Kafka_深入探秘者(5):kafka 分区
一、kafka 副本机制
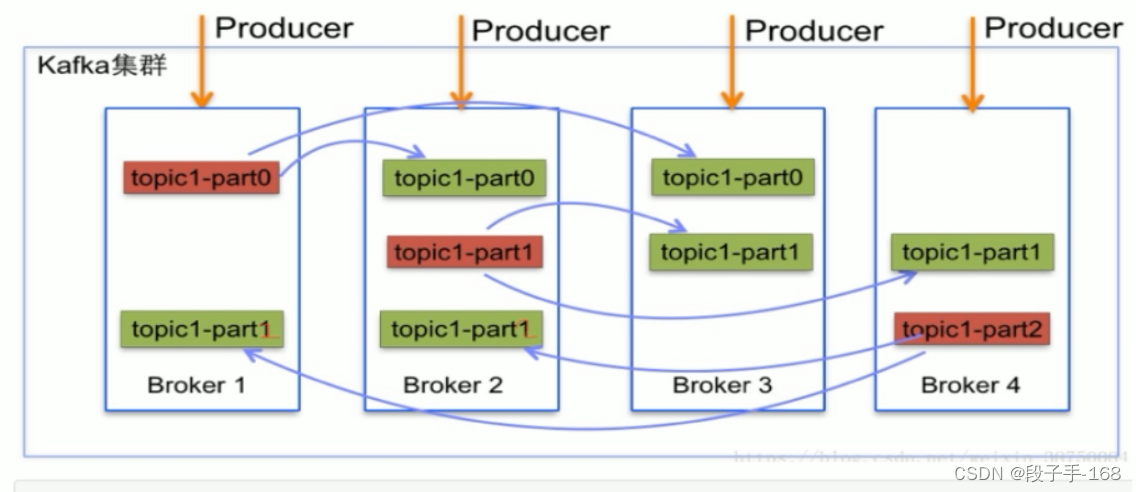
1、Kafka 可以将主题划分为多个分区(Partition),会根据分区规则选择把消息存储到哪个分区中,只要如果分区规则设置的合理,那么所有的消息将会被均匀的分布到不同的分区中,这样就实现了负载均衡和水平扩展。另外,多个订阅者可以从一个或者多个分区中同时消费数据,以支撑海量数据处理能力。
2、由于 kafka 消息是以追加到分区中的,多个分区顺序写磁盘的总效率要比随机写内存还要高(引用 ApacheKafka-A High Throughput Distributed Messaging System 的观点),是 Kafka 高吞吐率的重要保证之一。
3、kafka 副本机制
-
1)在由于 Producer 和 Consumer 都只会与 Leader 角色的分区副本相连,所以 kafka 需要以集群的组织形式提供主题下的消息高可用。kafka 支持主备复制,所以消息具备高可用和持久性。
-
2)kafka 一个分区可以有多个副本,这些副本保存在不同的 broker 上。每个分区的副本中都会有一个作为 Leader。当一个 broker 失败时,Leader 在这台 broker 上的分区都会变得不可用,kafka 会自动移除 Leader,再其他副本中选一个作为新的 Leader。
-
3)在通常情况下,增加分区可以提供 kafka 集群的吞吐量。然而,也应该意识到集群的总分区数或是单台服务器上的分区数过多,会增加不可用及延迟的风险。
二、kafka Leader 选举
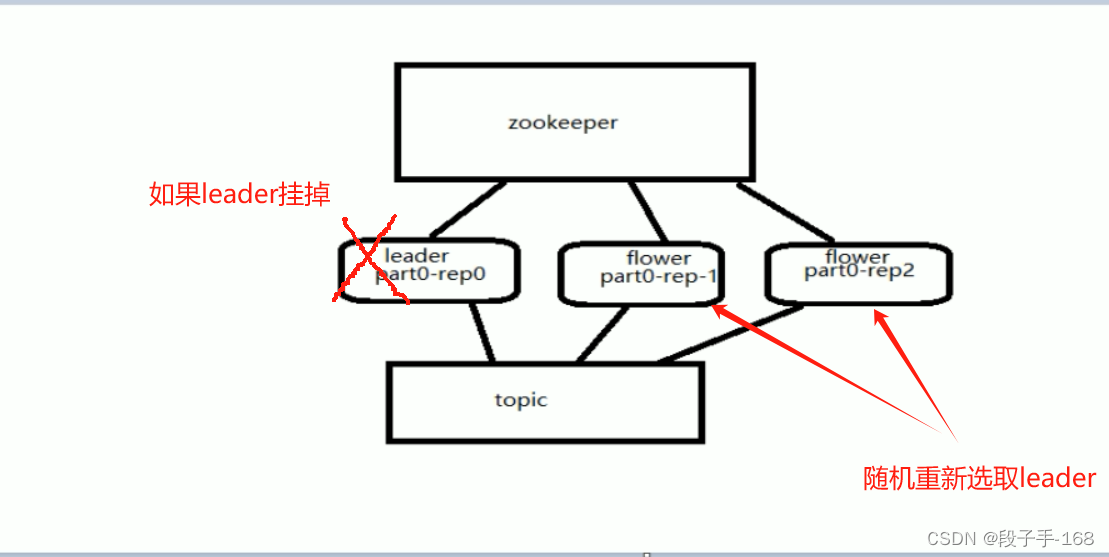
1、Kafka 可以预见的是,如果某个分区的 Leader 挂了,那么其它跟随者将会进行选举产生一个新的 leader,之后所有的读写就会转移到这个新的 Leader 上,在 kafka 中,其不是采用常见的多数选举的方式进行副本的 Leader 选举,而是会在 Zookeeper 上针对每个 Topic 维护一个称为 ISR(in-syncreplica,已同步的副本)的集合,显然还有一些副本没有来得及同步。只有这个 ISR 列表里面的才有资格成为 leader (先使用ISR里面的第一个,如果不行依次类推,因为 ISR 里面的是同步副本,消息是最完整且各个节点都是一样的)。
2、kafka 通过 ISR,kafka 需要的冗余度较低,可以容忍的失败数比较高。假设某个 topic 有 f+1 个副本,kafka 可以容忍 f 个不可用,当然,如果全部 ISR 里面的副本都不可用,也可以选择其他可用的副本,只是存在数据的不一致。
3、Leader 选举随机示例图:
三、kafka 分区重新分配 001
1、部署好的 Kafka 集群里面添加机器是最正常不过的需求,而且添加起来非常地方便,从已经部署好的 Kafka 节点中复制相应的配置文件,然后把里面的 brokerid 修改成全局唯一的,最后启动这个节点即可将它加入到现有 Kafka 集群中。
2、新添加的 Kafka 节点并不会自动地分配数据,所以无法分担集群的负载,除非我们新建一个 topic。 手动将部分分区移到新添加的 Kafka 节点上,Kafka 内部提供了相关的工具来重新分布某个 topic 的分区。
3、kafka 集群搭建:
3.1 拷贝三份 kafka_2.12-2.8.0 分别命名为:kafka-01, kafka-02, kafka-03
# 切换目录
cd /usr/local/kafka/
# 拷贝三份 kafka_2.12-2.8.0 分别命名为:kafka-01, kafka-02, kafka-03
cp -rf kafka_2.12-2.8.0 ./kafka-01
cp -rf kafka_2.12-2.8.0 ./kafka-02
cp -rf kafka_2.12-2.8.0 ./kafka-03
3.2 修改 kafka-01 的配置文件 kafka/kafka-01/config/server.properties
broker.id=0, log.dirs=/usr/local/kafka/kafka-01/logs, port=9092
# 切换目录
cd /usr/local/kafka/
# 修改 kafka-01 的配置文件 kafka-01/config/server.properties
vim kafka-01/config/server.properties
# 修改以下几个配置:
broker.id=0
log.dirs=/usr/local/kafka/kafka-01/logs
# listeners=PLAINTEXT://localhost:9092
host.name=localhost
port=9092
3.3 修改 kafka-02 的配置文件 kafka/kafka-02/config/server.properties
broker.id=1, log.dirs=/usr/local/kafka/kafka-02/logs, port=9093
# 切换目录
cd /usr/local/kafka/
# 修改 kafka-02 的配置文件 kafka-02/config/server.properties
vim kafka-02/config/server.properties
# 修改以下几个配置:
broker.id=1
log.dirs=/usr/local/kafka/kafka-02/logs
# listeners=PLAINTEXT://localhost:9093
host.name=localhost
port=9093
3.4 修改 kafka-03 的配置文件 kafka/kafka-03/config/server.properties
broker.id=2, log.dirs=/usr/local/kafka/kafka-03/logs, port=9094
# 切换目录
cd /usr/local/kafka/
# 修改 kafka-03 的配置文件 kafka-03/config/server.properties
vim kafka-03/config/server.properties
# 修改以下几个配置:
broker.id=2
log.dirs=/usr/local/kafka/kafka-03/logs
# listeners=PLAINTEXT://localhost:9094
host.name=localhost
port=9094
3.5 删除 kafka 三个节点 kafka-01, kafka-02, kafka-03 以前的日志文件。
删除命令:rm -rf logs/*
# 切换目录
cd /usr/local/kafka/
# 删除 节点1:kafka-01 以前的日志文件
rm -rf kafka-01/logs/*
# 删除 节点2:kafka-02 以前的日志文件
rm -rf kafka-02/logs/*
# 删除 节点3:kafka-03 以前的日志文件
rm -rf kafka-03/logs/*
3.6 启动 kafka 三个节点 kafka-01, kafka-02, kafka-03
启动命令:bin/kafka-server-start.sh config/server.properties
# 切换目录
cd /usr/local/kafka/
# 启动 节点1:kafka-01
kafka-01/bin/kafka-server-start.sh config/server.properties
# 启动 节点2:kafka-02
kafka-02/bin/kafka-server-start.sh config/server.properties
# 启动 节点3:kafka-03
kafka-03/bin/kafka-server-start.sh config/server.properties
四、kafka 分区重新分配 002
1、Kafka 创建一个有3个节点的集群(3个分区,3个副本)
创建命令:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --topic heima-par --partitions 3 --replication-factor 3
# 切换目录
cd /usr/local/kafka/
# 创建集群
kafka-01/bin/kafka-topics.sh --create --zookeeper localhost:2181 --topic heima-par --partitions 3 --replication-factor 3
# 查看新创建的主题 heima-par 的详细信息
kafka-01/bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic heima-par
2、为新创建的主题 heima-par 添加一个分区
添加分区命令:
bin/kafka-topics.sh --alter --zookeeper localhost:2181 --topic heima-par --partitions 4
# 切换目录
cd /usr/local/kafka/
# 创建集群
kafka-01/bin/kafka-topics.sh --alter --zookeeper localhost:2181 --topic heima-par --partitions 4
# 查看新创建的主题 heima-par 的详细信息
kafka-01/bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic heima-par
3、添加一个 brokder 节点
添加 brokder 节点 命令:
cp -rf kafka-01 ./kafka-04
# 切换目录
cd /usr/local/kafka/
# 添加 brokder 节点
cp -rf kafka-01 ./kafka-04
4、修改 节点 kafka-04 的配置文件 kafka/kafka-04/config/server.properties
broker.id=3, log.dirs=/usr/local/kafka/kafka-04/logs, port=9095
# 切换目录
cd /usr/local/kafka/
# 修改 kafka-04 的配置文件 kafka-04/config/server.properties
vim kafka-04/config/server.properties
# 修改以下几个配置:
broker.id=3
log.dirs=/usr/local/kafka/kafka-04/logs
# listeners=PLAINTEXT://localhost:9095
host.name=localhost
port=9095
5、删除 kafka 4个节点 kafka-01, kafka-02, kafka-03, kafka-04 以前的日志文件。
删除命令:rm -rf logs/*
# 切换目录
cd /usr/local/kafka/
# 删除 节点1:kafka-01 以前的日志文件
rm -rf kafka-01/logs/*
# 删除 节点2:kafka-02 以前的日志文件
rm -rf kafka-02/logs/*
# 删除 节点3:kafka-03 以前的日志文件
rm -rf kafka-03/logs/*
# 删除 节点4:kafka-04 以前的日志文件
rm -rf kafka-04/logs/*
6 启动 kafka 4个节点 kafka-01, kafka-02, kafka-03, kafka-04
启动命令:bin/kafka-server-start.sh config/server.properties
# 切换目录
cd /usr/local/kafka/
# 启动 节点1:kafka-01
kafka-01/bin/kafka-server-start.sh config/server.properties
# 启动 节点2:kafka-02
kafka-02/bin/kafka-server-start.sh config/server.properties
# 启动 节点3:kafka-03
kafka-03/bin/kafka-server-start.sh config/server.properties
# 启动 节点4:kafka-04
kafka-04/bin/kafka-server-start.sh config/server.properties
7、再次查看新创建的主题 heima-par 的详细信息,发现输出信息中新添加的节点4并没有分配之前主题的分区。
# 切换目录
cd /usr/local/kafka/
# 查看新创建的主题 heima-par 的详细信息
kafka-01/bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic heima-par
五、kafka 分区重新分配 003
将原先分布在 broker 1-3 节点上的分区重新分布到 broker 1-4 节点上,需要借助 kafka-reassign-partitions.sh 工具生成 reassign plan ,
1、定义一个 reassign.json 文件,说明哪些 topic 需要重新分区,文件内容如下:
# 切换目录
cd /usr/local/kafka/
# 定义一个 reassign.json 文件
vim kafka-01/reassign.json
# 文件内容如下
{"topics":[{"topic":"heima-par")],
"version":1
}
2、使用 kafka-reassign-partitions.sh 工具生成 reassign plan
命令:
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --topics-to-move-json-file reassign.json --broker-list “0,1,2,3” --generate
命令参数说明:
-generate :表示指定类型参数。
–topics-to-move-json-file : 指定分区重份配对应的主题清单路径。
# 切换目录
cd /usr/local/kafka/
# 使用 kafka-reassign-partitions.sh 工具生成 reassign plan
kafka-01/bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --topics-to-move-json-file reassign.json --broker-list "0,1,2,3" --generate
# 执行完命令会生成2个字符串。
3、重新分配 JSON 文件,创建 result.json 文件,保存 JSON 内容。
注意:第二步命令输出两个 json 字符串,第一个 JSON 内容为当前的分区副本分配情况,第二个为重新分配的候选方案,注意这里只是生成一份可行性的方案,并没有真正执行重分配的动作。
我们将第二个 JSON 内容保存到名为 result.json 文件里面(文件名不重要,文件格式也不一定要以json为结尾,只要保证内容是 json 即可),然后执行这些 reassign plan:
4、执行分配策略,并查看执行进度。
命令:
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file result.json --execute
命令参数说明:
–execute :执行命令。
–reassignment-json-file : 指定分区重分配 json 文件。
# 切换目录
cd /usr/local/kafka/
# 使用 kafka-reassign-partitions.sh 工具生成 reassign plan
kafka-01/bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file result.json --execute
# 查看执行进度
kafka-01/bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file result.json --verify
# 查看新创建的主题 heima-par 的详细信息
kafka-01/bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic heima-par
六、kafka 分区分配策略
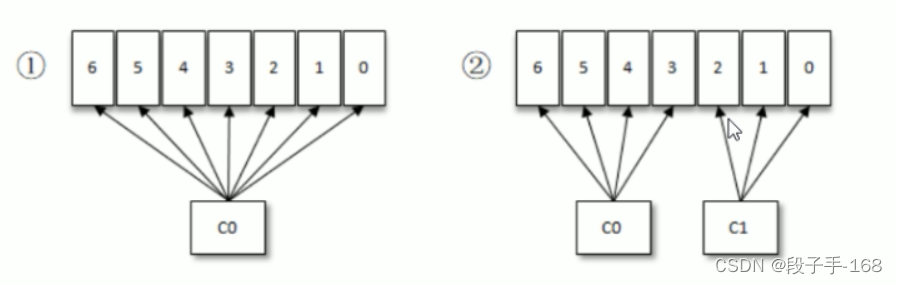
1、### 1、按照 Kafka 默认的消费逻辑设定,一个分区只能被同一个消费组 (ConsumerGroup) 内的一个消费者消费。假设目前某消费组内只有一个消费者 C0,订阅了一个 topic,这个 topic 包含 7 个分区,也就是说这个消费者 C0 订阅了 7 个分区,参考下图1
2、此时消费组内又加入了一个新的消费者 C1,按照既定的逻辑需要将原来消费者 C0 的部分分区分配给消费者 C1 消费,情形如图(2),消费者 C0 和 C1 各自负责消费所分配到的分区,相互之间并无实质性的干扰。
3、RangeAssignor 策略的原理
RangeAssignor 策略的原理是按照消费者总数和分区总数进行整除运算来获得一个跨度,然后将分区按照跨度进行平均分配,以保证分区尽可能均匀地分配给所有的消费者。对于每一个 topic,RangeAssignor 策略会将消费组内所有订阅这个 topic 的消费者按照名称的字典序排序,然后为每个消费者划分固定的分区范围,如果不够平均分配,那么字典序靠前的消费者会被多分配一个分区。
4、RoundRobinAssignor 策略的原理
RoundRobinAssignor 策略的原理是将消费组内所有消费者以及消费者所订阅的所有 topic 的 partition 按照字典序排序,然后通过轮询方式逐个将分区以此分配给每个消费者。RoundRobinAssignor 策略对应的 partition.assignment.strategy 参数值为: org.apache.kafka.clients.consumer.RoundRobinAssignor。
上一节关联链接请点击
# Kafka_深入探秘者(4):kafka 主题 topic