Pytorch
- 一、判断环境
- 1.导入必要的库
- 2.判断环境
- 二、定义字典
- 1.定义字典
- 三、处理图像数据集
- 1.导入必要的模块
- 2.定义变量
- 3.删除隐藏文件/文件夹
- 四、加载数据集
- 1.加载训练数据集
- 2.加载测试数据集
- 3.定义训练数据集和测试集路径
- 4.加载训练集和测试集
- 5.创建训练集和测试集数据加载器
- 五、定义卷积神经网络
- 1.定义卷积神经网络
- 六、创建AlexNet模型
- 1.创建模型
- 2.检查GPU设备
- 3.训练过程
- 七、训练模型
- 1.设置模型为训练模式
- 2.初始化计数器
- 3.遍历训练数据加载器
- 4.打印进度
- 5.打印最终结果
- 八、验证模型
- 1.设置模型为验证模式
- 2.初始化计数器
- 3.遍历测试数据加载器
- 4.打印验证结果
- 九、创建学习率调度器
- 1.创建学习率调度器
- 2.训练模型
一、判断环境
1.导入必要的库
torch.optim as optim: 导入 PyTorch 的优化器模块,用于定义优化器。
torch: 导入 PyTorch 的主库,提供神经网络和自动微分的核心功能。
torch.nn as nn: 导入 PyTorch 的神经网络模块,提供构建神经网络所需的层和功能。
torch.nn.parallel: 导入 PyTorch 的并行模块,用于在多GPU上运行模型。
torch.optim: 导入 PyTorch 的优化器模块,用于定义优化器。
torch.utils.data: 导入 PyTorch 的数据处理模块,用于处理数据集和数据加载器
torch.utils.data.distributed: 导入 PyTorch 的分布式数据处理模块,用于处理分布式数据。
torchvision.transforms as transforms: 导入 PyTorch 的图像变换模块,用于数据增强和预处理。
torchvision.datasets as datasets: 导入 PyTorch 的数据集模块,用于加载和访问数据集。
torchvision.models: 导入 PyTorch 的预训练模型模块,用于加载预训练的模型。
from torch.autograd import Variable: 导入 PyTorch 的自动微分模块,用于定义张量为可微变量。
from torchvision import models: 导入 PyTorch 的预训练模型模块,用于加载预训练的模型。
import os: 导入 Python 的操作系统模块,用于操作文件和目录。
from PIL import Image: 导入 Python 的图像处理库 PIL,用于打开和操作图像。
import cv2: 导入 OpenCV 库,用于处理图像和视频。
import torch.optim.lr_scheduler as lr_scheduler: 导入 PyTorch 的学习率调度器模块,用于调整学习率。
import torch.optim as optim
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision.models
from torch.autograd import Variable
from torch.nn import Conv2d
from tqdm import tqdm
from torchvision import models
import os
from PIL import Image
import cv2
import torch.optim.lr_scheduler as lr_scheduler
2.判断环境
根据 DEVICE 的值来决定是使用 CPU 还是 GPU 进行计算。
#判断环境是CPU运行还是GPU
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
DEVICE
运行结果:

二、定义字典
1.定义字典
定义一个名为 transform111 的字典,其中包含了两个键值对,分别对应于训练和验证数据集的图像变换。这些变换通常用于数据增强和预处理,以提高模型的泛化能力和性能。
transform111 字典的结构如下:
'train': 训练数据集的图像变换。
-
transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)):
从原始图片中随机裁剪一个大小为 256x256 的区域,裁剪区域的缩放范围为 0.8 到 1.0。 -
transforms.RandomRotation(degrees=15): 随机旋转图片 15 度。 -
transforms.RandomHorizontalFlip(): 随机水平翻转图片。 -
transforms.CenterCrop(size=224): 从裁剪后的图片中中心裁剪一个大小为 224x224 的区域。 -
transforms.ToTensor(): 将 PIL 图像转换为 PyTorch 张量。 -
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]):
对图像进行归一化处理,将每个通道的均值和标准差调整为 0.485、0.456、0.406 和 0.229、0.224、0.225。
'val': 验证数据集的图像变换。
transforms.Resize(size=256): 将图片大小调整为 256x256。transforms.CenterCrop(size=224): 从调整后的图片中中心裁剪一个大小为 224x224 的区域。transforms.ToTensor(): 将 PIL 图像转换为 PyTorch 张量。transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]):
对图像进行归一化处理,将每个通道的均值和标准差调整为 0.485、0.456、0.406 和 0.229、0.224、0.225。
transform111 = {
'train': transforms.Compose([
transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),
transforms.RandomRotation(degrees=15),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
}
transform111
运行结果:

三、处理图像数据集
1.导入必要的模块
import shutil: 导入 Python 的 shutil 模块,用于操作文件和目录。
import shutil
2.定义变量
modellr: 用于存储模型的学习率。学习率是模型训练中的一个关键超参数,它决定了优化算法中参数更新的步长。在这个例子中,学习率被设置为 1e-3,即 0.001。
BATCH_SIZE: 用于存储每个训练批次中的样本数量。较大的批大小可以提高计算效率,但可能会增加内存需求。在这个例子中,批大小被设置为 64。
EPOCHS: 用于存储训练过程中迭代的轮数。每个 epoch 表示数据集被完整地遍历了一次。在这个例子中,训练过程被设置为进行 60 个 epoch。
modellr = 1e-3
BATCH_SIZE = 64
EPOCHS = 60
3.删除隐藏文件/文件夹
删除指定目录及其所有子目录中包含 ‘ipynb_checkpoints’ 的文件和文件夹。
操作如下:
1)遍历目录:
for root, dirs, files in os.walk('./dataset'): 这行代码使用 os.walk
函数遍历指定目录 ./dataset 及其所有子目录。os.walk 函数会返回一个三元组 (root, dirs, files),其中 root 是当前目录的路径,dirs 是当前目录下的所有子目录列表,files 是当前目录下的所有文件列表。
2)删除隐藏文件:
for file in files: 这行代码遍历当前目录下的所有文件。if 'ipynb_checkpoints' in file: 这行代码检查文件名是否包含 ‘ipynb_checkpoints’。os.remove(os.path.join(root, file)): 如果文件名包含 ‘ipynb_checkpoints’,则使用
os.remove 函数删除该文件。
3)删除隐藏文件夹:
if 'ipynb_checkpoints' in root: 这行代码检查当前目录的路径是否包含
‘ipynb_checkpoints’。shutil.rmtree(root): 如果当前目录的路径包含 ‘ipynb_checkpoints’,则使用
shutil.rmtree 函数删除整个目录及其所有子目录和文件。
# 删除隐藏文件/文件夹
for root, dirs, files in os.walk('./dataset'):
for file in files:
if 'ipynb_checkpoints' in file:
os.remove(os.path.join(root, file))
if 'ipynb_checkpoints' in root:
shutil.rmtree(root)
四、加载数据集
1.加载训练数据集
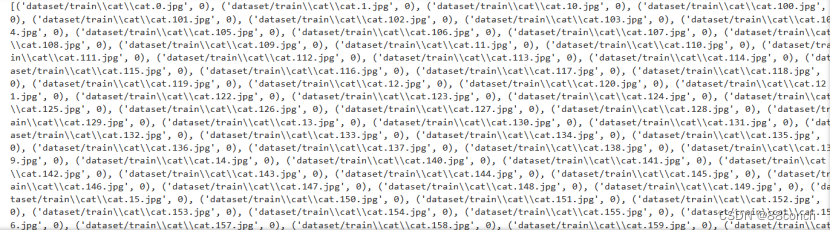
1)dataset_train = datasets.ImageFolder('dataset/train', transform111): 使用 datasets.ImageFolder 函数加载 dataset/train 目录中的图像数据,并应用之前定义的 transform111 变换。
2)print(dataset_train.imgs): 打印出训练数据集的图像路径和对应的标签。
3)print(dataset_train.class_to_idx): 打印出训练数据集的标签映射。
# 读取数据
dataset_train = datasets.ImageFolder('dataset/train', transform111)
print(dataset_train.imgs)
# 对应文件夹的label
print(dataset_train.class_to_idx)
2.加载测试数据集
1)dataset_test = datasets.ImageFolder('dataset/val', transform111): 使用 datasets.ImageFolder 函数加载 dataset/val 目录中的图像数据,并应用之前定义的 transform111 变换。
2)print(dataset_test.imgs): 打印出测试数据集的图像路径和对应的标签。
3)print(dataset_test.class_to_idx): 打印出测试数据集的标签映射。
dataset_test = datasets.ImageFolder('dataset/val', transform111)
# 对应文件夹的label
print(dataset_test.class_to_idx)
3.定义训练数据集和测试集路径
这两个路径分别指向 dataset/train 和 dataset/val 目录,这些目录包含训练和验证图像数据。
1)定义数据集路径:
dataset = './dataset': 定义一个变量 dataset,它指向 ./dataset 目录,这是数据集的根目录。
2)定义训练数据集路径:
train_directory = os.path.join(dataset, 'train'): 使用 os.path.join 函数将
dataset 变量和 ‘train’ 字符串连接起来,以创建训练数据集的路径。
3)定义验证数据集路径:
valid_directory = os.path.join(dataset, 'val'): 使用 os.path.join 函数将
dataset 变量和 ‘val’ 字符串连接起来,以创建验证数据集的路径。
dataset = './dataset'
train_directory = os.path.join(dataset, 'train')
valid_directory = os.path.join(dataset, 'val')
4.加载训练集和测试集
定义变量,并使用 datasets.ImageFolder 函数加载了训练和验证数据集。
1)定义批大小和类别数量:
batch_size = 32: 定义每个训练批次的样本数量为 32。num_classes = 6: 定义数据集中类别的数量为 6。
2)打印训练数据集路径:
print(train_directory): 打印出训练数据集的路径。
3)创建数据集字典:
data = {'train': datasets.ImageFolder(root=train_directory, transform=transform111['train']), 'val': datasets.ImageFolder(root=valid_directory, transform=transform111['val'])}: 创建一个名为 data 的字典,其中包含两个键值对。键为 ‘train’
和 ‘val’,对应的值分别是 datasets.ImageFolder 对象,这些对象加载了训练数据集和验证数据集。
batch_size = 32
num_classes = 6
print(train_directory)
data = {
'train': datasets.ImageFolder(root=train_directory, transform=transform111['train']),
'val': datasets.ImageFolder(root=valid_directory, transform=transform111['val'])
}
5.创建训练集和测试集数据加载器
定义变量,并使用 torch.utils.data.DataLoader 函数创建了训练和测试数据加载器。
1)获取数据集大小:
train_data_size = len(data['train']): 计算训练数据集的大小。valid_data_size = len(data['val']): 计算验证数据集的大小。
2)创建数据加载器:
train_loader = torch.utils.data.DataLoader(data['train'], batch_size=batch_size, shuffle=True, num_workers=8): 创建一个训练数据加载器,其中batch_size 参数定义了每个批次的样本数量,shuffle=True 参数表示在每次迭代时打乱数据,num_workers=8参数定义数据加载过程中使用的线程数。test_loader = torch.utils.data.DataLoader(data['val'], batch_size=batch_size, shuffle=True, num_workers=8):
创建一个测试数据加载器,其参数与训练数据加载器的参数相同。
3)打印数据集大小:
print(train_data_size, valid_data_size): 打印出训练数据集和验证数据集的大小。
train_data_size = len(data['train'])
valid_data_size = len(data['val'])
train_loader = torch.utils.data.DataLoader(data['train'], batch_size=batch_size, shuffle=True, num_workers=8)
test_loader = torch.utils.data.DataLoader(data['val'], batch_size=batch_size, shuffle=True, num_workers=8)
print(train_data_size, valid_data_size)
运行结果:
五、定义卷积神经网络
1.定义卷积神经网络
定义一个名为 AlexNet 的卷积神经网络类,它继承自 torch.nn.Module。这个类实现了一个简化版的 AlexNet 网络结构,用于图像分类任务。
1)__init__(self, num_classes=2): 构造函数接收一个参数 num_classes,表示输出层的类别数,默认值为 2(例如,二分类问题)。在构造函数中,定义以下层:
-
特征提取部分(self.features):
-
第一个卷积层:64 个输出通道,大小为 11x11 的卷积核,步幅为 4,填充为 2
-
ReLU 激活函数。 最大池化层:3x3的窗口,步幅为 2。
-
第二个卷积层:192 个输出通道,大小为 5x5 的卷积核,padding 为 2。 ReLU 激活函数。
-
最大池化层:3x3 的窗口,步幅为 2。 第三个卷积层:384 个输出通道,大小为 3x3 的卷积核,padding 为 1。
-
ReLU激活函数。
-
第四个卷积层:256 个输出通道,大小为 3x3 的卷积核,padding 为 1。 ReLU 激活函数。
-
第五个卷积层:256 个输出通道,大小为 3x3 的卷积核,padding 为 1。 ReLU 激活函数。
-
最大池化层:3x3的窗口,步幅为 2。
-
平均池化层(self.avgpool):自适应平均池化,输出尺寸为 6x6。
-
List item
-
全连接层(self.classifier):
Dropout 层。 第一个全连接层:4096 个神经元。 ReLU 激活函数。 Dropout 层。 第二个全连接层:4096
个神经元。 ReLU 激活函数。 第三个全连接层:num_classes 个神经元。LogSoftmax 层:用于计算每个类别的对数概率。
2)forward(self, x): 前向传播函数接收输入 x,并依次通过以下层:
- 特征提取部分。
- 平均池化层。
- 将特征图展平为一维向量。
- 全连接层。
- LogSoftmax 层。
- 返回展平后的特征图和每个类别的对数概率。
class AlexNet(nn.Module):
def __init__(self, num_classes=2):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
# softmax
self.logsoftmax = nn.LogSoftmax(dim=1)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
x = self.logsoftmax(x)
return x
六、创建AlexNet模型
1.创建模型
Alex_model = AlexNet()
2.检查GPU设备
如果 GPU 可用,则定义一个 torch.device 对象,表示使用 GPU。如果 GPU 不可用,则定义一个 torch.device 对象,表示使用 CPU。
以下是函数的详细步骤:
1)检查 GPU 可用性:
-
if torch.cuda.is_available(): 这行代码检查是否有可用的 GPU 设备。
-
device = torch.device(‘cuda’): 如果 GPU 可用,则定义一个 torch.device 对象,表示使用 GPU。
-
print(“CUDA is available! Using GPU for training.”): 打印一条消息,表示 CUDA
可用,并且使用 GPU 进行训练。 -
else: 如果 GPU 不可用,则执行以下代码。
2)使用 CPU 进行训练:
-
device = torch.device(‘cpu’): 定义一个 torch.device 对象,表示使用 CPU。
-
print(“CUDA is not available. Using CPU for training.”): 打印一条消息,表示
CUDA 不可用,并且使用 CPU 进行训练。
# 首先,检查是否有可用的 GPU
if torch.cuda.is_available():
# 定义 GPU 设备
device = torch.device('cuda')
print("CUDA is available! Using GPU for training.")
else:
# 如果没有可用的 GPU,则使用 CPU
device = torch.device('cpu')
print("CUDA is not available. Using CPU for training.")
3.训练过程
如果 GPU 可用,将模型移动到 GPU 上,并使用 GPU 进行训练;如果 GPU 不可用,则使用 CPU 进行训练。
1)将模型移动到 GPU:
Alex_model.to(device): 将模型移动到之前定义的 device 对象所表示的设备上。如果 device 是 ‘cuda’,则模型将被移动到 GPU;如果 device 是 ‘cpu’,则模型将被移动到 CPU。
2)定义损失函数:
criterion = nn.CrossEntropyLoss(): 定义交叉熵损失函数,这是用于分类问题的常见损失函数。
3)创建优化器:
optimizer = optim.Adam(Alex_model.parameters(), lr=0.001, weight_decay=1e-4): 创建Adam 优化器,其中 lr=0.001 表示学习率为 0.001,weight_decay=1e-4 表示权重衰减为 0.0001。
# 将模型移动到 GPU
Alex_model.to(device)
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 创建优化器
optimizer = optim.Adam(Alex_model.parameters(), lr=0.001, weight_decay=1e-4)
运行结果:

七、训练模型
1.设置模型为训练模式
将模型设置为训练模式,这样模型在计算梯度时会使用 Dropout 和 BatchNorm 层。
def train(model, device, train_loader, optimizer, criterion, epoch):
model.train()
2.初始化计数器
用于在每次迭代时累积损失、正确预测的数量和总样本数。
running_loss = 0.0
correct = 0
total = 0
3.遍历训练数据加载器
遍历 train_loader 中的每个批次,并将数据和标签移动到指定的设备上。然后,它执行前向传播、计算损失、
反向传播和更新模型参数。同时,它累积损失、样本数和正确预测的数量。
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
print(output) # 检查模型的输出是否为None
target = target.to(dtype=torch.long) # 将目标标签转换为长整数类型
loss = criterion(output, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
4.打印进度
在每 10 个批次后打印当前的轮次、批次数和损失值,以便监控训练进度。
if batch_idx % 10 == 0: # 每10个批次打印一次
print(f'Epoch {epoch}, Batch {batch_idx}, Loss: {loss.item()}')
5.打印最终结果
在当前轮次结束时打印平均损失和准确率。
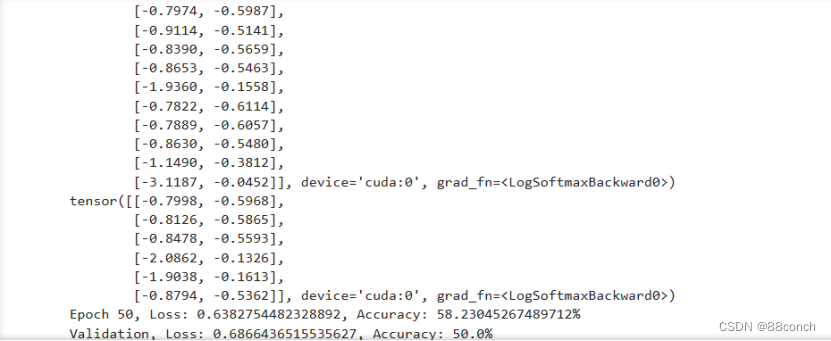
print(f’Epoch {epoch}, Loss: {running_loss / len(train_loader)}, Accuracy: {100 * correct / total}%')
说明:这个函数实现了一个基本的训练循环,它能够训练模型进行图像分类。在实际使用中,您可能需要根据您的具体任务调整学习率、优化器、损失函数等超参数,并确保数据加载器的设置与模型的需求相匹配。
八、验证模型
1.设置模型为验证模式
将模型设置为验证模式,这样模型在计算梯度时不会使用 Dropout 和 BatchNorm 层。
# 定义验证过程
def val(model, device, test_loader, criterion):
model.eval()
2.初始化计数器
用于在每次迭代时累积损失、正确预测的数量和总样本数。
running_loss = 0.0
correct = 0
total = 0
3.遍历测试数据加载器
遍历 test_loader 中的每个批次,并将数据和标签移动到指定的设备上。然后,它执行前向传播并计算损失。由于模型处于验证模式,它不会计算梯度。同时,它累积损失、样本数和正确预测的数量。
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
loss = criterion(output, target)
running_loss += loss.item()
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
4.打印验证结果
在验证过程结束时打印平均损失和准确率。
print(f’Validation, Loss: {running_loss / len(test_loader)}, Accuracy: {100 * correct / total}%')
说明:这个函数实现了一个基本的验证循环,它能够验证模型在测试数据集上的性能。在实际使用中,您可能需要根据您的具体任务调整超参数,并确保数据加载器的设置与模型的需求相匹配。
九、创建学习率调度器
1.创建学习率调度器
创建一个 StepLR 学习率调度器,其中 optimizer 是之前创建的优化器,step_size=7 表示每 7 个 epoch 调整一次学习率,gamma=0.1 表示每次调整学习率时减少 10%。
# 创建学习率调度器
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
2.训练模型
定义了一个循环,该循环执行了 EPOCHS 次。在每个 epoch 中,它首先使用 train 函数训练模型,然后使用 val 函数验证模型。在每个 epoch 结束时,它调用 scheduler.step() 方法来调整学习率。
# 训练模型
EPOCHS = 50
for epoch in range(1, EPOCHS + 1):
train(Alex_model, device, train_loader, optimizer, criterion, epoch) # 使用 Alex_model
val(Alex_model, device, test_loader, criterion) # 使用 Alex_model
scheduler.step() # 调整学习率
运行结果: