本地知识库+语言大模型=知域问答
本项目实质为本地知识库构建及应用,内容包含:
- 本地知识库构建及应用相关知识的介绍
- 离线式本地知识库构建及应用
- 在线式本地知识库构建及应用
本地知识库构建及应用相关知识的介绍
本地知识库
本地知识库通常是指存储在本地计算机或服务器上的数据库或数据集,用于提供本地环境下的知识和信息。
本地知识库构建思路
- 收集知识,如txt文件等;
- 对文本进行切分;
- 将文本转化为向量;
- 将向量保存到本地向量数据库或者在线向量数据库;
- 与LLM联系构建问答应用。
其实算法的整体思路也是这些步骤,明显只靠LLM是不够的,我们还需要一些其他功能将LLM应用起来,langchain就提供了一整套框架帮我们更好的应用LLM。
LangChain介绍
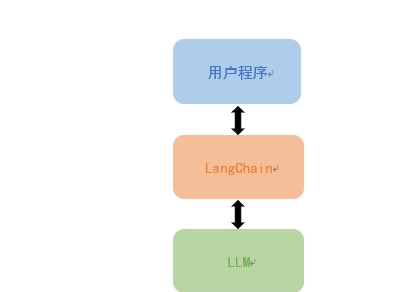
langchain是一个开发基于语言模型应用程序开发框架,链接面向用户程序和LLM之间的中间层。利用LangChain可以轻松管理和语言模型的交互,将多个组件链接在一起,比如各种LLM模型,提示模板,索引,代理等等。
langchain-ChatGLM
langchain-ChatGLM项目就是参考了Langchain的思路,实现了本地知识库构建及应用,我们一起看下langchain-ChatGLM搭建本地知识库的流程。
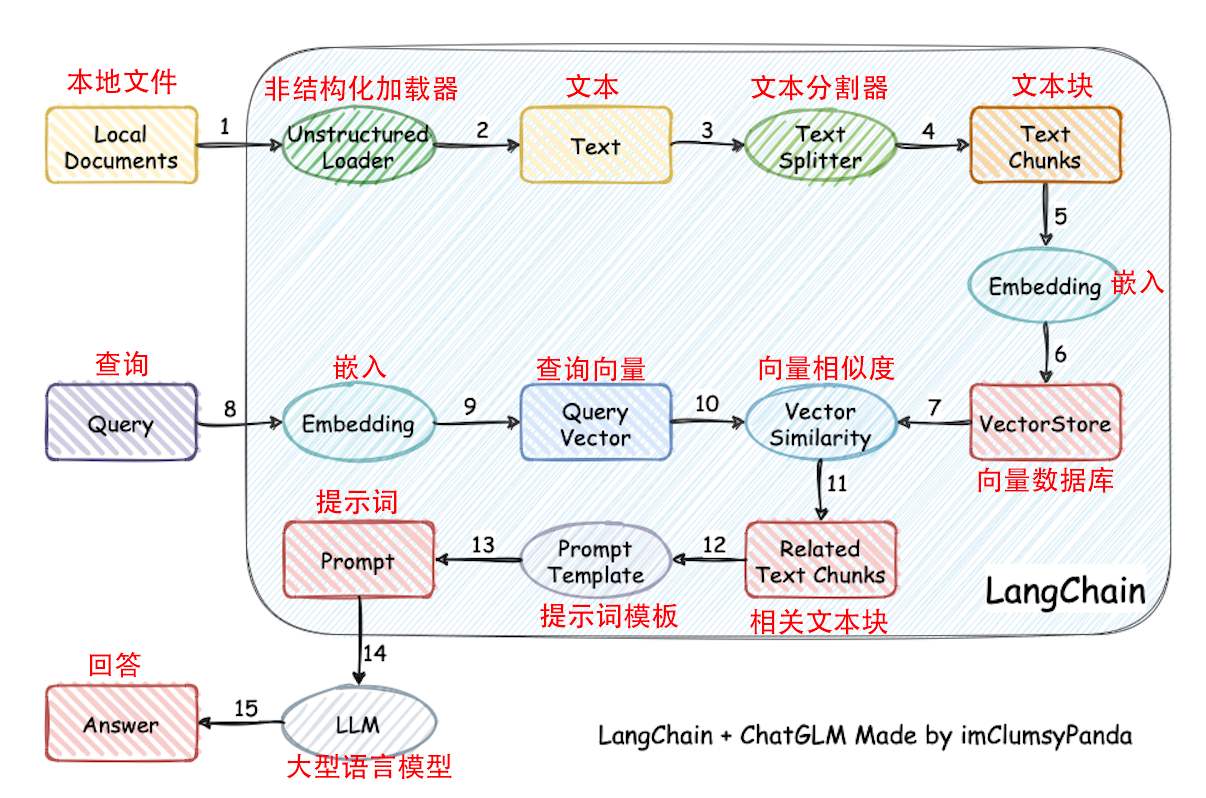
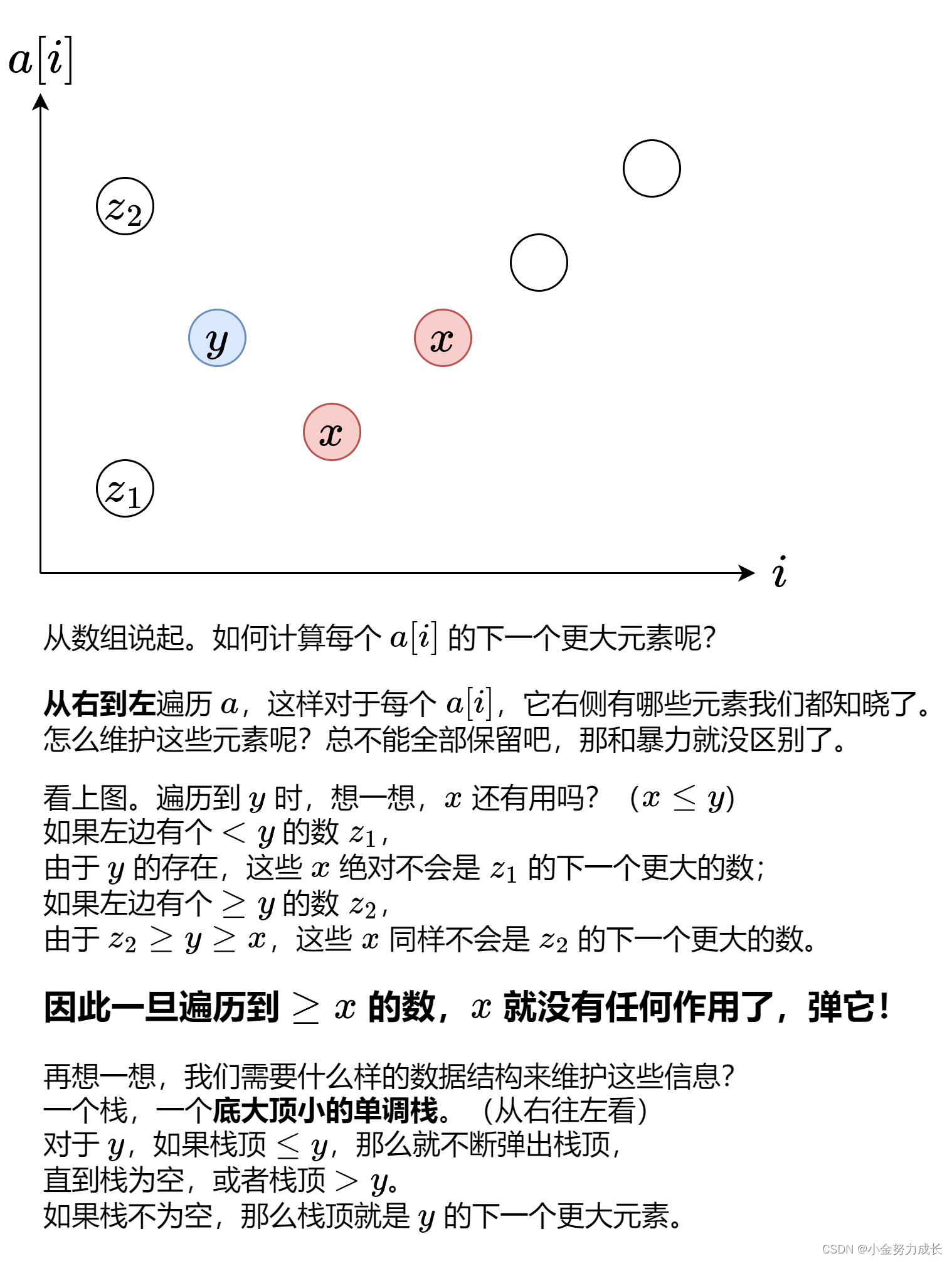
解释上图的langchain-ChatGLM项目流程如下:
(1-2)准备本地知识库文档,使用Unstructured Loader类加载文件,获取文本信息。
(3-4)对文本进行分割,将大量文本信息切分为chunks。
(5)选择一种embedding算法,对文本向量化,embedding算法有很多,选择其中一种即可。
(6)将知识库得到的embedding结果保存到数据库,保存到数据库后就不需要在执行上述步骤了。
(8-9)将问题也用同样的embedding算法,对问题向量化。
(10)从数据库中查找和问题向量最相似的N个文本信息。
(11)得到和问题相关的上下文文本信息。
(12)获取提示模板。
(13)得到输入大模型的prompt比如:"结合以下信息:" + 上下文文本信息 + "回答" + question + "输出规范:不要回答‘根据给出的信息、以上仅供参考、可以去哪里了解更多信息之类的’"。
(14)将prompt输入到LLM得到答案。
环境安装
In [ ]
# 创建持久化安装路径
!mkdir /home/aistudio/packages
!pip install langchain -t /home/aistudio/packages
# 加载文档
!pip install unstructured -t /home/aistudio/packages
# 解析表格
!pip install tabulate -t /home/aistudio/packages
# 使用sentence_transformers进行embedding
!pip install sentence_transformers -t /home/aistudio/packages
# 向量数据库
!pip install chromadb -t /home/aistudio/packages
!pip install supabase -t /home/aistudio/packages
# EB SDK
!pip install erniebot -t /home/aistudio/packages
# openai
!pip install openai -t /home/aistudio/packagesIn [ ]
# 执行完上面的环境安装部分后,以后再运行该项目只需要执行以下代码即可,无需重复安装环境
import sys
sys.path.append('/home/aistudio/packages')离线本地知识库搭建及应用
离线本地知识库构建及应用,离线本地知识库向量存储(VectorStore)使用的是Chroma。
切分文本
In [ ]
from langchain.document_loaders import UnstructuredFileLoader # 非结构化文件夹加载器,用于加载本地文件,目前,Unstructured支持加载文本文件、幻灯片、html、pdf、图像等
from langchain.text_splitter import RecursiveCharacterTextSplitter # 递归字符文本分割器,通过不同的符号递归地分割文档
# 导入文本
loader = UnstructuredFileLoader("bengbengbeng/lvzhe.txt")
# 将文本转成 Document 对象
data = loader.load()
print(f'documents:{len(data)}')
# 初始化分割器
# chunk_size每个分片的最大大小,chunk_overlap分片之间的覆盖大小,可以保持连贯性
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
# 切割加载的 document
split_docs = text_splitter.split_documents(data)
print("split_docs size:", len(split_docs), type(split_docs))文本生成Embedding
使用HuggingFaceEmbeddings生成Embedding数据
In [ ]
from langchain.vectorstores import Chroma # 围绕 ChromaDB 嵌入平台的包装器
from langchain.embeddings.huggingface import HuggingFaceEmbeddings # 文本嵌入模型
import IPython # 一个python的交互式shell
import sentence_transformers # 一个用于最先进的句子、文本和图像嵌入的 Python 框架
# 初始化 hugginFace 的 embeddings 对象
embeddings = HuggingFaceEmbeddings(model_name="/home/aistudio/models/Embeddings/text2vec-base-chinese")
# embeddings.client = sentence_transformers.SentenceTransformer(
# embeddings.model_name, device='mps') # MPS是一种CUDA并行计算模型,它可将多个CUDA进程合并为一个单一的进程,从而提高GPU的利用率。然而,由于MPS的特殊设计,可能会对图像加载产生一些负面影响。
print("embeddings", embeddings)
print("embeddings model_name", embeddings.model_name)将词向量通过Chroma保存到指定路径
In [5]
from langchain.vectorstores import Chroma # 围绕 ChromaDB 嵌入平台的包装器
# 初始化加载器,并将向量保存到磁盘
db = Chroma.from_documents(split_docs, embeddings, persist_directory="./data/doc_embeding")
# 持久化
db.persist()至此离线本地知识库已经构建完成,接下来将对语言大模型与构建好的离线本地知识库进行关联。
通过语言大模型构建问答系统
通过语言大模型构建问答系统分两种方式上进行,分别为:非langchain版和langchain版。
非langchain版:简单
langchain版:可拓展性高
非langchain版
In [ ]
import erniebot
# 认证鉴权
erniebot.api_type = 'aistudio'
erniebot.access_token = '{YOUR-ACCESS-TOKEN}'
# 加载之前持久化数据
db = Chroma(persist_directory="./data/doc_embeding", embedding_function=embeddings)
messages = []
while True:
try:
question = input('user: ')
similarDocs = db.similarity_search(question, k=4)
info = ""
for similardoc in similarDocs:
info = info + similardoc.page_content
question = "结合以下信息:" + info + "回答" + question + "输出规范:不要回答‘根据给出的信息、以上仅供参考、可以去哪里了解更多信息之类的’"
print(question)
messages.append({'role': 'user', 'content': question})
messages = messages[-5:]
response = erniebot.ChatCompletion.create(
model='ernie-bot',
messages=messages,
)
messages.append(response.to_message())
print('output: ' + response.get_result())
except KeyboardInterrupt:
print("检索世界库终止!")
break
langchain版
In [ ]
import erniebot
from pydantic import BaseModel, Field
from typing import Dict, List, Optional, Tuple, Union
from langchain.vectorstores import Chroma # 围绕 ChromaDB 嵌入平台的包装器
from langchain.prompts import PromptTemplate
from langchain.llms.base import LLM
from langchain.chains import RetrievalQA
from langchain.memory import ConversationBufferMemory
# 认证鉴权
erniebot.api_type = 'aistudio'
erniebot.access_token = '{YOUR-ACCESS-TOKEN}'
class EB(LLM):
def __init__(self):
super().__init__()
@property
def _llm_type(self) -> str:
return "erniebot"
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
prompt_list = []
prompt_list.append(prompt)
chat_completion = erniebot.ChatCompletion.create(model='ernie-bot', messages=[{"role": "user", "content": str(prompt_list)}])
response = chat_completion.get_result()
return response
class QuestionAnswer():
def __init__(self, model_name):
self.llm = EB()
self.embedding = HuggingFaceEmbeddings(model_name=model_name)
self.vector_store = Chroma(persist_directory="./data/doc_embeding", embedding_function=self.embedding)
self.prompt_template = """基于以下已知信息,严格按照信息简洁和专业的来回答用户的问题,不需要回复"根据已知信息"。
如果无法从中得到答案,请说 "非常抱歉!世界库知识检索失败!判断非本世界知识或产物。",不允许在答案中添加编造成分,答案请使用中文。
已知内容:
{context}
问题:
{question}"""
self.promptTemplate = PromptTemplate(
template=self.prompt_template,
input_variables=["context", "question"]
)
def generate(self, question):
knowledge_chain = RetrievalQA.from_llm(
llm=self.llm,
retriever=self.vector_store.as_retriever(search_kwargs={"k": 5}),
prompt=self.promptTemplate)
knowledge_chain.return_source_documents = True
result = knowledge_chain({"query": question})
response = result['result']
return response
model_name = "/home/aistudio/models/Embeddings/text2vec-base-chinese"
qa = QuestionAnswer(model_name)
while True:
try:
question = input('user: ')
response = qa.generate(question)
print('output: ' + response)
except KeyboardInterrupt:
print("检索世界库终止!")在线本地知识库构建及应用
在线本地知识库构建及应用,在线本地知识库向量存储(VectorStore)使用的是Supabase。
构建在线本地知识库之前的准备--Supabase账户注册与数据库创建
Supabase官网--Supabase
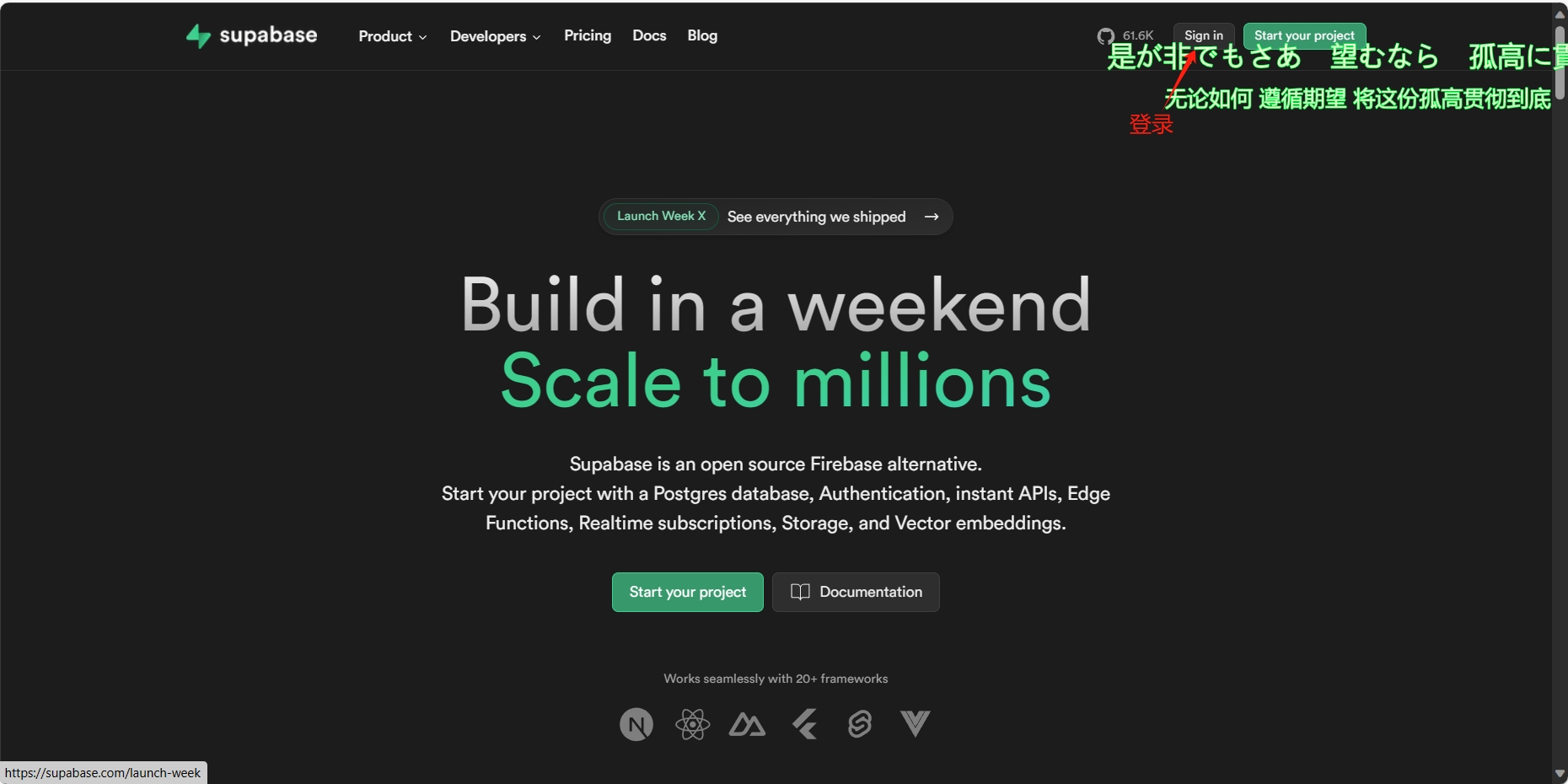
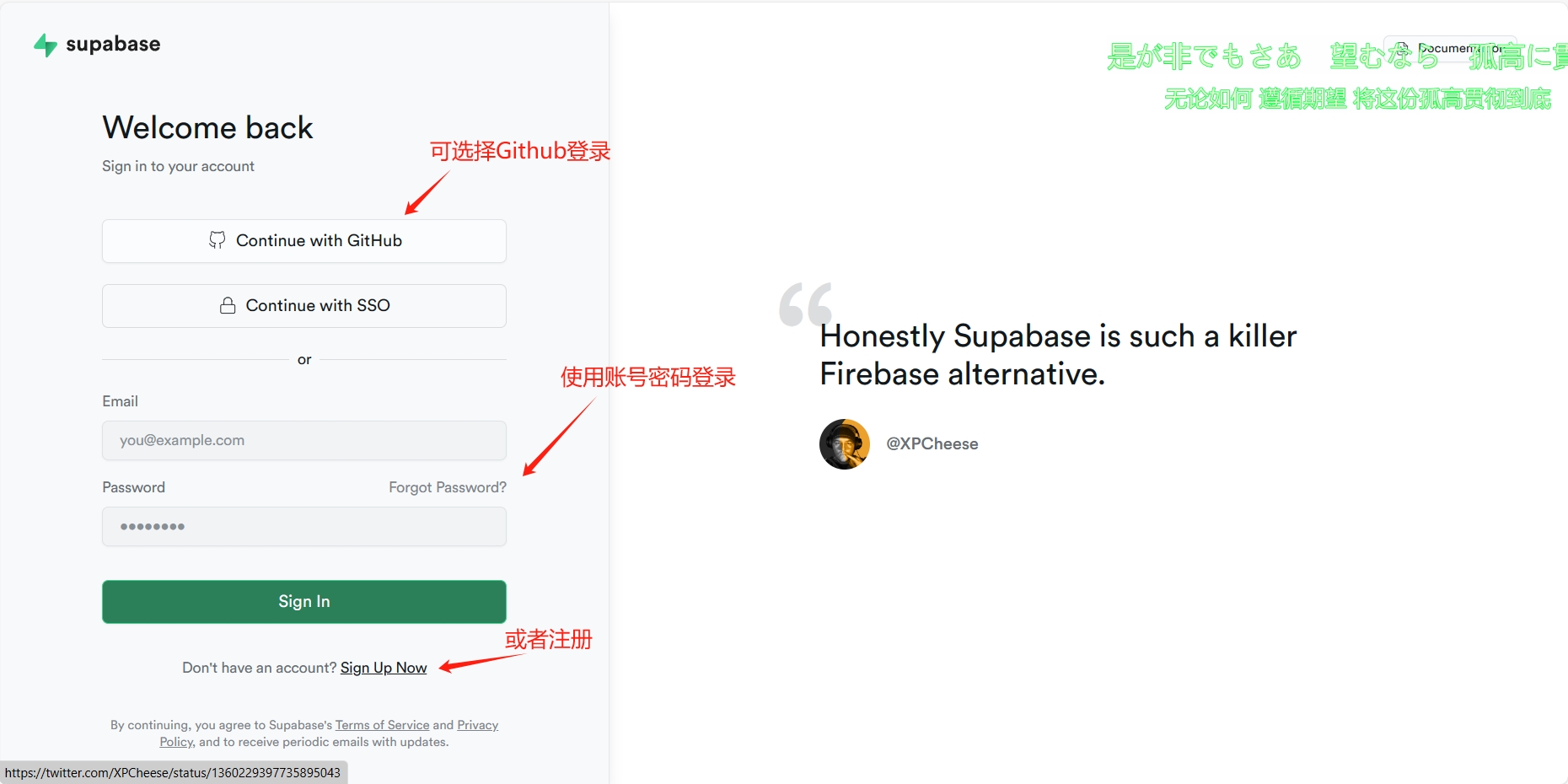
一、注册Supabase用户并登录
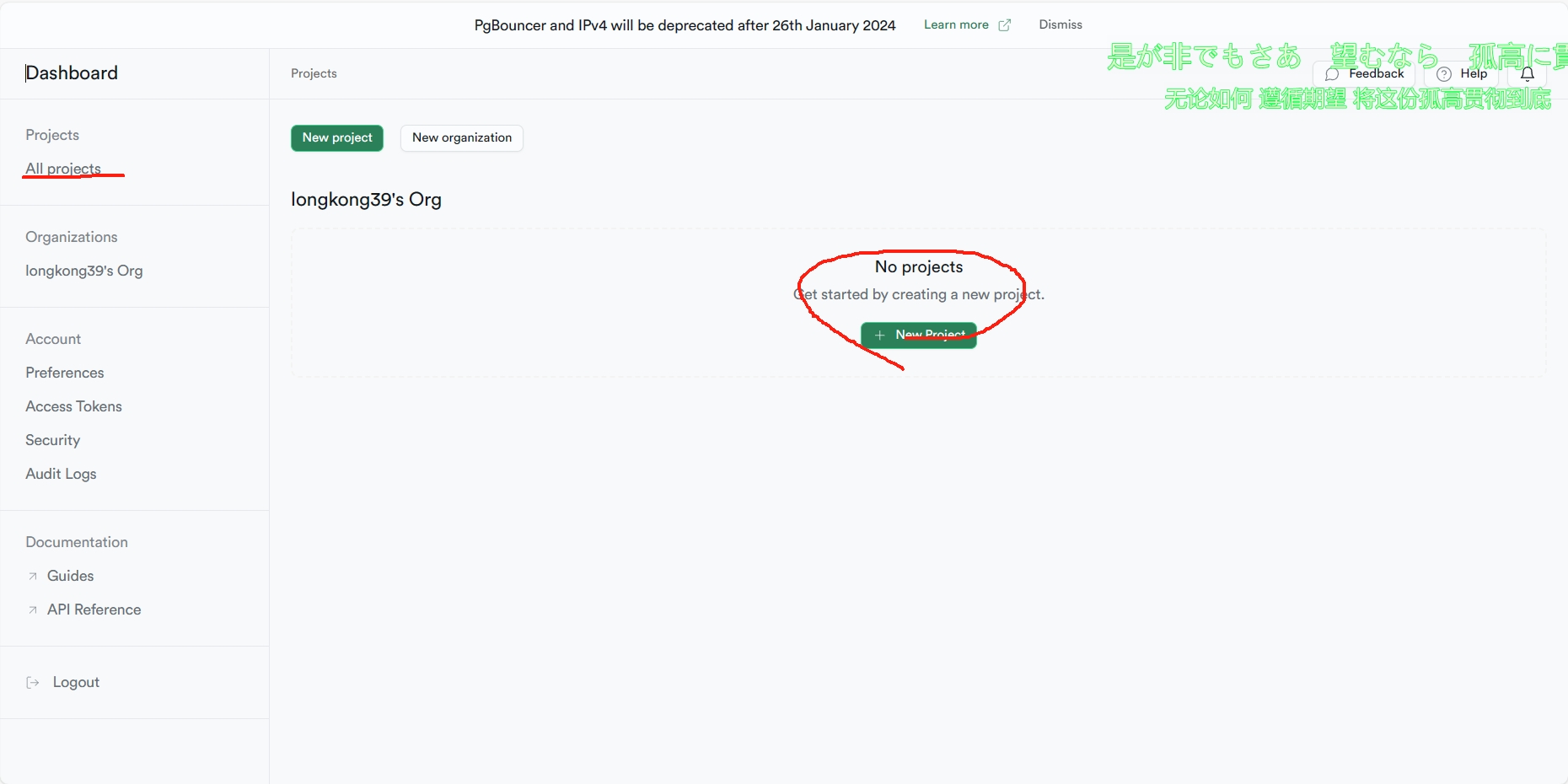
二、新建项目
三、填写信息
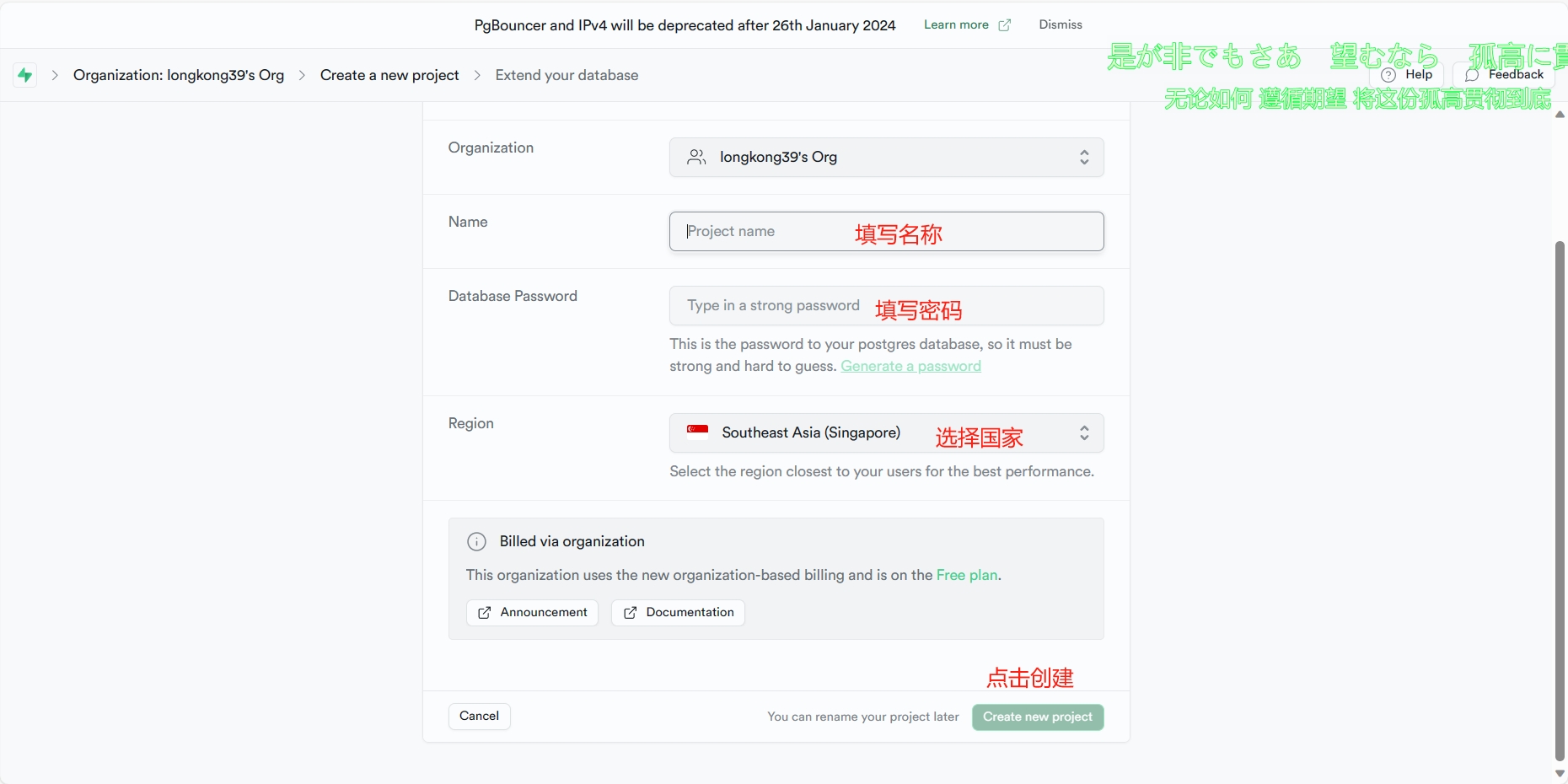
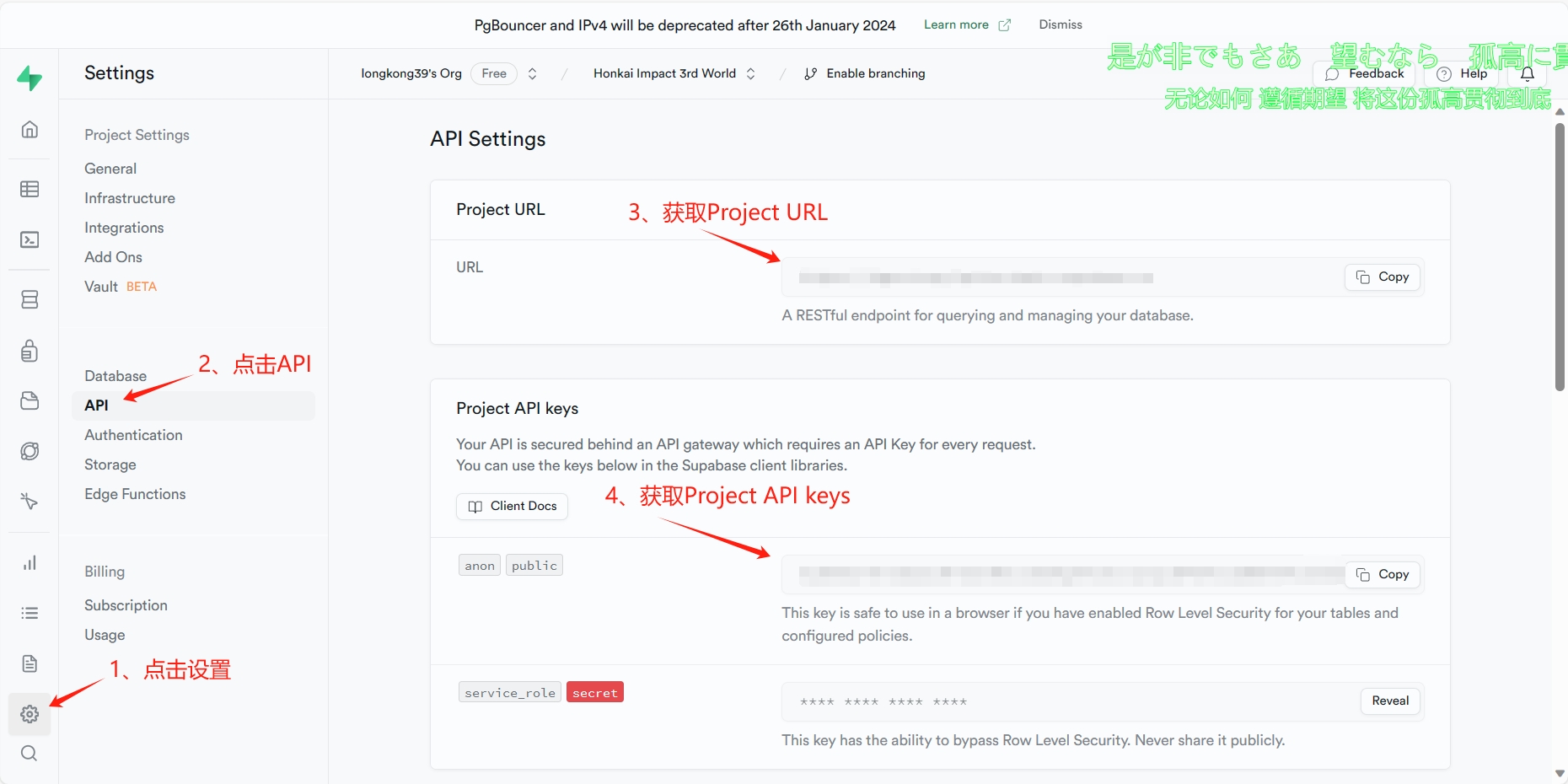
四、获取Project URL和Project API Keys
五、返回主页面
六、选择刚创建的数据库
七、pgvector扩展启用、match_documents函数、documents表创建
-- Enable the pgvector extension to work with embedding vectors
create extension vector;
-- Create a table to store your documents
create table documents (
id uuid primary key,
content text, -- corresponds to Document.pageContent
metadata jsonb, -- corresponds to Document.metadata
embedding vector(768) -- 1536 works for OpenAI embeddings, change if needed
);
-- Create a function to search for documents
create function match_documents (
query_embedding vector(768),
match_count int DEFAULT null,
filter jsonb DEFAULT '{}'
) returns table (
id uuid,
content text,
metadata jsonb,
embedding jsonb,
similarity float
)
language plpgsql
as $$
#variable_conflict use_column
begin
return query
select
id,
content,
metadata,
(embedding::text)::jsonb as embedding,
1 - (documents.embedding <=> query_embedding) as similarity
from documents
where metadata @> filter
order by documents.embedding <=> query_embedding
limit match_count;
end;
$$;
如果使用的Embedding模型为OpenAI embeddings,请将上面命令中所有的768改为1536。
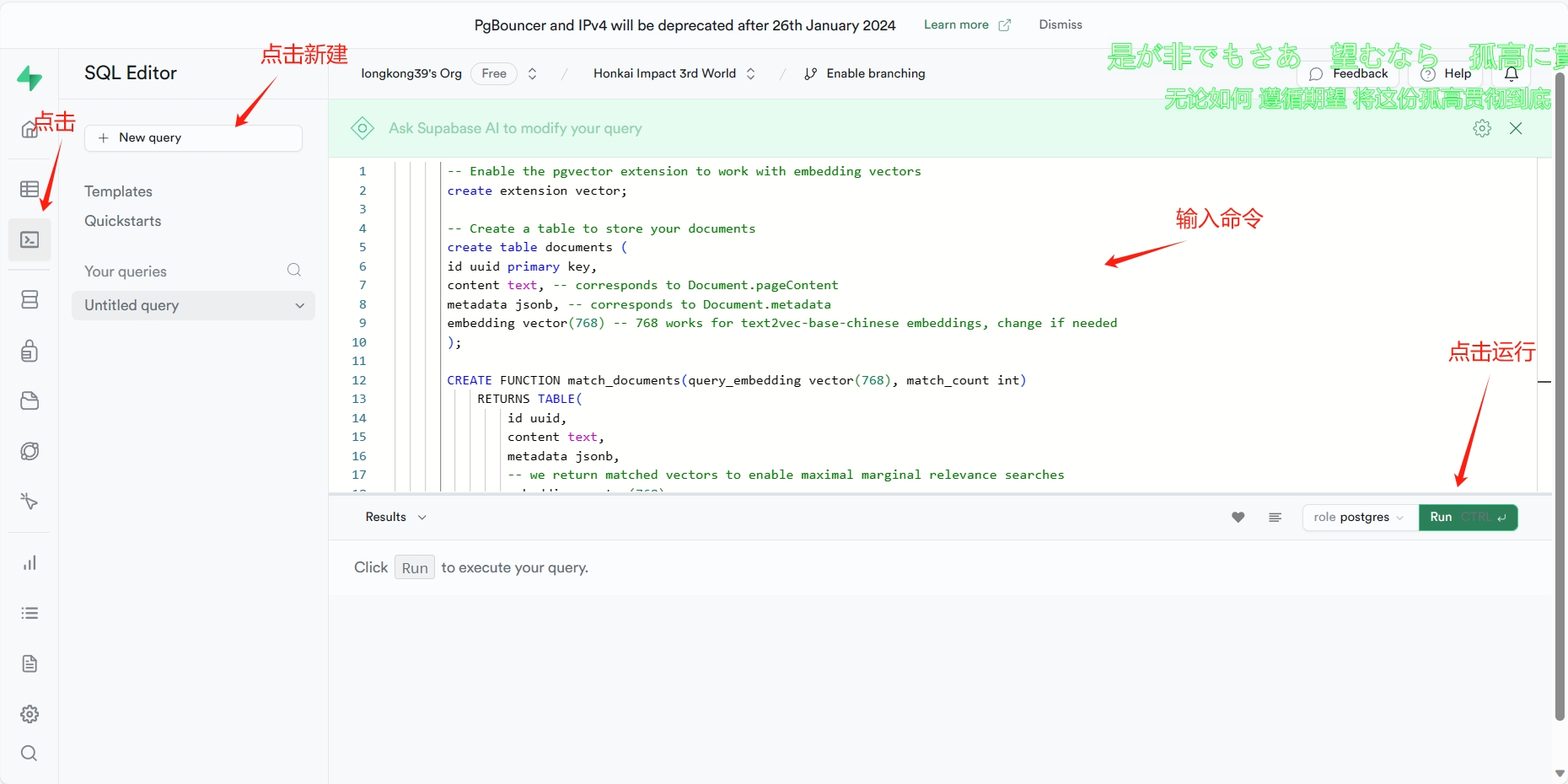
好了,构建在线本地知识库的准备工作已经完成了,接下来就正式开在线本地知识库的构建了!
切分文本
In [ ]
from langchain.document_loaders import UnstructuredFileLoader # 非结构化文件夹加载器,用于加载本地文件,目前,Unstructured支持加载文本文件、幻灯片、html、pdf、图像等
from langchain.text_splitter import CharacterTextSplitter # 递归字符文本分割器,通过不同的符号递归地分割文档
# 导入文本
loader = UnstructuredFileLoader("world/shijie.txt")
# 将文本转成 Document 对象
data = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=25)
split_docs = text_splitter.split_documents(data)文本生成Embedding
使用HuggingFaceEmbeddings生成Embedding数据
In [ ]
from langchain.embeddings.huggingface import HuggingFaceEmbeddings # 文本嵌入模型
embeddings = HuggingFaceEmbeddings(model_name="/home/aistudio/models/Embeddings/text2vec-base-chinese")
print("embeddings", embeddings)
print("embeddings model_name", embeddings.model_name)将词向量保存到在线数据库Supabase
In [ ]
# 配置Supabase
import os
import getpass
from langchain.vectorstores import SupabaseVectorStore
from supabase.client import Client, create_client
# 配置Supabase
os.environ['SUPABASE_URL'] = getpass.getpass('Supabase URL:')
os.environ['SUPABASE_SERVICE_KEY'] = getpass.getpass('Supabase Service Key:')
supabase_url = os.environ.get("SUPABASE_URL")
supabase_key = os.environ.get("SUPABASE_SERVICE_KEY")
supabase_client: Client = create_client(supabase_url, supabase_key)
vector_store = SupabaseVectorStore.from_documents(
split_docs,
embeddings,
client=supabase_client
)至此在线本地知识库已经构建完成,接下来将对语言大模型与构建好的在线本地知识库进行关联。
通过语言大模型构建问答系统
通过语言大模型构建问答系统分两种方式上进行,分别为:非langchain版和langchain版。
非langchain版:简单
langchain版:可拓展性高
非langchain版
In [ ]
import os
import getpass
import erniebot
from langchain.vectorstores import SupabaseVectorStore
from supabase.client import Client, create_client
from langchain.embeddings.huggingface import HuggingFaceEmbeddings # 文本嵌入模型
# 认证鉴权
erniebot.api_type = 'aistudio'
erniebot.access_token = '{YOUR-ACCESS-TOKEN}'
# 配置Supabase
os.environ['SUPABASE_URL'] = getpass.getpass('Supabase URL:')
os.environ['SUPABASE_SERVICE_KEY'] = getpass.getpass('Supabase Service Key:')
supabase_url = os.environ.get("SUPABASE_URL")
supabase_key = os.environ.get("SUPABASE_SERVICE_KEY")
supabase_client: Client = create_client(supabase_url, supabase_key)
embeddings = HuggingFaceEmbeddings(model_name="/home/aistudio/models/Embeddings/text2vec-base-chinese")
# 加载存储在Supabase上的数据
vector_store = SupabaseVectorStore(
client=supabase_client,
embedding=embeddings,
table_name="documents"
)
messages = []
while True:
try:
question = input('user: ')
similarDocs = vector_store.similarity_search(question, k=4)
info = ""
for similardoc in similarDocs:
info = info + similardoc.page_content + '\n'
question = "结合以下信息:\n" + info + "回答" + question + "输出规范:不要回答‘根据给出的信息、以上仅供参考、可以去哪里了解更多信息之类的’"
print(question)
messages.append({'role': 'user', 'content': question})
messages = messages[-5:]
response = erniebot.ChatCompletion.create(
model='ernie-bot',
messages=messages,
)
messages.append(response.to_message())
print('output: ' + response.get_result())
except KeyboardInterrupt:
print("检索世界库终止!")
breaklangchain版
In [ ]
import os
import getpass
import erniebot
from pydantic import BaseModel, Field
from typing import Dict, List, Optional, Tuple, Union
from langchain.vectorstores import SupabaseVectorStore
from supabase.client import Client, create_client
from langchain.prompts import PromptTemplate
from langchain.llms.base import LLM
from langchain.chains import RetrievalQA
from langchain.memory import ConversationBufferMemory
# 认证鉴权
erniebot.api_type = 'aistudio'
erniebot.access_token = '{YOUR-ACCESS-TOKEN}'
# 配置Supabase
os.environ['SUPABASE_URL'] = getpass.getpass('Supabase URL:')
os.environ['SUPABASE_SERVICE_KEY'] = getpass.getpass('Supabase Service Key:')
supabase_url = os.environ.get("SUPABASE_URL")
supabase_key = os.environ.get("SUPABASE_SERVICE_KEY")
supabase_client: Client = create_client(supabase_url, supabase_key)
class EB(LLM):
def __init__(self):
super().__init__()
@property
def _llm_type(self) -> str:
return "erniebot"
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
prompt_list = []
prompt_list.append(prompt)
chat_completion = erniebot.ChatCompletion.create(model='ernie-bot', messages=[{"role": "user", "content": str(prompt_list)}])
response = chat_completion.get_result()
return response
class QuestionAnswer():
def __init__(self, model_name):
self.llm = EB()
self.embedding = HuggingFaceEmbeddings(model_name=model_name)
self.vector_store = vector_store = SupabaseVectorStore(
client=supabase_client,
embedding=embeddings,
table_name="documents",
query_name="match_documents",
)
self.prompt_template = """基于以下已知信息,严格按照信息简洁和专业的来回答用户的问题,不需要回复"根据已知信息"。
如果无法从中得到答案,请说 "非常抱歉!世界库知识检索失败!判断非本世界知识或产物。",不允许在答案中添加编造成分,答案请使用中文。
已知内容:
{context}
问题:
{question}"""
self.promptTemplate = PromptTemplate(
template=self.prompt_template,
input_variables=["context", "question"]
)
def generate(self, question):
knowledge_chain = RetrievalQA.from_llm(
llm=self.llm,
retriever=self.vector_store.as_retriever(search_kwargs={"k": 5}),
prompt=self.promptTemplate)
knowledge_chain.return_source_documents = True
result = knowledge_chain({"query": question})
response = result['result']
return response
model_name = "/home/aistudio/models/Embeddings/text2vec-base-chinese"
qa = QuestionAnswer(model_name)
while True:
try:
question = input('user: ')
response = qa.generate(question)
print('output: ' + response)
except KeyboardInterrupt:
print("检索世界库终止!")
break以上就是本项目的所有内容了,希望你能从中学习到新的知识!