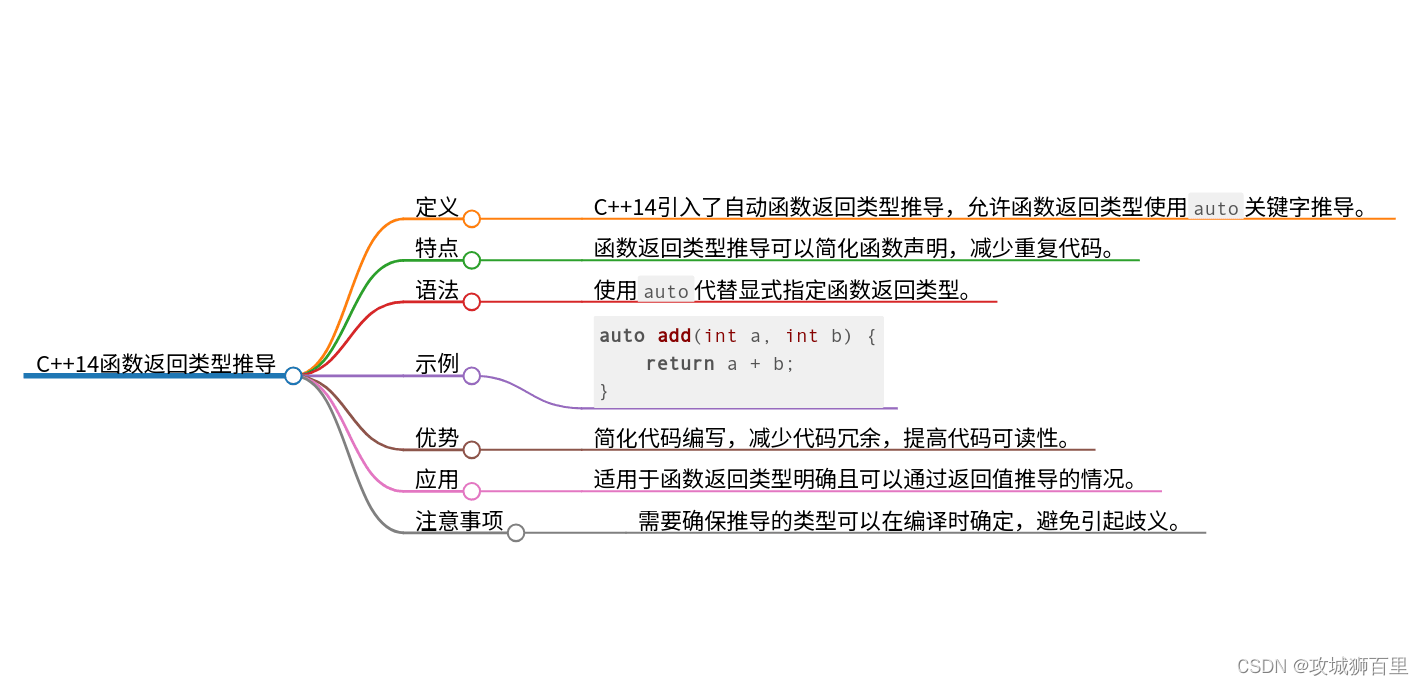
return type deduction for functions
函数返回类型推导,允许编译器从函数体中推导函数的返回类型,而不需要显式地指定。这一特性大大提高了C++语言的灵活性和表达力,尤其是在编写模板代码和Lambda表达式时。
使用方法
要使用函数返回类型推导,可以在函数声明中使用auto作为返回类型。编译器会根据函数体中return语句的类型来自动推导整个函数的返回类型。
auto Add(int x, int y) {
return x + y; // 返回类型根据返回值推导为int
}
auto GetMessage() {
return "Hello, World!"; // 返回类型根据返回值推导为const char*
}
-
如果函数包含多个
return语句,那么所有return语句的返回类型必须相同,或者必须有一个明确的、可以自动转换的公共类型,否则会导致编译错误。 -
函数不能仅由一个不返回任何值的
return语句构成,这样编译器无法推导出返回类型。 -
在某些复杂的情况下,显式指定返回类型可能更加清晰和直观。
适用场景
函数返回类型推导特别适用于如下场景:
-
模板编程:在模板编程中,函数的返回类型可能依赖于模板参数,使用
auto可以避免复杂的类型声明。 -
Lambda表达式:Lambda表达式在C++11中引入时就支持返回类型推导,C++14将这一特性扩展到了所有函数。
-
减少冗余:在某些函数的返回类型非常明显的情况下,使用返回类型推导可以减少代码的冗余,并提高代码的简洁性和可读性。
注意事项
-
一致的返回类型:如果函数包含多个
return语句,所有return语句必须具有相同的类型,或者它们的类型能够隐式转换为一个共同的类型。否则,编译器将无法推导出一个确定的返回类型,导致编译错误。 -
无返回值的情况:使用
auto作为返回类型时,函数体不能仅包含不返回值的return语句(例如,空的return;)。这是因为编译器需要通过return语句的类型来推导函数的返回类型。 -
递归函数的限制:对于递归函数,编译器可能无法在所有情况下准确推导出返回类型。
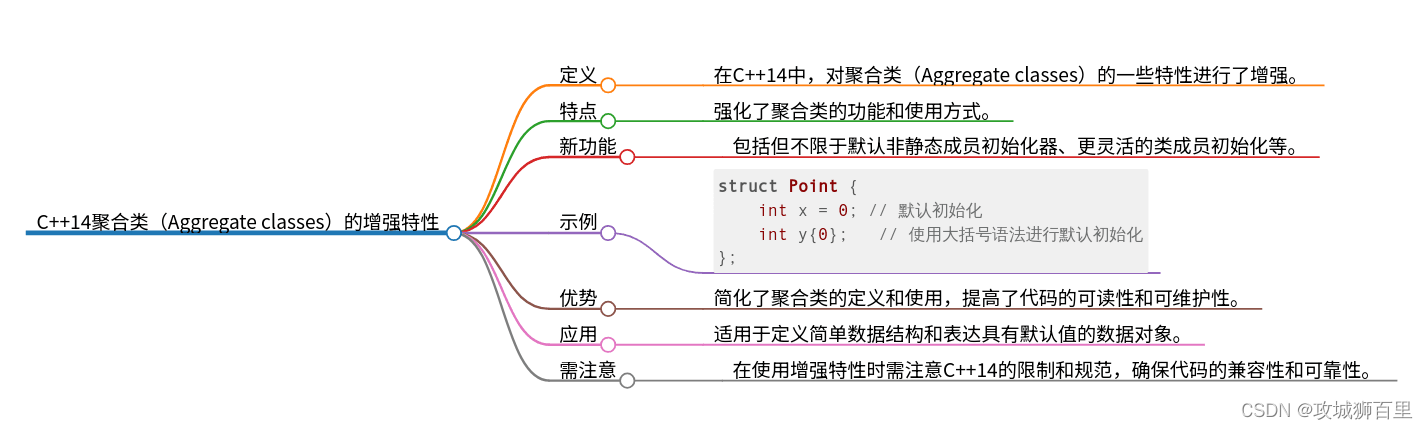
aggregate classes with default non-static member initializers
在C++14中,聚合类(Aggregate classes)的特性得到了增强,允许包含默认的非静态成员初始化器(Default non-static member initializers)。这意味着聚合类除了原有的特点,比如没有用户定义的构造函数(User-defined constructors)、没有私有或保护的非静态数据成员、没有基类和虚函数等,现在还可以为其非静态成员指定默认初始值。
聚合类定义
在C++14之前,聚合类主要用于简单地将数据组合在一起,没有复杂的类初始化语义。具体来说,一个聚合类满足以下条件:
- 没有用户定义的构造函数
- 没有私有或保护的非静态数据成员
- 没有虚函数
- 没有基类
C++14中的变化
C++14允许聚合类的非静态数据成员拥有默认的初始化器。这增加了聚合类的灵活性和易用性,允许它们在定义时指定成员的初始状态,而不需要用户定义的构造函数。
struct Point {
int x{0}; // 默认初始化为0
int y{0};
};
Point p; // p.x和p.y都默认初始化为0
Point q = {1, 2}; // 通过聚合初始化设置x为1,y为2
std::make_unique
内存管理工具——std::make_unique。这个函数模板用于创建并返回一个指向动态分配对象的std::unique_ptr,简化了动态内存分配的过程并帮助避免内存泄漏。

使用方法
std::make_unique函数模板的基本语法如下:
std::unique_ptr<T> make_unique<Args>(Args&&... args);
其中,T是动态分配对象的类型,Args是构造函数的参数列表。
示例:
auto ptr = std::make_unique<int>(42); // 创建一个指向int的std::unique_ptr并初始化为42
struct Point {
int x;
int y;
};
auto point = std::make_unique<Point>(Point{1, 2}); // 创建一个指向Point结构体的std::unique_ptr并初始化其成员
注意事项
-
只能创建std::unique_ptr:
std::make_unique只能用于创建std::unique_ptr,无法创建std::shared_ptr。对于需要使用std::shared_ptr的情况,应当使用std::make_shared或手动分配。 -
无法自定义删除器:与直接使用
std::unique_ptr构造函数不同,std::make_unique无法指定自定义的删除器。如果需要自定义内存释放方式,需要通过std::unique_ptr的构造函数来实现。 -
仅适用于单个对象:
std::make_unique仅用于分配单个对象的内存,并不能用于分配数组。分配数组需要使用std::make_unique替代品std::make_unique_for_overwrite或手动分配。 -
不支持初始化列表构造函数:
std::make_unique不支持通过初始化列表构造对象,只能传递参数给对象的构造函数来创建对象。 -
不支持动态数组:使用
std::make_unique创建的对象并不支持动态数组,因为std::unique_ptr不支持动态数组的内存释放。 -
类类型限制:要使用
std::make_unique创建的对象类型,必须是完整的对象类型,不能是不完整类型或抽象类型。
std::shared_timed_mutex and std::shared_lock
在C++14标准中,引入了std::shared_timed_mutex和std::shared_lock,这两个类分别是用于多线程读写操作的共享互斥锁和共享锁,提供了更灵活和高效的并发控制机制。
std::shared_timed_mutex
std::shared_timed_mutex是一个支持读写操作的共享互斥锁,允许多个线程同时读取共享数据,但在写入操作时会独占资源。
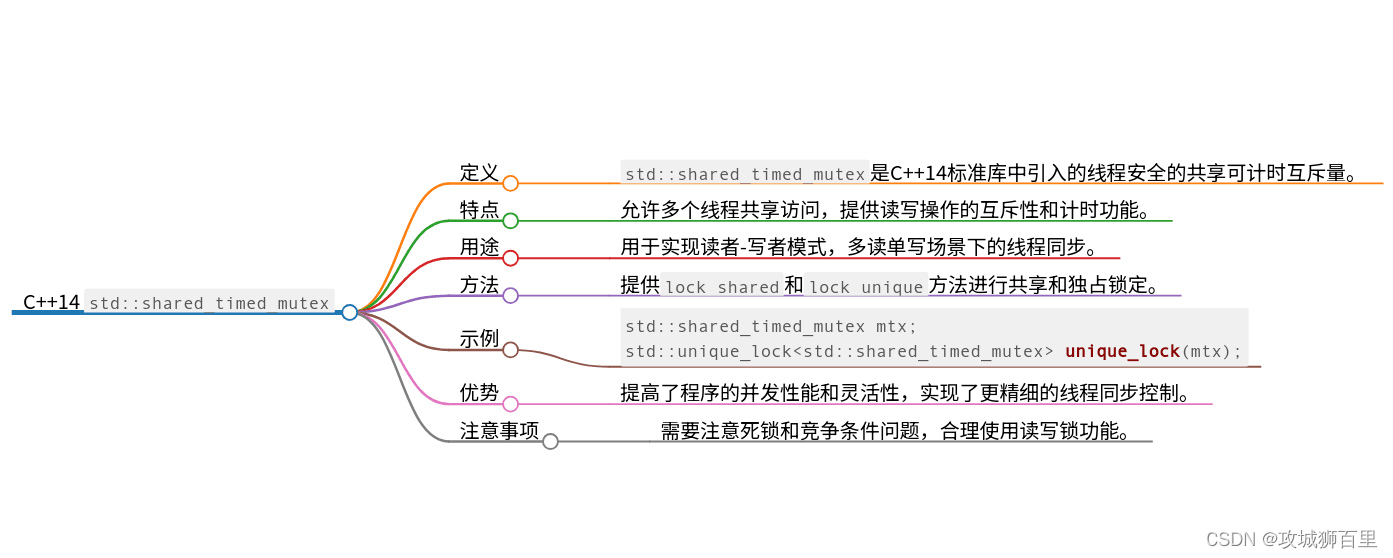
特点:
-
共享读取:多个线程可以同时获取共享锁(读取锁),允许并发读取数据。
-
独占写入:在写操作时,会独占资源,防止并发写入数据造成数据竞争。
-
超时支持:支持超时等待功能,可以在一定时间内获取锁或放弃操作。
使用std::shared_timed_mutex可以实现多线程读写操作的并发控制。以下是std::shared_timed_mutex的基本用法示例:
创建和初始化:
#include <iostream>
#include <thread>
#include <shared_mutex>
std::shared_timed_mutex mutex;
int shared_data = 0;
读取操作:
void read_data() {
std::shared_lock<std::shared_timed_mutex> lock(mutex);
std::cout << "Reading data: " << shared_data << std::endl;
}
写入操作:
void write_data(int value) {
std::unique_lock<std::shared_timed_mutex> lock(mutex);
shared_data = value;
std::cout << "Writing data: " << shared_data << std::endl;
}
主函数示例:
int main() {
// 创建读线程和写线程
std::thread reader1(read_data);
std::thread reader2(read_data);
std::thread writer(write_data, 42);
// 等待线程执行完毕
reader1.join();
reader2.join();
writer.join();
return 0;
}
在上述示例中,通过std::shared_lock和std::unique_lock锁定std::shared_timed_mutex实现了读和写的并发控制。多个读线程可以同时访问共享数据shared_data,而写线程在进行写操作时会独占资源,防止读写竞争。
std::shared_lock
std::shared_lock是用于管理共享互斥锁的智能锁类,它提供了对共享锁的自动获取和释放,简化了多线程编程中关于共享锁的操作。
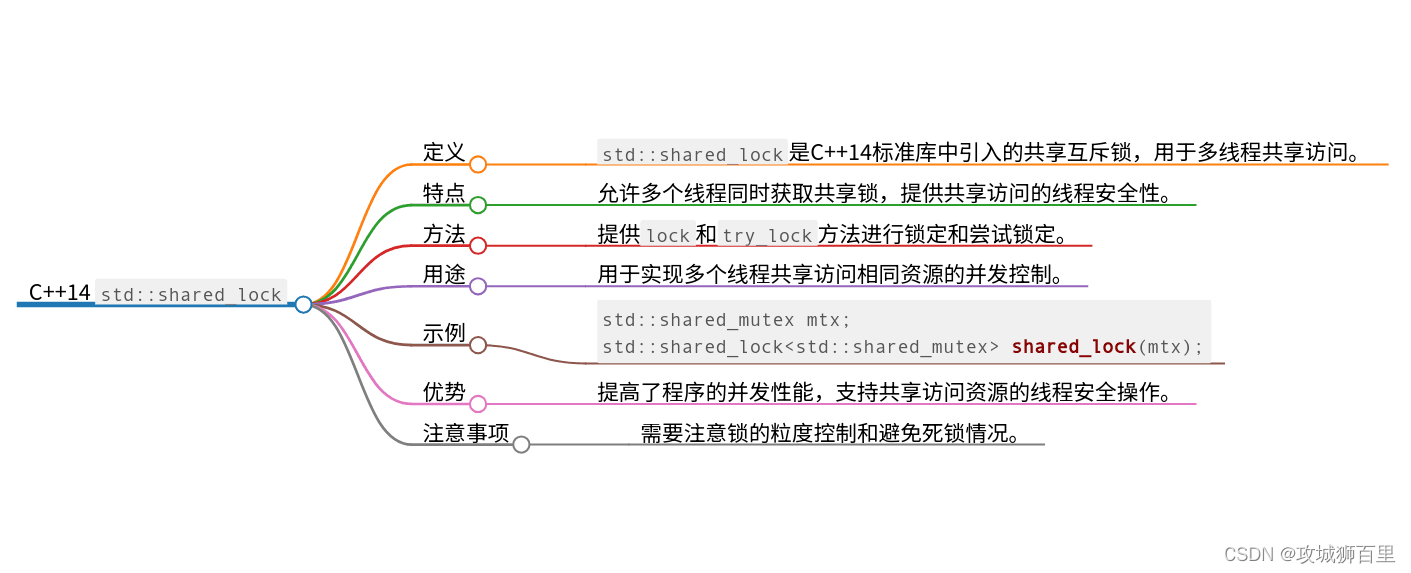
特点:
-
自动加锁和解锁:
std::shared_lock在构造时自动获取共享锁,在析构时自动释放共享锁,保证锁的正确使用。 -
共享锁支持:
std::shared_lock可以管理对std::shared_timed_mutex的共享锁,支持多线程并发读取数据。 -
适用于多读单写场景:适用于多个线程同时读取数据,但需要独占写入数据的场景,提高了读操作的并发性能。
std::shared_lock是C++14标准中用于管理共享互斥锁的智能锁类,它提供了对共享锁的自动获取和释放,能够简化多线程编程中的共享数据访问操作。以下是使用std::shared_lock的基本示例:
示例代码:
#include <iostream>
#include <thread>
#include <shared_mutex>
std::shared_timed_mutex mutex;
int shared_data = 0;
void read_data() {
std::shared_lock<std::shared_timed_mutex> lock(mutex);
std::cout << "Reading data: " << shared_data << std::endl;
}
void write_data(int value) {
std::unique_lock<std::shared_timed_mutex> lock(mutex);
shared_data = value;
std::cout << "Writing data: " << shared_data << std::endl;
}
int main() {
// 创建读线程和写线程
std::thread reader1(read_data);
std::thread reader2(read_data);
std::thread writer(write_data, 42);
// 等待线程执行完毕
reader1.join();
reader2.join();
writer.join();
return 0;
}
-
在主函数中,创建了两个读线程
reader1和reader2,以及一个写线程writer。 -
read_data()函数中使用std::shared_lock来锁定std::shared_timed_mutex,实现共享锁的获取,允许多个线程同时读取共享数据shared_data。 -
write_data(int value)函数中使用std::unique_lock来锁定std::shared_timed_mutex,实现独占锁的获取,确保写入操作时独占资源,防止数据竞争。 -
主函数中启动读线程和写线程,并通过
join()等待线程执行完毕。 -
在读取数据时,通过
std::shared_lock获取共享锁来读取共享数据,而在写入数据时,通过std::unique_lock获取独占锁来写入数据。
std::integer_sequence
std::integer_sequence是C++14引入的一个模板类,用于表示编译时整数序列。这个实用的模板类使得编译时的整数操作(比如索引列表、解包元组等)变得简单和类型安全。它常常与模板元编程和编译时计算一起使用,为C++模板提供了强大的编译时序列处理能力。
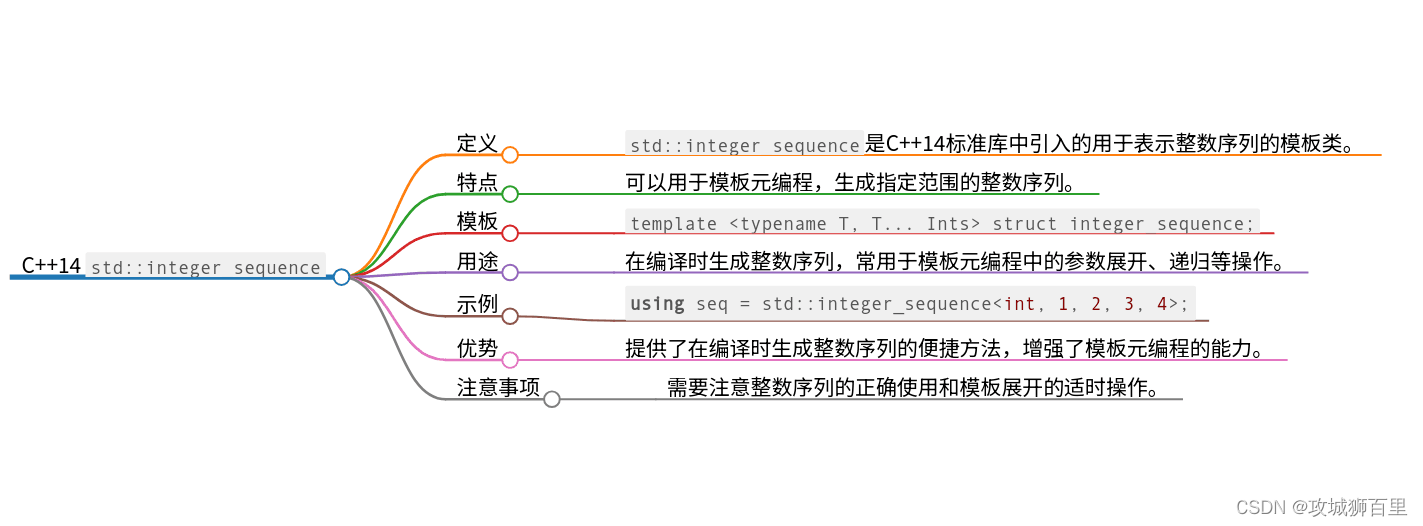
std::integer_sequence基本概念
std::integer_sequence<T, Ints...>是一个编译时整数序列的类型,其中T是整数类型(如int, size_t等),而Ints...则是一系列T类型的编译时常量。
用法示例
假如你想在编译时生成一个整数序列(例如,0到N-1),可以使用std::make_integer_sequence和std::integer_sequence来实现这一点。这种能力非常方便当你需要基于索引进行模板展开或操作元组时。
示例代码
下面是一个利用std::integer_sequence和std::make_integer_sequence展开函数参数并打印元组内容的示例:
#include <iostream>
#include <tuple>
// 函数模板,用于打印元组中的每个元素
template<typename Tuple, std::size_t... I>
void printTupleImpl(const Tuple& t, std::index_sequence<I...>) {
((std::cout << (I == 0 ? "" : ", ") << std::get<I>(t)), ...);
}
// 打印元组的主函数模板
template<typename... Args>
void printTuple(const std::tuple<Args...>& t) {
printTupleImpl(t, std::make_index_sequence<sizeof...(Args)>{});
}
int main() {
auto t = std::make_tuple(1, "two", 3.14); // 一个包含不同类型元素的元组
std::cout << "Tuple contains: ";
printTuple(t); // 打印元组内容
std::cout << std::endl;
return 0;
}
特性和用途
-
编译时索引生成:利用
std::make_integer_sequence或std::make_index_sequence生成一个编译时索引序列,以便于模板元编程和编译时算法中进行迭代或索引操作。 -
元组访问与展开:结合
std::get和std::index_sequence可以实现编译时的元组访问和元素展开,这对于泛型编程中的参数解包特别有用。 -
模板元编程:
std::integer_sequence和相关工具使得在模板元编程中处理整数序列变得更加直观和类型安全。
通过std::integer_sequence,C++14进一步增强了模板编程的能力,为编译时的序列操作提供了强大的工具。
std::exchange
std::exchange 是 C++14 标准库中引入的一项非常实用的功能。它位于 <utility> 头文件中。这个函数模板允许你将一个变量的值替换为另一个新值,同时返回变量原来的值。这种操作在很多情况下是非常便利的,尤其是在需要更新变量值的同时,又需要保留变量原来的值时。
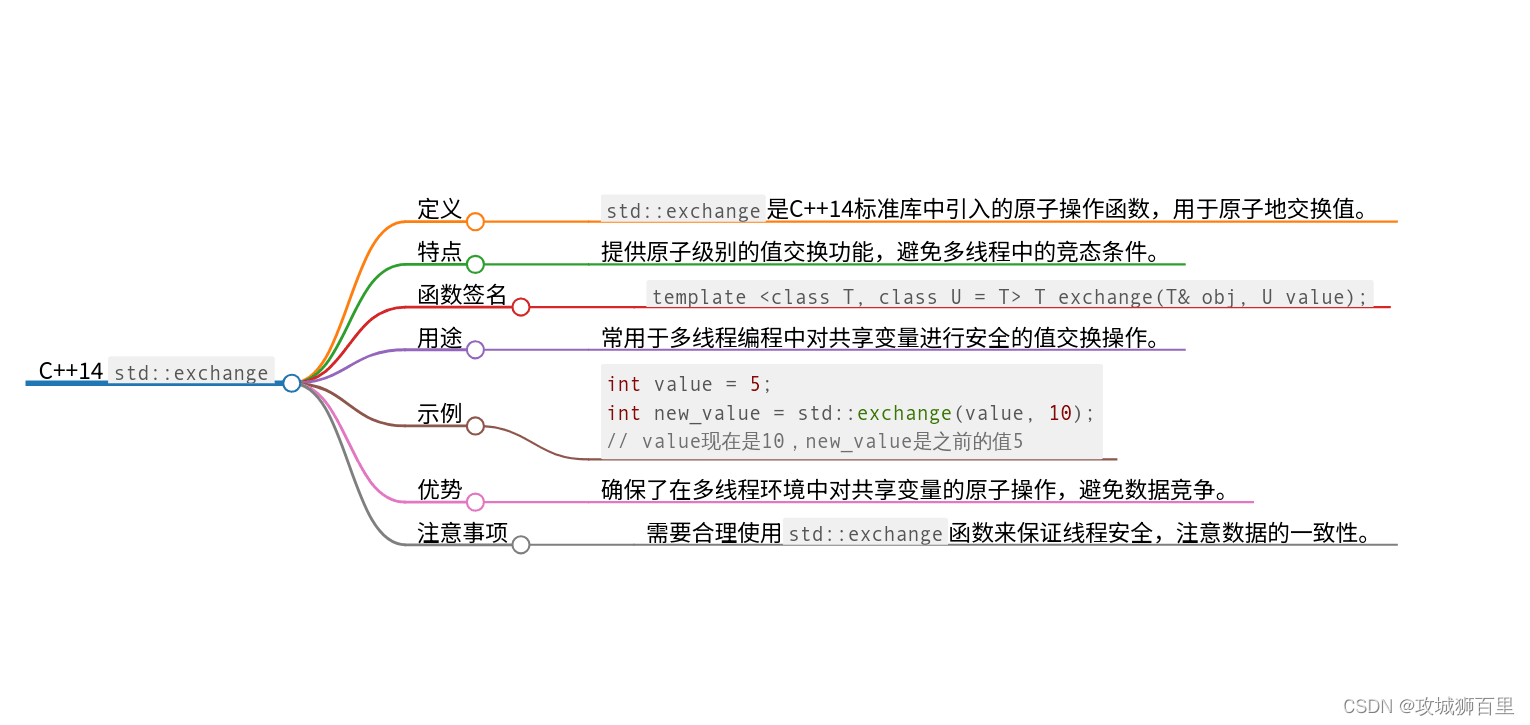
std::exchange 的函数原型
template< class T, class U = T >
T exchange( T& obj, U&& new_value );
obj: 是一个将要被新值替换的对象的引用。new_value: 是将要被设置给obj的新值。可以是右值引用(采用移动语义),这样可以避免不必要的复制操作。- 返回值:函数返回
obj的原始值。
使用示例
下面是一个使用 std::exchange 的简单示例,展示了如何使用它交换变量的值:
#include <iostream>
#include <utility>
#include <vector>
int main() {
int old_value = 42;
int new_value = 84;
// 使用 std::exchange 更新 old_value,同时获取其原始值
int original_value = std::exchange(old_value, new_value);
std::cout << "Original value: " << original_value << std::endl; // 输出:42
std::cout << "New value: " << old_value << std::endl; // 输出:84
// 也可以用于复杂类型,比如在替换 std::vector 内容时
std::vector<int> vec = {1, 2, 3};
std::vector<int> new_vec = {4, 5, 6};
auto old_vec = std::exchange(vec, std::move(new_vec));
// vec 现在 包含 new_vec 的内容,而 new_vec 是空的
for (int v : vec) std::cout << v << " "; // 输出:4 5 6
std::cout << std::endl;
return 0;
}
std::quoted
std::quoted 是 C++14 中引入的,位于 <iomanip> 头文件中的一个实用功能。它提供了一种便捷的方法来对输入和输出流进行引用和解引用操作,这在处理包含空格或分隔符的字符串时格外有用。它确保了字符串的完整性,在读取和写入文件或处理用户输入时特别有用。这个功能的出现简化了程序员在处理文本数据时需要编写的引号管理与转义字符的工具代码。
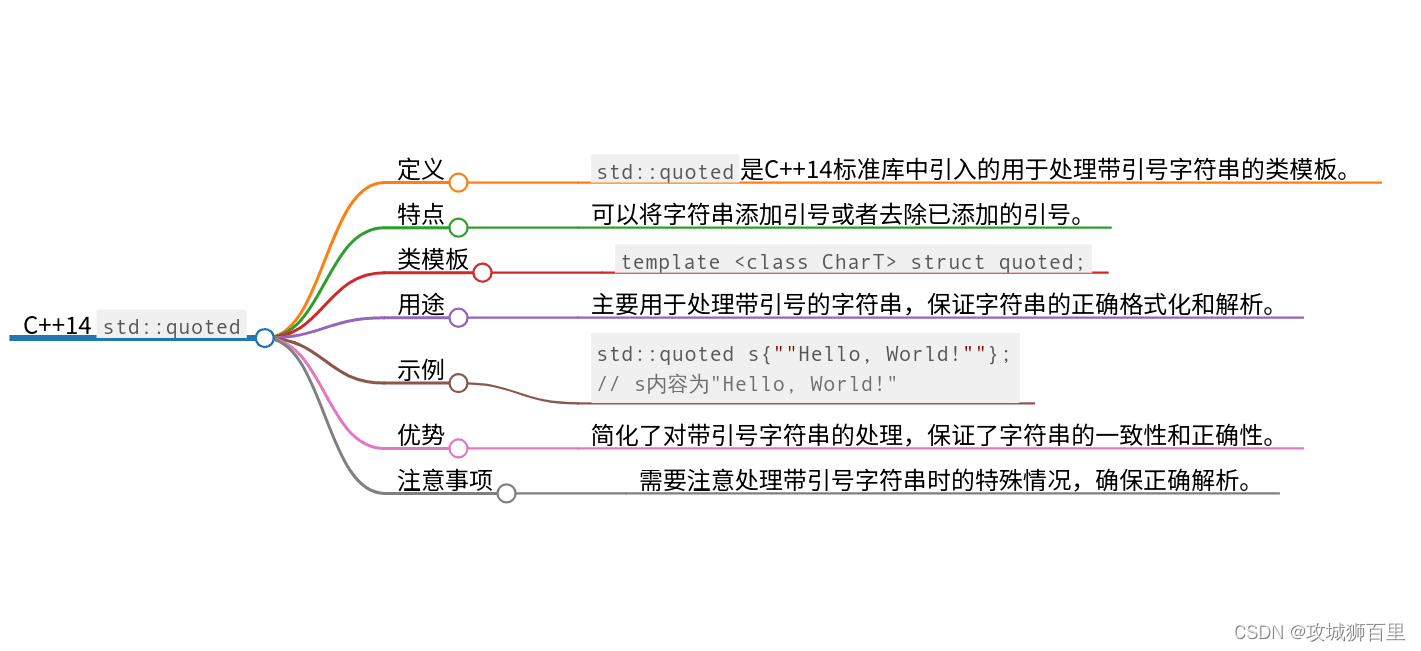
std::quoted 的基本用法
std::quoted 的主要目的是确保字符串数据在经过输入输出操作时,能够保持它们的字面值,并且正确处理其中的特殊字符。它会自动为字符串添加引号,并且将内部的特殊字符(如引号本身)进行转义,确保字符串在存储和传输时不会损失信息。
函数签名
template< class CharT, class Traits, class Allocator >
std::basic_ostream<CharT, Traits>& operator<< (std::basic_ostream<CharT, Traits>& os, const std::basic_string<CharT, Traits, Allocator>& str );
template< class CharT, class Traits, class Allocator >
std::basic_istream<CharT, Traits>& operator>> (std::basic_istream<CharT, Traits>& is, std::basic_string<CharT, Traits, Allocator>& str );
- 第一个函数签名表示在输出流中使用
std::quoted来写入字符串。 - 第二个函数签名表示在输入流中使用
std::quoted来读取字符串。
示例代码
#include <iostream>
#include <sstream>
#include <iomanip> // 导入 std::quoted
int main() {
std::string input = R"(John Doe "Programmer")";
std::stringstream sstream;
// 写入字符串时加上引号和必要的转义
sstream << std::quoted(input);
std::cout << sstream.str() << std::endl; // 输出:"John Doe \"Programmer\""
// 从流中读取字符串时解除引号和转义
std::string output;
sstream >> std::quoted(output);
std::cout << output << std::endl; // 输出:John Doe "Programmer"
return 0;
}
使用场景
- 当你需要向文件或其他输出流写入字符串,并想保证即使字符串中包含引号或特殊字符也能正确写入和读取时,使用
std::quoted。 - 在处理来自用户的输入,特别是在需要保留输入字符串中的空格和引号时。
通过使用 std::quoted,你能够更简单地处理文本数据,无需担心引号管理、转义符等细节问题。这在读写配置文件、处理CSV格式数据、或进行网络通信时特别有用,因为这些场合下经常会遇到需要精确管理字符串边界和特殊字符的情况。
and many small improvements to existing library facilities, such as
C++14 不仅引入了一些全新的功能和改进,还对现有库设施进行了许多小的改进。这些改进提高了标准库的实用性和灵活性。以下是一些值得注意的改进:
1. 类型推导和 auto 改进
- 返回类型推导:C++14 改善了函数返回类型的推导能力,使得在编写函数时,可以省略返回类型,并让编译器自动推导。
- 泛型 Lambda:C++14 允许在 lambda 表达式中使用
auto关键字作为参数类型,从而使 Lambda 表达式具有泛型能力。
2. std::make_unique
C++14 在 <memory> 头文件中引入了 std::make_unique 函数模板,作为创建 std::unique_ptr 实例的首选方式。这一改进补充了 C++11 中引入的 std::make_shared,使得智能指针的创建更加完整。
3. 数字字面量改进
C++14 引入了对二进制字面量的支持,允许直接用二进制形式表示整数。此外,引入了整型字面量和浮点型字面量的单字符后缀,用于指定更具体的类型。
4. 容器和算法的改进
std::cbegin和std::cend:用于获取容器的 const 迭代器,即使容器本身是非 const 的。- 容器访问函数:如
std::at函数,增加了对访问数组元素的安全性。 - 算法改进:例如,
std::copy_n,std::all_of,std::any_of,std::none_of等标准算法被改进,使其使用起来更加方便。
5. 编译时整数序列
通过 std::integer_sequence 和 std::make_integer_sequence 等,C++14 引入了编译时整数序列的支持,这在模板元编程中非常有用。
6. 定制化点
C++14 引入了定制化点 (customization points),通过定义特殊的自定义命名空间,开发者可以更加灵活地控制 ADL (Argument-Dependent Lookup) 的行为。
7. 其他语言和库改进
- 弃用属性:引入了
[[deprecated]]属性,允许标记过时的代码,提示使用者注意。 - 特化
std::get<>():对std::tuple的std::get<>()函数进行了特化,使得可以通过类型来获取元素。 - 着色器语言静态数据成员:允许着色器语言 (如 OpenGL Shading Language) 着色器和 C++ 代码共享静态数据成员。
这些是 C++14 引入的许多小改进中的一部分示例。这些改进的加入,使得 C++ 更加现代化,灵活性和实用性都得到了提升。开发者能够借助这些新特性和改进,编写出更简洁、更高效、更易于维护的代码。
two-range overloads for some algorithms
在 C++14 标准中,标准库算法获得了一项重要的增强:一些算法添加了所谓的“双范围重载”版本。这意味着,对于某些算法,你现在可以直接将两个独立的范围当做参数传入,而不是之前的单个范围加上目标开始迭代器。这一改进简化了算法的使用,并使得代码更易于阅读和理解。

双范围算法的使用场景
双范围重载在比较两个容器、复制一个容器到另一个容器、以及在两个容器之间进行移动、交换时特别有用。它们允许你直接指定源范围和目标范围,而不必指定起始和结束迭代器。
主要的双范围算法
以下是 C++14 中增加双范围重载的一些主要算法:
std::equal: 用于比较两个范围内的元素是否全部相等。C++14 之前,你需要提供两个范围的起始迭代器和第一个范围的结束迭代器。C++14 允许你直接传入两个范围。std::mismatch: 查找两个范围中第一对不匹配的元素。在 C++14 之前,使用此算法同样需要指定两个范围的起始迭代器和第一个范围的结束迭代器。C++14 使得直接传入两个范围成为可能。std::copy: C++14 为std::copy添加了重载版本,允许两个范围作为参数,简化了从一个容器向另一个容器复制元素的操作。
示例:使用 std::equal 的双范围版本
#include <algorithm>
#include <vector>
#include <iostream>
int main() {
std::vector<int> vec1 = {1, 2, 3, 4, 5};
std::vector<int> vec2 = {1, 2, 3, 4, 5};
// 使用 C++14 中的双范围重载
bool isEqual = std::equal(vec1.begin(), vec1.end(), vec2.begin(), vec2.end());
// 使用 C++14 简化的双范围调用形式
bool isEqualSimplified = std::equal(vec1.begin(), vec1.end(), vec2.begin());
std::cout << "The vectors are " << (isEqual ? "equal." : "not equal.") << std::endl;
std::cout << "Simplified call: The vectors are " << (isEqualSimplified ? "equal." : "not equal.") << std::endl;
return 0;
}
type alias versions of type traits
在 C++14 中,对类型特征(type traits)的改进之一是引入了类型别名版本,这些别名提供了更简洁的语法来访问类型特征的结果。类型特征是模板元编程中的一种工具,它允许在编译时对类型进行查询和操作。在 C++11 中,类型特征通常通过继承自 std::integral_constant 的模板结构体实现,其结果可以通过::value成员访问。而 C++14 通过提供类型别名简化了这个过程,使得获取类型特征的结果更加直接。
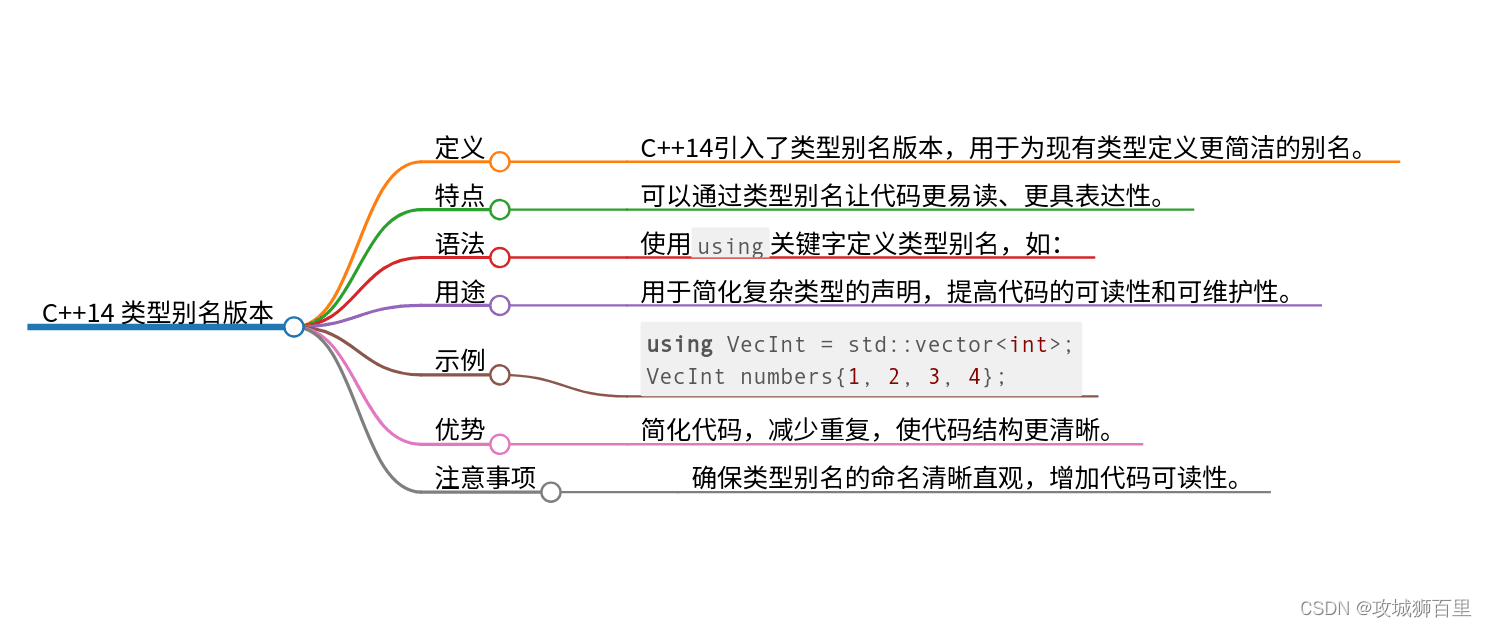
类型别名类型特征的优点
相对于 C++11 风格的类型特征,C++14 引入的类型别名版本提供了以下优势:
- 简洁的语法:不需要通过
::value或::type来访问结果,可以直接使用类型别名得到想要的结果。 - 提高代码的可读性:代码更为简洁,意图更加明显,提高了代码的可读性和易维护性。
示例
比较 C++11 和 C++14 在使用类型特征时的不同。
C++11 风格
#include <type_traits>
int main() {
// 使用C++11风格的类型判断
static_assert(std::is_integral<int>::value, "int is an integral type");
// 获取添加const修饰符后的类型
typedef std::add_const<int>::type MyConstIntType;
}
C++14 风格
#include <type_traits>
int main() {
// 使用C++14风格的类型别名
static_assert(std::is_integral_v<int>, "int is an integral type"); // 注意使用_v后缀
// 使用类型别名获取添加const修饰符后的类型
using MyConstIntType = std::add_const_t<int>; // 注意使用_t后缀
}
主要类型别名特征
C++14 为许多常用的类型特征引入了类型别名,这里列举一些例子:
- 类型属性:例如
std::is_integral_v<T>,直接获得布尔值结果,而不是std::is_integral<T>::value。 - 类型修改器:例如
std::add_const_t<T>,得到修改后的类型,而不是std::add_const<T>::type。 - 类型关系:例如
std::is_same_v<T, U>,直接得到比较结果,而不是std::is_same<T, U>::value。
user-defined literals for basic_string, duration and complex
C++14 中为 std::basic_string、std::chrono::duration 和 std::complex 引入了用户自定义字面量(User-Defined Literals, UDL),这是对 C++11 中用户自定义字面量功能的扩展。用户自定义字面量允许字面值直接定义自己的处理方式,使得代码更加清晰、直观。
std::basic_string 的用户自定义字面量
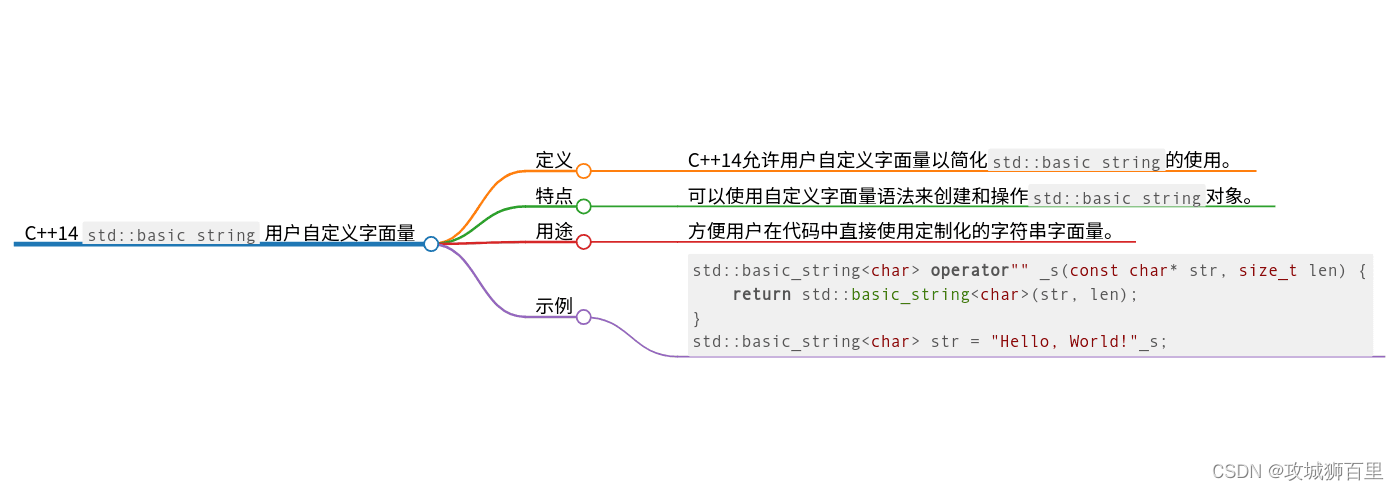
在 C++14 中,通过在字符串字面值后添加 s 后缀,可以直接创建 std::string 实例。这一功能由头文件 <string> 提供。
#include <iostream>
#include <string>
using namespace std::string_literals;
int main() {
// 使用用户自定义字面量创建 std::string
auto myString = "Hello, world!"s;
std::cout << myString << std::endl;
return 0;
}
这样的用户自定义字面量不仅适用于 std::string,也适用于 std::wstring、std::u16string 和 std::u32string,分别通过在字面值后添加 ws、s16 和 s32 后缀来创建。
std::chrono::duration 的用户自定义字面量
C++14 对 std::chrono 库进行了增强,引入了表示时间的用户自定义字面量,使得表示特定时间间隔变得更加直观。这些字面量定义在头文件 <chrono> 中。
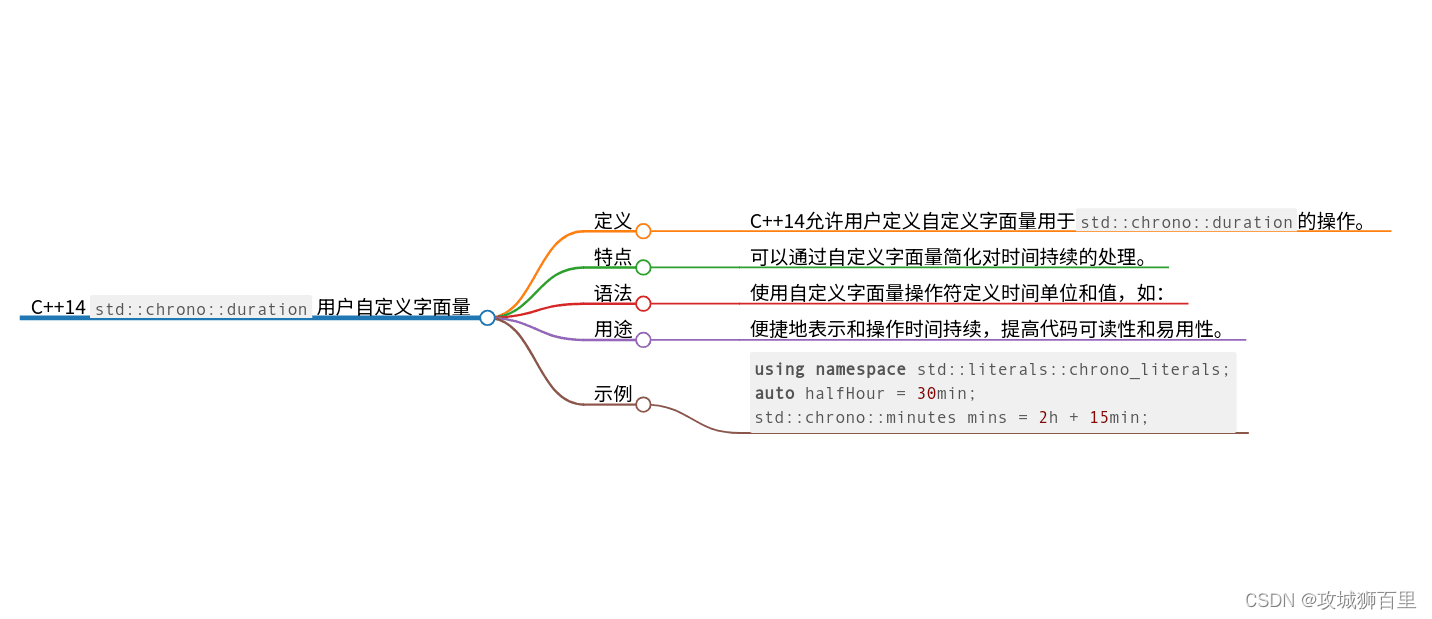
#include <iostream>
#include <chrono>
using namespace std::chrono_literals;
int main() {
auto oneSecond = 1s; // std::chrono::seconds 类型
auto halfAMinute = 30s; // 同样是 std::chrono::seconds 类型
auto oneDay = 24h; // std::chrono::hours 类型
std::cout << "One day has " << oneDay.count() << " hours." << std::endl;
return 0;
}
std::complex 的用户自定义字面量
C++14 也为复数类型 std::complex 引入了用户自定义字面量。通过在整数或浮点字面值后添加 i、if 或 il 后缀,可以创建 std::complex 类型的实例,表示复数。这一功能由头文件 <complex> 提供。
#include <iostream>
#include <complex>
using namespace std::complex_literals;
int main() {
auto myComplex = 3.0 + 4i; // 创建 std::complex<double> 实例
std::cout << "Real part: " << myComplex.real() << ", Imaginary part: " << myComplex.imag() << std::endl;
return 0;
}
【大厂面经、学习笔记、实战项目、大纲路线、讲解视频 领取文档】C++校招实习、社招、面试题
https://docs.qq.com/doc/DR2N4d25LRG1leU9Q
C/C++Linux服务器开发/高级架构师学习资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等)领取君羊739729163
合理利用自己每一分每一秒的时间来学习提升自己,不要再用"没有时间“来掩饰自己思想上的懒惰!趁年轻,使劲拼,给未来的自己一个交代!






![[word] Word如何删除所有的空行? #职场发展#学习方法](https://img-blog.csdnimg.cn/img_convert/794d729053d074244e428cdca4ddbbe2.png)