- 标题:Offline RL Without Off-Policy Evaluation
- 文章链接:Offline RL Without Off-Policy Evaluation
- 代码:davidbrandfonbrener/onestep-rl
- 发表:NIPS 2021
- 领域:离线强化学习(offline/batch RL)—— RL-Based / One-step
- 摘要:先前的大多数 Offline-RL 方法都采用了涉及 Off-policy evaluation 的迭代 Actor-Critic (AC) 方法。本文中我们证明了只需简单地基于 behavior policy 的 on-policy Q Q Q 价值估计做一步 constrained/regularized policy improvement,就会表现得惊人地好。这种 One-step 算法在大部分 D4RL benchmark 上击败了之前的迭代算法。这种 One-step baseline 在实现强大性能的同时,比以前提出的迭代算法简单很多,且对超参数更鲁棒。我们认为,迭代方法之所以性能较差,一方面是因为执行 Off-policy evaluation 时固有的高方差导致价值估计不准,另一方面是因为基于这些低质量价值估计迭代进行 policy improvement 会放大价值估计问题。此外,我们认为 One-step 算法的强大性能是由于它结合了 “环境中的有利结构” 和 “行为策略”
文章目录
- 1. 背景
- 1.1 Offline RL
- 1.2 One-step & Multi-step
- 1.3 Related work
- 2. 本文方法
- 3. 实验
- 4. 讨论
- 4.1 迭代算法的问题
- 4.1.1 问题的表现
- 4.1.2 Distribution shift
- 4.1.3 Iterative error exploitation
- 4.2 迭代方法的优势
1. 背景
1.1 Offline RL
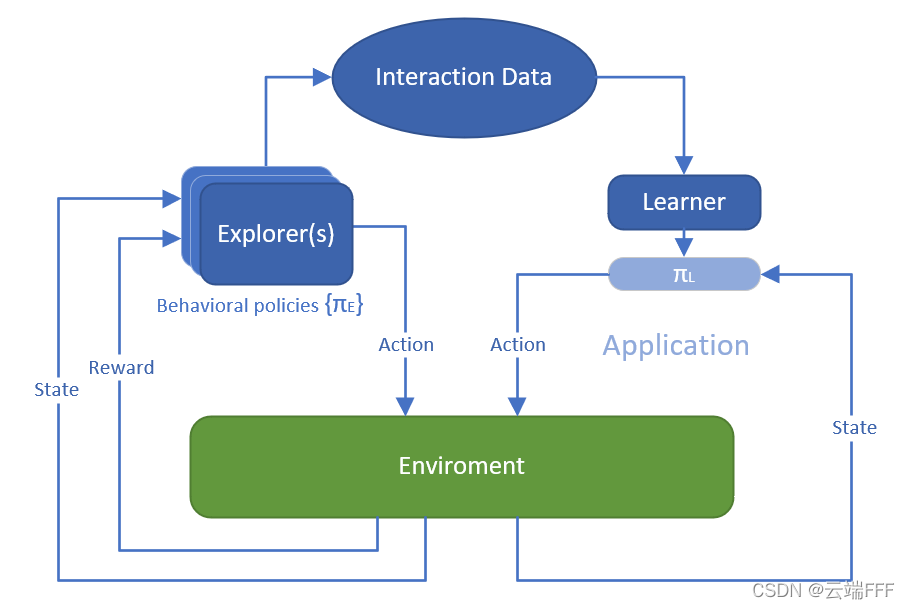
Offline RL是这样一种问题设定:Learner 可以获取由一批 episodes 或 transitions 构成的固定交互数据集,要求 Learner 直接利用它训练得到一个好的策略,而且禁止 Learner 和环境进行任何交互,示意图如下
关于 Offline RL 的详细介绍,请参考 Offline/Batch RL简介- Offline RL 是近年来很火的一个方向,下图显示了 2019 年以来该领域的重要工作
本文出现在 21 年,严格地讲作者其实没有提出新方法,只是发现了 “Offline 设定下,One-step 这种 train schedule,作为广义策略迭代(GPI)的一个特例,可以取得高性能” 这一现象,并深入探究分析了其原因,揭示了 Offline RL 训练的一些规律和特点,有较强的启发性 - 本文给出的 Offline RL Preliminaries 如下
考虑有限 MDP M = { S , A , ρ , P , R , γ } \mathcal{M}=\{\mathcal{S,A},\rho,P,R,\gamma\} M={S,A,ρ,P,R,γ},离线数据集 D N D_N DN 由某 behavior policy β \beta β 收集的 ( s i , a i , r i ) (s_i,a_i,r_i) (si,ai,ri) 组成,期望奖励为 r ( s , a ) = E r ∣ s , a [ r ] r(s,a)=\mathbb{E}_{r|s,a}[r] r(s,a)=Er∣s,a[r],任意策略 π \pi π 的 Q Q Q 价值定义为
Q π ( s , a ) : = E P , π ∣ s 0 = s , a 0 = a [ ∑ t = 0 ∞ γ t r ( s t , a t ) ] Q^{\pi}(s, a):=\mathbb{E}_{P, \pi \mid s_{0}=s, a_{0}=a}\left[\sum_{t=0}^{\infty} \gamma^{t} r\left(s_{t}, a_{t}\right)\right] Qπ(s,a):=EP,π∣s0=s,a0=a[t=0∑∞γtr(st,at)] 目标是最大化学得策略的期望 return
J ( π ) : = E ρ , P , π [ ∑ t = 0 ∞ γ t r ( s t , a t ) ] = E s ∼ ρ a ∼ π ∣ s [ Q π ( s , a ) ] J(\pi):=\underset{\rho, P, \pi}{\mathbb{E}}\left[\sum_{t=0}^{\infty} \gamma^{t} r\left(s_{t}, a_{t}\right)\right]=\underset{\substack{s \sim \rho \\ a \sim \pi \mid s}}{\mathbb{E}}\left[Q^{\pi}(s, a)\right] J(π):=ρ,P,πE[t=0∑∞γtr(st,at)]=s∼ρa∼π∣sE[Qπ(s,a)] 允许访问环境来调优一组少量的(< 10)超参数集
1.2 One-step & Multi-step
-
解释一下
One-step概念,这是针对要做 policy evaluation 价值评估的 RL-based 类 Offline RL 方法而言的。大多数这类方法都是基于 Bellman 等式做 TD-Learning 来评估价值的,整个过程服从广义策略迭代(GPI)框架,即迭代进行 policy evaluation 和 policy improvement 两步,其中policy evaluation阶段:先用上一步迭代的价值估计 Q ^ π k − 2 \hat{Q}^{\pi_{k-2}} Q^πk−2 进行 warm-start,然后用数据集 Q N Q_N QN 估计当前策略 π k − 1 \pi_{k-1} πk−1 的价值 Q ^ π k − 1 \hat{Q}^{\pi_{k-1}} Q^πk−1policy improvement阶段:先用上一步迭代的最新策略 π k − 1 \pi_{k-1} πk−1 进行 warm-start,然后根据估计价值 Q ^ π k − 1 \hat{Q}^{\pi_{k-1}} Q^πk−1、估计的行为策略 β \beta β 和数据集 D N D_N DN 来更新得到策略 π k \pi_k πk
归纳得到如下通用算法模板

根据 GPI 迭代的次数和程度,作者区分了以下几个概念One-step:迭代次数 K = 1 K=1 K=1。首先通过最大似然(比如 MC)得到 behavior policy 的估计 β ^ \hat{\beta} β^,然后做 Policy evaluation 至价值收敛,得到 behavior policy 的价值估计 Q ^ β \hat{Q}^\beta Q^β,最后做一步 Policy improvement 得到 π 1 \pi_1 π1 就结束。注意这个过程完全避免了 off-policy 的 bootstrap 计算Multi-step:迭代次数 K > 1 K>1 K>1,其他都和 One-step 一样,注意每一次 Policy evaluation 都要评估至收敛。由于 Offline 数据集是由 behavior policy β \beta β 收集的,对 π k , k ≥ 2 \pi_k, k\geq 2 πk,k≥2 进行的 Policy evaluation 一定都是 Off-policy 的Iterative actor-critic:这个很类似 Multi-step,区别在于使用更大的超参数 K K K,且不要求每次迭代中的 Policy evaluation 收敛。通常这里 evaluation 和 improvement 两步都使用梯度方法,具体使用的 operators 可以和 Multi-step 中相同
-
下图(来自 R_BVE 论文)展示了 One-step 和其他两种涉及 Off-policy evaluation 的 Iterative 方法在流程上的区别

下图(来自本文)显示了策略空间上的区别,注意学得策略 π i \pi_i πi 被约束在 behavior policy β \beta β 附近的安全范围内

1.3 Related work
Iterative 方法:这类方法涉及到 Q Q Q 函数的多步 iterative & off-policy 评估,涵盖了上文提到的 Multi-step 和 Iterative actor-critic,过去大多数 RL-based 类算法都属此类。为了减轻 Extrapolation Error(见 BCQ 论文解析 2.1 节) 问题对价值估计质量的影响,这些方法提出各种措施来确保学得策略不会偏离 behavior policy 太远,大致可以分成以下三类policy constraints/regularization: 直接优化 policy,使之和 behavior policy 接近。一类做法是对策略网络施加强约束,使其只选择 “能使 ( s , a ) (s,a) (s,a) 具有足够数据集支撑” 的动作 a a a(比如在 BC 的基础上加一个随机扰动),代表方法有 BCQ、SPIBB 等;另一类做法是在策略网络的优化目标中增加 KL、MMD 等正则化项,鼓励学得策略和 behavior policy 接近,代表方法有 BEAR 等modifications of imitation learning:基本都是 BC 的变体,比如先过滤掉低 Q Q Q 价值数据再做模仿学习,或者根据 Q Q Q 价值进行加权模仿。代表方法有 ABM、BAIL、COIL 等Q regularization:这类方法主要从 Q Q Q 函数估计(或者说 critic 的优化目标)入手,通过引入正则化措施,对未知或不确定的 ( s , a ) (s,a) (s,a) 保持悲观态度,从而间接地鼓励学得策略呆在 behavior policy 附近。比如 BRAC、CQL、Fisher-BRC、R_BVE 等
one-step 方法:这类方法只对 behavior policy 做一次 on-policy 的 Q Q Q 价值评估,然后优化一步 policy 结束,不涉及任何 iterative & off-policy 评估操作,不存在 Extrapolation Error 问题。过去的方法有- 在 D4RL 上做连续控制的 YOEO,该方法比较复杂,涉及 distributional Q Q Q 函数及其 ensembles,以及一种新正则化器,本文考虑的设定在能取得相似性能的情况下更简单,且更侧重分析
- 针对 Atari 等离散问题的 R_BVE,这种情况下 policy improvement 可以基于 Q Q Q 估计精确地进行,本文则主要针对连续控制问题;另外 R_BVE 将 Iterative 方法的问题归结于对 Q Q Q 价值的高估,本文则进一步探讨了导致高估的原因
- 其实理解 One-step 的做法之后,熟悉 RL 的读者应该对它的性能有一个大概的估计了,One-step 只对 behavior policy 做了一步提升,其实不会比 behavior policy 好太多,特别是 behavior policy 比较差的时候,One-step 学到的策略
π
1
\pi_1
π1 应该也是挺差的。但人们发现很多时候 One-step 的性能常比 Multi-step 和 Iterative actor-critic 等 Off-policy 迭代方法强很多,这就说明一定有一些因素破坏了多步方法的性能,本文对此现象进行进一步分析,贡献包括
- 提出了一个简单的 one-step baseline,其在很多 Offline RL 问题上优于更复杂的 Iterative 方法
- 检查了 Iterative 方法中 off-policy 价值评估的失效模式
- 描述了何时 one-step 算法可能优于 Iterative 方法
2. 本文方法
- 先回顾一下前面的算法模板
- 对于 policy improvement,作者考察了以下常用算子
Behavior cloning:直接返回 β ^ \hat{\beta} β^ 作为新的策略 π \pi π,其它算子应至少超过这个最简单的 baseline。这个算子和上文的 “modifications of imitation learning” 相关Constrained policy updates:BCQ 和 SPIBB 等算法使用这类算子将 policy 限制在 behavior policy 附近,作者这里用了一个简化版本的 BCQ 算子,称之 easy BCQ,它去掉了扰动网络,改成从 β ^ \hat{\beta} β^ 中采样 M M M 个样本,然后根据 Q ^ β \hat{Q}^{\beta} Q^β 贪心地更新策略,如下
π ^ k M ( a ∣ s ) = 1 [ a = arg max a j { Q ^ π k − 1 ( s , a j ) : a j ∼ π k − 1 ( ⋅ ∣ s ) , 1 ≤ j ≤ M } ] \hat{\pi}_{k}^{M}(a \mid s)=\mathbb{1}\left[a=\arg \max _{a_{j}}\left\{\widehat{Q}^{\pi_{k-1}}\left(s, a_{j}\right): a_{j} \sim \pi_{k-1}(\cdot \mid s), 1 \leq j \leq M\right\}\right] π^kM(a∣s)=1[a=argajmax{Q πk−1(s,aj):aj∼πk−1(⋅∣s),1≤j≤M}] 这个算子和上文的 “policy constraints/regularization” 相关Note:这里我感觉公式有点问题,策略的优化过程没有被约束到 behavior policy 附加,候选动作 a j a_j aj 应当采样自 β ^ \hat{\beta} β^,即改成
π ^ k M ( a ∣ s ) = 1 [ a = arg max a j { Q ^ π k − 1 ( s , a j ) : a j ∼ β ^ , 1 ≤ j ≤ M } ] \hat{\pi}_{k}^{M}(a \mid s)=\mathbb{1}\left[a=\arg \max _{a_{j}}\left\{\widehat{Q}^{\pi_{k-1}}\left(s, a_{j}\right): a_{j} \sim \hat{\beta}, 1 \leq j \leq M\right\}\right] π^kM(a∣s)=1[a=argajmax{Q πk−1(s,aj):aj∼β^,1≤j≤M}]Regularized policy updates:BRAC 等算法使用这类算子向 Offline RL 的最大化 return 目标中引入正则项,来控制策略优化过程中和 behavior policy 的偏离程度。给定任意散度 D D D,如下进行 policy improvement
π ^ k α = arg max π ∑ i E a ∼ π ∣ s [ Q ^ π k − 1 ( s i , a ) ] − α D ( β ^ ( ⋅ ∣ s i ) , π ( ⋅ ∣ s i ) ) \hat{\pi}_{k}^{\alpha}=\arg \max _{\pi} \sum_{i} \underset{a \sim \pi \mid s}{\mathbb{E}}\left[\hat{Q}^{\pi_{k-1}}\left(s_{i}, a\right)\right]-\alpha D\left(\hat{\beta}\left(\cdot \mid s_{i}\right), \pi\left(\cdot \mid s_{i}\right)\right) π^kα=argπmaxi∑a∼π∣sE[Q^πk−1(si,a)]−αD(β^(⋅∣si),π(⋅∣si)) 过去的研究发现 D D D 的不同选择影响不大,实践中通常使用 reverse KL divergence K L ( π ( ⋅ ∣ s i ) ∣ ∣ β ^ ( ⋅ ∣ s i ) ) KL(\pi(·|s_i)||\hat{\beta}(·|s_i)) KL(π(⋅∣si)∣∣β^(⋅∣si))。直观上看,这种正则化迫使 π \pi π 保持在 β \beta β 的支持下,而 2 中的正则化鼓励 π \pi π 覆盖 β \beta β。此算子和上文的 “Q regularization” 相关Variants of imitation learning:这类算子通过对观察到的行为进行过滤或加权来修改模仿学习算法,以进行 policy improvement。作者这里使用优势估计的指数来加权动作
π ^ k τ = arg max π ∑ i exp ( τ ( Q ^ π k − 1 ( s i , a i ) − V ^ ( s i ) ) ) log π ( a i ∣ s i ) \hat{\pi}_{k}^{\tau}=\arg \max _{\pi} \sum_{i} \exp \left(\tau\left(\widehat{Q}^{\pi_{k-1}}\left(s_{i}, a_{i}\right)-\widehat{V}\left(s_{i}\right)\right)\right) \log \pi\left(a_{i} \mid s_{i}\right) π^kτ=argπmaxi∑exp(τ(Q πk−1(si,ai)−V (si)))logπ(ai∣si) 这个算子和上文的 “modifications of imitation learning” 相关
- 对于 policy evaluation,本文作者仅考虑了 DDPG 那种简单的配合 target 网络进行的 td-style learning,没有使用更复杂的 Double Q Learning 或 Q ensembles 等做法,作者认为这些值得未来进一步研究
- 对于 policy improvement,作者考察了以下常用算子
3. 实验
- 作者将 one-step、multi-step、iterative 等算法模板和 Easy BCQ、reverse KL regularization、exponentially weighted imitation 等 improvement operator 进行各种组合,并在 D4RL 数据集上测试性能

这里第一列是 D4RL 里几种 Iterative 算法经过超参数调优后的最佳结果,后面是使用不同 policy improvement 算子的 one-step 方法。可见大多数情况下 one-step 都超过了 Iterative 方法,唯一的例外是在 random 数据集上 - 为了进一步探索 one-step 的性能特点,作者对使用 Rev KL Reg 算子的 one-step 方法进行了更多迭代,性能如下

发现更多的迭代计算往往破坏性能,这启发我们:在尝试一些更复杂的东西之前,将 one-step 算法作为 baseline 运行是值得的,这种简单的方法经常取得更好的性能
4. 讨论
4.1 迭代算法的问题
4.1.1 问题的表现
- 作者通过调整 Rev KL Reg 算子中逆 KL 散度正则化项的系数来调整约束强度,考察不同强度下的训练曲线

可见- Iterative & multi-step 方法的训练过程在约束强度不足时会迅速崩溃,加强正则化可以帮助防止这种崩溃,因为对行为策略的足够强的正则化确保了评估几乎是 on-policy 的
- one-step 方法关于约束强度要鲁棒得多,且其最优约束强度也要低一些
- 当约束足够强时,各种方法的性能差不多,这是因为学得策略被严格约束到 behavior policy 附近,policy evaluation 过程几乎变成和 one-step 一样的 on-policy 了
- 作者将迭代算法崩溃的原因归咎于
Distribution shift和Iterative error exploitation,下面分别说明
4.1.2 Distribution shift
- 这个老生常谈了,任何依赖于 off-policy evaluation 的算法都会遇到 Distribution shift 问题,这会减少有效样本量,并增加估计的方差。过去有一些文章对此进行了理论分析,BCQ 论文中将这个问题称作 Extrapolation Error,为了减轻此问题,大多数 RL-based 方法都要对 policy 施加约束,这也产生了这类方法的一个核心矛盾:为了得到并利用更准确的价值估计,学得策略不能离 behavior policy 太远,而我们又想学得策略性能尽量超越 behavior policy,因此二者又不能离得太近,需要估计并利用那些 OOD 的 ( s , a ) (s,a) (s,a) 对应的价值,这里就产生了一个 trade-off
- 作者检查了 off-policy 评估过程中 Distribution shift 发生的过程。先用 behavior policy 采样一个数据集从头训练
Q
Q
Q 价值,然后从 reply buffer 中采样 1000 个数据检查
Q
Q
Q 估计质量

可见约束越弱,Distribution shift 问题越严重, Q Q Q 估计质量越低;而约束足够强时,off-policy 评估的 Q Q Q 估计质量又和 on-policy 差不多了
4.1.3 Iterative error exploitation
- Iterative & multi-step 方法在 policy evaluation 时会使用上一轮迭代的价值估计进行 warm-start,并使用和 policy improvement 步骤相同的数据,这导致了步骤间的依赖性,并引发 Iterative error exploitation 问题。简而言之,产生该问题的原因是 policy improvement 步骤中
π
i
π_i
πi 倾向于选择 overestimate 的动作(这些动作通常是 OOD 的),然后这种高估会由于重用数据而在 policy evaluation 步骤中通过动态规划传播,R_BVE 论文中对此问题有清晰的解释

另一张相当直观的示意图如下

- 作者也做了一点理论分析,考虑在每个
(
s
,
a
)
(s,a)
(s,a) 处,基于行为策略
β
\beta
β 收集的固定数据集,对当前策略
π
\pi
π 进行policy evaluation 时会有
ε
β
π
(
s
,
a
)
\varepsilon_\beta^\pi(s,a)
εβπ(s,a) 的误差,即价值估计为
Q ^ π ( s , a ) = r ( s , a ) + γ E s ′ ∣ s , a a ′ ∼ π ∣ s ′ [ Q ^ π ( s ′ , a ′ ) ] + ε β π ( s , a ) . \widehat{Q}^{\pi}(s, a)=r(s, a)+\gamma \underset{\substack{s^{\prime}\left|s, a \\ a^{\prime} \sim \pi\right| s^{\prime}}}{\mathbb{E}}\left[\widehat{Q}^{\pi}\left(s^{\prime}, a^{\prime}\right)\right]+\varepsilon_{\beta}^{\pi}(s, a) . Q π(s,a)=r(s,a)+γs′∣s,aa′∼π∣s′E[Q π(s′,a′)]+εβπ(s,a). 这里误差 ε β π ( s , a ) \varepsilon_\beta^\pi(s,a) εβπ(s,a) 吸收了包括函数近似误差和缺乏样本导致的误差等所有误差,它通常随着数据集覆盖程度减小而增大。只要 ε β π ( s , a ) \varepsilon_\beta^\pi(s,a) εβπ(s,a) 在在不同的 π \pi π 之间高度相关就会导致 Iterative error exploitation,为了简单起见,这里假设 ε β π ( s , a ) \varepsilon_\beta^\pi(s,a) εβπ(s,a) 对于使用固定数据集评估的所有策略 π \pi π 都是相同的,并把符号简化为 ε β \varepsilon_\beta εβ,这种情况下估计误差不依赖于被评估的策略 π \pi π,因而可以将其看作辅助 reward,即有
Q ^ π ( s , a ) = Q π ( s , a ) + Q ~ β π ( s , a ) , Q ~ β π ( s , a ) : = E π ∣ s 0 , a 0 = s , a [ ∑ t = 0 ∞ γ t ε β ( s t , a t ) ] \widehat{Q}^{\pi}(s, a)=Q^{\pi}(s, a)+\widetilde{Q}_{\beta}^{\pi}(s, a), \quad \widetilde{Q}_{\beta}^{\pi}(s, a):=\underset{\pi \mid s_{0}, a_{0}=s, a}{\mathbb{E}}\left[\sum_{t=0}^{\infty} \gamma^{t} \varepsilon_{\beta}\left(s_{t}, a_{t}\right)\right] Q π(s,a)=Qπ(s,a)+Q βπ(s,a),Q βπ(s,a):=π∣s0,a0=s,aE[t=0∑∞γtεβ(st,at)] 这样一来,当使用上一步的 Q ^ \widehat{Q} Q 构造 TD target 进行 warm-start 时,误差 ε β \varepsilon_{\beta} εβ 就会自然地传播。下面我们可以概括一下 Iterative error exploitation 的过程:- 给定固定数据集,就会决定一个随着距离数据集支撑范围而增大的 “辅助奖励” ε β \varepsilon_{\beta} εβ
- 在不加约束的情况下,迭代算法会不断增大这个 “辅助奖励”,导致当前学得策略 π i \pi_i πi 越来越远离行为策略 β \beta β,使得 Q ~ β π i ( s , a ) \widetilde{Q}_{\beta}^{\pi_i}(s, a) Q βπi(s,a) 相对 Q π i ( s , a ) Q^{\pi_i}(s, a) Qπi(s,a) 变得更大
- 尽管随着迭代进行, Q π i ( s , a ) Q^{\pi_i}(s, a) Qπi(s,a) 可能给出比 Q β ( s , a ) Q^\beta(s, a) Qβ(s,a) 更好的信号,但它很容易被 Q ~ β π i ( s , a ) \widetilde{Q}_{\beta}^{\pi_i}(s, a) Q βπi(s,a) 淹没
- 相比而言, Q ~ β β ( s , a ) \widetilde{Q}_{\beta}^{\beta}(s, a) Q ββ(s,a) 的幅度更小,因此 one-step 算法对误差更有鲁棒性
- 作者同时给出了例子说明

这个网格环境有一个确定性奖励为 1 的好状态和一系列奖励分布为 N ( − 0.5 , 1 ) N(-0.5,1) N(−0.5,1) 的坏状态,因为所有的误差都来自缺乏样本导致的奖励估计错误,所以 ε β ε_β εβ 确实在所有的 π \pi π 上都是恒定的。直观地说,当有这么多的噪声状态时,很可能其中的一些会被高估,由于重用数据,这些高估持续存在并在状态空间中传播,产生 Iterative error exploitation,实验也表明这时 one-step 确实常优于 Iterative 方法。在 benchmark 中的许多高维控制问题中,这种 “具有许多估计不佳的状态” 的特性很可能也存在,特别是当 Offline 数据分布狭窄时更是如此 - 另外作者发现,如果打破迭代过程中由于 “重用数据” 和 “用上轮
Q
Q
Q 估计进行 warm-start” 而引入的依赖性,Iterative error exploitation 问题可以缓解

这里右图中每次 policy evaluation 都是重新独立采样数据,从头开始进行的,可见价值高估得到有效缓解,不过这不影响 4.2 节中的 Distribution shift 问题
4.2 迭代方法的优势
- 根据上一节的讨论,我们知道 multi-step 和 iterative 方法会传播估计误差
Q
~
β
π
i
(
s
,
a
)
\widetilde{Q}_{\beta}^{\pi_i}(s, a)
Q
βπi(s,a),但不应忽视它们在传播噪声的同时也传播了有用的信号
Q
π
i
(
s
,
a
)
Q^{\pi_i}(s, a)
Qπi(s,a),如果数据集有足够的覆盖范围来降低噪声的大小,信号的传播相对来说就不容易被误差
Q
~
β
π
i
(
s
,
a
)
\widetilde{Q}_{\beta}^{\pi_i}(s, a)
Q
βπi(s,a) 淹没,这可以帮助迭代算法的训练。如下示例

这里仅仅将 behavior policy 改成了更倾向于走向带噪声状态,使得 Offline 数据能充分覆盖这些状态,就能有效降低价值估计的误差,使多步 Iterative 方法能进行可靠的,更积极的规划;另一方面由于降低了 behavior policy 进入右上角良好状态的概率,损害了 one-step 方法的奖励信号传播,这两个变化使得 Iterative 方法的性能显著优于 one-step - 另一个更加直观的实验如下

如图可见这里将来自 random behavior policy 的数据与来自 medium behavior policy 的数据按不同比例进行混合来构造 Offline 数据集,可见只需引入一点 medium 数据,就能破坏 Iterative 方法使之不如 one-step 的性能了