文章目录
- 前言
- 1、知识蒸馏
- 1.1 是什么?
- 1.2 训练流程
- 1.3 问题与挑战
- 2、落地使用
- 2.1 后续问题:
- 总结
前言
有没有什么方法可以在不扩展硬件的情况下利用这些强大但庞大的模型来训练最先进的模型?目前,有三种方法可以压缩神经网络,同时保持预测性能:
权值裁剪、量化、知识蒸馏
知识蒸馏的本质:用一个神经网络训练另一个神经网络
这篇文章将要解决如下几个问题:
1.为什么需要知识蒸馏?
2.如何做知识蒸馏背后原理是什么?
3.实践案例
4.注意事项
1、知识蒸馏
1.1 是什么?
知识蒸馏的本质:用一个神经网络训练另一个神经网络
原始模型网络结构越来越复杂,参数越来越多,对算力的要求越来越大,动辄几亿个参数,成百上千兆的权重文件,这真的好么?再翻译直白点,问题1:我们是否需要一个聪明绝顶的不要不要的大脑,脑容量超大来做简单的任务比如:分类小猫小狗。问题2:我们面临一个非常复杂的问题,比如对数千个类进行图像分类,用ResNet50能达到99%的准确度么?所以我们会建立一个模型集合,平衡各种缺陷,性能很好,但推理时间。。。。额。。。
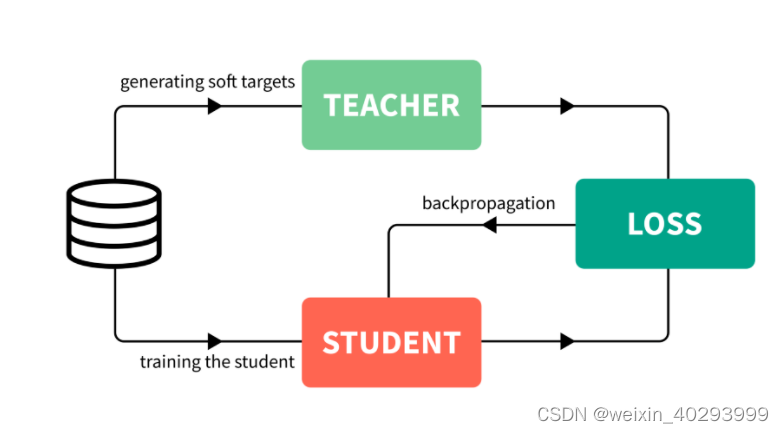
我们使用来自大而笨重的模型的预测来训练一个更小的,所谓的“学生”模型来逼近大模型!–这就是知识蒸馏,用一个聪明而笨重的神经网络训练一个小简单,但还可以的网络。放在生产上使用!
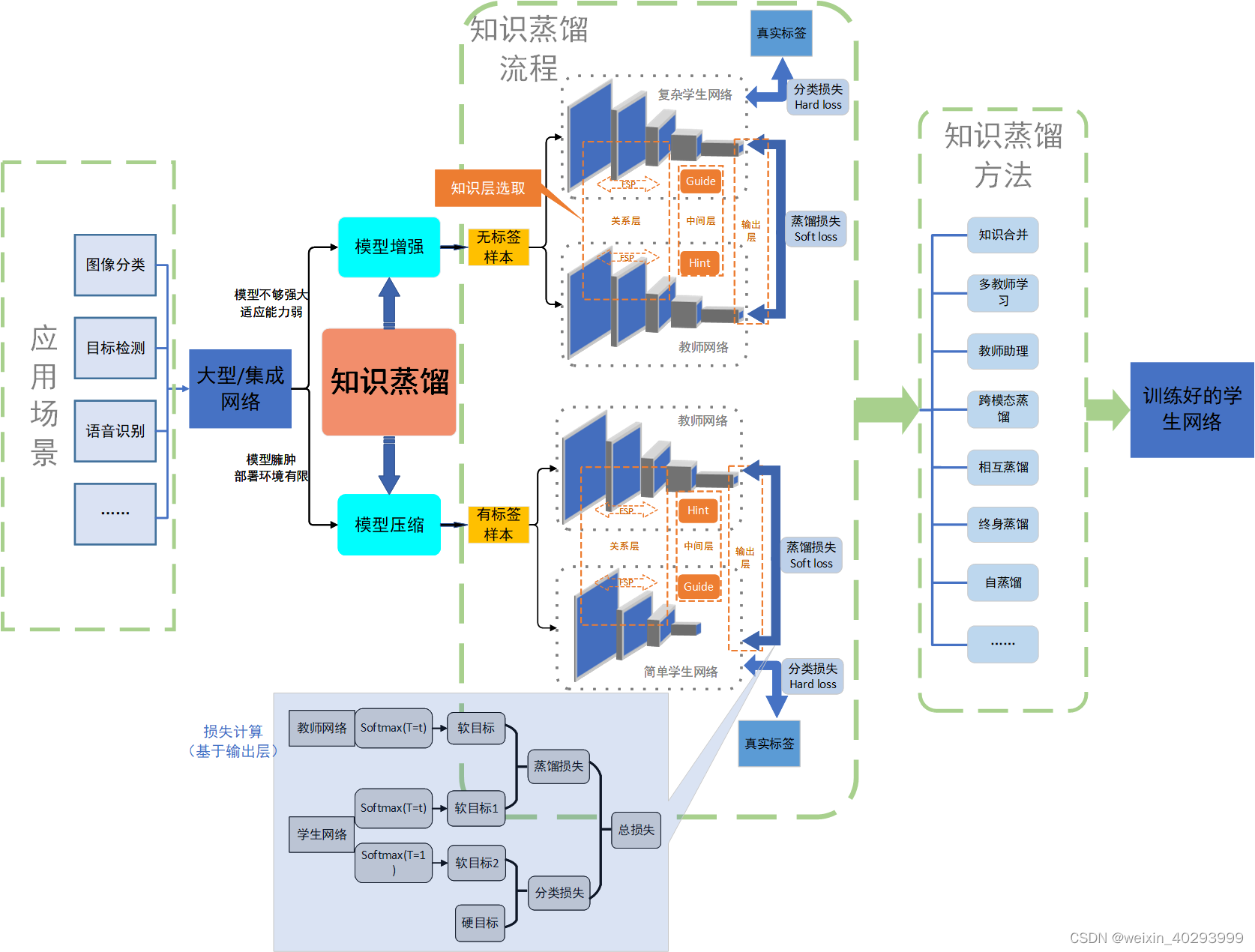
1.2 训练流程
- 训练一个能够性能很好泛化也很好的大模型。这被称为教师模型。
- 利用你所拥有的所有数据,计算出教师模型的预测。带有这些预测的全部数据集被称为知识,预测本身通常被称为soft targets。这是知识蒸馏步骤。
- 利用先前获得的知识来训练较小的网络,称为学生模型。
一句话总结:原始数据训练一个大模型(teacher),然后原始数据和大模型指导训练一个小模型(student),用将小模型放到生产上使用。
大模型的指导是指,将训练数据按batch送入teacher模型,得到batch的预测,这个预测是 猫的概率0.7,狗0.007 飞机 0.000001… 而ground true是 猫 1 其他都是0, 在这里体现了teacher对student的指导。
ground true叫hard target,teacher输出的叫 soft target teacher 要合并这两个target计算total loss
softtarget的部分体现的teacher的指导, 这张图虽然是猫,但和狗有一点点相似 比如四条腿,有毛。。。但和飞机就差的海的去了。正是这点指导能比直接用小网络+hard target的效果好
知识就是soft target, 蒸馏就是网络模型小了,用小脑子,装teacher学到的结论精华(soft target)。
我觉得这是所谓知识蒸馏的本质,论文里,会讲这一部分用新词汇表征,初看会云里雾里。
顺便提一下,soft target的软的程度,取决于超参数T,‘温度’越高,类与类之间会更加接近。
如果T = 1,就是原来的softmax函数。出于我们的目的,T被设置为大于1,因此叫做蒸馏。 T=1 就是原来的softmax函数
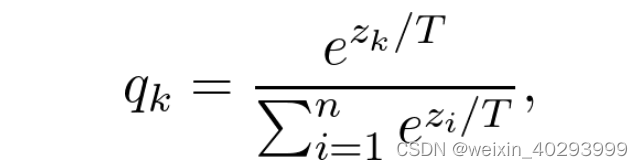
1.3 问题与挑战
1 为什么不直接训练小模型?
原始数据我有,直接训练小模型(student)得了呗,这个时候再叫student已经不合适了,没大模型(teacher)了。
可以这样做,但不一定有效!实验结果表明,参数越多,泛化效果越好,收敛速度越快。ref:On the Optimization of Deep Networks: Implicit Acceleration by Overparameterization
还有1.2 对hard target, soft target 的理解,就是答案!
首先,教师模型的知识可以教学生模型如何通过训练数据集之外的可用预测进行泛化。回想一下,我们使用教师模型对所有可用数据的预测来训练学生模型,而不是原始的训练数据集。
其次,soft targets提供了比类标签更有用的信息:它表明两个类是否彼此相似。例如,如果任务是分类狗的品种,像“柴犬和秋田犬非常相似”这样的信息对于模型泛化是非常有价值的。

2 这不就是迁移学习么?
真不是,迁移学习相当于后端的二次开发,直接用了学到的权重。
知识的一个更抽象的观点是,它是一个从输入向量到输出向量的学习好的映射,它将知识从任何特定的实例化中解放出来。知识蒸馏是我指导原始输入和大模型的输出,也知道大模型的表达式,但大模型的表达式太复杂,我想用一个小模型的表达式来达到大模型的效果(或者略低一点)。
- 你一直说用小模型,如何设计啊?
这个,…根据经验吧,一层不行2层,4层,8层。。。。
BN层,Relu或者其替代函数看着加,那个效果好用哪个
2、落地使用
git:https://github.com/justinge/knowledge-distillation-main
还没传上去,先这样
翻译了googLeNet模型 22层,实现的studentmodel很小5层(卷积+池化+卷积+池化+全连接)
googlenet的网络结构看这里:https://blog.csdn.net/qq_61897309/article/details/127677544
贴一下代码:
model.py
import torch.nn as nn
import torch
import torch.nn.functional as F
class Studentmodel(nn.Module):
def __init__(self):
super(Studentmodel, self).__init__()
# 原图像为nX224X224X3
self.conv1=nn.Conv2d(3,32,kernel_size=(7,7),stride=(2,2),padding=3)
#nx112X112X32
self.pool1=nn.MaxPool2d(kernel_size=(3,3),stride=(2,2))
#nx56x56x32
self.conv2 = nn.Conv2d(32, 32, kernel_size=(3, 3), stride=(2, 2), padding=1)
# nx28x28x32
self.pool2 = nn.MaxPool2d(kernel_size=(3, 3), stride=(2, 2))
# nx 14x14x32
# self.conv3 = nn.Conv2d(32,64, kernel_size=(3, 3), stride=(2, 2), padding=1)
# #nx 7X7X64
###先reshape->nx(7*7*64)
self.fc=nn.Linear(5408,5)
#nx5
self.dropout = nn.Dropout(0.4)
def forward(self,x):
x=self.conv1(x)
x=F.relu(x)
x=self.pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.pool2(x)
# x = self.conv3(x)
x = torch.flatten(x, 1)
x = self.dropout(x)
x = self.fc(x)
return x
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, init_weights=False):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
if self.training and self.aux_logits: # eval model lose this layer
return x, aux2, aux1
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # 保证输出大小等于输入大小
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = self.averagePool(x)
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
x = F.dropout(x, 0.5, training=self.training)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# N x 1024
x = self.fc2(x)
# N x num_classes
return x
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
train.py
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdm
from model import GoogLeNet,Studentmodel
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
#将图像随机裁剪为224X224大小
#以0.5的概率水平翻转
#将RGB三个通道值标准化为[-1,1]区间
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),###图像大小为224X224
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "..")) #
image_path = os.path.join(data_root, "data_set", "flower_data")
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
#获取类别名,并以daisy:0, dandelion:1, roses:2, sunflower:3, tulips:4的形式写入到json文件中
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
#每次训练32个样本
batch_size = 32
# nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])
# print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
)#每个epoch开始时,对数据重新排序
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
def train_teacher(loss_logits_wt=1,loss_aux_logits2_wt=0.3,loss_aux_logits1_wt=0.3):
#需要两个辅助分类器 初始化权重
model = GoogLeNet(num_classes=5, aux_logits=True, init_weights=True)
model.to(device)
#损失函数CrossEntropyLoss
#优化器Adm,学习率0.0003
#30个epoch
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.0003)
epochs = 30
best_acc = 0.0
save_path = './googleNet.pth'##保存模型参数位置
train_steps = len(train_loader)
for epoch in range(epochs):
#训练 self.training=True
model.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
logits, aux_logits2, aux_logits1 = model(images.to(device))
loss0 = loss_function(logits, labels.to(device))
loss1 = loss_function(aux_logits1, labels.to(device))
loss2 = loss_function(aux_logits2, labels.to(device))
loss = loss0*loss_logits_wt + loss1 *loss_aux_logits1_wt + loss2 * loss_aux_logits2_wt#总loss
loss.backward()
optimizer.step()
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,loss.item())
#测试 self.training=False 不再使用辅助分类器,只有一个输出 loss)
model.eval()
acc = 0.0
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = model(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num#计算正确率
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(model.state_dict(), save_path)
print('Teacher model training completed')
def train_dk(temp=5,hard_loss_wt=0.55,soft_loss_wt=0.45,loss_logits_wt=1,loss_aux_logits2_wt=0.3,loss_aux_logits1_wt=0.3):
teacher_model = GoogLeNet(num_classes=5, aux_logits=True).to(device)
weights_path = "./googleNet.pth" ##训练好的模型参数保存位置
####导入训练好的教师模型
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
teacher_model.load_state_dict(torch.load(weights_path, map_location=device),
strict=False)
student_model=Studentmodel().to(device)
#hardloss采用交叉熵CrossEntropyLoss,softloss采用相对熵KL散度KLDivLoss,二者作用原理相似
#优化器Adm,学习率0.0001
#30个epoch
student_loss_fn = nn.CrossEntropyLoss()
divergence_loss_fn = nn.KLDivLoss(reduction="batchmean")
optimizer = torch.optim.Adam(student_model.parameters(), lr=1e-4)
teacher_model.train()#teacher_model不需要训练,由于要用到辅助分类器输出结果,此句仅为了将self.training置为true
student_model.train()
epochs = 30
best_acc = 0.0
save_path = './googleDKNet.pth'##保存模型参数位置
train_steps = len(train_loader)
for epoch in range(epochs):
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
images=images.to(device)
labels=labels.to(device)
with torch.no_grad():
teacher_preds,teacher_preds_aux2,teacher_preds_aux1 = teacher_model(images)
student_preds=student_model(images)
student_loss=student_loss_fn(student_preds,labels)
##蒸馏温度=5 学生网络与教师网络的loss等于与教师网络三个输出(两个辅助分类器)的loss加权和
dist_loss0 = divergence_loss_fn(F.softmax(student_preds / temp, dim=1),
F.softmax(teacher_preds / temp, dim=1))
dist_loss1 = divergence_loss_fn(F.softmax(student_preds / temp, dim=1),
F.softmax(teacher_preds_aux1 / temp, dim=1))
dist_loss2 = divergence_loss_fn(F.softmax(student_preds / temp, dim=1),
F.softmax(teacher_preds_aux2 / temp, dim=1))
distillation_loss=loss_logits_wt*dist_loss0+loss_aux_logits1_wt*dist_loss1+loss_aux_logits2_wt*dist_loss2
total_loss=student_loss*hard_loss_wt+distillation_loss*soft_loss_wt
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
running_loss += total_loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
total_loss)
student_model.eval()
acc_num = 0.0
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = student_model(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc_num += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc_num / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(student_model.state_dict(), save_path)
print('DK model training completed')
def train_student():
student_model = Studentmodel().to(device)
#损失函数CrossEntropyLoss
#优化器Adm,学习率0.0001
#30个epoch
student_loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(student_model.parameters(), lr=1e-4)
student_model.train()
epochs = 30
best_acc = 0.0
save_path = './studentNet.pth' ##保存模型参数位置
train_steps = len(train_loader)
for epoch in range(epochs):
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
images = images.to(device)
labels = labels.to(device)
student_preds = student_model(images)
loss = student_loss_fn(student_preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
student_model.eval()
acc = 0.0
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = student_model(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(student_model.state_dict(), save_path)
print('Student model training completed')
if __name__ == '__main__':
train_teacher()
train_dk()
train_student()
2.1 后续问题:
在分类上好用,那么在比较复杂的backbone上是否还好用,比如darknet53之类的,这个是需要继续深挖的问题,如果好用,那么网络设置有啥讲究?
总结
在深度学习的背景下,为了达到更好的预测效果,高性能的神经网络往往层数纵深,参数密集,难以部署在资源受限的设备上。知识蒸馏作为一种模型压缩方法,可以将复杂网络(称为教师网络)学到的知识传递给小网络(称为学生网络),使学生网络达到较好的预测效果,同时学生网络所占计算参数数量及内存大小远小于教师网络,从而使其移植到低内存低算力的终端上成为了可能。本项目介绍了知识蒸馏的理论知识和作用机制,并基于flower数据集利用知识蒸馏方法将GoogLeNet(教师网络,大小为50MB) 进行压缩,“知识” 选择教师网络的输出层,实验结果表明,蒸馏后的学生网络预测准确性要比单独训练的小模型高,且其模型大小不足100KB,模型压缩效果显著。