基于在校学习平台MOOC的选课推荐系统
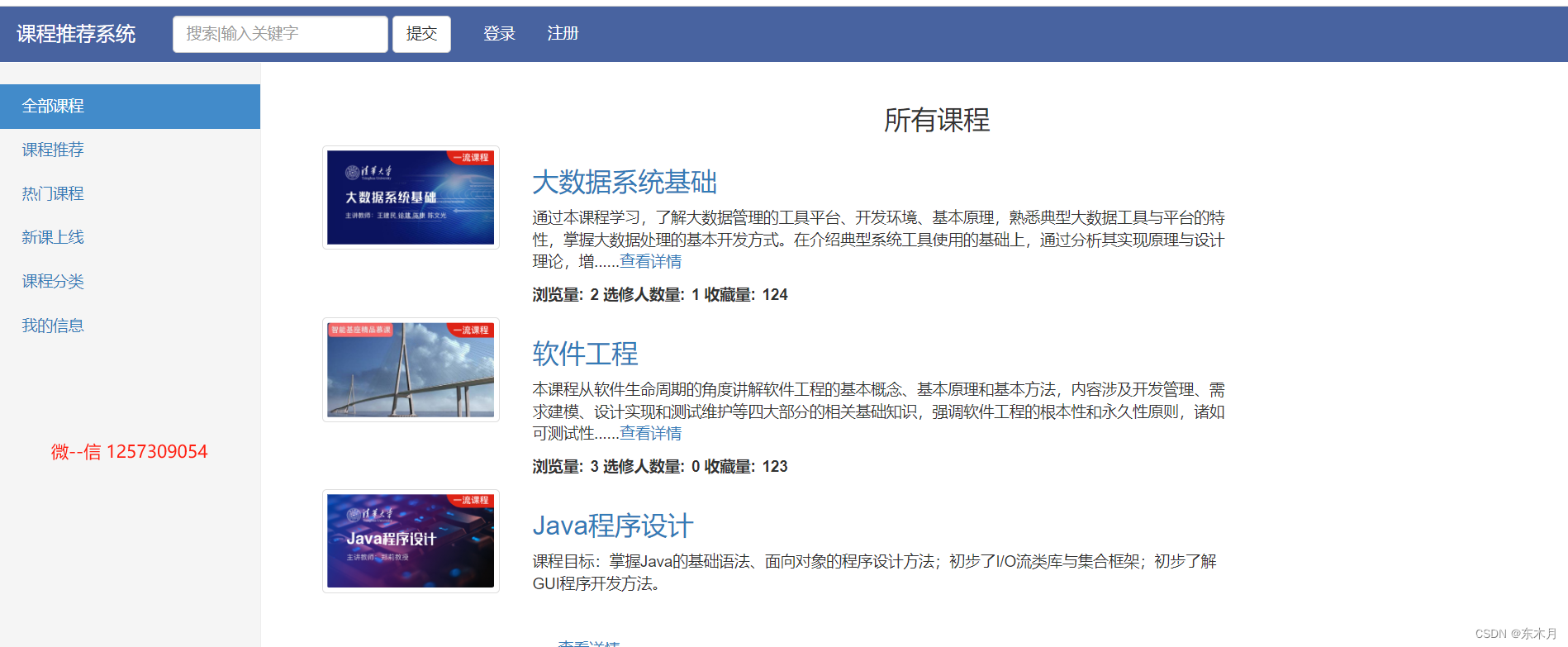
1、效果
在线demo,点我查看
2、功能
根据学生于在校学习平台MOOC学习期间的选课记录等相关特征来对学生进行课程推荐。
采用数据挖掘技术,包括BPR、FM、CF,神经网络推荐,用户协同过滤推荐。
用到的数据集来自于XuetangX,数据集的名称为Course Recommendation,该数据中记录了学生于在线学习平台XuetangX上的选课学习记录,包括学生id、时间、课程id、类别id等。
关于数据集的详细介绍可以参照官方说明。
数据集介绍链接如下:http://moocdata.cn/data/course-recommendation。
登录注册,个人中心,冷启动,热门课程,课程推荐,课程分类,可视化,收藏,选修,点赞,评论,评分
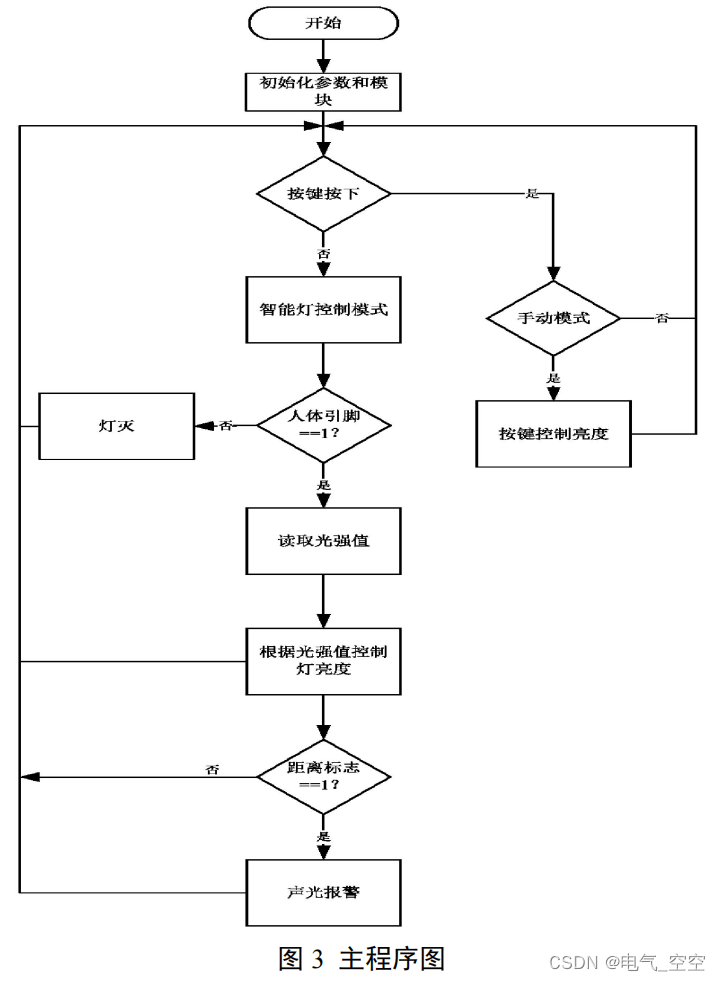
3、推荐算法
3.1 导入库
# -*- coding: utf-8 -*-
"""
@contact: (微)信 1257309054
@file: test.py
@time: 2024/6/22 12:46
@author: LDC
"""
pip install numpy
pip install pandas
pip install tensorflow
3.2 算法说明
1、从数据库中获取所有选修数据
2、对矩阵进行向量化,便于神经网络学习
3、使用LabelEncoder将字符串标签转换为整数标签
4、划分训练集与测试集
5、创建NCF模型
6、合并 embeddings向量
7、添加全连接层
8、编译模型
9、模型训练
10、模型评估
11、模型保存
12、模型推荐
3.3 全部代码
# -*- coding: utf-8 -*-
"""
@contact: 微信 1257309054
@file: recommend_ncf.py
@time: 2024/6/16 22:13
@author: LDC
"""
import os
import django
import joblib
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from keras.models import load_model
os.environ["DJANGO_SETTINGS_MODULE"] = "course_manager.settings"
django.setup()
from course.models import *
def get_all_data():
'''
从数据库中获取所有物品评分数据
[用户特征(点赞,收藏,评论,
物品特征(收藏人数,点赞人数,浏览量,评分人数,平均评分)
]
'''
# 定义字典列表
user_item_list = []
# 从评分表中获取所有课程数据
item_rates = RateCourse.objects.all().values('course_id').distinct()
# 获取每个用户的评分数据
for user in User.objects.all():
user_rate = RateCourse.objects.filter(user=user)
if not user_rate:
# 用户如果没有评分过任何一本课程则跳过循环
continue
data = {'User': f'user_{user.id}'}
for br in item_rates:
item_id = br['course_id']
ur = user_rate.filter(course_id=item_id)
if ur:
data[f'item_{item_id}'] = ur.first().mark # 对应课程的评分
else:
data[f'item_{item_id}'] = np.nan # 设置成空
user_item_list.append(data)
data_pd = pd.DataFrame.from_records(user_item_list)
print(data_pd)
return data_pd
def get_data_vector(data):
'''
对矩阵进行向量化,便于神经网络学习
'''
user_index = data[data.columns[0]]
data = data.reset_index(drop=True)
data[data.columns[0]] = data.index.astype('int')
scaler = 5 # 评分最高为5,把用户的评分归一化到0-1
df_vector = pd.melt(data, id_vars=[data.columns[0]],
ignore_index=True,
var_name='item_id',
value_name='rate').dropna()
df_vector.columns = ['user_id', 'item_id', 'rating']
df_vector['rating'] = df_vector['rating'] / scaler
df_vector['user_id'] = df_vector['user_id'].apply(lambda x: user_index[x])
print(df_vector)
return df_vector
def evaluation(y_true, y_pred):
'''
模型评估:获取准确率、精准度、召回率、F1-score值
y_true:正确标签
y_pred:预测标签
'''
accuracy = round(classification_report(y_true, y_pred, output_dict=True)['accuracy'], 3) # 准确率
s = classification_report(y_true, y_pred, output_dict=True)['weighted avg']
precision = round(s['precision'], 3) # 精准度
recall = round(s['recall'], 3) # 召回率
f1_score = round(s['f1-score'], 3) # F1-score
print('神经网络协同推荐(NCF):准确率是{},精准度是{},召回率是{},F1值是{}'.format(accuracy, precision, recall, f1_score))
return accuracy, precision, recall, f1_score
def get_data_fit(df_vector):
'''
数据训练,得到模型
'''
scaler = 5 # 特征标准化:最高分为5,需要归一化到0~1
dataset = df_vector # 已向量化的数据集
# 使用LabelEncoder将字符串标签转换为整数标签
user_encoder = LabelEncoder()
item_encoder = LabelEncoder()
dataset['user_id'] = user_encoder.fit_transform(dataset['user_id'])
dataset['item_id'] = item_encoder.fit_transform(dataset['item_id'])
# Split the dataset into train and test sets
train, test = train_test_split(dataset, test_size=0.2, random_state=42) # 划分训练集与测试集
# train = dataset
# Model hyperparameters
num_users = len(dataset['user_id'].unique())
num_countries = len(dataset['item_id'].unique())
embedding_dim = 64 # 64维向量标识
# 创建NCF模型
inputs_user = tf.keras.layers.Input(shape=(1,))
inputs_item = tf.keras.layers.Input(shape=(1,))
embedding_user = tf.keras.layers.Embedding(num_users, embedding_dim)(inputs_user)
embedding_item = tf.keras.layers.Embedding(num_countries, embedding_dim)(inputs_item)
# 合并 embeddings向量
merged = tf.keras.layers.Concatenate()([embedding_user, embedding_item])
merged = tf.keras.layers.Flatten()(merged)
# 添加全连接层
dense = tf.keras.layers.Dense(64, activation='relu')(merged)
dense = tf.keras.layers.Dense(32, activation='relu')(dense)
output = tf.keras.layers.Dense(1, activation='sigmoid')(dense)
# 编译模型
model = tf.keras.Model(inputs=[inputs_user, inputs_item], outputs=output)
model.compile(optimizer='adam', loss='mse', metrics=['mae'])
# 模型训练
model.fit(
[train['user_id'].values, train['item_id'].values],
train['rating'].values,
batch_size=64,
epochs=100,
verbose=0,
# validation_split=0.1,
)
item_rates = RateCourse.objects.all().values('course_id').distinct()
# 获取每个用户的评分数据
result_df = {}
for user in User.objects.all():
user_rate = RateCourse.objects.filter(user=user)
if not user_rate:
# 用户如果没有评分过任何一本课程则跳过循环
continue
user = f'user_{user.id}'
result_df[user] = {}
for br in item_rates:
item_id = br['course_id']
item = f'item_{item_id}'
pred_user_id = user_encoder.transform([user])
pred_item_id = item_encoder.transform([item])
result = model.predict(x=[pred_user_id, pred_item_id], verbose=0)
result_df[user][item] = result[0][0]
result_df = pd.DataFrame(result_df).T
result_df *= scaler
print('全部用户预测结果', result_df)
# 预测测试集并转成整形列表
y_pred_ = np.floor(model.predict(x=[test['user_id'], test['item_id']], verbose=0) * scaler).tolist()
y_pred = []
for y in y_pred_:
y_pred.append(int(y[0]))
y_true = (test['rating'] * scaler).tolist()
evaluation(y_true, y_pred) # 模型评估
joblib.dump(user_encoder, 'user_encoder.pkl') # 保存用户标签
joblib.dump(item_encoder, 'item_encoder.pkl') # 保存课程标签
model.save('ncf.dat') # 模型保存
def get_ncf_recommend(user_id, n=10):
'''
# 获取推荐
user_id:用户id
n:只取前十个推荐结果
'''
scaler = 5 # 特征标准化:最高分为5,需要归一化到0~1
model = load_model('ncf.dat') # 加载模型
# 加载标签
user_encoder = joblib.load('user_encoder.pkl')
item_encoder = joblib.load('item_encoder.pkl')
result_df = {}
item_rates = RateCourse.objects.all().values('course_id').distinct()
for item in item_rates:
item_id = item['course_id']
user = f'user_{user_id}'
item = f"item_{item_id}"
pred_user_id = user_encoder.transform([user])
pred_item_id = item_encoder.transform([item])
result = model.predict(x=[pred_user_id, pred_item_id], verbose=0)
if not RateCourse.objects.filter(user_id=user_id, course_id=item_id):
# 过滤掉用户已评分过的
result_df[item_id] = result[0][0] * scaler
result_df_sort = sorted(result_df.items(), key=lambda x: x[1], reverse=True) # 推荐结果按照评分降序排列
print('预测结果', result_df_sort)
recommend_ids = []
for rds in result_df_sort[:n]:
recommend_ids.append(rds[0])
print(f'前{n}个推荐结果', recommend_ids)
return recommend_ids
if __name__ == '__main__':
data_pd = get_all_data() # 获取数据
df_vector = get_data_vector(data_pd) # 数据向量化
data_recommend = get_data_fit(df_vector) # 获取数据训练模型
user_id = 1
recommend_ids = get_ncf_recommend(user_id) # 获取用户1的推荐结果
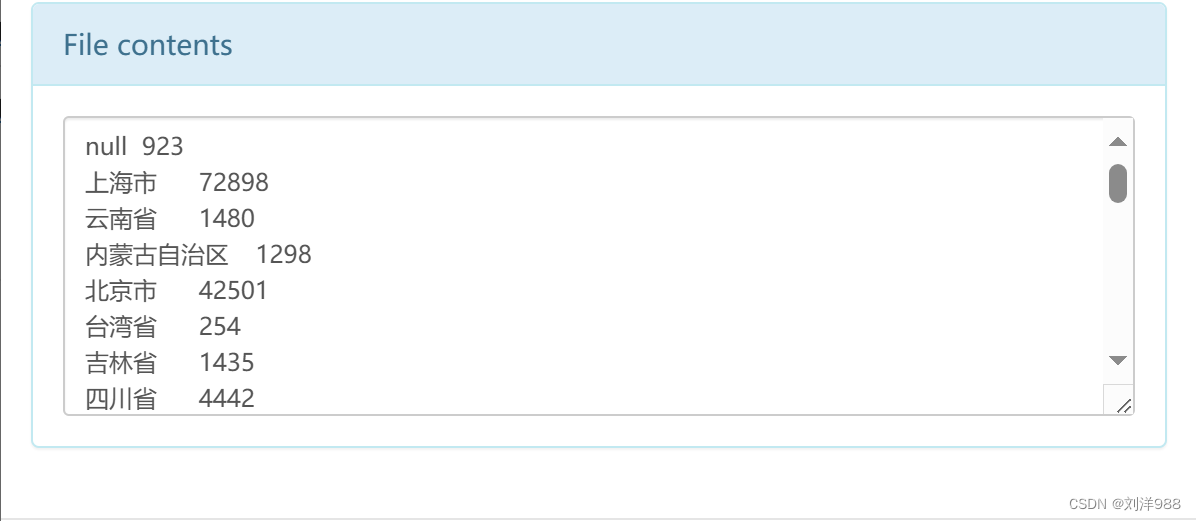
4、数据概览
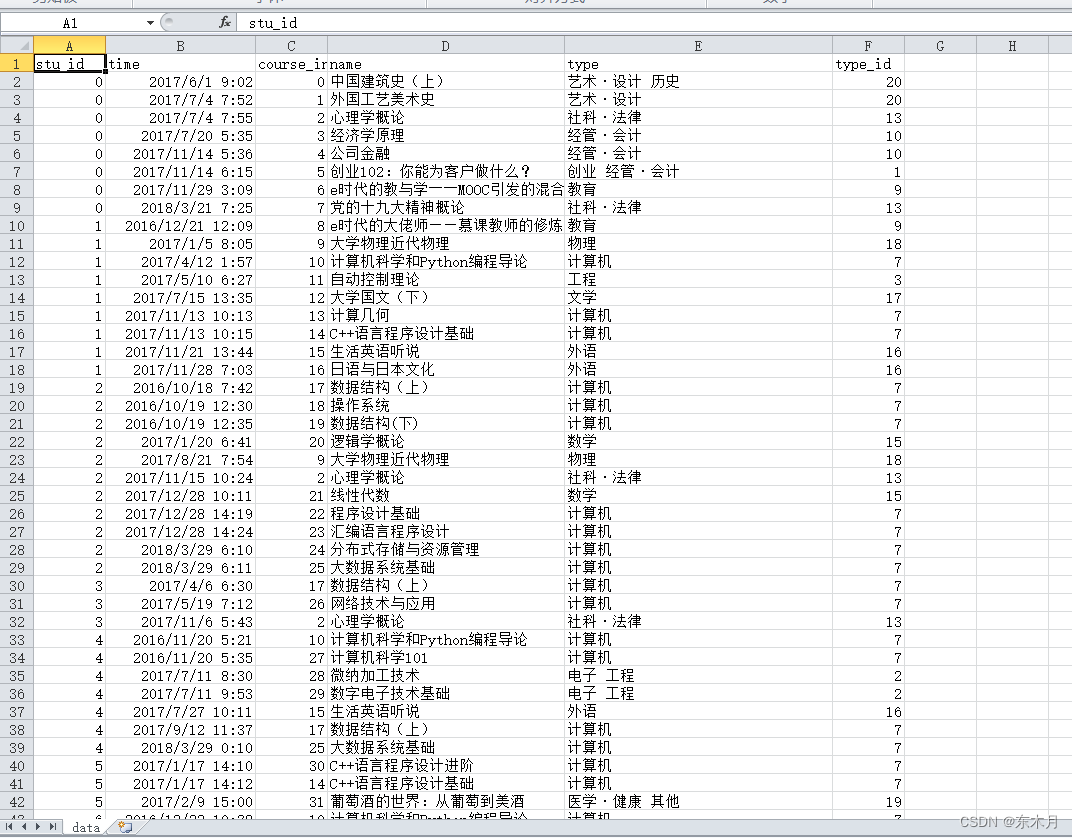
5、数据导入
流程:
1、保存上一个用户
2、创建学生信息,用户名就是学生编号,密码是123456
3、更新课程序号
4、创建选课记录
5、添加用户喜欢的课程类型
6、更改上一个用户
7、
def import_data(request):
with open('data/data.csv', 'r', newline='', encoding='gbk') as fp:
reader = csv.reader(fp)
user_last = None # 上一个用户
tag_id = []
for row in reader:
user_id = row[0]
if user_id == 'stu_id':
continue
if not user_last:
user_last = user_id
users = User.objects.filter(username=user_id)
if not users:
user = User.objects.create(username=user_id, password='123456') # 创建学生信息,用户名就是学生编号,密码是123456
else:
user = users.first()
# 查找课程
course_infos = CourseInfo.objects.filter(name=row[3])
if not course_infos:
continue
course = course_infos.first()
if not course.course_index:
course.course_index = row[2] # 更新课程序号
course.save()
if not UserCourse.objects.filter(user=user, course=course):
# 创建选课记录
UserCourse.objects.create(
user_id=user.id,
course_id=course.id,
std_id=row[0],
course_index=row[2],
enroll_time=row[1]
)
course.select_num += 1
course.look_num += 1
course.save()
if user_id != user_last:
# 添加用户喜欢的课程类型
user_select = UserSelectTypes.objects.filter(user=User.objects.get(username=user_last))
if not user_select:
user_select = UserSelectTypes.objects.create(user=User.objects.get(username=user_last))
else:
user_select = user_select.first()
for value in tag_id:
user_select.category.add(value)
user_last = user_id # 更改上一个用户
tag_id = []
else:
tag_id.append(course.tags_id)
print('创建选课记录成功', user_id, row[3])
else:
course.select_num += 1
course.look_num += 1
course.save()
return HttpResponse('导入成功')