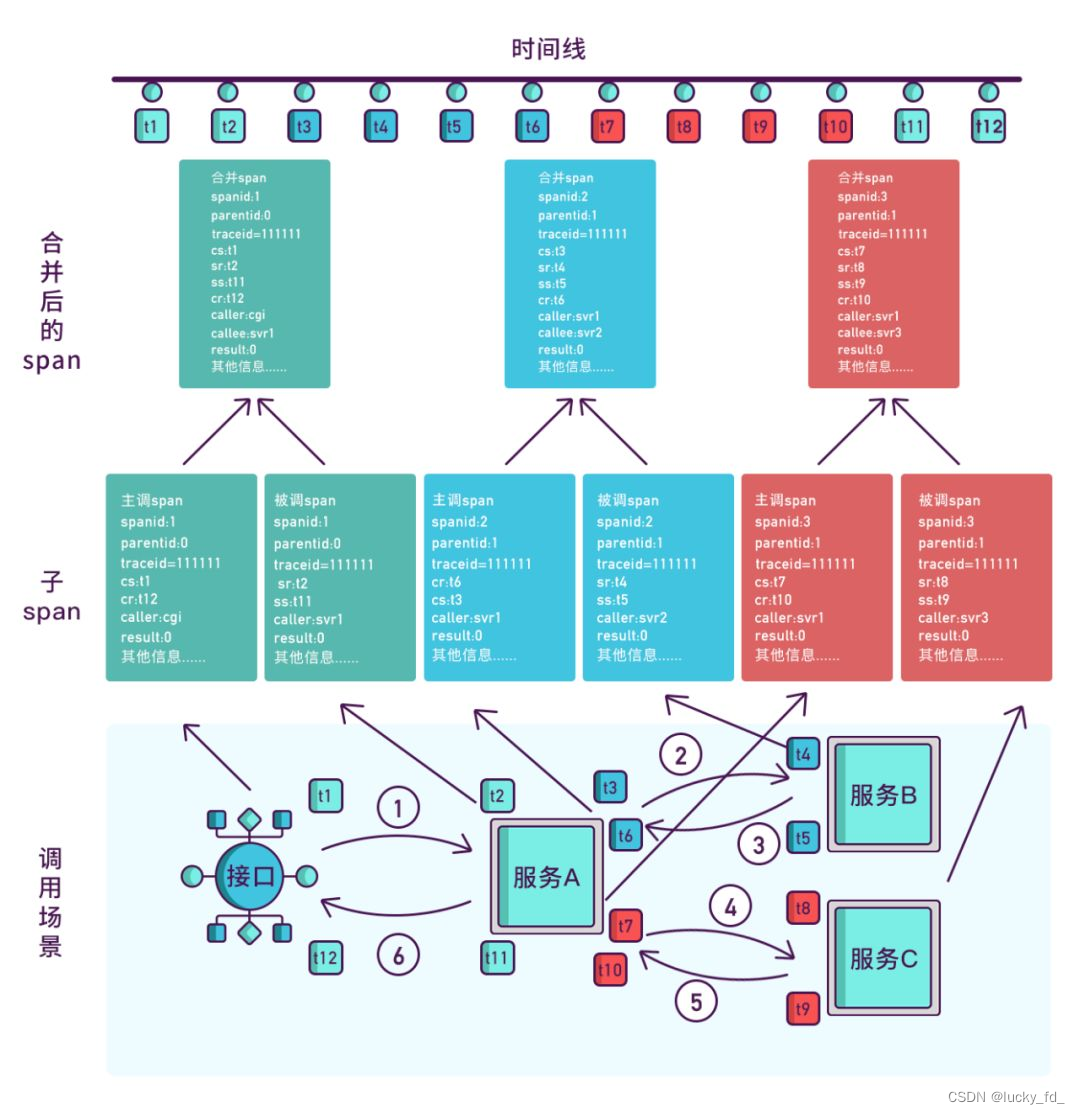
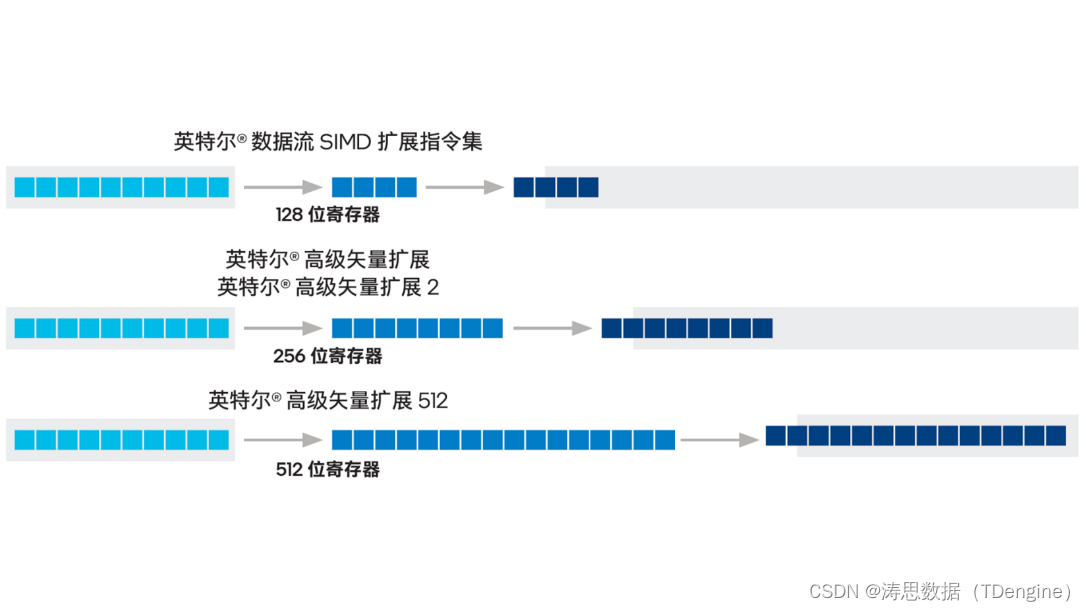
在当今的 IoT 和智能制造领域,海量时序数据持续产生,对于这些数据的实时存储、高效查询和分析已经成为时序数据库(Time Series Database,TSDB)的核心竞争力。作为一款高性能的时序数据库,TDengine 不仅采用了先进数据处理算法,还在 3.2.3.0 版本引入了英特尔® AVX512 高级向量扩展指令集,实现并行处理数据,产品查询性能获得了进一步提升。本篇文章将深入介绍 TDengine 与 AVX512 集成的优化工作。
TDengine 与 AVX-512 集成原理
作为一种单指令多数据(Single Instruction Multiple Data,SIMD)指令集,英特尔® AVX-512 在密集型计算负载中有着得天独厚的优势。得益于其 512 位的寄存器宽度和两个 512 位的融合乘加(Fused Multiply Add,FMA)单元,该指令集能并行执行 32 次双精度、64 次单精度浮点运算,或操作 8 个 64 位和 16 个 32 位整数,极大地提升了数据的处理能力。
时序数据中存在大量相似数据,而 TDengine 对时序数据的处理流程是一致的。对于这些无前后依赖性的时序数据,采用 AVX512 并行处理数据可以显著提升系统性能。特别是在 TDengine 进行数据平均值查询时,由于符合数据并行化特点,引入 AVX512 技术可有效提升性能。
为了节省数据存储空间,TDengine 在数据存储前会进行编码处理,去除数据中的冗余,并进行压缩,从而使最终存储的数据占用空间大大减少。而数据平均值的查询过程则是相反的,需要对存储的数据进行解码和计算。如下图所示:
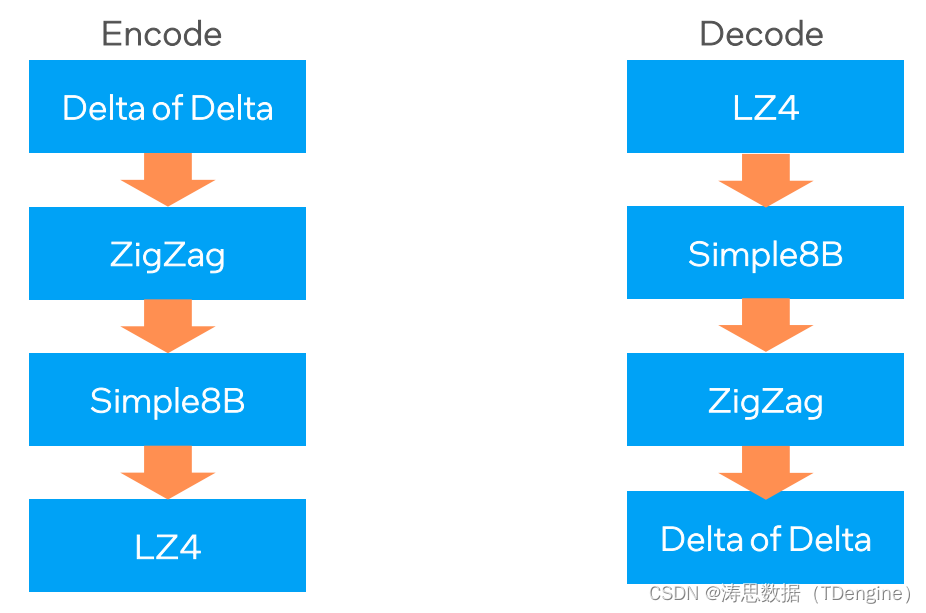
其中算法 Simple8B、ZigZag、Delta of Delta 可以通过 AVX512 进行优化。
-
Simple8B 的 AVX512 优化
如果要将相同长度的数据使用 Simple8B 存储在一个 64bit 空间中,例如每个有效数据占用 3bit,在 64bit 内,索引占用 4bit,剩下的 60bit 可以存储 20 个 3bit 的有效数据。在解码过程中,传统的方法是将每个有效的 3bit 数据逐个加载到 32bit 变量中,然后进行处理,这将需要进行 20 次处理。
而使用 AVX512 指令,可以一次并行将 8 个 3bit 的数据变换成 32bit 的数据,这样我们用很少的次数就可以处理完所有数据,大大提升了系统性能。如下图,payload 是 64bit 的 simple8B 数据,使用 AVX512 指令,通过并行同步移位和掩码的方式,一次提取出 8 个有效数据,并装载在 512bit 的寄存器里(32bit x 8),为 ZigZag 算法提供数据输入。

-
ZigZag 算法的 AVX512 优化
通过 AVX512 的指令,替代了之前的 8 次相同的循环操作,实现了一次并行处理 8 个数据,利用减法和移位异或操作,将数据还原成 ZigZag 编码前的数值。在优化后,只用了很少的 AVX512 指令,就实现了循环多次才能获得的结果,极大的减少了指令数,提升了系统的性能。

AVX512 的编译环境和运行环境
为了充分利用 AVX512 指令集,建议使用 gcc 版本 9 以上的编译器进行编译,以获得更完善的 AVX512 指令支持。在运行时,应检查 CPU 是否支持 AVX512 指令,只有在支持 AVX512 的 CPU 上运行 AVX512 指令,才能做到和其他非 AVX512 的 CPU 的代码兼容。
总而言之,通过利用英特尔® AVX512 高级向量扩展指令,TDengine 成功优化了数据处理算法,提升了时序数据库的性能。特别是针对 Simple8B 和 ZigZag 算法的优化,让时序数据的处理得以实现更高效的并行计算,通过一次性处理多个数据,减少了指令数,显著提升了系统的性能表现。
开启 AVX512 指令集优化以后,在 TDengine 新版本 3.2.3.0 上,解码整数类型数据的性能是软件解码性能的 1.82 倍,是 AVX2 指令集解码性能的 1.28 倍。这些优化措施也让 TDengine 在处理海量数据的查询和分析过程中更加高效,为实时应用场景提供了更强大的支持。
注:AVX指令集支持的开启,需要用户自己编译代码并打开配置开关。具体操作可以联系 TDengine 官方团队。
特别鸣谢:在本次 TDengine 与 AVX512 的优化集成工作中,英特尔数据中心与人工智能事业部的高级软件架构师蒋锴,凭借专业知识和技术能力,积极推动着优化工作的进展,为 TDengine 的发展贡献着重要的力量。